创新指南 | 用这8种商业分析模型,让你得到靠谱的业务创新灵感_商业分析常用的业务模型分为:市场分析模型、《(1)》、 《(2)》 以及服务分析模型-程序员宅基地
当我们想要创新时,往往需要有实际的依据来支撑我们的想法。商业咨询顾问通常被认为是聪明的人,他们拥有模型化的分析思维,这种思维方式可以帮助他们更好地理解市场、竞争对手和客户需求。商业分析思维是一种系统性的思考方式,它可以帮助我们更好地理解商业问题,并提出切实可行的解决方案。
以下是8种常见的商业分析思维,它们可能不会瞬间升级你的思维模式,但说不定会为你以后的工作带来“灵光一闪”的感觉。
01. 分类模型
在日常工作中,我们需要进行分类思维,例如客户分群、产品归类、市场分级等。分类后的结果需要在核心关键指标上能够拉开距离,也就是说,分类后的对象必须有显著的集群倾向,而不是随机分布。通常情况下,我们会将关注的核心指标作为横轴和纵轴,在这些指标的基础上进行分类。
举个例子,RFM模型是一种常用的用户分群体系,它依托收费的三个核心指标(最近一次消费时间、消费频率、消费金额)来构建。我们将实际的用户根据这些指标划分为八个区域,每个区域代表了一种不同的用户价值群体。我们需要促进不同的用户向更有价值的区域转移,并根据不同付费用户群体的价值采用不同的策略来提高其价值。

在R/M/F三个指标上,我们通过经验将实际的用户划分为以下8个区(如上图),我们需要做的就是促进不同的用户向更有价值的区域转移。也就是将每个付费用户根据消费行为数据,匹配到不同的用户价值群体中,然后根据不同付费用户群体的价值采用不同的策略(如下图)
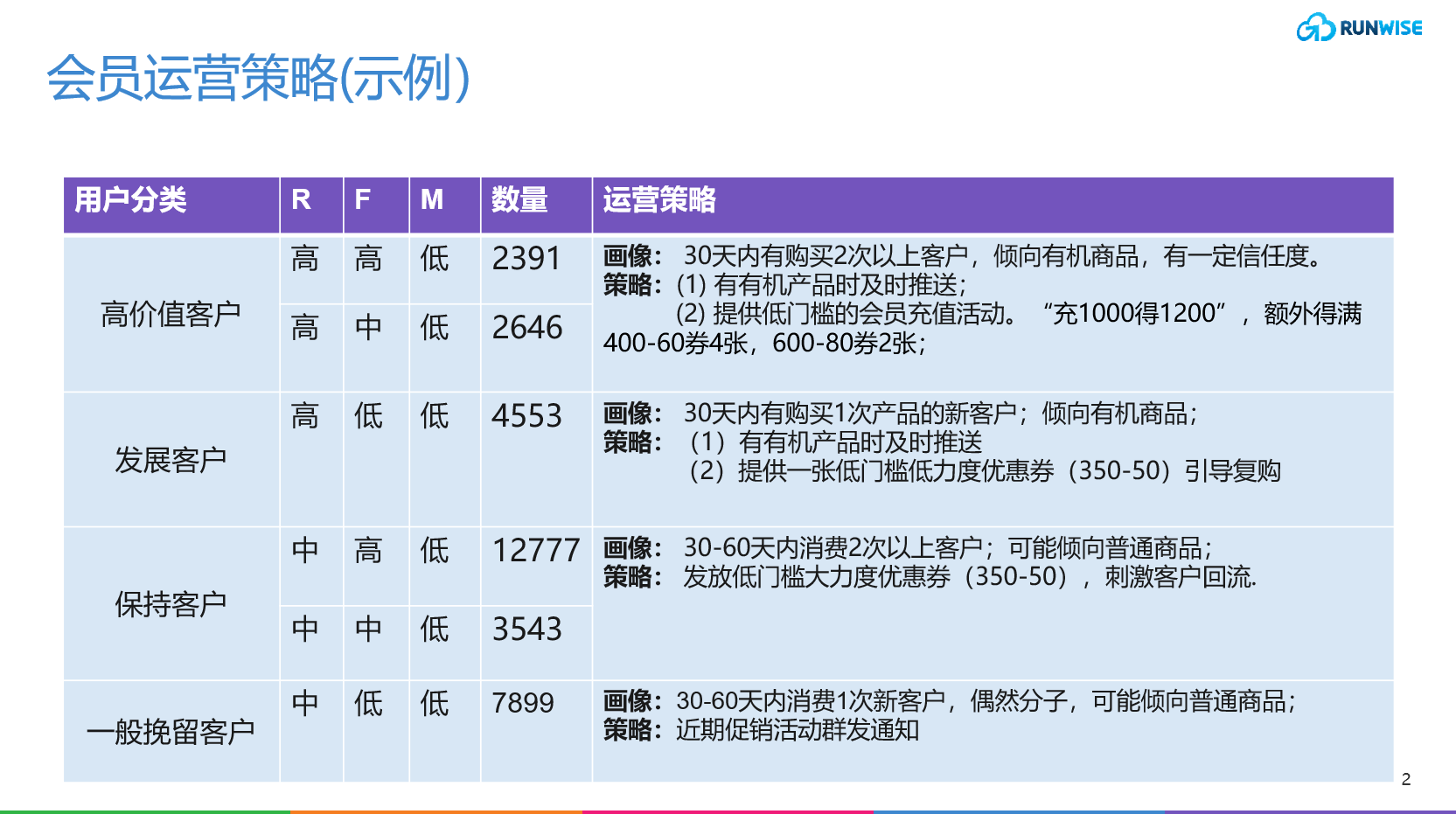
分类是一种常见的手段,可以应用于许多场景,例如用户分类(如新老用户、活跃度、消费力水平等)和商品分类(如价格带、规格、用户需求等)。在数据挖掘或机器学习中,分类问题占据了很大的比例,其目的是将具有某些共同点或相似特征的对象分为一组,以便更好地管理和进行业务精细化运营。此外,分类也有助于研究同类事物的共性和差异,以便更好地理解其特性和用户需求。但需要注意的是,分类只是一种手段,我们不应该为了分类而分类。
02. 象限模型
象限模型是分类模型的一种发展,它不再仅限于使用量化指标进行分类。当我们没有数据支持时,只能通过经验主观推断。在这种情况下,我们可以将一些重要因素组合成矩阵,大致定义出好坏的方向,然后进行分析。著名的波士顿矩阵就是一种经典的管理分析象限模型,可以帮助我们进行分类和分析。

象限分析法有以下优势:
-
找到问题的共性原因:通过将具有相同特征的事件进行归因分析,可以总结出其中的共性原因。例如,在广告推广案例中,第一象限的事件可以提炼出有效的推广渠道和策略,第三和第四象限则可以排除一些无效的推广渠道。
-
建立分组优化策略:针对不同象限,可以建立优化策略。例如,在RFM客户管理模型中,可以根据象限将客户分为重点发展客户、重点保持客户、一般发展客户、一般保持客户等不同类型。然后,可以给重点发展客户倾斜更多的资源,比如VIP服务、个性化服务、附加销售等。给潜力客户销售价值更高的产品,或者提供一些优惠措施来吸引他们回归。
03. 漏斗模型
漏斗模型是比较被人所熟知的分析法。其中包括长漏斗和短漏斗。长漏斗通常涉及环节较多,时间周期较长,例如渠道归因模型、AARRR模型和用户生命周期模型。短漏斗则有明确的目的,时间短,例如订单转化漏斗和注册漏斗。

漏斗分析通常用于分析多业务环节和用户成交的链路分析。然而,应用时需要注意漏斗的长度。漏斗不应超过5个环节,各环节的百分比数值量级不应超过100倍,并且最后一个环节的转化率数值不应低于1%。如果超过这些限制,建议将漏斗分为多个部分进行观察。
这是因为如果漏斗的环节超过5个,往往会出现多个重点环节,容易在一个漏斗模型中分析多个重要问题,从而产生混乱。另外,各环节的百分比数值量级差距过大时,数值间波动相互关系很难被察觉,容易遗漏信息。因此,需要注意这些限制以避免出现混乱和遗漏信息的情况。
04. 帕累托模型
帕累托模型(也叫ABC分析模型)源于经典的二八法则,即20%的数据产生了80%的效果。在数据分析中,使用二八法则可以帮助我们找到重点,从而提高效果。
在业务运营中,我们经常需要分清主次。ABC分析模型是一种帮助我们做出这种决策的工具。这种模型可以用来划分产品、客户及客户交易额等。例如,在产品分类上,我们可以按照销售额从大到小排列,并计算每个产品销售额占总销售额的百分比。然后,我们可以根据百分比的不同将产品划分为A、B和C类。百分比在70%(含)以内的产品划分为A类,70%~90%(含)的产品划分为B类,90%~100%(含)的产品划分为C类。这种划分可以帮助我们了解哪些产品对销售额贡献最大,从而更好地分配资源。
ABC分析模型不仅可以用来划分产品,还可以用来划分客户及客户交易额等。例如,我们可以通过计算每个客户对总利润的贡献来划分客户。如果只有20%的客户贡献了80%的利润,那么我们就知道要重点维护这些客户。这种分析模型可以帮助企业了解哪些客户或产品对利润贡献最大,从而更好地制定战略和决策。

05. 逻辑树分析法
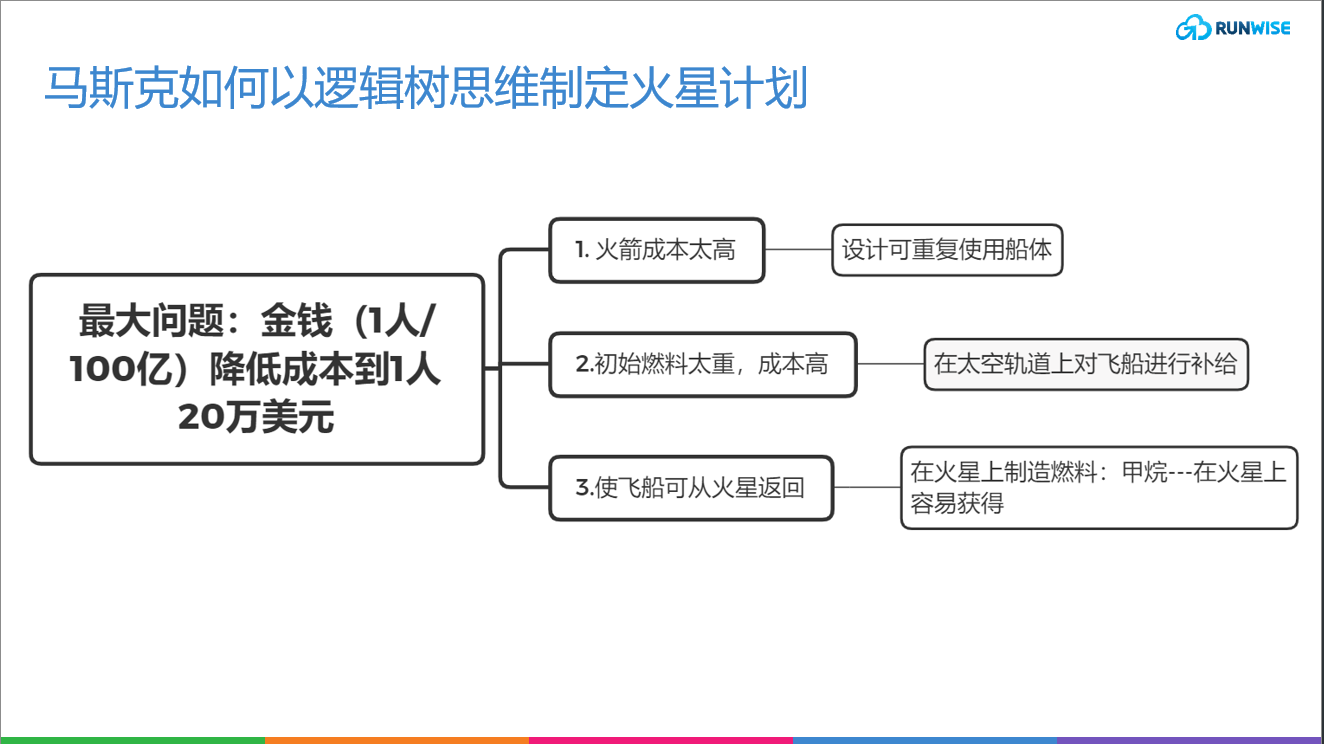
逻辑树分析法是一种将问题分解为多个子问题的工具,也被称为问题树、演绎树和分解树等。通过逐层细化问题,直到找到解决方案,逻辑树分析法可以确保没有遗漏或疏忽,并建立共识。这种方法被广泛应用于解决商业和社会问题。

我们可以把一个已知的问题作为一个树干,然后开始思考这个问题与哪些相关的子问题或者子任务相关。每次想到什么,就给问题(也就是树干)加上一个分支,指明这个分支具体代表什么问题,此外,分支可以进一步分叉,一个大的分支可以有多个小分支,以此类推找出所有相关项的问题。
这就是逻辑树分析法,也叫问题树、演绎树或分解树。
06. 留存/队列模型
队列分析是按照一定的规则,在时间上将观察对象进行切片,形成一个观察样本,然后观察这个样本在某些指标上随着时间的变化。目前,队列分析最常用的应用场景是留存分析。留存分析是指对用户在某个时间段内的活跃度进行分析,以了解他们对产品或服务的忠诚度。队列分析可以帮助我们了解用户留存率的变化趋势,并根据这些趋势来制定相应的策略,以提高用户留存率。

留存率是指新用户在一段时间后仍然保持访问、登录、使用或转化等特定行为的比例。留存率根据不同的时间周期可以分为三类。以登录行为为例,留存率是指在一定时间后仍然保持登录行为的新用户占当时新用户总数的比例。
留存率反映的实际上是一种转化率,即由初期的不稳定的用户转化为活跃用户、稳定用户、忠诚用户的过程。随着统计数字的变化,运营人员可看到不同时期用户的变化情况,从而判断产品对客户的吸引力。从产品的角度出发,我们通过之前的留存分析,找到触发影响留存的关键行为,帮助用户尽快找到产品留存的关键节点,提高早期用户的留存。
07 关联模型(购物篮分析)
相信您应该都听过这样一个案例:超市里经常会把婴儿的尿不湿和啤酒放在一起售卖,原因是经过数据分析发现,买尿不湿的父亲,如果他们在买尿不湿的同时看到了啤酒,将有很大的概率购买,从而提高啤酒的销售量。
这种关联模型通过研究用户消费数据,将不同商品之间进行关联,并挖掘二者之间联系。在进行商品关联分析时,可以使用三个指标来判断商品之间的关联,这三个指标分别是支持度、置信度和提升度。支持度指的是同时购买两个商品的概率,置信度指的是购买一个商品后购买另一个商品的概率,提升度则是指两个商品之间的关联程度,即购买一个商品是否会对另一个商品的销售产生积极影响。通过商品关联分析法,商家可以更好地了解消费者的购买行为,从而制定更加有效的营销策略。

08 KANO模型
企业经常会遇到非常多的产品需求, 开发团队忙的不可开交, 用户又似乎什么都想要。开发产品资源有限,怎么才能捞出真正的用户需求给真正重要的需求高优先级?
KANO模型:是对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。
在KANO模型中,根据不同类型的需求与用户满意度之间的关系,可将影响用户满意度的因素分为五类:基本型需求、期望型需求、兴奋型需求、无差异需求、反向型需求。
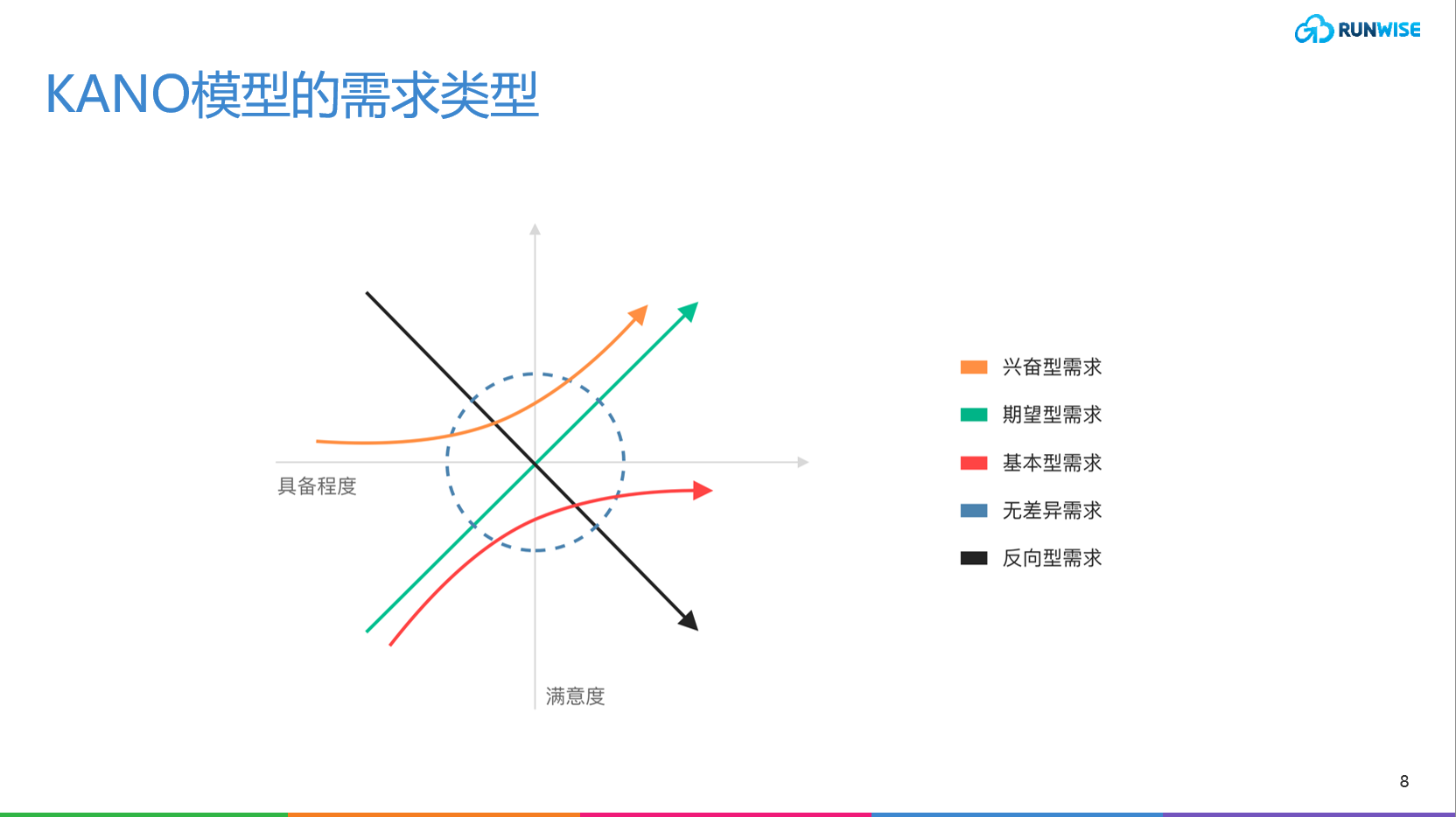
KANO模型就可以帮助我们很好地贴合业务需求,从具备程度和满意程度这两个维度出发,将CRM中新增的功能进行区分和排序,从而知道:哪些功能是一定要有,否则会直接影响用户体验的(基础属性、期望属性);哪些功能是没有时不会造成负向影响,拥有时会给用户带来惊喜的(兴奋属性);哪些功能是可有可无,具备与否对用户都不会有大影响的(无差异因素)。
而获取用户需求要通过问卷进行,KANO问卷对每个质量特性都由正向和负向两个问题构成,分别测量用户在面对存在或不存在某项质量特性时的反应。

当正向问题的回答是“我喜欢”,负向问题的回答是“我不喜欢”,那么KANO评价表中,这项功能特性就为“O”,即期望型。
如果将用户正负向问题的回答结合后,为“M”或“A”,则该功能被分为基本型需求或兴奋型需求。其中,R表示用户不需要这种功能,甚至对该功能有反感;I类表示无差异需求,用户对这一功能无所谓。Q表示有疑问的结果,一般不会出现这个结果(除非这个问题的问法不合理,或者是用户没有很好的理解问题,或者是用户在填写问题答案时出现错误)。
简单来说就是:
- A:兴奋型;
- O:期望型;
- M:必备型;
- I:无差异型;
- R:反向型;
- Q:可疑结果。
注意:以上对照表只是的最常见的一种归类方式。实际操作中,可因人而异,因产品、公司、地域而异(尤其是关于“R”和“O”的定义),因为满意度本身就难以衡量。

从上表中不难看出,“通讯录中「拨打电话」“这个功能在6个维度上均可能有得分,将相同维度的比例相加后,可得到6个属性维度的占比总和。总和最大的一个属性维度,便是该功能的属性归属。
可看出“在通讯录中提供「拨打电话」功能“属于兴奋型需求。即说明没有这个功能,用户不会有强烈的负面情绪,但是有了这个功能,会让用户感受到满意和惊喜。
如果你只判断这一个需求,那么进行到这一步就可以到此为止了。如果涉及到多个需求的排序分级,你还需进行下一步—-计算 better-worse系数
Better,可以解读为增加后的满意系数。Better的数值通常为正,代表如果产品提供某种功能或服务,用户满意度会提升。正值越大/越接近1,则表示用户满意度提升的效果会越强,满意度上升的越快。
Worse,可以叫做消除后的不满意系数。Worse的数值通常为负,代表产品如果不提供某种功能或服务,用户的满意度会降低。其负值越大/越接近-1,则表示对用户不满意度的影响最大,满意度降低的影响效果越强,下降的越快。
因此,根据 better-worse系数,对两者系数绝对分值较高的项目应当优先实施。
其计算公式如下:
- 增加后的满意系数 Better/SI=(A+O)/(A+O+M+I)
- 消除后的不满意系数 Worse/DSI= -1 *(O+M)/(A+O+M+I)
假设某产品希望优化5项功能,但不确定哪些功能是用户最需要的。通过计算这5项功能的better-worse系数值,并将其绘制成散点图,可以将图形分为四个象限,以确定每个功能的需求优先级。

- 第一象限:也称为期望型因素。在这个象限中,better系数值高,worse系数绝对值也很高,代表着这些因素对用户的满意度有较大的影响。例如,功能2属于这个象限,如果产品提供了这个功能,用户的满意度会提高;反之,如果不提供这个功能,用户的满意度会下降。
- 第二象限:兴奋型因素。这个象限中,better系数值高,worse系数绝对值低,代表着这些因素对用户的满意度有很大的提升作用。例如,功能1属于这个象限,如果产品不提供这个功能,用户的满意度不会下降;但是如果提供了这个功能,用户的满意度会大大提高。
- 第三象限:无差异型因素。better系数值低,worse系数绝对值也低,代表着这些因素对用户的满意度没有明显的影响。例如,功能3属于这个象限,无论产品提供或不提供这个功能,用户的满意度都不会有太大的改变,这些功能点并不是用户关注的重点。
- 第四象限:必备因素。在这个象限中,落入其中的因素被称为基本要求,是产品必须要具备的功能。例如,功能4属于这个象限,如果产品提供了这个功能,用户的满意度不会有太大提升;但是如果不提供这个功能,用户的满意度会大幅降低,说明这个功能是最基本的功能之一。
在实际项目中:
- 我们首先要全力以赴地满足用户最基本的需求,即第四象限表示的必备型因素,这些需求是用户认为我们有义务做到的事情。
- 在满足最基本的需求之后,再尽力去满足用户的期望型需求,即第一象限表示的期望因素,这是质量的竞争性因素。提供用户喜爱的额外服务或产品功能,使其产品和服务优于竞争对手并有所不同,引导用户加强对本产品的良好印象。
- 最后争取实现用户的兴奋型需求,即第二象限表示的兴奋型因素,提升用户的忠诚度。
因此,在这个例子中,根据KANO模型计算出的better-worse系数值,说明该产品先满足功能5和4,再优化功能2,最后满足功能1。
而功能3对用户来说有或者没有都无所谓,属无差异型需求,并没有必要花大力气去实现。
原文链接:
# 创新指南 | 用这8种商业分析模型,让你得到靠谱的业务创新灵感
延展文章:
1. 创新案例|昆曲DTC创新,用大数据和社群营销重塑传统演出商业模式
2. 创新案例|千亿护肤品牌林清轩DTC以全域直播+私域运营重塑新零售力
更多精彩案例与方案可以访问Runwise创新社区。
智能推荐
计算机的外围设备简介_计算机外围固定-程序员宅基地
文章浏览阅读6.1k次,点赞3次,收藏5次。外围设备介绍计算机的外围设备(简称外设)虽然很多,但按功能分大类只有四类:输入、输出、存储、网络通讯。有些专业计算机需要的外围设备也不尽相同,并不都需要这四类外围设备。外围设备可以按需要组装,有些专业计算机甚至可以将存储设备和主芯片集成到一片芯片上,从而不再需要外加存储设备。最早的计算机(那时还只能称为计算器,只能做简单运算,如ABC机和ENIAC机)输入只是一些拨码开关,只能输入数字(还得是二进_计算机外围固定
java 图片中加文字_java怎么在图片上加文字-程序员宅基地
文章浏览阅读1.5k次。java 图片中加文字_java怎么在图片上加文字
GBase8cGDCA认证模拟题题库(三)_如果需要打开delete语句的审计功能,需要开启下面哪个参数-程序员宅基地
文章浏览阅读720次,点赞20次,收藏6次。B 选项,在创建模式时,可以不指定模式名。C 选项,兼容模式可选值为 AB、C、PG.安装GBase 8c分布式集群时所需的配置文件gbase.yml,在解压GBase8cV5 S3.0.0BXX CentOS x86 64.tar.bz2压缩包生成的目录中得到。真值的有效文本值是: TRUE、t、"true'、y、yes'、"1'TRUE'、true、整数范围内1~2^63-1、整数范围内-1~-2^63。GBase 8c 使用create table 创建表时,不指定参数,默认是astore,行存表。_如果需要打开delete语句的审计功能,需要开启下面哪个参数
xml文件中几个名词_xml文件里面的名词-程序员宅基地
文章浏览阅读334次。1 xmlns是XML Namespaces的缩写,中文名称是XML(标准通用标记语言的子集)命名空间。 web-app是web.xml的根节点标签名称 version是版本的意思 xmlns是web.xml文件用到的命名空间 xmlns:xsi是指web.xml遵守xml规范 xsi:schemaLocation是指具体用到的schema资源_xml文件里面的名词
【OpenGL】中点圆、椭圆生成算法_用setpixel函数中点画圆算法代码c++-程序员宅基地
文章浏览阅读1.6w次,点赞12次,收藏69次。OpenGL 中点圆、椭圆生成算法_用setpixel函数中点画圆算法代码c++
HTML-CSS实现背景图片出现不同的位置_css背景图高度占据一半另一半有别的背景色-程序员宅基地
文章浏览阅读2.1k次。首先在HTML中写入div,命名为img,在这个div中加入一个span标签并命名为img-bg和img50(5星为50).<div class="img"> <span class="img-bg img50"></span> <span class="img-bg img45"></span> <span class="img-bg img40"></span> </div> 在css代码._css背景图高度占据一半另一半有别的背景色
随便推点
duilib vs2015 安装_DuiLib(1)——简单的win32窗口-程序员宅基地
文章浏览阅读169次。资源下载https://yunpan.cn/cqF6icWRN5CTc 访问密码 92e3 注:DUILIB库.7z 是vs2015下编译好的动态库及静态库,如上图所示一、新建一个win32工程项目设置中选择:debug,常规中:全程无优化-全程无优化,多线程调试 (/MTd);我的项目选择的是静态编译,使用的是静态库,就不需要带duilib.dll文件了代码如下:#include #inclu..._vs2015使用duilib
OpenGL: 渲染管线理论详解_通过此次实验你对固定渲染管线的opengl编程有什么了解。-程序员宅基地
文章浏览阅读5k次,点赞4次,收藏13次。学习着色器,并理解着色器的工作机制,就要对OpenGL的固定功能管线有深入的了解。首先要知道几个OpenGL的术语:渲染(rendering):计算机根据模型(model)创建图像的过程。模型(model):根据几何图元创建的物体(object)。几何图元:包括点、直线和多边形等,它是通过顶点(vertex)指定的。 最终完成了渲染的图像是由在屏幕上绘制的像素组成的。在内存中,和像素有关的信息(如像素的颜色)组织成位平面的形式,位平面是一块内存区域,保存了屏幕上每个像素的一个位的信息。_通过此次实验你对固定渲染管线的opengl编程有什么了解。
Android MPAndroidChart:动态添加统计数据线【8】_android 动态统计-程序员宅基地
文章浏览阅读3.9k次。Android MPAndroidChart:动态添加统计数据线【8】本文在附录相关文章6的基础上,动态的依次增加若干条统计折线(相当于批量增加数据点)。布局文件:
vmware中的linux虚拟机如何增加磁盘容量_linux虚拟机磁盘空间不足-程序员宅基地
文章浏览阅读6.3k次。vmware中 centos的磁盘大小 20G->30G现象:fdisk -l可以看到增大后的磁盘总量,但是需要增加分区并格式化然后挂载才能使用.一、vmware中的设置先关闭虚拟机vm->settings->hard disk->utilities->expand->输入大小(增加后的大小)二、启动虚拟机,进入命令行1、 fdisk /dev/sda进入命令行Comman_linux虚拟机磁盘空间不足
Hadoop2.7.3下Mysql8.0下Hive2.3.8的安装_hive2.3.8安装-程序员宅基地
文章浏览阅读927次。hive安装前提:1.基于hadoop2.7的完全分布式集群搭建完成hadoop2.7集群搭建2.MySQL8.0安装完成 安装centos7上MySQL8.0Hive2.3.8的安装下载链接:https://mirrors.tuna.tsinghua.edu.cn/apache/下滑找到hive点击进去点击hive2.3.9(hive2.3.9和hive2.3.8差别不大)下载画红线的也就是bin.tar.gz后缀的hive解压安装下载完成后通过xftp传到虚拟机上(基操不在赘述)_hive2.3.8安装
The‘grub-efi-amd64-signed‘ package failed to install into /target/. Without the GRUB boot loader,_the grub-efiamd64-signed' package failed to instal-程序员宅基地
文章浏览阅读430次,点赞8次,收藏4次。在进行安装的时候有一个是否联网的选择,选择链接网络,则在安装的时候,可以看到在安装过程中,它会主动下载grub-efi-amd64-signed' package,确确实实,我在安装详情里看到了它有这个的download过程以及update过程。_the grub-efiamd64-signed' package failed to install intotarget without the g