机器学习之 数据预处理 preprocessing_state_preprocessing-程序员宅基地
技术标签: 机器学习
数据归一化及两种常用归一化方法
min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 , 1]之间。转换函数如下:
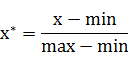
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
min-max标准化python代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Z-score标准化方法
也称为均值归一化(mean normaliztion), 给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1。转化函数为:
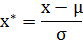
其中 μ 为所有样本数据的均值, σ 为所有样本数据的标准差。














智能推荐
oracle去重差个数,多表查询 - Oracle 查询技巧与优化_数据库技术_Linux公社-Linux系统门户网站...-程序员宅基地
文章浏览阅读254次。前言上一篇blog介绍了Oracle中的单表查询和排序的相关技巧,本篇blog继续介绍查询中用的最多的——多表查询的技巧与优化方式,下面依旧通过一次例子看一个最简单的多表查询。多表查询上一篇中提到了学生信息表的民族代码(mzdm_)这个字段通常应该关联字典表来查询其对应的汉字,实际上我们也是这么做的,首先简单看一下表结构,首先是字典表:如上图,可以看到每个民族代码和名称都是由两个字段——“item..._oracle 统计去重后的数量优化
基于51单片机的门锁系统_基于c51单片机的指纹锁的设计的主函数怎么写-程序员宅基地
文章浏览阅读5.4k次,点赞25次,收藏103次。8051单片机按键门锁系统概述设计思想仿真原理图代码展示main.ckeys.hkeys.clcd.hlcd.cdelay.hdelay.c说明实例图片概述本人纯属小白,无聊就想着做一个密码锁,由于知识的不足,以及制作是间断周期性的,所以有一些bug,有些也不够想法完善,但还是要把这些记录下来,也算是给自己的一个交代。设计思想以89c51单片机作为核心,4*4矩阵键盘输入,lcd1602输出,舵机作为机械动作。实现交互,密码的输入,显示,修改,提示,开门动作。代码分为以下四部分:LCD库 :端口_基于c51单片机的指纹锁的设计的主函数怎么写
Lua使用 lua_shared_dict 共享内存和进程间变量、lua脚本中实现美化打印显示table的函数、以及Nginx服务器非覆盖安装lua扩展的方法-程序员宅基地
文章浏览阅读417次,点赞18次,收藏13次。共享内存就是在内存块中分配出一个空间,让几个不相干的进程都能访问存储在这里面的变量数据,实际我们用过的redis,memcache也具有共享内存的意义,redis,memcache等是更高级的可跨服务器的共享内存,在lua中使用共享内存也非常简单。语法:lua_shared_dict 意义:定义一块名为name的共享内存空间,内存大小为size。_lua_shared_dict
[原创]VMware Workstation 14.1.3 Pro安装CentOS_7.6.1810-程序员宅基地
文章浏览阅读38次。【原文链接】:https://blog.tecchen.xyz ,博文同步发布到博客园。由于精力有限,对文章的更新可能不能及时同步,请点击上面的原文链接访问最新内容。欢迎访问我的个人网站:https://www.tecchen.xyz 。前言Linux作为最主流的服务器操作系统,在市场上的使用占比保持着领先对位。其中CentOS作为基于Red Hat Linux 提供的可自由使用..._vmware pro 14.1.3 csdn下载
【完美解决系列】duplicate entry: com/google/gson/annotations/Expose.class-程序员宅基地
文章浏览阅读1.1w次,点赞8次,收藏5次。项目在引入Retrofit2时,运行项目时会报出以下错误:Error:Execution failed for task ':app:transformClassesWithJarMergingForDebug'.> com.android.build.api.transform.TransformException: java.util.zip.ZipException: duplicate e_duplicate entry: com/
Android开发规范,性能优化-程序员宅基地
文章浏览阅读3.7k次。本文带您全面了解Android开发规范,其中包括Android编码规范,Android性能优化和Android UI优化,读完绝对不会后悔的好文章。一、Android编码规范1.java代码中不出现中文,最多注释中可以出现中文2.局部变量命名、静态成员变量命名只能包含字母,单词首字母出第一个外,都为大写,其他字母都为小写
随便推点
mybatis JdbcTypeInterceptor - 运行时自动添加 jdbcType 属性-程序员宅基地
文章浏览阅读130次。上代码:package tk.mybatis.plugin;import org.apache.ibatis.executor.ErrorContext;import org.apache.ibatis.executor.parameter.ParameterHandler;import org.apache.ibatis.mapping.BoundSql;impo..._mybatis 增加 jdbctype
ONL(open network linux) from OCP-程序员宅基地
文章浏览阅读169次。https://opennetlinux.org/github:https://github.com/OpenComputeProject/OpenNetworkLinuxOpen Network Linuxis a Linux distribution for "bare metal" switches, that is, network forwarding devices buil..._open network linux
请注意,这不是自动驾驶汽车,这是一艘机器人帆船-程序员宅基地
文章浏览阅读99次。Saildrone机器人帆船驶进了白令海峡,它们的任务是统计鱼的数量,具体来说,是统计黑线鳕鱼的数量。现在的硅谷,至少有20家公司正在追寻着自己的自动驾驶汽车梦,但梦想并没有实现。不过,自动驾驶帆船却已经实实在在地落地了。Saildrone是一家提供水上无人机服务的公司,公司于2012年在加利福尼亚阿拉米达市成立。公司的主要业务是通过水上无人机...
Android开发指南-窗口小部件_android 开发权威指南 小部件-程序员宅基地
文章浏览阅读585次。http://dev.10086.cn/cmdn/wiki/index.php?doc-view-2228.htmlAndroid开发指南-窗口小部件(App Widgets) 目录1 应用程序窗口小部件App Widgets 2 基础知识The Basics 3 在清单中声明一个应用小部件 4 增加AppWidgetProv_android 开发权威指南 小部件
最热开源项目,以及java基础整理_软件java项目最热算法?-程序员宅基地
文章浏览阅读186次。1、halo,这是一个轻快,简洁,功能强大,使用Java开发的博客系统。项目地址:https://github.com/halo-dev/halo Star 61392、jeecg-boot项目地址:https://github.com/zhangdaiscott/jeecg-boot Star 2873这是一款基于代码生成器的JAVA快速开发平台!提高UI能力的同时,降低前后分离的..._软件java项目最热算法?
redis 获取不到_Redis::scan 函数时获取不到数据-程序员宅基地
文章浏览阅读1.7k次。我在redis 组件 src/Connection/Connection.php 文件里面添加了scan替代 把迭代值返回 解决了这个问题* @param mixed $iterator* @param string $key* @param array $keys** @return array*/public function scan($iterator, string $pattern ...