数学建模笔记CH3:线性代数方法建模_线性代数建模-程序员宅基地
CH3线性代数方法建模
overview
线性代数是以向量和矩阵为对象,以实向量空间为背景的一种抽象数学工具,它的应用遍及科学技术和国民经济各个领域。本篇通过基因遗传学、投入产出模型等几个例子阐述以线性代数为主要工具建立数学模型的一般方法和步骤。
3.1常染色体基因遗传
常染色体基因遗传中,后代是从每个亲本的基因对中各继承一个基因,形成自己的基因对。
模型一 植物基因的分布
植物基因对为AA、Aa、aa三种类型,设:
x 1 ( n ) x_1(n) x1(n):第n代植物中基因AA所占比例
x 2 ( n ) x_2(n) x2(n):第n代植物中基因Aa所占比例
x 3 ( n ) x_3(n) x3(n):第n代植物中基因aa所占比例
x ( n ) = ( x 1 ( n ) , x 2 ( n ) , x 3 ( n ) ) T , n = 0 , 1 , 2 , . . . x(n)=(x_1(n),x_2(n),x_3(n))^T,n=0,1,2,... x(n)=(x1(n),x2(n),x3(n))T,n=0,1,2,...
显然: x 1 ( n ) + x 2 ( n ) + x 3 ( n ) = 1 x_1(n)+x_2(n)+x_3(n)=1 x1(n)+x2(n)+x3(n)=1
由于后代是各从父代和母体的基因对中等可能地得到一个基因而形成自己的基因对,父代母代基因对和子代各基因对之间地转移概率如下表:
| 子代v父母> | AA-AA | AA-Aa | AA-aa | Aa-Aa | Aa-aa | aa-aa |
|---|---|---|---|---|---|---|
| AA | 1 | 1 2 \frac{1}{2} 21 | 0 | 1 4 \frac{1}{4} 41 | 0 | 0 |
| Aa | 0 | 1 2 \frac{1}{2} 21 | 1 | 1 2 \frac{1}{2} 21 | 1 2 \frac{1}{2} 21 | 0 |
| aa | 0 | 0 | 0 | 1 4 \frac{1}{4} 41 | 1 2 \frac{1}{2} 21 | 1 |
若使用AA型植物与其他基因植物相结合地方法培育后代,则有:
{ x 1 ( n ) = x 1 ( n − 1 ) + 1 2 x 2 ( n − 1 ) x 2 ( n ) = 1 2 + x 3 ( n − 1 ) x 3 ( n ) = 0................. ( 1 ) \small \begin{cases} x_1(n)=x_1(n-1)+\frac{1}{2}x_2(n-1)\\ x_2(n)=\frac{1}{2}+x_3(n-1)\\ x_3(n)=0 .................(1) \end{cases} ⎩⎨⎧x1(n)=x1(n−1)+21x2(n−1)x2(n)=21+x3(n−1)x3(n)=0.................(1)
令
L = ( 1 1 2 0 0 1 2 1 0 0 0 ) L= \begin{pmatrix} 1&\frac{1}{2}&0\\ 0&\frac{1}{2}&1\\ 0&0&0 \end{pmatrix} L=⎝⎛10021210010⎠⎞
则第n代与第n-1代植物基因型分布关系为:
x ( n ) = L x ( n − 1 ) , ( n = 1 , 2 , . . . ) ( 2 ) x(n)=Lx(n-1),(n=1,2,...) (2) x(n)=Lx(n−1),(n=1,2,...)(2)
由(2)得:
x ( n ) = L n x ( 0 ) , ( n = 1 , 2 , . . . ) ( 3 ) x(n)=L^nx(0),(n=1,2,...) (3) x(n)=Lnx(0),(n=1,2,...)(3)
将L对角化,求出L的特征值1、1/2、0对应的特征向量构成矩阵:
P = ( 1 1 1 0 − 1 − 2 0 0 1 ) P=\begin{pmatrix} 1&1&1\\ 0&-1&-2\\ 0&0&1 \end{pmatrix} P=⎝⎛1001−101−21⎠⎞
再求
P − 1 = ( 1 1 1 0 − 1 − 2 0 0 1 ) P^{-1}= \begin{pmatrix} 1&1&1\\ 0&-1&-2\\ 0&0&1 \end{pmatrix} P−1=⎝⎛1001−101−21⎠⎞
则:
L n = L ( 1 0 0 0 1 / 2 0 0 0 0 ) P − 1 = ( 1 1 − ( 1 2 ) n 1 − ( 1 2 ) n − 1 0 ( 1 2 ) n ( 1 2 ) n − 1 0 0 0 ) (4) L^n=L \begin{pmatrix} 1&0&0\\ 0&1/2&0\\ 0&0&0 \end{pmatrix}P^{-1} =\begin{pmatrix} 1&1-(\frac{1}{2})^n&1-(\frac{1}{2})^{n-1}\\ 0&(\frac{1}{2})^n&(\frac{1}{2})^{n-1}\\ 0&0&0 \end{pmatrix}\tag{4} Ln=L⎝⎛10001/20000⎠⎞P−1=⎝⎛1001−(21)n(21)n01−(21)n−1(21)n−10⎠⎞(4)
将(4)代入(3)可得:
{ x 1 ( n ) = x 1 ( 0 ) + [ 1 − ( 1 2 ) n ] x 2 ( 0 ) + [ 1 − ( 1 2 ) n − 1 ] x 3 ( 0 ) x 2 ( n ) = ( 1 2 ) n x 2 ( 0 ) + ( 1 2 ) n − 1 x 3 ( 0 ) x 3 ( n ) = 0 \small \begin{cases} x_1(n)=x_1(0)+[1-(\frac{1}{2})^n]x_2(0)+[1-(\frac{1}{2})^{n-1}]x_3(0)\\ x_2(n)=(\frac{1}{2})^nx_2(0)+(\frac{1}{2})^{n-1}x_3(0)\\ x_3(n)=0 \end{cases} ⎩⎨⎧x1(n)=x1(0)+[1−(21)n]x2(0)+[1−(21)n−1]x3(0)x2(n)=(21)nx2(0)+(21)n−1x3(0)x3(n)=0
所以,当 n → ∞ n\rightarrow \infty n→∞时,存在 x 1 ( n ) → 1 , x 2 ( n ) → 0 , x 3 ( n ) → 0 x_1(n)\rightarrow1,x_2(n)\rightarrow0,x_3(n)\rightarrow0 x1(n)→1,x2(n)→0,x3(n)→0,也就是说,培育的植物AA型基因所占的比例在不断增加,极限状态下所有植物的基因都是AA型。
模型二 常染色体遗传疾病
常染色体遗传疾病对应的基因型将人口分成三类。记
- AA型:正常人,
- Aa型:隐性患者,
- aa型:显性患者。
假设在开始时,AA,Aa,aa型基因的人所占比例为 a 0 , b 0 , c 0 a_0,b_0,c_0 a0,b0,c0; x 1 ( n ) , x 2 ( n ) , x 3 ( n ) x_1(n),x_2(n),x_3(n) x1(n),x2(n),x3(n)为第n代人口中所占的百分比。
控制结合
显性患者(aa)不能生育后代,隐形患者(Aa)必须与正常人(AA)结合才能剩余后代。
则从n=1开始就有 x 3 ( n ) = 0 x_3(n)=0 x3(n)=0,即不再有显性患者,而且:
{ x 1 ( n ) = x 1 ( n − 1 ) + 1 2 x 2 ( n − 1 ) x 2 ( n ) = 1 2 x 2 ( n − 1 ) ( n = 1 , 2 , . . . ) (1) \small \begin{cases} x_1(n)=x_1(n-1)+\frac{1}{2}x_2(n-1)\\ x_2(n)=\frac{1}{2}x_2(n-1) (n=1,2,...) \end{cases}\tag{1} {
x1(n)=x1(n−1)+21x2(n−1)x2(n)=21x2(n−1)(n=1,2,...)(1)
或:
( x 1 ( n ) x 2 ( n ) ) = ( 1 1 2 0 1 2 ) ( x 1 ( n − 1 ) x 2 ( n − 1 ) ) (2) \begin{pmatrix} x_1(n)\\ x_2(n) \end{pmatrix} =\begin{pmatrix} 1&\frac{1}{2}\\ 0&\frac{1}{2} \end{pmatrix} \begin{pmatrix} x_1(n-1)\\ x_2(n-1) \end{pmatrix}\tag{2} (x1(n)x2(n))=(102121)(x1(n−1)x2(n−1))(2)
递推得:
( x 1 ( n ) x 2 ( n ) ) = C n ( a 0 b 0 ) (3) \begin{pmatrix} x_1(n)\\ x_2(n) \end{pmatrix} =C^n \begin{pmatrix} a_0\\ b_0 \end{pmatrix}\tag{3} (x1(n)x2(n))=Cn(a0b0)(3)
由于:
( 1 1 2 0 1 2 ) n = ( 1 1 − ( 1 2 ) n 0 ( 1 2 ) n ) (4) {\begin{pmatrix} 1&\frac{1}{2}\\ 0&\frac{1}{2} \end{pmatrix}}^n =\begin{pmatrix} 1&1-(\frac{1}{2})^n\\ 0&(\frac{1}{2})^n \end{pmatrix}\tag{4} (102121)n=(101−(21)n(21)n)(4)
可得:
{ x 1 ( n ) = a 0 + [ 1 − ( 1 2 ) n ] b 0 x 2 ( n ) = ( 1 2 ) n b 0 ( n = 1 , 2 , . . . ) (5) \small \begin{cases} x_1(n)=a_0+[1-(\frac{1}{2})^n]b_0\\ x_2(n)=(\frac{1}{2})^nb_0 (n=1,2,...) \end{cases}\tag{5} {
x1(n)=a0+[1−(21)n]b0x2(n)=(21)nb0(n=1,2,...)(5)
可见在控制结合的方案下,隐形及那个逐渐消失。
自由结合
三种基因的人任意结合生育后代(假设男女比例为1:1)
记:
A 1 : 父 代 为 A A , B 1 : 母 代 为 A A , C 1 : 子 代 为 A A A_1:父代为AA,B_1:母代为AA,C_1:子代为AA A1:父代为AA,B1:母代为AA,C1:子代为AA
A 2 : 父 代 为 A a , B 2 : 母 代 为 A a , C 2 : 子 代 为 A a A_2:父代为Aa,B_2:母代为Aa,C_2:子代为Aa A2:父代为Aa,B2:母代为Aa,C2:子代为Aa
A 3 : 父 代 为 a a , B 3 : 母 代 为 a a , C 3 : 子 代 为 a a A_3:父代为aa,B_3:母代为aa,C_3:子代为aa A3:父代为aa,B3:母代为aa,C3:子代为aa
记 p ( A i B j ) = p ( A i ) p ( B j ) = x i ( n − 1 ) x j ( n − 1 ) ( i , j = 1 , 2 , 3 ) p(A_iB_j)=p(A_i)p(B_j)=x_i(n-1)x_j(n-1)(i,j=1,2,3) p(AiBj)=p(Ai)p(Bj)=xi(n−1)xj(n−1)(i,j=1,2,3)
则由全概率公式可得: p ( C k ) = x k ( n ) = ∑ i = 1 3 ∑ j = 1 3 p ( A i B j ) p ( C k ∣ A i B j ) ( k = 1 , 2 , 3 ) p(C_k)=x_k(n)=\sum_{i=1}^{3}\sum_{j=1}^{3}p(A_iB_j)p(C_k|A_iB_j) (k=1,2,3) p(Ck)=xk(n)=∑i=13∑j=13p(AiBj)p(Ck∣AiBj)(k=1,2,3)
代入后可得:
{ x 1 ( n ) = ( x 1 ( n − 1 ) + 1 2 x 2 ( n − 1 ) ) x 1 ( n − 1 ) + ( x 1 ( n − 1 ) + 1 2 x 2 ( n − 1 ) ) 1 2 x 2 ( n − 1 ) x 2 ( n ) = ( 1 2 x 2 ( n − 1 ) + x 3 ( n − 1 ) ) x 1 ( n − 1 ) + 1 2 ( x 1 ( n − 1 ) + x 2 ( n − 1 ) + x 3 ( n − 1 ) ) x 2 ( n − 1 ) + ( x 1 ( n − 1 ) + 1 2 x 2 ( n − 1 ) ) x 3 ( n − 1 ) x 3 ( n ) = 1 2 ( 1 2 x 2 ( n − 1 ) + x 3 ( n − 1 ) ) x 2 ( n − 1 ) + ( x 3 ( n − 1 ) + 1 2 x 2 ( n − 1 ) ) x 3 ( n − 1 ) (6) \small \begin{cases} x_1(n)=(x_1(n-1)+\frac{1}{2}x_2(n-1))x_1(n-1)+(x_1(n-1)+\frac{1}{2}x_2(n-1))\frac{1}{2}x_2(n-1)\\ x_2(n)=(\frac{1}{2}x_2(n-1)+x_3(n-1))x_1(n-1)+\frac{1}{2}(x_1(n-1)+x_2(n-1)+x_3(n-1))x_2(n-1)+(x_1(n-1)+\frac{1}{2}x_2(n-1))x_3(n-1)\\ x_3(n)=\frac{1}{2}(\frac{1}{2}x_2(n-1)+x_3(n-1))x_2(n-1)+(x_3(n-1)+\frac{1}{2}x_2(n-1))x_3(n-1) \end{cases}\tag{6} ⎩⎨⎧x1(n)=(x1(n−1)+21x2(n−1))x1(n−1)+(x1(n−1)+21x2(n−1))21x2(n−1)x2(n)=(21x2(n−1)+x3(n−1))x1(n−1)+21(x1(n−1)+x2(n−1)+x3(n−1))x2(n−1)+(x1(n−1)+21x2(n−1))x3(n−1)x3(n)=21(21x2(n−1)+x3(n−1))x2(n−1)+(x3(n−1)+21x2(n−1))x3(n−1)(6)
化简得:
{ x 1 ( n ) = x 1 2 ( n − 1 ) + x 1 ( n − 1 ) x 2 ( n − 1 ) + 1 4 x 2 2 ( n − 1 ) x 2 ( n ) = x 1 ( n − 1 ) x 2 ( n − 1 ) + 2 x 1 ( n − 1 ) x 3 ( n − 1 ) + x 2 ( n − 1 ) x 3 ( n − 1 ) + 1 2 x 2 2 ( n − 1 ) x 3 ( n ) = x 3 2 ( n − 1 ) + x 2 ( n − 1 ) x 3 ( n − 1 ) + 1 4 x 2 2 ( n − 1 ) (7) \small \begin{cases} x_1(n)=x_1^2(n-1)+x_1(n-1)x_2(n-1)+\frac{1}{4}x_2^2(n-1)\\ x_2(n)=x_1(n-1)x_2(n-1)+2x_1(n-1)x_3(n-1)+x_2(n-1)x_3(n-1)+\frac{1}{2}x_2^2(n-1)\\ x_3(n)=x_3^2(n-1)+x_2(n-1)x_3(n-1)+\frac{1}{4}x_2^2(n-1) \end{cases}\tag{7} ⎩⎨⎧x1(n)=x12(n−1)+x1(n−1)x2(n−1)+41x22(n−1)x2(n)=x1(n−1)x2(n−1)+2x1(n−1)x3(n−1)+x2(n−1)x3(n−1)+21x22(n−1)x3(n)=x32(n−1)+x2(n−1)x3(n−1)+41x22(n−1)(7)
记 p = a 0 + b 0 2 , q = c 0 b 0 2 p=a_0+\frac{b_0}{2},q=c_0\frac{b_0}{2} p=a0+2b0,q=c02b0,从n=1开始递推得:
{ x 1 ( 1 ) = a 0 2 + a 0 b 0 + 1 4 b 0 2 = p 2 x 2 ( 1 ) = a 0 b 0 + 2 a 0 c 0 + b 0 c 0 + 1 2 b 0 2 = 2 p q x 3 ( 1 ) = c 0 2 + b 0 c 0 + 1 4 b 0 2 = q 2 (8) \small \begin{cases} x_1(1)=a_0^2+a_0b_0+\frac{1}{4}b_0^2=p^2\\ x_2(1)=a_0b_0+2a_0c_0+b_0c_0+\frac{1}{2}b_0^2=2pq\\ x_3(1)=c_0^2+b_0c_0+\frac{1}{4}b_0^2=q^2 \end{cases}\tag{8} ⎩⎨⎧x1(1)=a02+a0b0+41b02=p2x2(1)=a0b0+2a0c0+b0c0+21b02=2pqx3(1)=c02+b0c0+41b02=q2(8)
{ x 1 ( 2 ) = p 2 ( p 2 + 2 p q + q 2 ) = p 2 x 2 ( 2 ) = 2 p q ( p 2 + 2 p q + q 2 ) = 2 p q x 3 ( 2 ) = q 2 ( p 2 + 2 p q + q 2 ) = q 2 (9) \small \begin{cases} x_1(2)=p^2(p^2+2pq+q^2)=p^2\\ x_2(2)=2pq(p^2+2pq+q^2)=2pq\\ x_3(2)=q^2(p^2+2pq+q^2)=q^2 \end{cases}\tag{9} ⎩⎨⎧x1(2)=p2(p2+2pq+q2)=p2x2(2)=2pq(p2+2pq+q2)=2pqx3(2)=q2(p2+2pq+q2)=q2(9)
说明以后各代中基因得分布永远是 p 2 , 2 p q , q 2 p^2,2pq,q^2 p2,2pq,q2,三类人的比例不变.
3.4层次分析法
背景
某些问题的一个共同特点是它们都通常涉及到经济、社会、人文等方面的因素。在作比较、判断、评价、决策时,这些因素的重要性、影响力或者优先程度往往难以量化,人的主观选择会起着相当重要的作用,这就给用一般的数学方法(机理分析和统计分析)解决问题带来本质上的困难。例如:
- 国家综合实力分析需要考虑到国民收入、军事、科技、社会稳定、外贸等方面的因素
- 资源开发的综合判断需要考虑潜在经济价值、开采费用、风险、需求、战略重要性、交通条件等因素
- 大学生毕业工作选择需要考虑贡献、收入、发展、声誉、关系、位置等因素
- 科技成果的综合评价
*层次分析法(简记AHP)*是一种定性和定量相结合的,系统化,层次化的分析方法,由T.L.Saaty等人在七十年代提出,是一种能有效地处理这样一类问题的实用方法。从处理问题的类型上分类,主要是决策、评价、分析、预测等。
AHP的基本步骤
1.建立层次结构模型
在深入分析实际问题的基础上,将有关的各个因素按不同属性自上而下地分解成若干层次。同一层次的诸因素从属于上一层的因素或对上层因素有影响,同时又支配下一层的因素或受下层因素的作用,最上层为目标层,最下层为方案层,中间可有1个或几个层次,称为准则层。
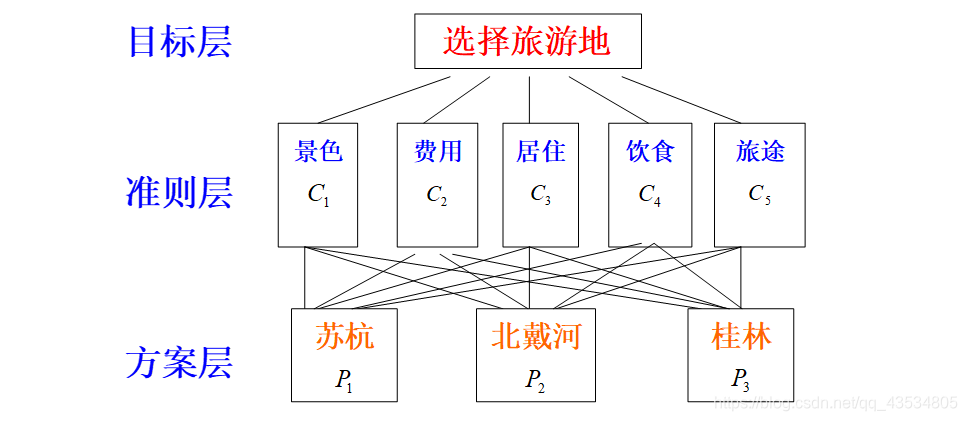
2.构成对比较矩阵
从层次结构模型的第二层开始,对于从属于上一层每个因素的同一层诸因素,用成对比较法和1-9比较尺度构造成对比较阵,直到最下层。
例如要比较 C 1 , C 2 , C 3 , . . . , C n C_1,C_2,C_3,...,C_n C1,C2,C3,...,Cn对上层因素O的影响,每次取两个因素 C i , C j C_i,C_j Ci,Cj,用 a i j a_{ij} aij表示 C i , C j C_i,C_j Ci,Cj对O的影响之比。所有的比较结果用比较矩阵 A = ( a i j ) n × n , a i j > 0 , a j i = 1 a i j A=(a_{ij})_{n\times n},a_{ij}>0,a_{ji}=\frac{1}{a_{ij}} A=(aij)n×n,aij>0,aji=aij1来表示,这里的 a i j a_{ij} aij是相对比较尺度,其含义为:
| 尺度 a i j a_{ij} aij | 含义 |
|---|---|
| 1 | C i C_i Ci对 C j C_j Cj的影响相同 |
| 3 | C i C_i Ci对 C j C_j Cj的影响稍强 |
| 5 | C i C_i Ci对 C j C_j Cj的影响强 |
| 7 | C i C_i Ci对 C j C_j Cj的影响明显地强= |
| 9 | C i C_i Ci对 C j C_j Cj的影响绝对地强 |
| 2,4,6,8 | C i C_i Ci对 C j C_j Cj的影响之比在上述两相邻等级之间 |
3.计算权向量并作一致向检验
对于承兑比较矩阵A,应满足 a i j ⋅ a j k = a i k ( i , j , k = 1 , 2 , 3 , . . . , n ) a_{ij}\cdot a_{jk}=a_{ik}(i,j,k=1,2,3,...,n) aij⋅ajk=aik(i,j,k=1,2,3,...,n),则称A为一致性矩阵,有如下性质:
- 1.rank A=1,A的唯一非零特征根为n
- 2.A的任一列向量都是对应于特征根n的特征向量
因此自然应取对应特征根n的,归一化的特征向量(即分量之和为1)表示诸因素 C 1 , C 2 , C 3 , . . . , C n C_1,C_2,C_3,...,C_n C1,C2,C3,...,Cn对上层因素O的权重,这个特征向量称为权向量。
一般成对比较矩阵不容易做到完全一致,因为矩阵A的特征根和特征向量连续地依赖于矩阵的元素 a i j a_{ij} aij,所以当 a i j a_{ij} aij离一致性的要求不远时,A的特征根和特征向量也与一致阵相差不大,Saaty等人建议,如果成对比较阵A不是一致阵,但在不一致的容许范围内,仍可以用对应于A的最大特征根 λ \lambda λ的特征向量(归一化)作为权向量W。
要确定A的不一致程度的容许范围,就要进行一致性检验,其步骤为:
- 1.计算一致性指标 C I = λ − n n − 1 CI=\frac{\lambda-n}{n-1} CI=n−1λ−n;
- 2.查下表得出随机一致向指标RI的数值:
n 1 2 3 4 5 6 7 8 9 10 11 RI 0 0 0.58 0.90 1.12 1.24 1.32 1.41 1.45 1.49 1.51 - 3
- 对 n ≥ 3 n\ge3 n≥3,计算一致性比率 C R = C I R I CR=\frac{CI}{RI} CR=RICI;
- 对 C R < 0.1 CR<0.1 CR<0.1,认为A的不一致程度在容许范围内,可以用其特征向量作为权向量,否则就要从小构造对比矩阵。
4.计算组合权向量并做组合一致性检验
由各准则对目标的权向量 W ( 2 ) W^{(2)} W(2)和各方案对于每个准则的权向量 W k ( 3 ) ( k = 1 , 2 , . . . , n ) W_k^{(3)}(k=1,2,...,n) Wk(3)(k=1,2,...,n),计算各方案对目标的权向量 W ( 3 ) W^{(3)} W(3),称为组合权向量,计算方法如下:
以 W k ( 3 ) W_k^{(3)} Wk(3)为列向量构成矩阵 W ( 3 ) = [ W 1 ( 3 ) , W 2 ( 3 ) , . . . , W n ( 3 ) ] W^{(3)}=[W_1^{(3)},W_2^{(3)},...,W_n^{(3)}] W(3)=[W1(3),W2(3),...,Wn(3)],则第三次对第一层的组合权向量 W ( 3 ) W^{(3)} W(3)为 W ( 3 ) = W ( 3 ) W ( 2 ) W^{(3)}=W^{(3)}W^{(2)} W(3)=W(3)W(2)。
在层次分析的整个计算过程中,除了对每个成对比较阵进行一致性检验,以判断每个权向量是否可以应用外,还应对最后结果进行组合一致性检验,以确定组合权向量是否可以作为最终的决策依据。
3.6 CT图像重建
CT,即计算机断层成像技术(Computer Tomography),亦称计算机辅助断层扫描CAT-Scanner。
CT原理
拍X光片是将三维对象(立体)显示在二维的胶片或荧光屏上,待检测物体与胶片平行,X射线垂直投射到胶片上,这样,在深度方向的信息重叠在一起,混淆不清。另外,由于胶片的密度分辩力低,不能区分软组织的细节,只能区分密度差别大的内脏器官,影响了诊断的效力。CT的创立,解决了这个问题。它不同于传统的X射线,它的X射线束位于待检测物体的横截面内,X射线源发射出极细的笔束X射线,在其对面放置一检测器,测量出X射线源发出的射线的强度 I 0 I_0 I0 ,以及经过物体衰减后达到检测器的X射线强度 I I I,然后,将X射线源与检测器在观测平面内不断同步改变位置(平移或旋转),得到关于X射线强度 I I I的若干组数据(可以是几万组甚至几十万组)。
建模
如果物体是均匀的,物体对于X射线的衰减系数为常数。假设强度为 I 0 I_0 I0的射线在物体中行进距离x后衰减至 I 0 I_0 I0,由Beer定理:
I = I 0 e − μ x 或 μ x = l n ( I 0 I ) ( 1 ) I=I_0e^{-\mu x}或\mu x=ln(\frac{I_0}{I}) (1) I=I0e−μx或μx=ln(II0)(1)
但是若物体在待测的xy平面内是不均匀的,则 μ = μ ( x , y ) \mu=\mu(x,y) μ=μ(x,y)。此时X射线在某一方向沿某一路径 L 0 L_0 L0的总衰减可以用线积分表示:
∫ L μ d l = l n ( I 0 I ) ( 2 ) \int_L\mu dl=ln(\frac{I_0}{I}) (2) ∫Lμdl=ln(II0)(2)
(2)称为射线投影。若未指明路径L,即 ∫ μ d l \int\mu dl ∫μdl,则称为投影,投影式一组谁先按投影的集合。
CT图像重建要做的就是根据一系列 I 0 I_0 I0和 I I I来求 μ = μ ( x , y ) \mu=\mu(x,y) μ=μ(x,y),求出来是一个离散的二元函数,然后数模转换器可以将这个函数转换为图像信号,这个过程就是投影重建图像。
投影重建技术的方法包括反投影重建算、滤波重建算法、迭代重建算法,这里介绍迭代重建算法。
将待测物体的截面分成许多边长为 δ \delta δ的小正方形,每个小正方形称为一个像元。设一束宽为 δ \delta δ的射线,平行于像元的边,穿过整个像元。X射线中的光子以一定的速率被像元内的组织吸收,其速率正比于组织的X射线密度(线性衰弱系数)。记第j个像元的X射线密度为 x j x_j xj,定义:
x j = l n 进 入 第 j 个 像 元 的 光 子 数 目 离 开 第 j 个 像 元 的 光 子 数 目 = − l n ( 穿 过 第 j 个 像 元 而 未 被 吸 收 的 光 子 所 占 百 分 比 ) x_j=ln\frac{进入第j个像元的光子数目}{离开第j个像元的光子数目}=-ln(穿过第j个像元而未被吸收的光子所占百分比) xj=ln离开第j个像元的光子数目进入第j个像元的光子数目=−ln(穿过第j个像元而未被吸收的光子所占百分比)
如果第i束X射线穿过由有k个像元组成的一行像元,那么第i束X射线经过这行像元未被吸收的百分比=第i束X射线经过待检测物体的截面而未被吸收的百分比。
记: b i = l n 第 i 束 射 线 未 经 过 待 检 测 截 面 进 入 检 测 器 的 光 子 数 目 第 i 束 射 线 经 过 待 测 截 面 进 入 检 测 器 的 光 子 数 目 = − l n ( 第 i 束 射 线 经 过 待 检 测 截 面 后 未 被 吸 收 的 光 子 的 百 分 比 ) b_i=ln\frac{第i束射线未经过待检测截面进入检测器的光子数目}{第i束射线经过待测截面进入检测器的光子数目}=-ln(第i束射线经过待检测截面后未被吸收的光子的百分比) bi=ln第i束射线经过待测截面进入检测器的光子数目第i束射线未经过待检测截面进入检测器的光子数目=−ln(第i束射线经过待检测截面后未被吸收的光子的百分比)
称为第i束X射线的密度,从而:
x 1 + x 2 + . . . + x k = b i ( 3 ) x_1+x_2+...+x_k=b_i (3) x1+x2+...+xk=bi(3)
式中的 b i b_i bi可以测量,而 x 1 , x 2 , . . . , x k x_1,x_2,...,x_k x1,x2,...,xk是未知的。
将待测的截面分别成 N = n 2 N=n^2 N=n2个像元,其标号由1~N,第i束X射线穿过n个像元组成的一行像元,这些像元记为 j 1 , j 2 , . . . , j n j_1,j_2,...,j_n j1,j2,...,jn,则(3)可写为:
x j 1 + x j 2 + . . . + x j n = b i ( 4 ) x_{j_1}+x_{j_2}+...+x_{j_n}=b_i (4) xj1+xj2+...+xjn=bi(4)
令
a i j = { 1 , 若 j = j 1 , j 2 , . . . j n 0 , 其 他 \small a_{ij}= \begin{cases} 1,若j=j_1,j_2,...j_n\\ 0,其他\\ \end{cases} aij={
1,若j=j1,j2,...jn0,其他
则(4)可写成线性方程组 a i 1 x 1 + a i 2 x 2 + . . . + a i N x N = b i , i = 1 , 2 , . . . , M ( 5 ) a_{i1}x_1+a_{i2}x_2+...+a_{iN}x_N=b_i,i=1,2,...,M (5) ai1x1+ai2x2+...+aiNxN=bi,i=1,2,...,M(5)
其中M为射线数目,称(5)为第i束X射线的方程,矩阵 A = ( a i j ) M × N A=(a_{ij})_{M\times N} A=(aij)M×N称为投影矩阵。
然而,一束射线并不一定沿平行于像元的方向穿过像元,因而需要对(5)中 a i j a_{ij} aij的值进行修正,常用如下方法:
- (1)像元中心法:
a i j = { 1 , 若 第 i 束 射 线 经 过 第 j 个 像 元 的 中 心 0 , 其 他 (6) \small a_{ij}= \begin{cases} 1,若第i束射线经过第j个像元的中心\\ 0,其他 \end{cases}\tag{6} aij={ 1,若第i束射线经过第j个像元的中心0,其他(6) - (2)中心线法: a i j = 第 i 束 射 线 的 中 心 线 位 于 第 j 个 像 元 内 的 长 度 第 j 个 像 元 内 的 长 度 = 1 δ ( 7 ) a_{ij}=\frac{第i束射线的中心线位于第j个像元内的长度}{第j个像元内的长度}=\frac{1}{\delta} (7) aij=第j个像元内的长度第i束射线的中心线位于第j个像元内的长度=δ1(7)
- (3)面积法: a i j = 第 i 束 射 线 位 于 第 j 个 像 元 内 的 面 积 第 i 束 射 线 若 平 行 于 像 元 变 穿 过 第 j 个 像 元 时 位 于 第 j 个 像 元 内 的 面 积 ( 8 ) a_{ij}=\frac{第i束射线位于第j个像元内的面积}{第i束射线若平行于像元变穿过第j个像元时位于第j个像元内的面积} (8) aij=第i束射线若平行于像元变穿过第j个像元时位于第j个像元内的面积第i束射线位于第j个像元内的面积(8)
假设共有M束射线,N个像元,利用三种方法中的一种选择 a i j a_{ij} aij,可以得到一个含有N个未知数,M个方程的线性方程组:
∑ j = 1 N a i j x j = b i , i = 1 , 2 , . . . , M ( 9 ) \sum_{j=1}^{N}a_{ij}x_j=b_i,i=1,2,...,M (9) ∑j=1Naijxj=bi,i=1,2,...,M(9)
实际的CT设备中, N = 80 × 80 ; 320 × 320 N=80\times80;320\times320 N=80×80;320×320d等,M=28800;184300等。
(9)可能有解,可能无解;有解时也可能由无穷多组解。从客观实际的角度出发,(9)应该有解。由于模型是由实际问题经过若干近似抽象而来的,数据又是测量得到的,误差不可避免,因此可能出现无解的情况。故把(9)写成:
A x + e = b ( 10 ) Ax+e=b (10) Ax+e=b(10)
其中,e为误差向量。
第j个像元内的面积} (8)$
假设共有M束射线,N个像元,利用三种方法中的一种选择 a i j a_{ij} aij,可以得到一个含有N个未知数,M个方程的线性方程组:
∑ j = 1 N a i j x j = b i , i = 1 , 2 , . . . , M ( 9 ) \sum_{j=1}^{N}a_{ij}x_j=b_i,i=1,2,...,M (9) ∑j=1Naijxj=bi,i=1,2,...,M(9)
实际的CT设备中, N = 80 × 80 ; 320 × 320 N=80\times80;320\times320 N=80×80;320×320d等,M=28800;184300等。
(9)可能有解,可能无解;有解时也可能由无穷多组解。从客观实际的角度出发,(9)应该有解。由于模型是由实际问题经过若干近似抽象而来的,数据又是测量得到的,误差不可避免,因此可能出现无解的情况。故把(9)写成:
A x + e = b ( 10 ) Ax+e=b (10) Ax+e=b(10)
其中,e为误差向量。
由于矩阵A的元素很多,又有许多元素为零,用消元法来解很费时,在CT中用迭代法求解。它的思想是:先建立一个判据,即接受的标准,选择一个解的初始值,若它符合判据,则接受为解,若达不到要求,则按一定的方法对原值加以修正,通过不断的迭代,直到可以接受为解为止。
智能推荐
nyoj5 Binary String Matching 查子串个数 strstr函数模板题_nyoj5串匹配-程序员宅基地
文章浏览阅读1.5k次。Binary String Matching时间限制:3000 ms | 内存限制:65535 KB难度:3描述Given two strings A and B, whose alphabet consist only ‘0’ and ‘1’. Your task is only to tell how many times does A appear as a substring of B..._nyoj5串匹配
《数据分析与挖掘 第十四章 基于基站定位数据的商圈分析》_基于基站定位数据的商圈分析 scala-程序员宅基地
文章浏览阅读1.4k次。基于基站定位数据的商圈分析数据抽取以2014-1-1开始到2014-6-30结束时间作为分析窗口数据分析以55555这个人为例,判断其活动位置,基站号改变,说明其进入下一个区域,分析出2014-1-1下午零时53分进入36902基站,直到二时13分才进入36907基站,说明他在36902基站呆了80分钟数据预处理首先,去掉无用的属性,例如什么信令类型,LOC编号这些的,只留下日期,时间..._基于基站定位数据的商圈分析 scala
【技术分享】针对SOAP的渗透测试与防护_available soap services 漏洞-程序员宅基地
文章浏览阅读2.2k次,点赞3次,收藏2次。本文翻译自:https://blog.securelayer7.net/owasp-top-10-penetration-testing-soap-application-mitigation/SOAP概述简单对象访问协议(SOAP)是连接或Web服务或客户端和Web服务之间的接口。SOAP通过应用层协议(如HTTP,SMTP或甚至TCP)进行操作,用于消息传输。图1 SOAP操..._available soap services 漏洞
GB∕T 33171-2016 城市交通运行状况评价规范_城市交通运行状况评价规范 下载-程序员宅基地
文章浏览阅读407次,点赞5次,收藏8次。标准号:GB/T 33171-2016中文标准名称:城市交通运行状况评价规范 英文标准名称:Specification for urban traffic performance evaluation_城市交通运行状况评价规范 下载
ROS1与ROS2的bag包互换(包含自定义消息)_ros2的rosbag可以用ros1播放么-程序员宅基地
文章浏览阅读7.3k次,点赞8次,收藏48次。https://blog.csdn.net/shanpenghui/article/details/117282535https://blog.csdn.net/weixin_37532614/article/details/109602947https://blog.csdn.net/weixin_41010198/article/details/117042386_ros2的rosbag可以用ros1播放么
Python报错:RuntimeError: one of the variables needed for gradient computation has been modified by_python runtimeerror: one of the variables needed f-程序员宅基地
文章浏览阅读978次。Python报错:RuntimeError: one of the variables needed for gradient computation has been modified by_python runtimeerror: one of the variables needed for gradient computation ha
随便推点
华为云鲲鹏服务器安装gogs_kunpeng golang镜像-程序员宅基地
文章浏览阅读922次。部署环境名称类型服务器华为云鲲鹏服务器系统版本CentOS 7.6 64bit with ARM安装gogs安装gityum install git -y下载gogs的armv8版本 gogs_0.12.3_linux_armv8.tar.gz 上传到服务器上解压gogs_0.12.3_linux_armv8.tar.gztar -zxvf gogs_0.12.3_linux_armv8.tar.gz进入到对应目录cd gogs后台_kunpeng golang镜像
打表法-程序员宅基地
文章浏览阅读4.8k次,点赞9次,收藏24次。今天见到了传说中的打表法,有人说这是流氓算法,但是我觉得这个也是非常牛逼的。下面就来说说这个打表法把,打表法对于某些用时较长的题目非常的有用。就是将我们要的结果打印到一个文本文档中,然后直接调用这个结果就可以了。在编译的时候就不用再程序里面计算,这样就省了很多时间,。是不是非常的牛逼呢,哈哈程序如下;#include<iostream>#include<..._打表法
Ribbon实战与原理剖析_ribbon原理-程序员宅基地
文章浏览阅读2.3k次,点赞2次,收藏11次。通过实现IRule接口可以自定义负载策略,主要的选择服务逻辑在 choose 方法中。}_ribbon原理
Centos 安装GPU并行lammps_centos lammps gpu-程序员宅基地
文章浏览阅读6.1k次,点赞6次,收藏16次。以下描述了如何在Centos服务器上安装GPU版本的lammps。安装环境目标属性系统Linux/CentOS 7.6CPU12*Intel Xeon CPU E5-2609 v3 @ 1.90GHzGPU2*NVIDIA Tesla K80/CUDA 8.0安装准备1. CUDA由于是安装GPU版本lammps,首先应确保系统安装有显卡所对..._centos lammps gpu
小米HR:说说对API有多少的理解? 看了后,和面试官扯皮,吹牛逼!绰绰有余!_能直接温hr是不是刷api的吗-程序员宅基地
文章浏览阅读2.9k次,点赞4次,收藏32次。目录什么是API?什么是API测试API测试的测试用例:API测试方法:如何进行API测试API测试的最佳做法:API测试检测到的错误类型API测试工具API测试的挑战结论:最后什么是API?API(全称Application Programming Interface)是两个单独的软件系统之间的通信和数据交换。实现API的软件系统包含可以由另一个软件系统执行的功能/子例程。什么是API测试API测试是一种用于验证API(应用程序编程接口)的._能直接温hr是不是刷api的吗
Android开发 入门篇(二) - 常用UI控件_能(textview、edittext、button、progressbar、alertdialog-程序员宅基地
文章浏览阅读915次,点赞2次,收藏7次。date: 2020-01-12 21:46:05文章目录控件ButtonTextViewEditTextImageViewProgressBarAlertDialogProgressDialog布局LenearLayoutandroid:layout_gravityandroid:layout_weightRelativeLayoutFrameLayout百分比布局其他自定义控件ListVie..._能(textview、edittext、button、progressbar、alertdialog、progressdialog、lis