Hadoop基础学习---3、HDFS概述、HDFS的Shell操作、HDFS的API操作_hadoop setrep-程序员宅基地
1、HDFS概述
1.1 HDFS产出背景及定义
1、HDFS产生背景
随着数据量越来越大,在一个操作系统存不住所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
2、HDFS定义
HDFS(Hadoop Distributed File System),是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
1.2 HDFS 优缺点
1、HDFS优点
(1)高容错
数据自动保存多个副本。它通过增加副本的形式提高容错性。
某一个副本丢失以后,它可以自动恢复。
(2)适合处理大数据
数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据;
文件规模:能够处理百万规模以上的文件数量,数量相当之大。
(3)可构建在廉价机器上,通过多副本机制,提高可靠性。
2、HDFS缺点
(1)不适合低延时数据范围,比如毫秒级的存储数据,是做不到的。
(2)无法高效的对大量小文件进行存储。
存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
(3)不支持并发写入、文件随机修改
一个文件只能有一个写,不允许多个线程同时写。
仅支持数据append(追加),不支持文件的随机修改。
1.3 HDFS组成架构
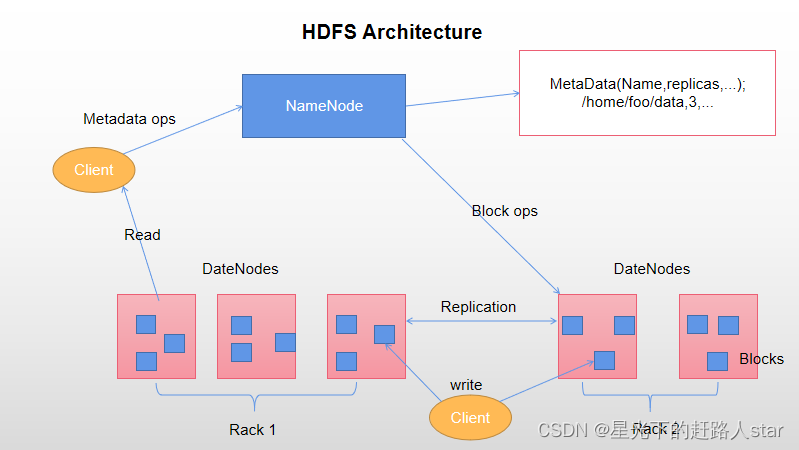
1、NameNode(nn):就是Master,它是一个主管、管理者。
(1)管理HDFS的名称空间
(2)配置副本策略
(3)管理数据块(Block)映射信息
(4)处理客户端读写请求。
2、DateNode:就是workes(slave)。NameNode下达命令,DataNode执行实际的操作。
(1)存储实际的数据块
(2)执行数据块的读/写操作
3、Client:客户端
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据。
(4)Client提供一些命令来管理HDFS,比如NameNode格式化
(5)Client可以通过一些命令来访问HDFS,比如对HDFS增删改查操作。
4、Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不是能马上替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode。
(2)在紧急情况下,可辅助恢复NameNode。
1.4 HDFS文件块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs blocksize)来规定,默认大小在hadoop2.x和3.x版本中是128M,1.x是64M。
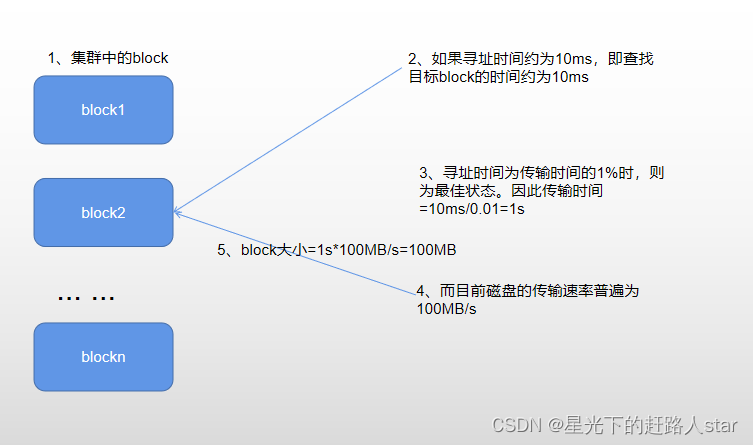
为什么块的大小不能设置太小也不能太大?
(1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
(2)如果块设置的太大,从磁盘传输速率的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘传输速率。
2、HDFS的Shell操作
2.1 基本语法
hadoop fs 具体命令 OR hdfs dfs 具体命令
两个是完全相同的。
2.2 命令大全
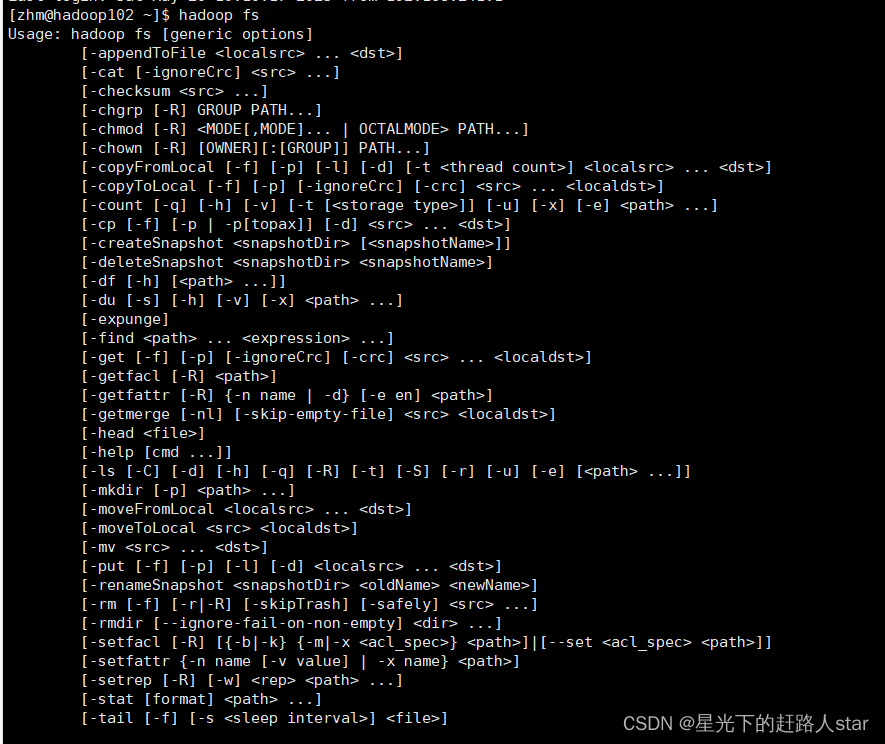
2.3 常用命令实操
2.3.1 准备工作
(1)启动hadoop集群
[zhm@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[zhm@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
(2)- help:输出这个命令参数
hadoop fs -help rm
(3)创建/zhm文件夹
hadoop fs -mkdir /zhm
2.3.2 上传
1、-moveFromLocal:从本地剪切粘贴到HDFS
hadoop fs -moveFromLocal 文件路径 目的路径
2、-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
hadoop fs -copyFromLocal 文件路径 目的路径
3、-put:等同于copyFromLocal,生产环境更习惯用put
hadoop fs -put 文件路径 目的路径
4、-appendToFile:追加一个文件到已经存在的文件末尾
hadoop fs -appendToFile 文件路径 目的路径
2.3.3 下载
1、-copyToLocal:从 HDFS 拷贝到本地
hadoop fs -copyToLocal 文件路径 目的路径
2、-get:等同于 copyToLocal,生产环境更习惯用 get
hadoop fs -get 文件路径 目的路径
2.4 HDFS直接操作
1、-ls:显示目录信息
hadoop fs -ls 目录
2、-cat:显示文件内容
hadoop fs -cat 文件路径
3、-chgrp、-chmod、-chown:Linux 文件系统中的用法一样,修改文件所属权限
4、-mkdir:创建路径
hadoop fs -mkdir 目录路径
5、-cp:从 HDFS 的一个路径拷贝到 HDFS 的另一个路径
hadoop fs -cp 文件路径 目的目录
6、-mv:在 HDFS 目录中移动文件
hadoop fs -mv 文件路径 目的路径
7、-tail:显示一个文件的末尾 1kb 的数据
hadoop fs -tail 文件路径
8、-rm:删除文件或文件夹
hadoop fs -rm 文件路径
9、-rm -r:递归删除目录及目录里面内容
hadoop fs -rm -r 文件路径
10、-du 统计文件夹的大小信息
hadoop fs -du 文件路径
11、-setrep:设置 HDFS 中文件的副本数量
hadoop fs -setrep 数量 文件路径
这里设置的副本数只是记录在NameNode的元数据中,是否真的有会有这么多的副本,还得看DataNode的数量、因为目前只有三台DataNode,最多也就是3个副本,只有节点数增加到相应的数量时,副本数才会达到相应的数量。
3、HDFS的API操作
3.1 客户端环境准备
1、找到资料包路径下的Windows依赖文件夹,拷贝hadoo-3.1.0到非中文路径(比如 d:\)。
链接:https://pan.baidu.com/s/1wamz5h6P0kyNxD_J6vwi8w
提取码:zhm6
–来自百度网盘超级会员V1的分享
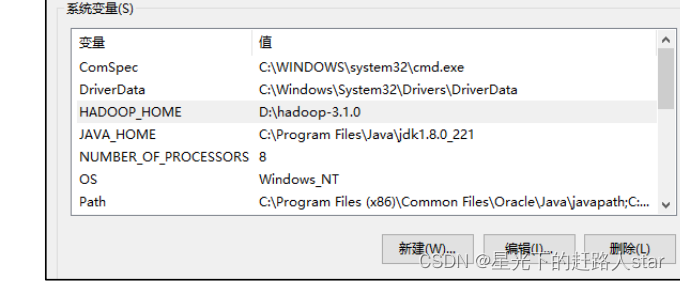
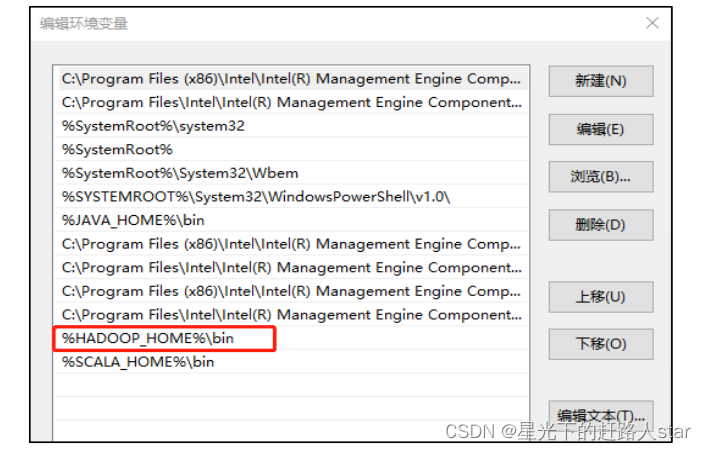
2、配置HADOOP_HOME环境变量
3、配置Path环境变量
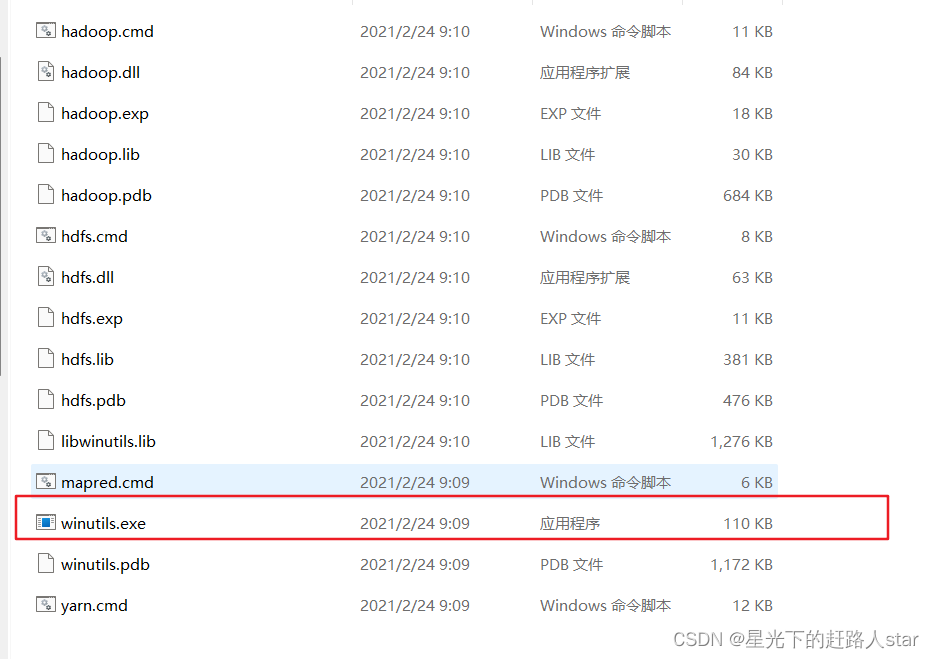
验证Hadoop环境变量是否正常,双击winutils.exe。
4、在IDEA中创建一个Maven工程,并导入相应的依赖坐标+日志添加
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5、创建包名:com.zhm.hdfs
6、在hdfs包下创建HdfsClient类
public class HdfsClient {
@Test
public void testMkdirs() throws IOException, URISyntaxException,
InterruptedException {
// 1 获取文件系统
Configuration configuration = new Configuration();
// FileSystem fs = FileSystem.get(new
URI("hdfs://hadoop102:8020"), configuration);
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration,"zhm");
// 2 创建目录
fs.mkdirs(new Path("/xiyou/huaguoshan/"));
// 3 关闭资源
fs.close();
}
}
7、执行程序
3.2 HDFS的API案例实操
3.2.1 HDFS文件上传(测试参数优先级)
1、编写源码
@Test
public void testCopyFromLocalFile() throws IOException,
InterruptedException, URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
configuration.set("dfs.replication", "2");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 上传文件
fs.copyFromLocalFile(new Path("d:/sunwukong.txt"), new
Path("/xiyou/huaguoshan"));
// 3 关闭资源
fs.close();
}
2、将hdfs-site.xml拷贝到项目的resource资源目录下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3、参数优先级
参数优先级排序:(1)客户端代码中设置的值>(2)Classpath下的用户自定义配置文件>(3)然后就是服务器的自定义配置(xxx-site.xml)>(4)服务器的默认配置(xxx-default.xml)
3.2.2 HDFS文件下载
@Test
public void testCopyToLocalFile() throws IOException,
InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 执行下载操作
// boolean delSrc 指是否将原文件删除
// Path src 指要下载的文件路径
// Path dst 指将文件下载到的路径
// boolean useRawLocalFileSystem 是否开启文件校验
fs.copyToLocalFile(false, new
Path("/xiyou/huaguoshan/sunwukong.txt"), new Path("d:/sunwukong2.txt"),
true);
// 3 关闭资源
fs.close();
}
3.2.3 HDFS文件更名和移动
@Test
public void testRename() throws IOException, InterruptedException,
URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 修改文件名称
fs.rename(new Path("/xiyou/huaguoshan/sunwukong.txt"), new
Path("/xiyou/huaguoshan/meihouwang.txt"));
// 3 关闭资源
fs.close();
}
3.2.4 HDFS删除文件和目录
@Test
public void testDelete() throws IOException, InterruptedException,
URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 执行删除
fs.delete(new Path("/xiyou"), true);
// 3 关闭资源
fs.close();
}
3.2.5 HDFS文件详情查看
查看文件名称、权限、长度、块信息
@Test
public void testListFiles() throws IOException, InterruptedException,
URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 获取文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"),
true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("========" + fileStatus.getPath() + "=========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// 获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
// 3 关闭资源
fs.close();
}
3.2.5 HDFS文件详情查看
@Test
public void testListStatus() throws IOException, InterruptedException,
URISyntaxException{
// 1 获取文件配置信息
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 判断是文件还是文件夹
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
// 如果是文件
if (fileStatus.isFile()) {
System.out.println("f:"+fileStatus.getPath().getName());
}else {
System.out.println("d:"+fileStatus.getPath().getName());
}
}
// 3 关闭资源
fs.close();
}
智能推荐
一个例子来全面比较一下传统测试与敏捷测试的区别_敏捷测试与传统测试的区别-程序员宅基地
文章浏览阅读1.2k次。这一讲的内容我想通过一个例子来全面比较一下传统测试与敏捷测试的区别,这个例子来自一本书——《凤凰项目:一个 IT 运维的传奇故事》。这是由美国的三位 DevOps 专家撰写的一本关于 IT 运维的小说。有人说,在 IT 咨询业,没读过这本书都不好意思跟人家谈 DevOps。别急,我们这一讲的重点的确不是 DevOps,而是比较传统测试与敏捷测试,一千个人眼里有一千个哈姆雷特,尽管大家对 DevOps 有不同的理解,但是,你要知道,DevOps 其实是敏捷开发向 IT 运维的自然延伸,它的原则和实践与_敏捷测试与传统测试的区别
VS2015中QT VS TOOLS Open Qt Project file 无反应报错Cannot run compiler 'cl'. Maybe you forgot to setup the_vs2015 qt tools 报错cmd32.exe-程序员宅基地
文章浏览阅读4.5k次。用VS2015中QT VS TOOLS 的Open Qt Project file 选项打开qt工程报错(Import): Generating new project of liteidex.pro file(qmake) : Using: C:\QT\QT5.9.1\5.9.1\MSVC2015\bin\qmake(qmake) : Working Directory: C:\_vs2015 qt tools 报错cmd32.exe
[leetcode] 173. Binary Search Tree Iterator_implement an iterator over a binary search tree (b-程序员宅基地
文章浏览阅读131次。DescriptionImplement an iterator over a binary search tree (BST). Your iterator will be initialized with the root node of a BST.Calling next() will return the next smallest number in the BST.Exampl..._implement an iterator over a binary search tree (bst)
小米OJ #18 帮小学生排队_在我家地下出现了h次数-程序员宅基地
文章浏览阅读562次。原题还蛮有意思的一道题,先要理解题目给的输入:h和k是一对一对给的,因此对每位小朋友位置进行变动的时候,h,k应是一起变动。(一开始理解成了h,k混着给,想了半天没想出思路)用两个数组同步保存h,k,再利用第三个数组保存h,k的索引。首先进行一次排序:h值大的在前;h值相同的,则k值更小的在前。随后可以发现,每对hk的正确位置应该是插入到 距离其当前位置向前(pos-k)个长度的位置。利..._在我家地下出现了h次数
aardio - 【库】zint生成二维码条形码_zint条码-程序员宅基地
文章浏览阅读762次,点赞3次,收藏5次。aardio-【库】zint生成二维码条形码_zint条码
库_计算机库-程序员宅基地
文章浏览阅读1.2k次。库【1】库的概念1.什么是库库是一个二进制可执行的文件。库需要被载入到内存中才能使用相比较可执行的二进制程序,库是不能单独运行的。windows和linux都有自己的库,不兼容的。2.库的分类1.动态库(共享库)2.静态库区分:通过库的后缀来区分库的类型windowslinux静态库*.lblibxxx.a动态库*.lldlibxxx.so3.库存在的意义库是已经写好的,成熟的,可以复用的代码。其实我们写的很多代码,都是依赖于基础库的,_计算机库
随便推点
(c++)vector——find方法的使用_vector find-程序员宅基地
文章浏览阅读3.9w次,点赞14次,收藏32次。## vector _find方法的使用 不同于map(map有find方法),vector本身是没有 find这一方法的,其find函数是依靠algorithm来实现的 所有要使用#include<algorithm> 例如:vector<int>::iterator it = find(vec.begin(),vec.end(),1); if(it != vec.end()) cout<<"found"<<endl; else _vector find
【STM32】EXTI---外部中断/事件控制器_stm32外部中断上升沿下降沿都触发 如何区分-程序员宅基地
文章浏览阅读5.4k次,点赞55次,收藏109次。EXTI——外部中断/事件控制器。外部中断简介,EXTI初始化结构体,外部中断控制实验。利用按键输入作为中断的外部输入,产生中断后,进入中断服务函数,实现LED状态的变化。_stm32外部中断上升沿下降沿都触发 如何区分
[vue3] error in ./node_modules/@vue/reactivity/dist/reactivity.esm-bundler.js-程序员宅基地
文章浏览阅读2.1k次,点赞10次,收藏8次。question使用vue-cli(4.5.13) create vue3(3.1.3)npm run servererrorerror in ./node_modules/@vue/reactivity/dist/reactivity.esm-bundler.jssolution1办法1: 编辑配置文件vue.config.js此办法不行// vue.config.jsmodule.exports = { transpileDependencies: ['@vue/reactivi_in ./node_modules/@vue/reactivity/dist/reactivity.esm-bundler.js
数据挖掘——数据采集和数据清洗_selenium 自动化数据采集和清洗-程序员宅基地
文章浏览阅读7.2k次,点赞12次,收藏63次。数据采集和数据清洗一、数据清洗1.数据去重(一)相关知识1> pandas读取csv文件-read_csv()2> pandas的去重函数-drop_duplicates()(二)本关任务(三)参考代码2.处理空值(一)相关知识1> DataFrame中空值的表示2> 查找空值及计算空值的个数3> 处理空值-fillna(二)本关任务(三)参考代码一、数据清洗1.数据去重(一)相关知识1> pandas读取csv文件-read_csv() _selenium 自动化数据采集和清洗
Visual.Assist.X.10.9.Build.2375.0 2020.05.16 最新版-程序员宅基地
文章浏览阅读2.2k次。Visual.Assist.X.10.9.Build.2375.0 2020.05.16 最新版,带特殊文件,解压后查看使用说明。 VC++编程助手,支持VS 2019,亲测可用。 共享备用。7zip压缩格式。没有7zip的解压时需要先下载7zip解压软件,免费的,很好用。下载地址:https://download.csdn.net/download/redleafe/12426530免费下载,0积分。...
灵魂拷问!程序猿老司机才知道的IT网站,你都知道几个?_拷问网战-程序员宅基地
文章浏览阅读2.6k次。 程序猿是这个世界上最神秘的职业之一,他们能够用最原始的文字符号,书写出最复杂的程序。因此他们自成圈子,交流、学习、分享、进阶都自成一“国”,渐渐的就成了外人眼里的沉默寡言。可是事实上,在你不知道的另一端,他们可劲的“浪”着呢~今天小泽就给大家介绍下国内外程序员们最爱逛的网站,上次华住资料泄露的事就是在这些网站里爆出来的呢~1、stackoverflow众所周知,stackover..._拷问网战