Kafka消息中间件(一)_kafka 9095-程序员宅基地
技术标签: 开发
Kafka消息中间件
- Kafka消息组件简介
Kafka可以说是现在所有开源消息组件之中性能最高的产品,但是同时也需要认识到一个问题:Kafka是一项不断继续发展的技术,所以来说对于其的稳定性永远无法评估。Kafka官网地址:
http://kafka.apache.org/
Kafka是分布式发布-订阅消息系统(主题)。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。阿里也有RabbitMQ消息组件。两者本质一样,但kafka在性能上占优势。
对于分布式消息系统主要有两种,一种是主题,一种是队列.
Kafka是一个分布式的,可划分的,冗余备份的持久性日志服务。它主要用于处理活跃的流式数据。

什么是消息组件:
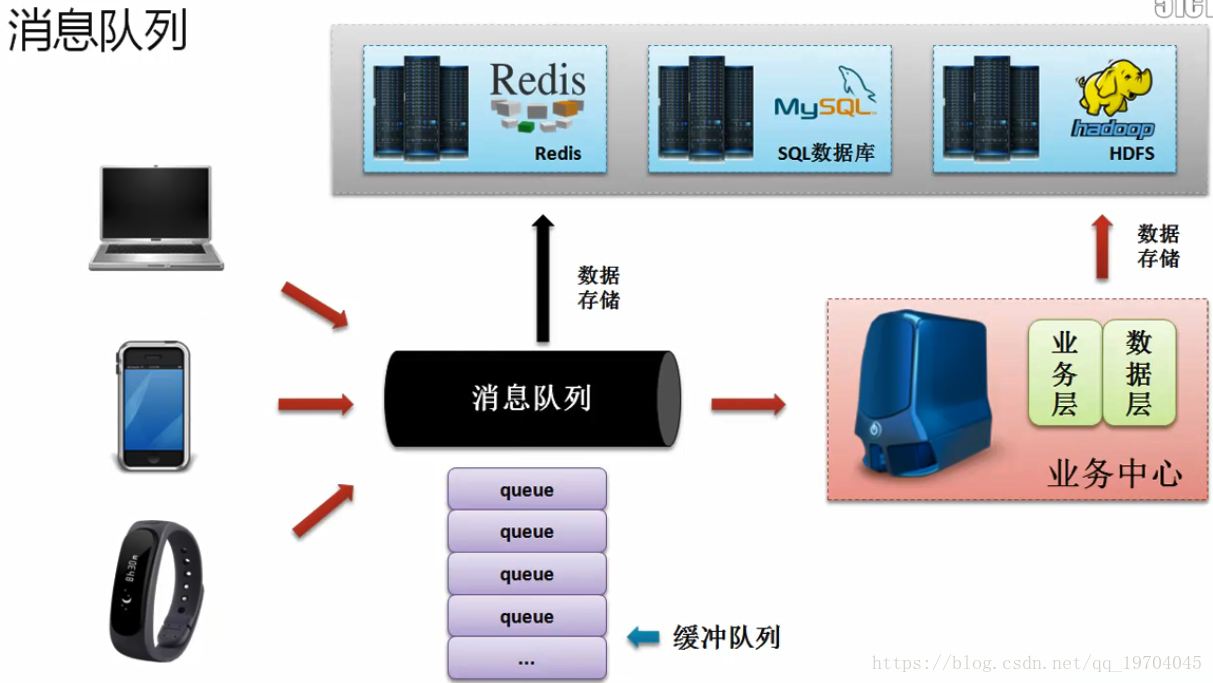
当各个设备发送的消息过多的时候,那么一定会引起数据量的暴涨,如果直接将这些消息交给处理程序,那么处理程序将无法正确处理,将导致消息数据的丢失,所以使用消息队列有一个最大的功能就是进行数据的缓冲操作。
而消息队列有两种处理消息的方式:一种是:直接将消息处理而后保存到持久化设备之中;(由于处理会造成处理速度变慢);第二种方式是利用其他的处理程序,例如:Strom进行消息的处理。
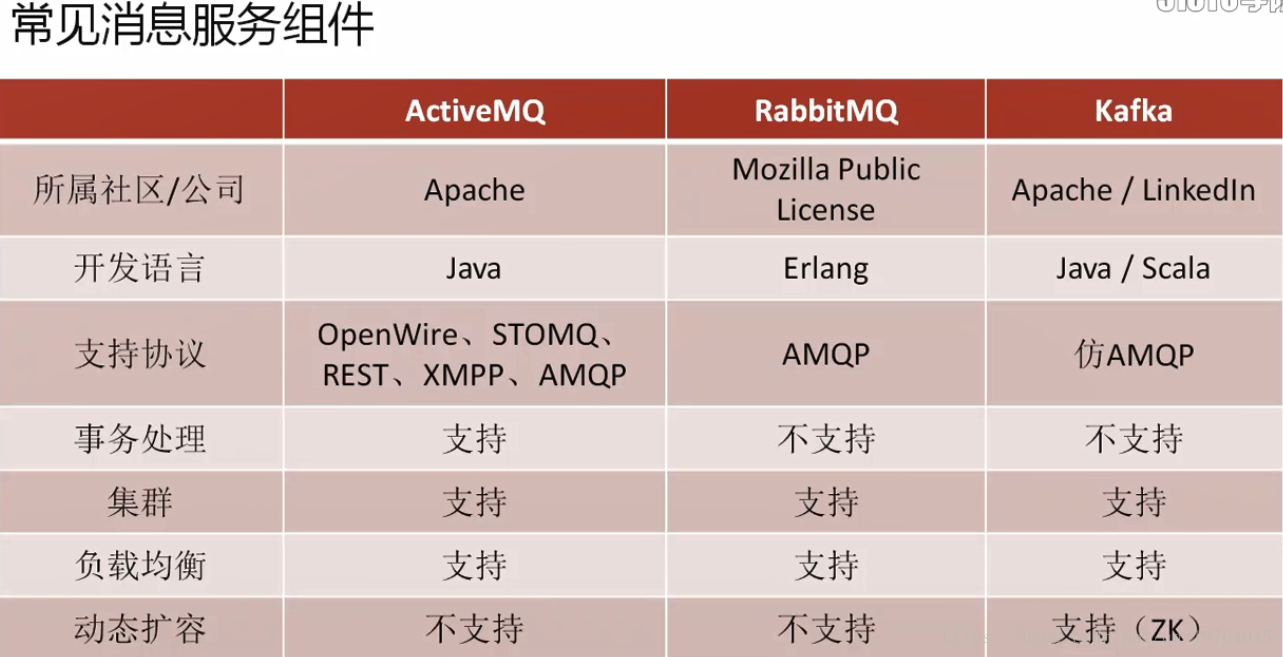
如果要说到消息队列,那么首先自然能够想到的就是JMS(JMS属于java消息服务,这就是javay原生的操作协议),其中JMS实现的代表性的开源的项目(ActiveMQ)–这种组件由于跨越的时间太长了,实际上已经不适合当前高并发的项目使用。

JMS支持多种类型,但是好比第七层实现的协议。需要去实现。
AMQP有两大著名的实现框架:Kafka、RabbitMQ
AMQP是一种协议,更准确的说是一种链接协议
AMQP不从API层进行限定,而是直接定义网络交换的数据格式,这使得AMQP的provider天然就是跨平台的。直接基于网络做的,不像JMS是基于数据接收到的处理来做的。–这是性能高的原因。
Kafka支持动态扩容(zookeeper组件支持)
AMQP是一种不受程序限制的传输的处理协议,而JMS受到程序限制。所以AMQP它的性能和适应性会更高,但是kafka作为AMQP的实现有一个最重要的特征:
RabbitMQ、ActiveMQ有一个最大的特点:消息消费完成消息就删除。
kafka特点:所有的消息会自动保存两天的时间。
- Kafka工作原理
Kafka是一款性能很高的消息组件,但是不管如何改变,对于消息组件本身其最基础的组成部分:
消息的生产者:负责进行消息信息的推送,推送给指定的服务器
消息的消费者:负责通过服务器获取消息的内容
消息服务中间件(服务器):负责消息的存储,也就是当消费者来不及处理完全部消息的时候,可以在消息中间件之中进行消息内容的缓冲,所以消息中间件也往往被称为消息队列中间件;
影响整个程序运行的关键性因素:程序的设计要合理,CPU处理速度快,内存要大,缓存大、磁盘转速要快(磁盘的寻址是成为性能最大的瓶颈),对于消息组件最快的做法就是网络传输也要快。而Kafka设计里面将所有可能影响到程序性能的部分全部考虑到了。
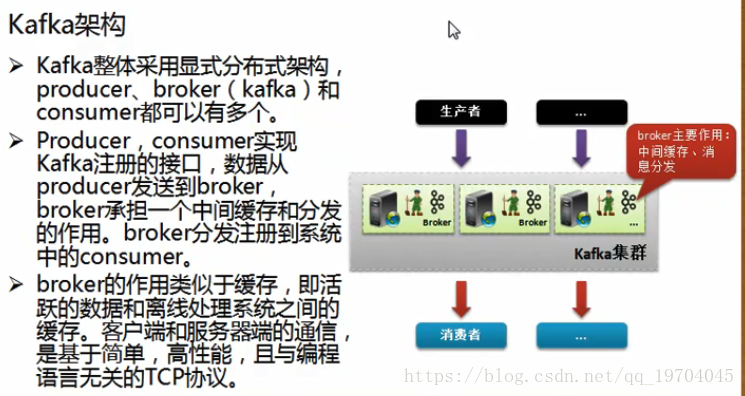
Kafka是基于zookeeper设计,所以对于Kafka的集群来讲实现就相对容易许多,同时Zookeeper可以保存所有集群主机的信息内容,也就是说在配置Kafka之前一定要首先进行zookeeper的配置。
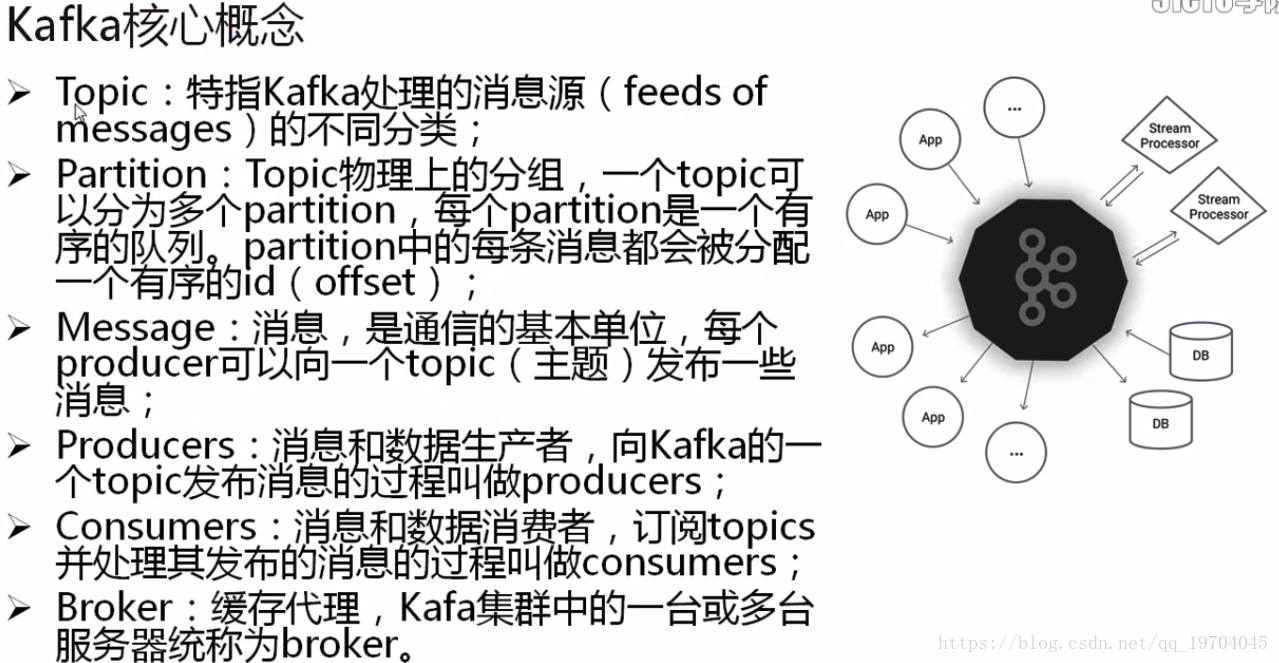
如果要想进行消息的处理,所有的消息组件都一定会提供有一个消息主题,所有的消息的生产者根据主题将自己的消息发送并且保存到服务器之中,而消费者也可以通过指定的主题获取消息的内容。这样就可以传递多种消息。
Partition:指的是分区:如果你现在配置的主机只是单核CPU,那么你能够进行的合理的分区划分只能够有一个分区,但是如果你CPU的核心数可能有16个,那么你这台服务器上可以进行的分区操作就可以划分出16个分区,在每一台服务器上可以有多个分区,而分区划分最简单的依据:根据你cpu的性能来决定
当然并不是说一核CPU无法进行多分区的配置,只不过要想发挥出最好的性能,那么一定要使用多核CPU再设置多个分区操作。(多个分区共享一个CPU,会出现轮询算法等,会有性能的瓶颈)
Message:消息,是通信的基本单位,每个producer可以向一个topic发布一些消息。
Producers:消息和数据产生者,向Kafka的一个topic发布消息的过程叫做producers
Consumers:消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers
Borker:缓存代理,Kafka集群中的一台或多台服务器统称为Broker
在整个Kafka集群里面,所有的分区数量= 主机CPU内核数量
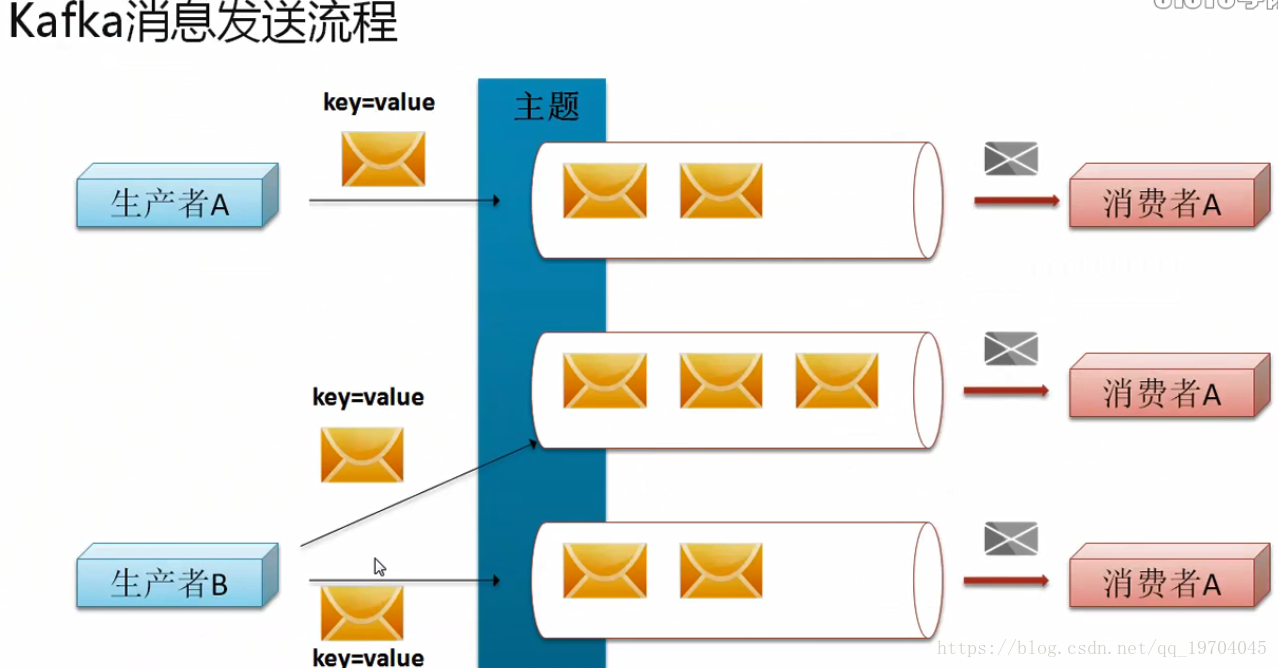
消息如何发送?
在Kafka之中消息的发送一定要依据主题进行划分,而每一个主题为了让消息处理的更快,专门设置有多个分区,就好比一件工作绝对要比三个人慢许多,同时在整个Kafka里面,最新的版本支持key-value的结构传输,这样的传输模式对于消费者而言会更加容易处理数据。在进行消费者设计的时候,你的消费者可以使用的数据数量就是你的分区数量,也就是说如果你现在设置了三个分区,那就就表示可以使用三个消费者,反之你只设置了一个分区,那么只能够有一个消费者。
Kafka消息处理流程:
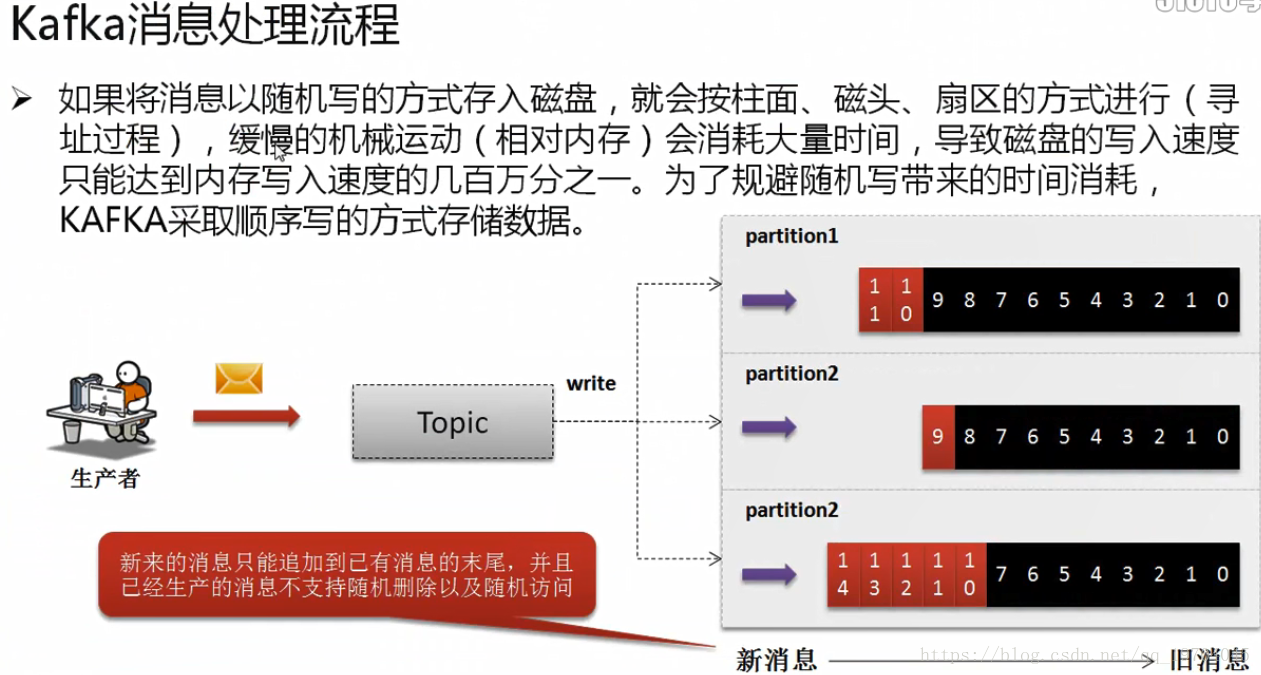
如果在进行信息写入的时候,所有磁盘中的数据保存采用随机的方式进行存储,那么在读取的时候就一定会产生性能瓶颈,因为磁盘会出现寻址变慢的情况,但是kafka采用顺序写入的方式存储数据。
新来的消息只能追加到已有消息的末尾,并且已经产生的消息不支持随机删除以及随机访问。
在整个kafka里面还有一个比较逆天的性能(也是迫切需要的),传统的JMS设计的时候存在一个缺陷:当某一个消息消费了之后,那么该消息将会被自动删除。而kafka不是,它在进行消息获取之后并不会立即删除,而是会将消息暂存2天,2天后自动删除。
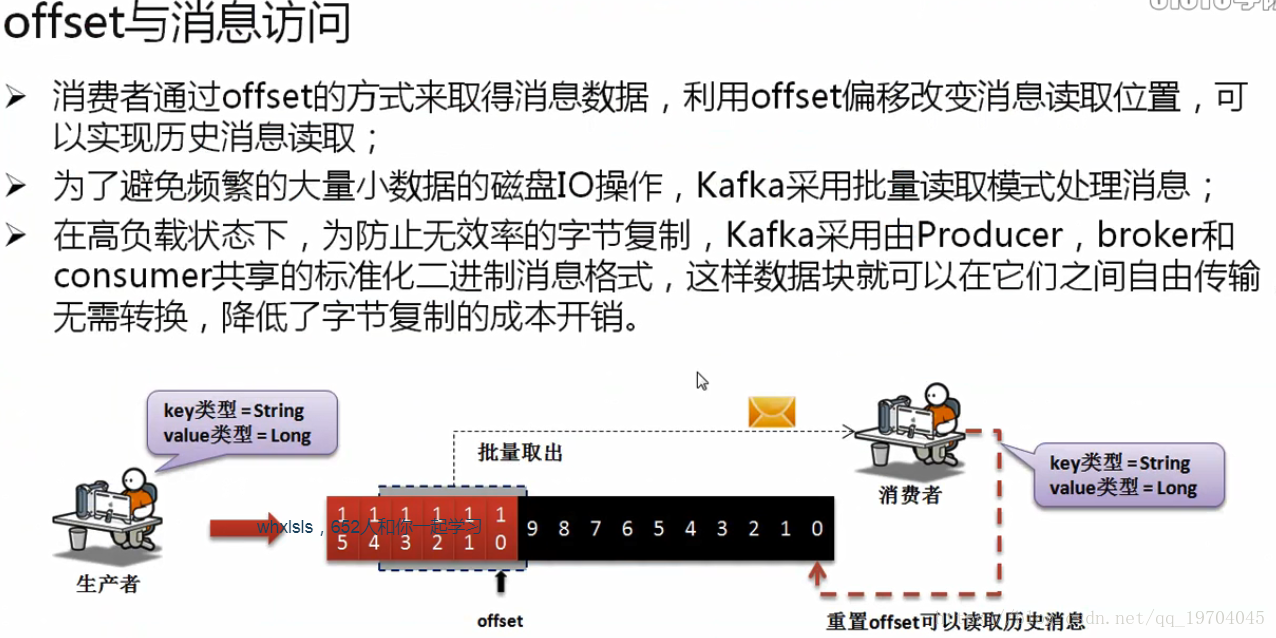
在这样的状态下为了保证kafka读取性能,单独设计了一个offset,可以理解为当前要操作的消息的下标,如果要想读取历史消息,只需要修改offset的指向即可实现。
在一些组件整合的过程中,需要考虑好offset设计,如果设计不当会造成历史消息重复读取的问题。
在磁盘之中,如果要不断进行各种细小的琐碎的操作,那么就有可能造成性能下降,所以在kafka里面专门设计有批量的数据操作,也就是说所有要消费的数据会批量读取,这样就减少了磁盘操作量,性能也会得到提升。
在很多的消息系统中,由于其可以传输的数据类型比较少,(字符串为主),所以在每一次消费的时候都需要去判断数据的类型,这样自然会造成时间复杂度的提升,那么为了解决这样的问题,Kafka约定了,你的消息的生产者一定要与消息的消费者协商好要传递的消息数据类型。

Kafka是基于JDK的实现,所以在Kafka之中 对于内存要想发挥高效,就不能纯粹的依靠JVM进行管理,所以Kafka还会使用到操作系统的内存空间,这样的好处是即使Kafka崩溃了,但是数据不在JVM里面,所以即使重新启动,数据也可以立刻重新恢复。

文件传输是整个网络操作的核心所在,毕竟消息组件之中是需要有消费者的,而所有的消费者如果想要进行消息的获取,传统的做法一定要通过CPU进行磁盘读取,而后在通过CPU进行网络传输,那么这样的处理中间会经过CPU控制,自然会造成性能的下降,
采用sendfile方式传输:
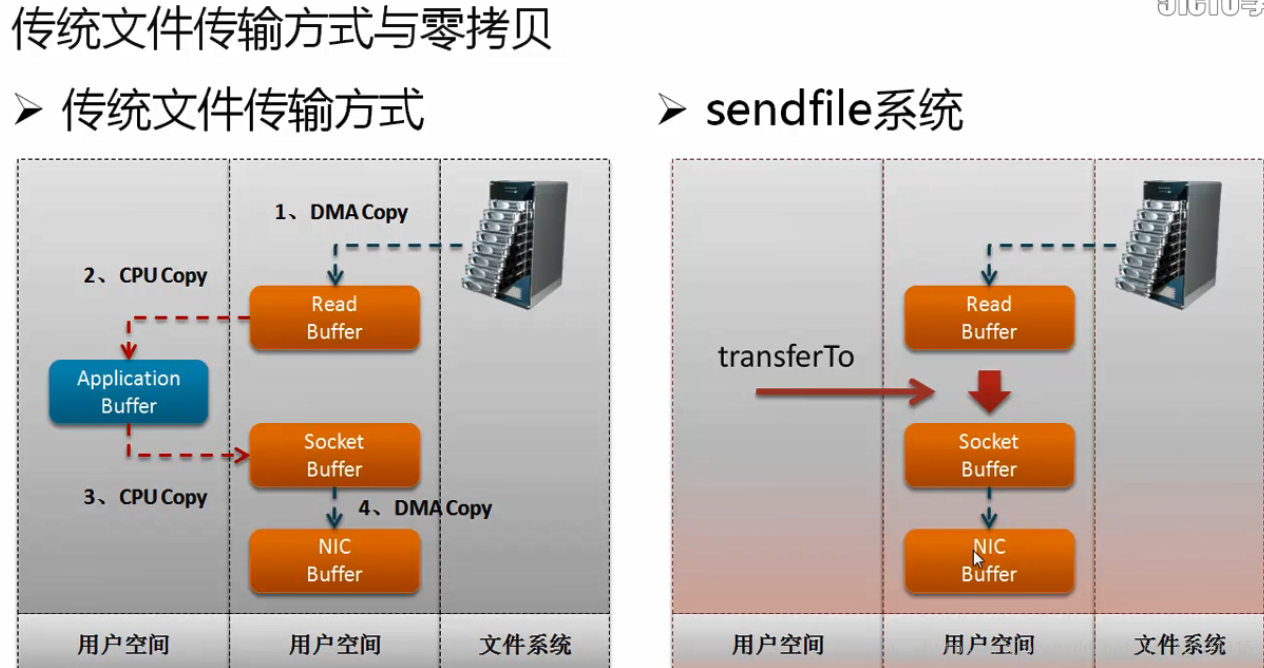
中间缺少了CPU处理环节,可以让执行性能更改。而这样的操作形式在Kafka之中称为零拷贝。
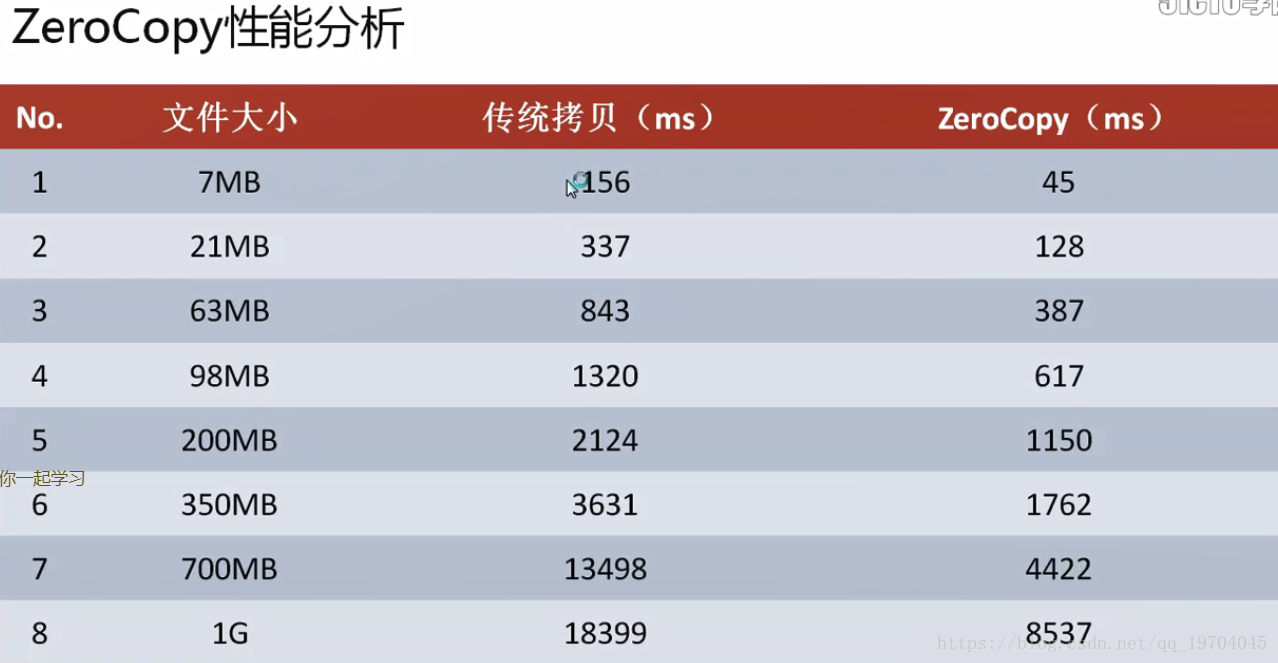
现在所有的设计都是围绕Kafka服务器本身的优化,但是关键性的因素还包括有网络传输,
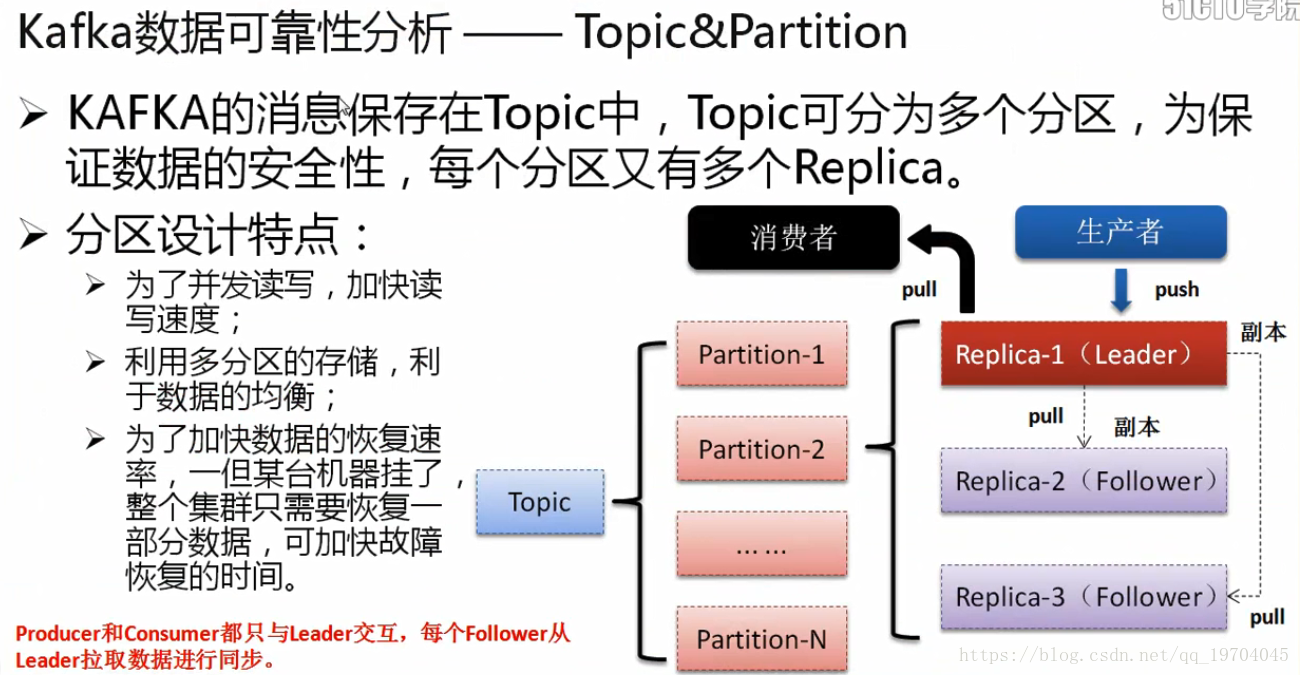
当你现在设计有多台Kafka服务器的时候,就可以进行副本的设计,如果设计了三个副本,那么这三个副本要推选出一个leader,两个follower,所有的跟随者通过leader进行数据的抓取,而所有的生产者会将数据交给leader,而我们的消费者也通过leader读取数据,这样当一个leader出现了问题之后,其它的两个fllower将自动推选出新的leader。保证数据完整性。
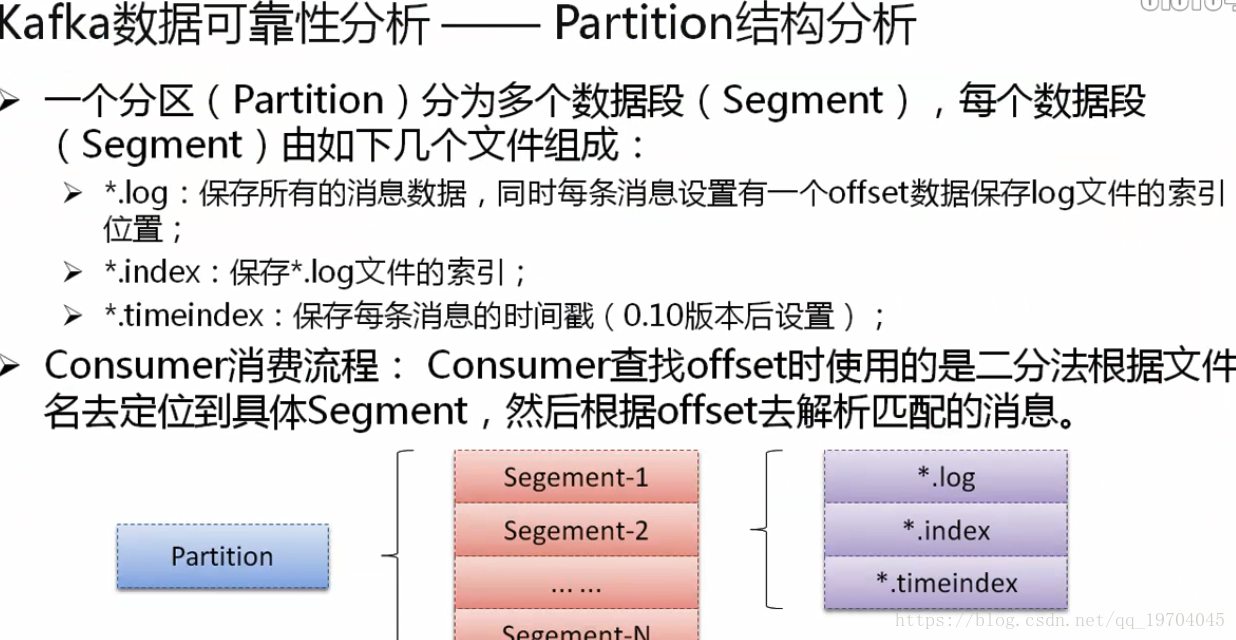
一个分区(partition)分为多个数据段(Segment),每个数据段又分为log、index、timeindex等。
消费者查找offset时使用二分法根据文件名定位到具体的Segment,然后在更具offset去解析匹配的消息。
综合来讲,可以轻松的总结出kafka所谓性能高的实现模型:
采用零拷贝技术,让数据传输更加迅速;
采用批量的数据读取,减少磁盘I/O操作,可以提升性能;
为了保证历史消息可以被继续消费,提供有一个offset指向,通过指向负责消息的读取;
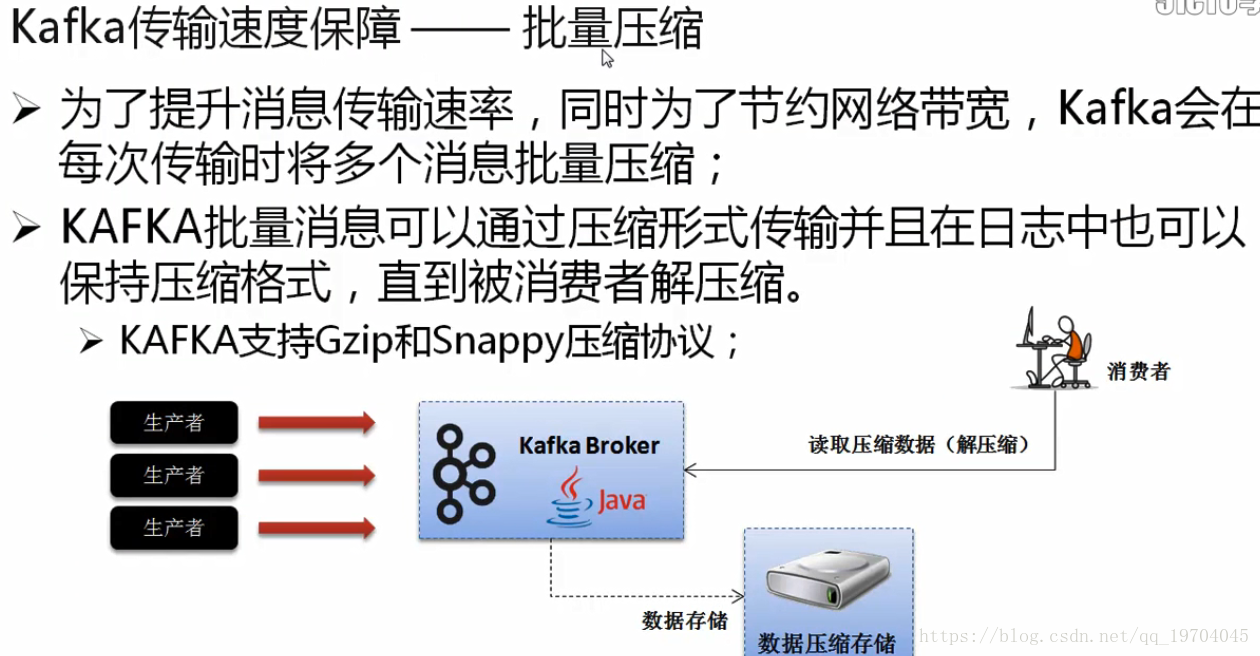
网络传输采用数据压缩的格式,所以传输更快,占用的带宽更少;
Kafka中的数据可以设置副本,这样可以保证在出现问题之后依然保证该数据的有效性(高可用性的表现)
- Kafka基础配置
本次选用的Kafka版本为:kafka_2.10-0.10.1.0.tgz,但需要知道的是Kafka是一个不断发展的技术,所以可以发现现在其版本号还不稳定,至少没有出现大的版本变化。它是不断更新的组件,可能会不断有新功能产生,也会有旧功能被淘汰。
1.将Kafka的开发包上传到Linux系统之中;
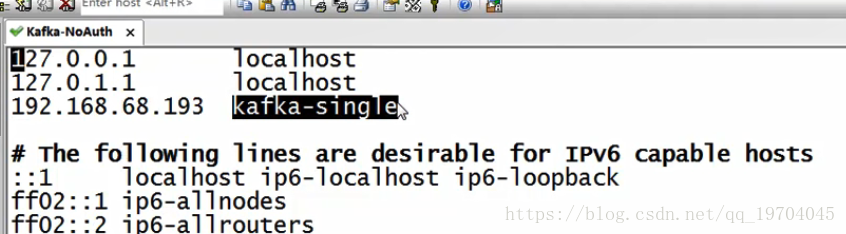
Linux系统IP地址是192.168.68.193
考虑到后期的维护方便,建议修改好系统的主机的IP地址映射:vim /etc/hosts;
2.将kafka开发包进行解压缩:
tar xzvf /srv/ftp/kafka_2.10-0.10.1.0.tgz -C /usr/local/
3.为了方便进行管理将解压缩后的文件夹进行更名处理:
mv /usr/local/kafka_2.10-0.10.1.0/ /usr/local/kafka
4.kafka本身依赖于zookeeper,但是需要注意的是Kafka开发包中本身就提供有了ZooKeeper支持命令,但是考虑到数据保存的方便,建议建立两个文件夹
mkdir -p /usr/data/{zookeeper,kafka}
分别处理zookeeper和kafka
5.编辑zookeeper.properties配置文件(kafka内部的zookeeper足够使用,不要再做外接了)
vim /usr/local/kafka/config/zookeeper.properties
原来的tmp目录在linux重新启动之后会被自动清除
所以修改:
dataDir=/usr/data/zookeeper
6.随后要进行kafka配置文件的定义:
server.properties文件
vim /usr/local/kafka/config/server.properties
关键:
broker.id=0(如果要是有多台主机,这些brokerid肯定不同)
配置数据保存目录:
log.dirs=/usr/data/kafka
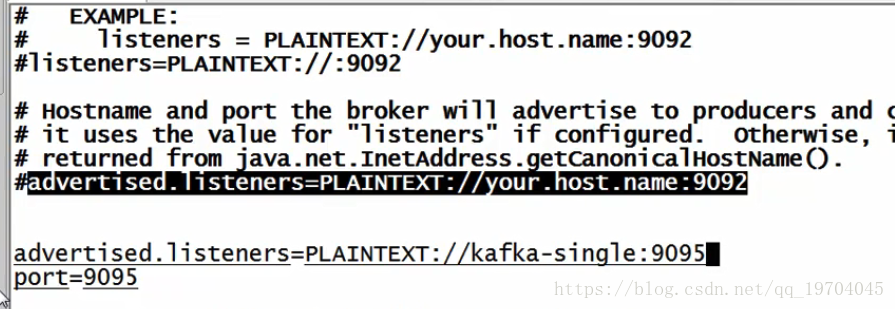
设置服务端口
port=9095
Kafka默认的访问端口设置为9092(如果你什么都不修改,它就是9092),但是一般在实际的使用过程之中,往往会为其分配其它的开发端口,本次设置为9095(一般很少用9092,涉及到加密问题)
默认此时kafka只能被内部访问
设置外网访问IP地址(端口号相同-9095):
上述一个是内部访问listeners=plaintext://9092
如果此时设置的不是9095,那么一定访问不了(通过java程序访问不了)

7.启动kafka服务,kafka依赖于zookeeper,server.properties中有对应的设置
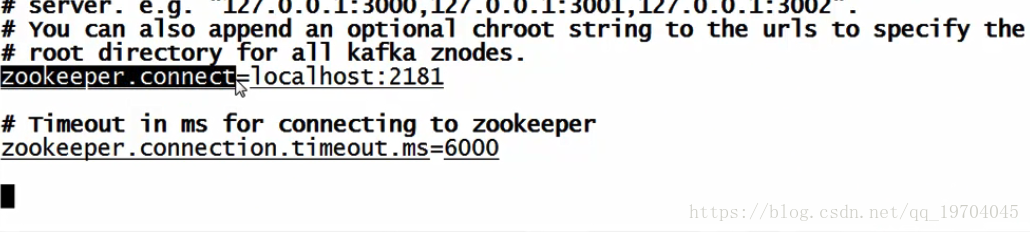
启动kafka内置 zookeeper服务:
/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties
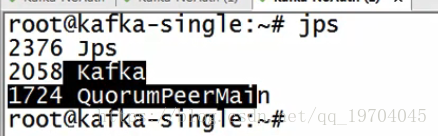
启动了zookeeper服务进程
启动kafka服务进程:
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
8.kafka启动之后会自动在zookeeper里面进行信息的注册,但是如果你现在使用的是kafka内置的zookeeper,则这些数据要想查看比较麻烦(Kafka提供了自己的zookeeper命令-这个命令不好用)
/usr/local/kafka/bin/zookeeper-shell.sh kafka-single ls /
(列出根目录下的所有数据)

9.如果用户要想进行kafka操作,那么一定要创建若干主题(Topic)
主题的所有信息都在zookeeper中。


10.查看所有的主题信息:

11.kafka内部提供有测试环境,可以直接利用指定的命令进行消息的生产者和消费者的通讯测试
1)启动kafka的消息消费者 --独占进程
不接受历史消息: 去掉 from beginning
接受历史消息:保留 from beginning

12.启动消息的生产者–消息发送者

输入helloworld
消息的消费者可以接收到消息 -----测试成功
这个两个工具只是在本机的测试操作使用,实际使用之中没有任何意义,只是能保证当前的kafka运行正常。
智能推荐
JVM在线分析-解决问题的工具一(jinfo,jmap,jstack)_jmap 在线分析-程序员宅基地
文章浏览阅读807次。扩展。_jmap 在线分析
台式计算机cpu允许温度,玩游戏cpu温度多少正常(台式电脑夏季CPU一般温度多少)...-程序员宅基地
文章浏览阅读1.1w次。随着炎热夏季的到来,当玩游戏正爽的时候,电脑突然死机了,自动关机了,是不是有想给主机一脚的冲动呢?这个很大的原因是因为CPU温度过高导致的。很多新手玩家可能都有一个疑虑,cpu温度多少以下正常?有些说是60,有些说是70,到底多高CPU温度不会死机呢?首先我们先看看如何查看CPU的温度。下载鲁大师并安装,运行鲁大师软件,即可进入软件界面,并点击温度管理,即可看到电脑各个硬件的温度。鲁大师一般情况下..._台式机玩游戏温度多少正常
小白自学Python日记 Day2-打印打印打印!_puthon打印任务收获-程序员宅基地
文章浏览阅读243次。Day2-打印打印打印!我终于更新了!(哭腔)一、 最简单的打印最最简单的打印语句: print(“打印内容”)注意:python是全英的,符号记得是半角下面是我写的例子:然后进入power shell ,注意:你需要使用cd来进入你保存的例子的文件夹,保存时名字应该取为xxx.py我终于知道为什么文件夹取名都建议取英文了,因为进入的时候是真的很麻烦!如果你没有进入正确的文件夹..._puthon打印任务收获
Docker安装:Errors during downloading metadata for repository ‘appstream‘:_"cenerrors during download metadata for repository-程序员宅基地
文章浏览阅读1k次。centos8问题参考CentOS 8 EOL如何切换源? - 云服务器 ECS - 阿里云_"cenerrors during download metadata for repository \"appstream"
尚硅谷_谷粒学苑-微服务+全栈在线教育实战项目之旅_基于微服务的在线教育平台尚硅谷-程序员宅基地
文章浏览阅读2.7k次,点赞3次,收藏11次。SpringBoot+Maven+MabatisPlusmaven在新建springboot项目引入RELEASE版本出错maven在新建springboot项目引入RELEASE版本出错maven详解maven就是通过pom.xml中的配置,就能够从仓库获取到想要的jar包。仓库分为:本地仓库、第三方仓库(私服)、中央仓库springframework.boot:spring-boot-starter-parent:2.2.1.RELEASE’ not found若出现jar包下载不了只有两_基于微服务的在线教育平台尚硅谷
java 实现 数据库备份_java数据备份-程序员宅基地
文章浏览阅读1k次。数据库备份的方法第一种:使用mysqldump结合exec函数进行数据库备份操作。第二种:使用php+mysql+header函数进行数据库备份和下载操作。下面 java 实现数据库备份的方法就是第一种首先我们得知道一些mysqldump的数据库备份语句备份一个数据库格式:mysqldump -h主机名 -P端口 -u用户名 -p密码 --database 数据库名 ..._java数据备份
随便推点
iOS NSTimer定时器-程序员宅基地
文章浏览阅读2.6k次。iOS中定时器有三种,分别是NSTimer、CADisplayLink、dispatch_source,下面就分别对这三种计时器进行说明。一、NSTimerNSTimer这种定时器用的比较多,但是特别需要注意释放问题,如果处理不好很容易引起循环引用问题,造成内存泄漏。1.1 NSTimer的创建NSTimer有两种创建方法。方法一:这种方法虽然创建了NSTimer,但是定时器却没有起作用。这种方式创建的NSTimer,需要加入到NSRunLoop中,有NSRunLoop的驱动才会让定时器跑起来。_ios nstimer
Linux常用命令_ls-lmore-程序员宅基地
文章浏览阅读4.8k次,点赞17次,收藏51次。Linux的命令有几百个,对程序员来说,常用的并不多,考虑各位是初学者,先学习本章节前15个命令就可以了,其它的命令以后用到的时候再学习。1、开机 物理机服务器,按下电源开关,就像windows开机一样。 在VMware中点击“开启此虚拟机”。2、登录 启动完成后,输入用户名和密码,一般情况下,不要用root用户..._ls-lmore
MySQL基础命令_mysql -u user-程序员宅基地
文章浏览阅读4.1k次。1.登录MYSQL系统命令打开DOS命令框shengfen,以管理员的身份运行命令1:mysql -u usernae -p password命令2:mysql -u username -p password -h 需要连接的mysql主机名(localhost本地主机名)或是mysql的ip地址(默认为:127.0.0.1)-P 端口号(默认:3306端口)使用其中任意一个就OK,输入命令后DOS命令框得到mysql>就说明已经进入了mysql系统2. 查看mysql当中的._mysql -u user
LVS+Keepalived使用总结_this is the redundant configuration for lvs + keep-程序员宅基地
文章浏览阅读484次。一、lvs简介和推荐阅读的资料二、lvs和keepalived的安装三、LVS VS/DR模式搭建四、LVS VS/TUN模式搭建五、LVS VS/NAT模式搭建六、keepalived多种real server健康检测实例七、lvs持久性工作原理和配置八、lvs数据监控九、lvs+keepalived故障排除一、LVS简介和推荐阅读的资料 学习LVS+Keepalived必须阅读的三个文档。1、 《Keepalived权威指南》下载见http://..._this is the redundant configuration for lvs + keepalived server itself
Android面试官,面试时总喜欢挖基础坑,整理了26道面试题牢固你基础!(3)-程序员宅基地
文章浏览阅读795次,点赞20次,收藏15次。AIDL是使用bind机制来工作。java原生参数Stringparcelablelist & map 元素 需要支持AIDL其实Android开发的知识点就那么多,面试问来问去还是那么点东西。所以面试没有其他的诀窍,只看你对这些知识点准备的充分程度。so,出去面试时先看看自己复习到了哪个阶段就好。下图是我进阶学习所积累的历年腾讯、头条、阿里、美团、字节跳动等公司2019-2021年的高频面试题,博主还把这些技术点整理成了视频和PDF(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节。
机器学习-数学基础02补充_李孟_新浪博客-程序员宅基地
文章浏览阅读248次。承接:数据基础02