Postgresql学习笔记之——内核技术简述_在postgressql中,如一个事务失败,在数据文件中这个事务产生的数据会不会在事务回-程序员宅基地
技术标签: postgresql Postgresql
一、表上的隐藏系统字段
在Postgresql中每个表都有几个系统字段,由系统隐含定义。在数据库中使用 “\d” 命令时不会显示的。因为表中已经隐含了某些名字的字段,所以用户在定义字段名称时就不能再使用这些名字。
这些字段如下:
1. oid
行对象标识符-Object Identifier(对象ID)。Postgresql在内部使用对象标识符(oid)作为各种系统表的主键。系统不会给用户建表时增加一个oid字段。目前oid类型用一个4字节的无符号整数实现,官方不建议用户建表时使用oid字段。
oid类型代表一个对象标识符,除此以外oid还有几个表示具体对象类型的别名,他所代表的所有对象标识符类型如下:
| 类型名称 | 引用 | 描述 | 数值例子 |
|---|---|---|---|
| oid | 任意 | 数字化的对象标识符 | 23874 标志着表 test |
| regproc | pg_proc | 函数名字 | Sum |
| regprocedure | pg_proc | 带参数类型的函数 | sum(int) |
| regoper | pg_operator | 操作符名 | + |
| regoperator | pg_operator | 带参数类型的操作符 | *(integer,integer) |
| regclass | pg_class | 表名或索引名 | pg_type |
| regtype | pg_type | 数据类型名 | Integer |
| regconfig | pg_ts_config | 全文检索配置 | English |
| regdictionary | pg_ts_dict | 全文检索路径 | Simple |
除了oid这种通用的对象标识符类型外,其他的类型都提供一种把字符串转换成oid类型的操作符,这可以大大方便查询对象信息。
例如,要查询对象标识符1259的表的名称是什么:
postgres=# select 1259::regclass;
regclass
----------
pg_class
(1 row)
要查询系统表,看表employee有哪些字段,正常的SQL需要查询pg_attribute,然后关联pg_class表才能查到:
postgres=# select attrelid,attname,atttypid,attlen,attnum,attnotnull from pg_attribute where attrelid = (select oid from pg_class where relname = 'employee');
attrelid | attname | atttypid | attlen | attnum | attnotnull
----------+----------+----------+--------+--------+------------
16656 | tableoid | 26 | 4 | -6 | t
16656 | cmax | 29 | 4 | -5 | t
16656 | xmax | 28 | 4 | -4 | t
16656 | cmin | 29 | 4 | -3 | t
16656 | xmin | 28 | 4 | -2 | t
16656 | ctid | 27 | 6 | -1 | t
16656 | id | 23 | 4 | 1 | t
16656 | name | 25 | -1 | 2 | f
16656 | sex | 16 | 1 | 3 | f
16656 | age | 23 | 4 | 4 | f
16656 | emp_no | 23 | 4 | 5 | f
(11 rows)
但是使用regclass类型的自动转换运算符,就可以不关联查询pg_class了:
postgres=# select attrelid,attname,atttypid,attlen,attnum,attnotnull from pg_attribute where attrelid = 'employee'::regclass;
attrelid | attname | atttypid | attlen | attnum | attnotnull
----------+----------+----------+--------+--------+------------
16656 | tableoid | 26 | 4 | -6 | t
16656 | cmax | 29 | 4 | -5 | t
16656 | xmax | 28 | 4 | -4 | t
16656 | cmin | 29 | 4 | -3 | t
16656 | xmin | 28 | 4 | -2 | t
16656 | ctid | 27 | 6 | -1 | t
16656 | id | 23 | 4 | 1 | t
16656 | name | 25 | -1 | 2 | f
16656 | sex | 16 | 1 | 3 | f
16656 | age | 23 | 4 | 4 | f
16656 | emp_no | 23 | 4 | 5 | f
(11 rows)
下面例子是查询操作符的左右两边参数的标准类型,使用**::regtype** 后将不再需要关联查询系统表pg_type,就可以得到结果:
postgres=# select oprname,oprleft::regtype,oprright::regtype,oprresult::regtype from pg_operator limit 5;
oprname | oprleft | oprright | oprresult
---------+---------+----------+-----------
= | integer | bigint | boolean
<> | integer | bigint | boolean
< | integer | bigint | boolean
> | integer | bigint | boolean
<= | integer | bigint | boolean
(5 rows)
2. tableoid
包含本行的表的oid。对附表(该表存在有继承关系的子表)进行查询时,使用这个字段,就可以知道某一行来自父表还是子表。tableoid 可以和 pg_class 的oid字段关联获取表名称。
3. xmin、xmax、cmin、cmax
这四个字段在多版本实现中用于控制数据行是否对用户可见。Postgresql会将修改前后的数据都存储在相同的结构中,这又分以下几种情况:
(1)新插入一行时,将新插入行的xmin填写为当前的事务ID,xmax填写0。
(2)修改一行时,实际上是新插入一行,旧行上的xmin不变,旧行上的xmax改为当前的事务ID,新行上的xmin填写为当前事务ID,新行上的xmax填写为0。
(3)删除一行时,把被删除行上的xmax填写为当前事务ID。
通过以上可以看出,xmin标记插入数据行的事务ID,xmax标记删除数据行的事务ID。
PS:Postgresql中没有修改数据行的操作,因为修改数据行实际上就是把旧数据行的xmax标记为自己的事务ID(相当于打上了删除标记),然后在新插入一条记录。
cmin 和 cmax 用于判断同一个事务内的不同命令导致的行版本变化是否可见。如果一个事务内的所有命令都是严格按照顺序执行的,那么每个命令都可以看到之前该事务内的所有变更,这种情况下不需要使用命令标识。
一般编程中,对一个数组和列表遍历时,是不允许在遍历中删除或增加元素的,因为这样会导致逻辑错误,而数据库中,对游标进行遍历时,可以对游标引用的表进行插入或删除行的操作而不出现逻辑错误,这时因为游标时一个快照,遍历时的删除或增加操作不会影响游标的数据,遍历游标时看到的是声明游标时的数据快照而不是执行时的数据,所以它在扫描数据时,会忽略声明游标后对数据的变更,因为这些变更对于游标都是无效的。
游标后续看到的数据都是声明游标之前的一个快照,相当于游标与后续的命令并发交错执行,这与不同事物之间的命令交错执行类似,存在数据可见性的问题。与解决事务内可见性问题类似,Postgresql引入了命令ID的概念。行上记录了操作这行的命令ID,当其他命令读取这行数据时,如果当前的命令ID大于等于数据行上的命令ID,说明这行数据时可见的;如果当前命令的ID小于等于数据行上的命令ID,则这条数据不可见。
4. ctid
ctid表示数据行在它所处的表内的物理位置。ctid字段的类型是oid,尽管oid可以非常快速地定为数据行,但每次 VACUUM FULL 之后,数据行在块内的物理位置就会移动,即ctid就会发生变化,所以ctid是不能作为长期的行标识符的,应该使用主键来标识一个逻辑数据行。
postgres=# select * from employee ;
id | name | sex | age | emp_no
----+-------+-----+-----+--------
1 | zhang | f | 23 | 201
3 | anmi | t | 22 | 203
(2 rows)
postgres=# select ctid,id,name from employee ;
ctid | id | name
--------+----+-------
(0,17) | 1 | zhang
(0,19) | 3 | anmi
(2 rows)
从上面的查询看出,ctid有两个数字组成,第一个数字标识物理块号,第二个数字表示在物理块中的行号。并且ctid还可以作为where条件进行数据的查询过滤:
postgres=# select * from employee where ctid = '(0,19)';
id | name | sex | age | emp_no
----+------+-----+-----+--------
3 | anmi | t | 22 | 203
(1 row)
在Oracle中表中每行都有一个唯一标识rowid,可以通过rowid进行表数据去重,ctid也有类似想过,可以通过此字段进行表数据的去重:
(对存在重复数据的sys_users表去重)
postgres=# select * from sys_users ;
id | user_name | password | user_email | user_mark
----+-----------+----------+----------------+-----------
2 | zhang2 | zhang123 | zhang2@163.com | hello2
3 | zhang3 | zhang123 | zhang3@163.com | hello3
1 | Lee | zhang123 | zhang@163.com | hello
2 | zhang2 | zhang123 | zhang2@163.com | hello2
3 | zhang3 | zhang123 | zhang3@163.com | hello3
1 | Lee | zhang123 | zhang@163.com | hello
2 | zhang2 | zhang123 | zhang2@163.com | hello2
3 | zhang3 | zhang123 | zhang3@163.com | hello3
1 | Lee | zhang123 | zhang@163.com | hello
2 | zhang2 | zhang123 | zhang2@163.com | hello2
3 | zhang3 | zhang123 | zhang3@163.com | hello3
1 | Lee | zhang123 | zhang@163.com | hello
2 | zhang2 | zhang123 | zhang2@163.com | hello2
3 | zhang3 | zhang123 | zhang3@163.com | hello3
1 | Lee | zhang123 | zhang@163.com | hello
(15 rows)
postgres=# delete from sys_users a where a.ctid <> (select min(b.ctid) from sys_users b where a.id=b.id);
DELETE 12
postgres=# select * from sys_users ;
id | user_name | password | user_email | user_mark
----+-----------+----------+----------------+-----------
2 | zhang2 | zhang123 | zhang2@163.com | hello2
3 | zhang3 | zhang123 | zhang3@163.com | hello3
1 | Lee | zhang123 | zhang@163.com | hello
(3 rows)
如果表中数据量过大,上面的去重方式效率是比较低的,可以通过以下方式更高效处理:
from sys_users where ctid = any(array(select ctid from (select row_number() over (partition by id), ctid from sys_users )x where x.row_number >1));
重点解释:
1.row_number() over (partition by id)
其中row_number()会给数据行标上序号,然后 partition by id 是以id分组,最后结果就是以id相同的值分组,然后每组相同的id依次从 1 开始递增加上序号,单独执行结果如下:
postgres=# select * from sys_users order by id;
id | user_name | password | user_email | user_mark
----+-----------+----------+----------------+-----------
1 | Lee | zhang123 | zhang@163.com | hello
1 | Lee | zhang123 | zhang@163.com | hello
1 | Lee | zhang123 | zhang@163.com | hello
1 | Lee | zhang123 | zhang@163.com | hello
1 | Lee | zhang123 | zhang@163.com | hello
2 | zhang2 | zhang123 | zhang2@163.com | hello2
2 | zhang2 | zhang123 | zhang2@163.com | hello2
2 | zhang2 | zhang123 | zhang2@163.com | hello2
2 | zhang2 | zhang123 | zhang2@163.com | hello2
2 | zhang2 | zhang123 | zhang2@163.com | hello2
3 | zhang3 | zhang123 | zhang3@163.com | hello3
3 | zhang3 | zhang123 | zhang3@163.com | hello3
3 | zhang3 | zhang123 | zhang3@163.com | hello3
3 | zhang3 | zhang123 | zhang3@163.com | hello3
3 | zhang3 | zhang123 | zhang3@163.com | hello3
(15 rows)
postgres=# select id,user_name,row_number() over (partition by id) from sys_users ;
id | user_name | row_number
----+-----------+------------
1 | Lee | 1
1 | Lee | 2
1 | Lee | 3
1 | Lee | 4
1 | Lee | 5
2 | zhang2 | 1
2 | zhang2 | 2
2 | zhang2 | 3
2 | zhang2 | 4
2 | zhang2 | 5
3 | zhang3 | 1
3 | zhang3 | 2
3 | zhang3 | 3
3 | zhang3 | 4
3 | zhang3 | 5
(15 rows)
2.array 、any
array将查询结果(row_numer()大于1表示出了等于1的其他都是重复值)中的ctid转成了数组格式,any是将数组可以作为sql语句查询条件,相当于in数组中的值。
二、多版本并发控制
多版本并发控制(Multi-Version Concurrency Control),简称为MVCC,实在数据库中并发访问数据时保证数据一致性的方法。
1.原理
MVCC的原理是在写数据时,旧版本的数据并不删除,并发的读还能读到旧版本的数据,这样就不会出现数据不一致的问题。
实现MVCC的方法有两种:
(1)在写数据时,把旧数据移到一个单独的地方,如回滚段中,其他人在读数据时,从回滚段中把旧数据读出来。
(2)写新数据时,旧数据不删除,而是把新数据插入。
Postgresql数据库使用的就是第二种方法。而oracle数据库和MySQL数据库的innodb引擎使用的是第一种方法。
2.Postgresql中的多版本并发控制
上面说到,Postgresql数据库是通过把旧数据留在数据文件中,新插入一条数据来实现多版本功能的。而且为了实现此功能,每张表都添加了四个系统字段xmin、xmax、cmin、cmax。当两个事务同时访问记录时,通过参考xmin、xmax的标记可判断记录的版本,然后根据版本号与自己当前事务标识进行比较,确定自己的数据权限。当删除数据时,需要记住记录并没有从数据块中删除,空间也没有立即释放。
Postgresql中多版本实现首先要解决的是旧数据的空间释放问题。Postgresql通过运行vacuum进程来回收之前的存储空间,默认Postgresql数据库中的autovacuum是打开的,也就是说当一个表的更新达到一定数量时,autovacuum自动回收空间。当然也可以关闭autovacuum,然后在业务低峰期手动运行vacuum来回收空间。
在Postgresql中,若一个事务失败,在数据文件中这个事务产生的数据并不会在事务回滚时被清理掉。为什么不在事务提交时将数据标记为有效的,事务回滚后表示为无效的?这是出于效率的考虑,若事务提交或回滚时再次标记了数据,这些数据就有可能会被刷新到磁盘上,而再次标记会导致另一个IO消耗,降低了数据库性能。而Postgresql通过记录事务的状态来实现,因为数据行上记录了xmin和xmax,所以只需了解了这两个系统字段对应的事务是成功提交还是回滚就可以知道这些数据行是否有效。
Postgresql数据库中事务ID缩写为xid,是一个32字节的数字,有以下三种特殊的事务ID是给系统内部使用的,它们有这特殊的含义:
(1)InvalidTransactionId = 0,表示是无效的事务ID。
(2)BootstrapTransactionId = 1,表示系统表初始化时的事务ID。
(3)FrozenTransactionId = 2,表示冻结的事务ID。
所以数据库系统第一个正常的事务ID是从3开始的,然后不停的递增,达到最大值后,再从3开始。事务ID为0、1、2的始终保留。
3.Postgresql多版本的优劣分析
Oracle数据库和MySQL数据库的innodb引擎都实现了多版本的功能,但它们与Postgresql数据库的实现方式不同。在两个数据库中旧版本的数据并不记录在原先的数据块中,而是记录在回滚段中。如果要读取旧版本的数据,需要根据回滚段的数据重构旧版本的数据。
Postgresql的多版本机制与Java虚拟机的垃圾回收机制类似。事务提交前,只需访问原来的数据,提交后,系统更新元祖的存储标识,知道vacuum进程收回为止。
因此Postgresql多版本的优势在于:
(1)事务回滚可以立即完成,无论事务进行了多少操作。
(2)数据可以进行很多更新,不必如Oracle或MySQL那样需要经常保证回滚段不会被用完,导致无妨读取旧数据而报错。
而Postgresql的劣势在于:
(1)旧版本的数据需要清理,Postgresql清理旧版本的命令称之为vacuum。
(2)旧版本的数据会导致查询更慢,以为旧版本数据存放是在磁盘中,查询就会导致需要扫描磁盘数据块。
三、物理存储结构
Postgresql数据库目前不支持裸设备和块设备,在Postgresql数据库中表的数据时存放在一个或者多个物理的数据文件中。而相应的数据文件又分多个固定大小的数据块,数据就放在数据块中。
1.Postgresql数据库中术语
Postgresql数据库与其他数据库不同,对于如表,数据行的称呼如下:
(1)relation:表示表或索引,也就是oracle或MySQL中的table或index。
(2)tuple:表示表中的数据行,oracle中称为row。
(3)page:表示磁盘中的数据块。
(4)buffer:表示内存中的数据块。
2.数据块结构
数据块结构如下图所示:
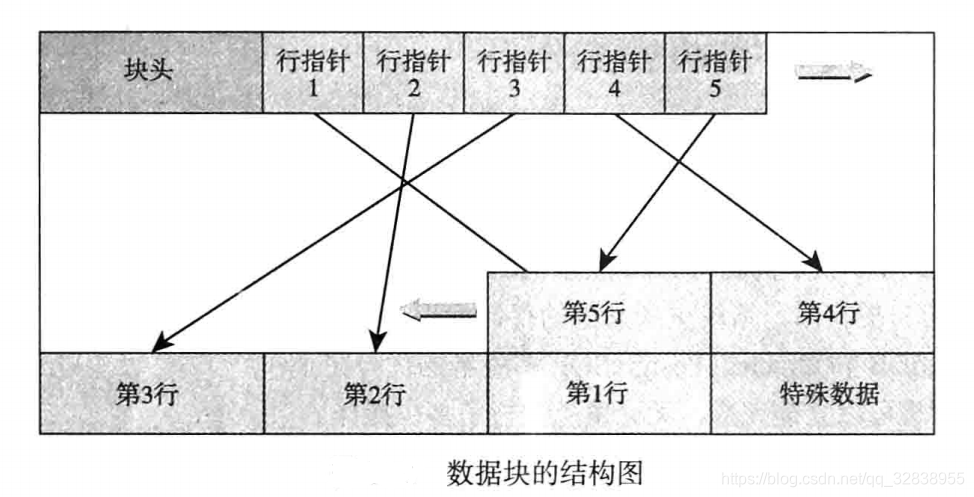
数据块的大小默认为8K,最大支持32K,一个数据块中可存放多行的数据,块中的结构是先有一个块头,其中记录这个数据块中各个数据行的指针,行指针是向后顺序排列的,而实际的数据行内容是从块尾向块头的方向反向排列的。行数据指针与数据行之间的部分则是空闲的空间。
块头记录如下信息:
(1)块的checksum值。
(2)空闲空间的起始位置和结束位置。
(3)特殊数据的起始位置。
(4)其他信息
行指针是一个32字节的数字,具体结构如下:
(1)行内容的偏移量,占15bit。
(2)指针的标记,占2bit。
(3)行内容的长度,占15bit。
行指针中表示行内容的偏移量是15bit,表示最大偏移量为2的15次方,也就是32768,所以在Postgresql中,块的最大大小为32768,也就是32KB。
3.tuple结构
在Postgresql数据库中的tuple就是指表中的数据行,结构如下图:
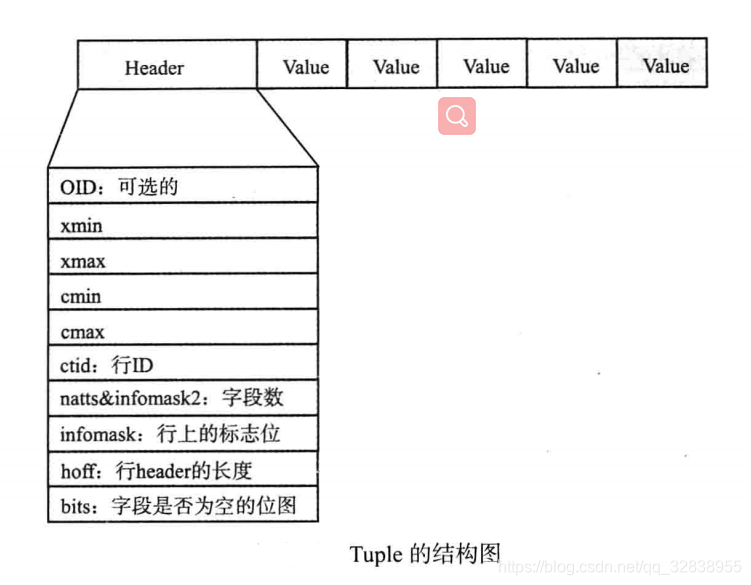
从上图看出,行的物理结构是先有一个行头,后面跟了各项数据。行头中记录了如下信息(只作为了解):
(1)oid、ctid、xmin、xmax、cmin、cmax。
(2)natts&infomask2:字段数。其中第11位表示这行有多少个列。其他位则是用于HOT(heap only touple)技术及行可见性的标志位。
(3)infomask:用于标识行当前的状态,比如行是否有oid,是否有空属性,供16位,每一位代表不同意思。
(4)hoff:表示行头的长度。
(5)bits:是一个数组,用于标识改行上哪些字段是空值。
4.数据块空闲空间管理
在表的数据块中插入、更新和删除数据时,会产生旧版本的数据,这些旧版本的数据通过vacuum进行清理,会在数据块中产生空间空间。在向表中插入新数据时,最好的办法是据需使用这些旧数据块中的空闲处的空间,如果给所有的新数据分配新的数据块会导致数据文件不断增大。当插入数据行时若多个数据块中有空闲空间,应把数据行查到其中那个数据块中呢?可以想象出,有的空间空间数据块不一定能存放下新数据行,因此想要插入一行数据时,首先需要快速定为空闲空间充足的数据块。
因此需要知道每个数据块的空闲空间的大小,并能够实现快速查找定为所需的数据块。
在Postgresql数据库中使用一个名为FSM的文件记录每个数据块的空闲空间。FSM-Free Space Map。
Postgresql为了缩小FSM文件的大小,使用1个字节记录数据块中的空闲空间,1字节表示的是空闲空间的范文:
| 字节值 | 表示空闲空间的范围(单位字节) |
|---|---|
| 0 | 0 ~ 31 |
| 1 | 32 ~ 63 |
| 2 | 64 ~ 95 |
| 3 | 96 ~ 127 |
| … | … |
| 255 | 8164 ~ 8192 |
从表格中看出,如果这个字节值为0,表示数据块中存在的空闲空间范围是 0-31个字节。以此类推。
在新版本的Postgresql数据库中对每个数据文件都会创建一个名为 “<表oid>_fsm” 的文件,例如一个表的oid为7844,那么它的fsm文件名就是 7844_fsm。
为了快速查找满足要求的数据块,Postgresql数据库使用了树形结构组织FSM文件。fsm文件固定使用三层树形结构,第0层和第1层为查找辅助层,第2层中每个块的每个字节代表其对应的数据块中的最大值。假设第2层的每个数据块都可以填4000个字节,则这4000个字节对应着在真正的数据文件中4000个数据块各有多个空闲空间,而第1层中的这个字节,则表示第2层中对应数据块中的最大值,也就是指对应到真正的数据文件中这4000个数据块最大的空闲空间,同时第0层中的每个字节表示的是下一层中数据块的最大值。第0层只有一个数据块,当需要判断数据块的空闲空间是否足够大时,只需要查询第0层的这个数据块,就可确定是否有合适的空闲空间的数据块了。
下面使用图示来理解以上的思路,为了简化理解,图中每个块只能放4个字节的数据有,原来与4000个字节一样:
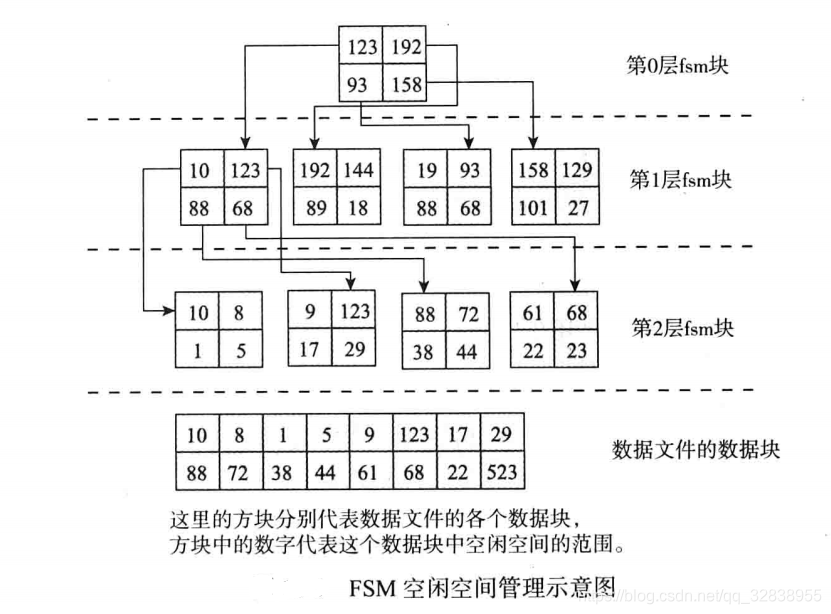
在图中,第0层的数据块中,4个字节中每个字节代表了第1层中一个数据块里4个字节数的中最大值,而第1层中每个数据块中4个字节每个字节数都代表第2层中一个数据块中4个字节的最大值,而第2层的数据块中4个字节中每个字节数字代表数据文件中数据块的空闲空间的范围(字节数和范围对应参考fsm文件解释)。第0层只有一个数据块,这个数据块中的第一个字节值为123,表示它下层,也就是第1层的第1个数据块中4个字节数最大值为123,。同样第0层的第2个字节值为192,表示它下层第2个数据块中4字节中最大值为192,以此类推。第1层与第2层也是如此映射。
FSM文件不是在创建表文件时就会立刻创建,而是等到需要时才会创建,如执行VACUUM操作时或者为了插入行而第一次查询FSM文件时才会创建。
示例
postgres=# create table test(id int,name varchar(75));
CREATE TABLE
postgres=# insert into test values (1,'zhang');
INSERT 0 1
postgres=# select oid from pg_class where relname='test';
oid
-------
25413
(1 row)
postgres=# \q
[postgres@local ~]$ ll /data/pgsql_data/base/13537/25413*
-rw------- 1 postgres postgres 8.0K Apr 11 16:20 /data/pgsql_data/base/13537/25413
查看数据目录中表数据文件时,只有表一个,没有fsm文件,然后对标做vacuum :
postgres=# vacuum test;
VACUUM
postgres=# \q
[postgres@local ~]$ ll /data/pgsql_data/base/13537/25413*
-rw------- 1 postgres postgres 8.0K Apr 11 16:20 /data/pgsql_data/base/13537/25413
-rw------- 1 postgres postgres 24K Apr 11 16:24 /data/pgsql_data/base/13537/25413_fsm
-rw------- 1 postgres postgres 8.0K Apr 11 16:24 /data/pgsql_data/base/13537/25413_vm
可以看到已经生成了fsm文件了,在看到fsm文件同时,也看到了一个以 _vm结尾的文件,它其实是可见性映射表文件。
5.可见性映射表文件
在Postgresql中更新、删除表中某行后,该行并不会马上从数据块中清理掉,而是需要等到执行vacuum命令后再清理,为了能加快VACUUM清理的速度和降低对系统IO的性能影响,Postgresql为每个数据文件加了一个后缀名为 _vm 的文件,这个文件被称为可见性映射表文件。简称VM文件。VM文件中为每个数据块设置了一个标志位,用来标记数据块中是否存在需要清理的行。有了这个文件后,通过使用VACUUM命令扫描这个文件时,如果发现VM文件中这个数据块上的位表示该数据块没有需要清理的行时,则会跳过对这个数据块的扫描,从而加快VACUUM清理的速度。
VACUUM清理数据有两种方式,一种称为**“Lazy VACUUM”,另一种被称为“Full VACUUM”。VM文件仅在“Lazy VACUUM”中使用到。“Full VACUUM”**操作则需要对整个数据文件进行扫描。
以待更新
智能推荐
FPGA设计经验谈 —— 10年FPGA开发经验的工程师肺腑之言-程序员宅基地
文章浏览阅读2.4k次,点赞10次,收藏30次。FPGA设计经验谈 —— 10年FPGA开发经验的工程师肺腑之言2014年08月08日 14:08 看门狗关键词: FPGA作者:friends 从大学时代第一次接触FPGA至今已有10多年的时间。至今记得当初第一次在EDA实验平台上完成数字秒表,抢答器,密码锁等实验时,那个兴奋劲。当时由于没有接触到HDL硬件描述语言,设计都是在MAX+plus II原理图环境下用..._fpga开发经验是什么
Java程序设计实验六 Socket网络程序设计-程序员宅基地
文章浏览阅读5.4k次,点赞7次,收藏52次。[1]实验目的:理解Socket通信原理,掌握使用Socket和ServerSocket类进行TCP Socket通信的程序设计方法。[2]实验内容:1、使用ServerSocket类和Socket类实现按如下协议通信的服务器端和客户端程序。服务器程序的处理规则如下:向客户端程序发送Verifying Server!。 若读口令次数超过3次,则发送Illegal User!给客户端,程序退出。否则向下执行步骤3)。 读取客户端程序提供的口令。 若口令不正确,则发送PassWord Wr_实验六 socket网络程序设计
易语言和python混合编程_易语言python交互源码,不需要把易语言编译成静态库-程序员宅基地
文章浏览阅读422次。.版本 2.支持库 spec.子程序 _启动子程序, 整数型, , 本子程序在程序启动后最先执行.局部变量 mothod, PyMethodDef.局部变量 创建结果, 整数型.局部变量 错误类型, 整数型.局部变量 错误信息, 文本型.局部变量 错误信息2, 整数型.局部变量 错误信息3, 文本型.局部变量 错误堆栈, 整数型Py_SetPythonHome (“C:\Python36”)Py_..._易语言python混合开发
数仓建设生命周期_最最最全数据仓库建设指南,速速收藏!-程序员宅基地
文章浏览阅读557次。开讲之前,我们先来回顾一下数据仓库的定义。数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。这个概念最早由数据仓库之父比尔·恩门(Bill Inmon)于1990年在《建立数据仓库》一书中提出,近年来却被愈发广泛的提及和应用,不信看下图:到底是什么,让一个从上世纪90年代提出的概念,在近几年确越来越热?带着这个问题,我们来了解一..._数仓生命周期管理
winform GridControl 总结-程序员宅基地
文章浏览阅读2.4k次,点赞4次,收藏19次。winfrom GridControl总结一、GridControl和GridView的关系GridControl表示网格控件,网格控件使用视图(如 GridView、BandedGridView)来显示数据。GridControl 相当于容器,GridView 相当于容器中的可视化组件,一个GridControl网格控件里面可以有多个视图。类似于 Excel 表格文件 与工作表 Sheet 的关系。二、绑定数据源点击 RunDesigner增加列 Column与DataTabl_winform gridcontrol
安装完Ubuntu后要做的事情-程序员宅基地
文章浏览阅读100次。Ubuntu 16.04安装完成后,还需要做一些配置才能愉快的使用,所以装完系统后还要进行一系列的优化。1.删除libreofficelibreoffice虽然是开源的,但是Java写出来的office执行效率实在不敢恭维,装完系统后果断删掉sudoapt-getremovelibreoffice-common2.删除Amazon的链接sudoapt-get..._prepend domain-name-servers 114.114.114.114;
随便推点
python的string模块(字符)和random模块的使用_import string在python中的用法-程序员宅基地
文章浏览阅读2.2k次,点赞3次,收藏18次。一、模块string的简单使用import string #导入string模块,获取大小写字母、特殊字符、数字等#获取大小写字母abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZprint(string.ascii_letters)#获取大写字母ABCDEFGHIJKLMNOPQRSTUVWXYZprint(string.ascii_uppercase)#获取小写字母abcdefghijklmnopqrstuvwxyzprint(s_import string在python中的用法
IntelliJ IDEA导入 Eclipse 项目【山东大学 现代软件开发技术】2023.2.2 Ulitimate Edition_idea导入eclipse-程序员宅基地
文章浏览阅读1.2k次,点赞3次,收藏8次。本文记录了将 Eclipse 项目 导入 IDEA 2023.2.2 的过程,同时也适用于山东大学现代软件开发技术这门课的开发环境迁移。_idea导入eclipse
Chrome浏览器调试教程_chrome 浏览器调试协议-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏2次。Chrome浏览器及调试教程引言在web开发过程中,我们在写JavaScript脚本时难免会遇到各种bug,这时,我们就需要去调试我们的JavaScript脚本,然后去修改代码。最简单的调试方法就是使用alert方法,将可信息通过alert方法的弹窗显示出来。但是,alert方法有几个弊端:1)alert方法在弹..._chrome 浏览器调试协议
【小程序开发必备】微信小程序常用API全介绍,附示例代码和使用场景_微信小程序代码大全-程序员宅基地
文章浏览阅读1.1w次,点赞64次,收藏180次。本篇博文介绍了微信小程序常用API,包括网络请求、数据缓存、交互反馈、设备、媒体、界面、开放接口等方面。每个API都附有详细的介绍和示例代码,以及使用场景。这些API可以帮助小程序开发者快速实现各种功能和交互效果,是小程序开发的必备工具。无论是初学者还是有一定经验的开发者,都能从本篇博文中学到很多实用的技巧和知识。_微信小程序代码大全
Lc.exe已退出 代码为-1 解决方法-程序员宅基地
文章浏览阅读92次。打开一个别人曾经做的项目,里面用来三方控件,本机没有安装此控件,只是添加的相应的dll,结果导致了LC.exe错误:"Lc.exe已退出 代码为-1 "解决方法:1、把项目文件夹下Properties文件夹下的licenses.licx文件删除,重新编译即可;2、文本方式打开*.csproj文件,在文件中查找licenses.licx字样,删除对应节点。注意:还有..._错误64“lc.exe”已退出,代码为 -1。printlab
matlab paper size,Matlab有用的小工具小技巧-程序员宅基地
文章浏览阅读714次。hc=colorbar;set(hc,'FontSize',times*get(hc,'FontSize'))%假设有colorbar,实际上就是另外一个axes,同样设置它的字体看了这个这里才知道输出格式还可以在ExportSetup里设置的,而set(findall(gcf,'-property','FontSize'),'FontSize',12)可以把所有的对象中字体大小都改到12号!7...._matlab papersize