搜索引擎之ElasticSearch(es)入门学习、ELK 和 beats_essearch 教程-程序员宅基地
技术标签: 学习 java elasticsearch 后端 搜索引擎
好记星不如烂笔头,这里记录平时工作中用到的东西,不喜可以留言。
一、ElasticSearch为啥要用
ElasticSearch简称es是一个ElasticSearch是一个分布式,高性能、高可用、可伸缩的搜索和分析系统 。可以当做一个上层数据库来使用和关系数据库和Nosql有一定区别和相似性。其他搜索引擎,Lucene(Es底层)、Apache Solr (底层Lucene)。使用es的几个原因:
- 关系型数据库模糊搜索不足索引,会全表扫描非常慢。%关键词%这种搜索会非常慢。主:关系型数据库支持的是%关键词,搜索非常快。
- 关系型数据库不支持全文搜索分词,
- eg 我想baidu搜索电影碟中谍-全面瓦解的时候,不小心打错了,打成了全瓦解,es就可以根据分词搜索出来这个电影。
- eg 企查查网站搜索的时候, 打成了 千穆 上海,es也能搜索出来所有的千穆相关的公司。
- eg 启信宝,搜索的时候 深圳特斯拉, es能搜索出来 几十个包含 深圳 和 特斯拉 相关的公司
在比如:搜索 上海千穆计算机xxx, 打成了 千穆 上海,es也能搜索出来的。
3. 数据分析、日志分析, PB级别可以毫秒级搜索,自带分析能力
4. mongo不支持restful api, 底层使用BSON放数据,es使用json
5. 看看阿里云上面大数据里面就是 ElasticSearch
6. ELKB是什么?ELK(ElasticSearch, logstash, kibana)技术栈的版本统一,免的给用户带来混乱。kibana是一个可视化的形式工具,用来检索和图形化es。
7. beats 是一个专门的数据采集工具,是 logstash的轻量级版本
数据采集程序:beats
可视化工具:grafana
监控:promethues
引用1:大白话ElasticSearch是什么以及应用场景
引用2:Springboot + ElasticSearch 构建博客检索系统 [慕课网]
引用3:ElasticSearch入门 [慕课网 瓦力]
引用4 ELK和beats ELK和beats
1 Es简单介绍
- java开发,生产使用es6,jdk8+, 提供统一的restful接口访问能力
- elasticSearch配套工具,kibana(web界面操作es)、logstash同步中间件 mysql和es数据、elasticsearch head插件 类似kibaba 非官网插件。
- 关系型数据库和es对比
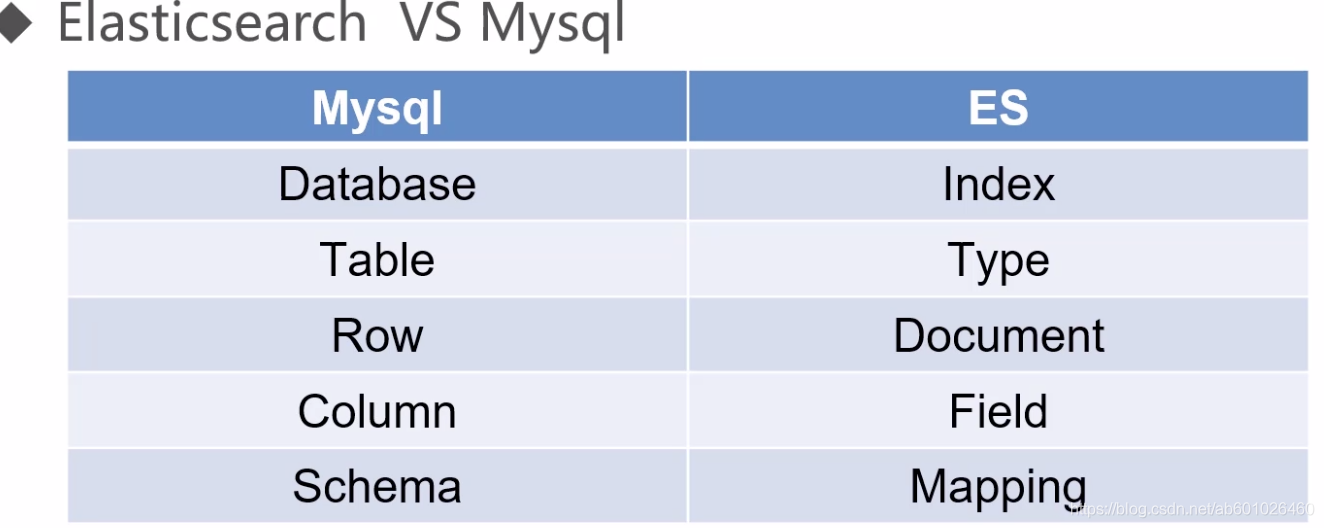
Mysql: Select * from user.user_info where name = ‘张三’;
ES: Get /user/user_info/_searchq=name:张三
ES7: 重大特点,去掉了Type
2 ES数据同步中间件
- 数据同步分为两种,全量和后期增量(新增、修改)
- 同步有:代码层在修改mysql的时候,同步更新es(缺点耦合,模块多很难维护);数据库层利用mysql binlog订阅,把es当做一个客户端; 使用 logstash配置mysql和es数据源并制定表格进行复制,支持多表。
- logstash-input-jdbc同时同步多个表 https://www.cnblogs.com/xuwenjin/p/8989043.html
3 springboot集成Es
- springboot增加es starter, 增加es 地址和端口9200
4 es分词插件
- es默认分词对中文支持非常差,我们一般会安装第三方中文分词插件,比如“我是中国人”,看分词插件如何分词
5 es免费资源课程
- imooc ElasticSearch入门
- imooc Springboot + ElasticSearch 构建博客检索系统
二.Es安装
es使用java开发,目前主流5+都可以,目前推荐使用6,最新的已经到7了。java使用java8+
2.1 es单实例安装、kibana安装
elaticsearch官方下载,到Download页面,下载老版本,请在该页面搜索"past releases"。
目前我们使用6.x版本,太新的版本资料和生态(springboot2.0)不完善,我们按照6.8.6版本。
2.1.1 找到下载地址&安装es
官网历史版本下载地址:elasticsearch-6-8-3,当然官网下载慢到死的,下载要么通过香港服务器下载==》下载到本地、或者网上搜索 Elasticsearch 国内镜像下载站。
#1: Download and unzip Elasticsearch
# yum list | grep -i elasticsearch # linux centos7 使用,但不推荐,我们自己下载安装把。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.8.3.zip #下载zip版本、.tar.gz、.msi等
wget https://elasticsearch.thans.cn/downloads/elasticsearch/elasticsearch-6.8.3.tar.gz # 下载国内地址
# 说明 zip版本、tar.gz版,其实都一样,类似 tomcat, 平台通用的。这里进行解压
unzip elasticsearch-6.8.3.zip #解压zip文件
tar -vxf elasticsearch-6.8.3.tar.gz #解压 tar.gz文件
2: Run bin/elasticsearch (or binelasticsearch.bat on Windows)
3: Run curl http://localhost:9200/ or Invoke-RestMethod http://localhost:9200 with PowerShell,运行之后发现只是一个是json, 可以使用 postman 调用 restful接口。如何判断启动成功:打印 started 并且打印 对外监听端口9200。说明:9300是多个节点nodes之前的通讯接口。
4: 下载kibana进行进行图形界面化操作。kibana版本最好和es一致,至少大版本一致的。
elasticsearch docs guide cn
2.1.2 安装kibana(web应用,图像化操作es)
kibana一个图像化操作工具,是一个web程序。
Elasticsearch是一个基于JSON的分布式搜索和分析引擎。
Kibana可以让您的数据变的有型有样,是一个可扩展的用户界面。
kibana国内下载地址 , elaticsearch国外站点巨慢。下载可以用迅雷,可能快很多。使用5601进行访问。kibana官方下载地址 。最后推荐使用华为的mirrors ,搜索kibana选择版本进行下载。
# Download and unzip Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.8.3-windows-x86_64.zip #windows
wget https://repo.huaweicloud.com/kibana/6.8.3/kibana-6.8.3-darwin-x86_64.tar.gz # mac os
wget https://repo.huaweicloud.com/kibana/6.8.3/kibana-6.8.3-linux-x86_64.tar.gz # linux 64
2 Open config/kibana.yml in an editor,Set elasticsearch.hosts to point at your Elasticsearch instance
3 Run bin/kibana (or binkibana.bat on Windows)
4 Point your browser at http://localhost:5601
所有kibana配置看
三.http restful和es进行交互
这里演示用postman 或者 curl 和 elastcisearch进行交互
## 查看索引,所有 索引,增加前缀;工具,直接可以提示 所有的索引
## 查看索引,所有 索引,增加前缀;工具,直接可以提示 所有的索引
##nuc_delivery
#nuc_location
#nuc_person_conn
#nuc_sys_dept
#sys_dict_data
#vfic_vaccinate_process
### 查询关键字,"" 会提示api关键词
#{
# "_index" : "nuc_positive_person",
# "_type" : "_doc",
# "_id" : "1474694263478657024",
# "_score" : 4.3594446,
# "_source" : {
# "person_id" : null,
# "person_name" : "刘xx",
# "id_card" : "61272619XX07070010",
# "person_phone" : "135XXXX8166",
# "collect_org_name" : "西安市曲江新区新型冠状病毒感染的肺炎疫情防控指挥部",
# "collect_location_name" : null,
# "collect_time" : "2021-12-25T08:02:15+08:00",
# "check_org_name" : "西安金域医学检验所有限公司",
# "check_time" : "2021-12-25T18:43:07+08:00",
# "swab_result" : "阳性",
# "igg_result" : null,
# "igm_result" : null,
# "progress" : "0",
# "create_time" : "2021-12-25T18:51:26+08:00",
# "audit_time" : null,
# "audit_user_id" : null,
# "publish_time" : null,
# "publish_user_id" : null,
# "repeal_time" : null,
# "repeal_user_id" : null,
# "tube_code" : "-",
# "collect_limit" : 1,
# "collect_location_type" : null,
# "add_time" : null
# }
### 1、查看所有的索引【表】名称
GET /_cat/indices?format=json
### 2、查看集群监控状态
### kibana Dev Tools常用命令 https://www.cnblogs.com/bigfacecat-h/p/14500466.html
GET /_cat/health?format=json
### 3、查看指定索引(表)中的一条数据document(column)详细数据
### 3、 查看索引【nuc_sys_dept】中文档id【id】 = 100的文档
GET nuc_sys_dept/_doc/100
### 4、查看指定所有的总条数
### Elasticsearch查询文档总数 https://www.cnblogs.com/jamh/p/14975903.html
#### 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/cat-count.html
### GET /_cat/count/<target>
### v=true: 是否包含列
### 查看索引[表] 总条数
GET /_cat/count/nuc_positive_person?v=true
### 查看指定文件的的详情数据
GET /nuc_positive_person/_doc/1462095480748158976
### 按照搜索
### 查询条件
### 2.x 中文(Elasticsearch: 权威指南 ? 基础入门 ? 请求体查询 ? 最重要的查询)(https://www.elastic.co/guide/cn/elasticsearch/guide/current/_most_important_queries.html#_match_all_查询)
### 7.x 英文 (Elasticsearch Guide [7.16] ? Query DSL ? Full text queries)(https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-queries.html)
GET /_cat/count/nuc_positive_person?v=true
{
"query": {
"match": {
"id_card": "610632199010202035"
}
}
}
###### 5、查询语句
###### 5.1 query/match 【匹配】
###### id_card 是文档中的字段
GET /nuc_positive_person/_search
{
"query": {
"match": {
"id_card": "610632199010202035"
}
}
}
###### 5.2 query/match/(query|fuzziness[中文:模糊性]) 【类似like匹配】
### person_name:需要like的字段
### query: person_name的查询条件,如:姓`张`(query)的用户, auto自动模糊fuzziness
GET /nuc_positive_person/_search
{
"query": {
"match": {
"person_name": {
"query": "军",
"fuzziness": "auto"
}
}
}
}
###### 5.3 范围(range)查询,日期、数字或字符串字
## https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html#_ranges
### 范围查询 https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-range-query.html
### 查询 采样上线 collect_limit >= 5 and collect_limit <= 10
# query: 查询, range:执行范围查询
# sort: 指定排序规则
# from: 指定分页start
# from: 指定分页size
# aggs: 聚合函数
# aggs: avg: 指定字段平均数
# ElasticSearch - 聚合 aggs https://blog.csdn.net/weixin_40341116/article/details/81173016
# ES之五:关于Elasticsearch查找相关的问题汇总(match、match_phrase、query_string和term) https://www.cnblogs.com/duanxz/p/3508338.html
GET /nuc_positive_person/_search
{
"query": {
"range": {
"collect_limit": {
"gte": 5,
"lte": 10,
"boost": 2.0
}
}
},
"sort": [
{
"collect_time": {
"order": "desc"
}
}
],
"aggs": {
"my_avg_collect_limit": {
"avg": {
"field": "collect_limit"
}
}
},
"from": 0,
"size": 2
}
###### 5.4 范围(range)查询,日期
## 采样时间:collect_time >gte and <= now
GET /_cat/count/nuc_positive_person?v=true
{
"query": {
"range": {
"collect_time": {
"time_zone": "+08:00",
"gte": "2021-12-31T00:00:00",
"lte": "now"
}
}
}
}
############################################################
### 6.核算检测系统,数据量查询
### nuc_person_query #人员信息索引(nuc_person)
### nuc_tube_person 已经废弃xxx
### nuc_tube ## 试管 db(nuc_tube)
### nuc_tube_person_conn_new
################################################
GET /_cat/count/nuc_tube?v=true
{
"query": {
"range": {
"collect_time": {
"time_zone": "+08:00",
"gte": "2021-12-29T00:00:00+08:00",
"lte": "2021-12-31T00:00:00+08:00"
}
}
}
}
### 7.聚合查询 - 分组
## ES 24 - 通过 Elasticsearch 实现聚合检索 (分组统计)
### https://www.cnblogs.com/shoufeng/p/11290669.html
## Elasticsearch 5.4.3 聚合分组 https://www.cnblogs.com/shoufeng/p/11290669.html
### 查询一条信息
GET /vfic_project/_search
{
"from": 0,
"size": 1
}
### 查询总条数
GET /_cat/count/vfic_project?v=true
### field 字段,必须是指定的字段,否则报错。
### 使用 部门进行分组
GET /vfic_project/_search
{
"from": 0,
"size": 1,
"aggs": {
"group_by_tags—deptId": {
"terms": {
"field": "dept_id"
}
}
}
}
### 8、删除疫苗无效的数据
##ES 16 - 增删改查Elasticsearch中的索引数据 (CRUD)
## https://www.cnblogs.com/shoufeng/p/10701141.html#4--删除document
GET /_cat/count/vfic_vaccinate_process?v=true #26558256
GET /_cat/count/vfic_vaccinate_processnew?v=true #0
GET /vfic_vaccinate_process/_search
{
"from": 0,
"size": 10,
"query": {
"match": {
"person_id_card": "61100220120503XXXX"
}
}
}
### 根据文档id进行查询
GET vfic_vaccinate_process/_doc/2186576
## 根据文档document的id 进行删除
## 语法:DELETE index/type/id
DELETE vfic_vaccinate_process/_doc/2043053
1、Elasticsearch: 权威指南 ? 基础入门 ? 请求体查询 ? 最重要的查询
2、Elasticsearch Guide [7.16] ? Query DSL ? Full text queries
-
1:GET 查看所有的索引
curl -XGET http://localhost:9200/_all #查询所有的索引
-
2:PUT 创建一个索引-person
curl -XPUT http://localhost:9200/person #创建一个索引 person 人类
-
3:DELETE 删除一个索引
curl -XDELETE http://localhost:9200/person #删除一个索引
-
4:PUT 新增数据
新增一条 userid = 1 的用户
curl -H “Content-Type: application/json” -XPUT http://localhost:9200/person/_doc/1 -d ‘{“first_name”:“John”,“last_name”:“Smith”,“age”:25,“about”:“I love to go rock climbing”,“interests”:[“sports”,“music”]}’
json格式化如下
{
“first_name”:“John”,
“last_name”:“Smith”,
“age”:25,
“about”:“I love to go rock climbing”,
“interests”: [“sports”, “music”],
}新版本6.0x, 目前一个索引person【类似一个数据库】,只有一个type【类似一个表】,我们用官网推荐的_doc【目前一个索引里面只有一个type,我们统一用_doc】,或者自定义一个 user 来代表。1:是id=1的数据。
https://www.cnblogs.com/gshao/p/11010642.html
-
5:搜索数据
我们尝试搜索一条数据,搜索 person索引中 默认类型_doc中id=1的数据
person_id
curl -XGET http://localhost:9200/person/_doc/1
person_name (进阶搜索)
curl -XGET http://localhost:9200/person/_doc/_search?q=first_name:john #_search系统搜索关键词
四.使用Kibana Dev Tools 操作es
这里演示用Kibana 和 elastcisearch进行交互, 其实和直接使用 curl 或者 postman都是一样的。
这里提供了,智能的提示。

#搜索所有
GET _all
# 搜索 person, es6.0之后,官方推荐_doc可以不写
GET /person/_doc/1
# 在演示一个【结构化查询】DSL 语句写法
# 这里,我们es6+,只有一个type,直接省略_doc
# 查询语句是json
# query 是查询,全文检索
# book 需要返回bool类型
# 【should】: 应该要做什么,类似sql 【or】
# 【should】变成 【must】: 必须要,类似 sql 【and】
# match 匹配,做具体的字段搜索, 可以是多个匹配条件。
# last_name: 姓名是 Smith, about 爱好是: basketball
#
POST /person/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"last_name": "Smith"
}
},
{
"match": {
"about": "basketball"
}
}
]
}
}
}
其他更多演示,进阶演示,见 【ES】ElasticSearch 结构化查询和过滤
五、数据同步Beats vs Canal
beats: 定时同步
Canal: 实时同步
智能推荐
Tensorflow模型预测时,若用CPU计算,如何设置? 并行计算-多核(multicore),多线程(multi-thread)_tensorflow如何实现cpu pool并行-程序员宅基地
文章浏览阅读1.2w次,点赞3次,收藏23次。在标准系统上通常有多个计算设备.TensorFlow 支持 CPU 和 GPU 这两种设备. 用指定字符串来标识这些设备. 比如:"/cpu:0": 机器中的 CPU"/gpu:0": 机器中的 GPU, 如果你有一个的话."/gpu:1": 机器中的第二个 GPU, 以此类推...在Tensorflow程序中,我们会经常看到 with tf.device("/cpu:0"): 这个语..._tensorflow如何实现cpu pool并行
将iPad作为Windows电脑副屏的几种方法_ipad作为windows扩展屏-程序员宅基地
文章浏览阅读6.1w次,点赞18次,收藏118次。有时候Windows电脑的副屏使用(适用于台式机及笔记本电脑),充分利用iPad的便携性;将iPad合理利用,来增强生产力。以下给大家介绍了几种iPad作为Windows台式机副屏的几种方法。_ipad作为windows扩展屏
查找恢复密钥_windows11恢复密钥官网-程序员宅基地
文章浏览阅读2.7w次。登陆自己的微软账号可查看恢复密钥,点击以下链接查找恢复密钥:https://account.microsoft.com/devices/recoverykey根据密钥ID,输入对应的恢复密钥。_windows11恢复密钥官网
计算机功能区各部分,Win8.1资源管理器窗口各部分名称是什么(适于Win8)?-程序员宅基地
文章浏览阅读2.1k次。Win8.1资源管理器窗口各部分名称是什么(适于Win8)?使用了Win8.1这么长时间,Win8.1的资源管理器的窗口,很多位置都不知道名称是什么,总感觉多少有些对不住微软,而且以后看高手介绍的相关内容,倘若使用这些窗口的专业名称,让人似懂不懂的,实在是让人汗颜,针对这个问题,笔者编辑了下面的内容,相信对您了解Win8或者Win8.1,资源管理器的窗口各部分的名称是有帮助的!还是以Win8.1为..._资源处理器窗口各名称
1、 赛灵思-Zynq UltraScale+ MPSoCs:产品简介_apu a53-程序员宅基地
文章浏览阅读6.1k次,点赞11次,收藏55次。1、 赛灵思-Zynq UltraScale+ MPSoCs:产品简介_apu a53
better-scroll切换栏吸顶效果_better scroll 吸顶-程序员宅基地
文章浏览阅读1.5k次。在better-scroll里使用position:sticky会无效,使用position:fixed定位会被better-scroll自身实现过程的tanslate给位移出去解决方法: 做两个切换栏,一个在better-scroll外,一个在内,当达到临界值时,通过v-if指令,让内部隐藏,外部显示,外部可以使用postion:fixed达到吸顶的效果代码示例:<template> <div class='home'> <NavBar title_better scroll 吸顶
随便推点
串口RS232的学习_232tx和rx-程序员宅基地
文章浏览阅读4.9k次,点赞4次,收藏42次。《FPGA Verilog开发实战指南——基于Altera EP4CE10》2021.7.10(上)串口RS232的学习_232tx和rx
2019年最新编程语言排行榜出炉TIOBE_2019 计算机语言排行榜-程序员宅基地
文章浏览阅读2.9w次,点赞7次,收藏12次。Python编程语言赢得了“年度编程语言”的称号!Python已经获得了这个称号,因为与其他所有语言相比,它在2018年获得了最多的排名。Python语言赢得了3.62%,其次是Visual Basic .NET和Java。Python现在已经成为大型编程语言的一部分。近20年来,C,C ++和Java一直位居前三,远远领先于其他公司。Python现在正在加入这三种语言。它是当今大学中最常用的第一..._2019 计算机语言排行榜
目标检测MMDetection_mmdetection 检测头-程序员宅基地
文章浏览阅读1.4k次。论文:MMDetection: Open MMLab Detection Toolbox and BenchmarkGithub:https://github.com/open-mmlab/mmdetection.git商汤和港中文开源的一个集成很多主流目标检测算法的检测框架,提供了超过200多个预训练模型。相比Facebook开源的Detectron框架,作者声称mmdetecti..._mmdetection 检测头
uos应用_UOS就是Deepin V20?-程序员宅基地
文章浏览阅读214次。Hello,小伙伴们打扎好。上期呢我发了个视频合集是关于Deepin V20的。当时下面我也提到自己在申请成为UOS的内测,不过一周过去了还没有消息。于是就去网上找了别的内测开发者放出来的内测系统镜像文件,来验证一下是不是UOS就是Deepin V20毕竟通过相关的媒体报道和视频对比来看真的 太相似了,一些old out自媒体直接把uos作为Deepin V20。不过本身其实也没有什么好意外的,毕..._deepin v20 uos
Dex-Net 2.0 论文翻译_deep learning a grasp function for grasping under -程序员宅基地
文章浏览阅读7.9k次,点赞3次,收藏32次。一、绪论1)本文的主要贡献 1、制作dex-net2.0数据集,该数据集包括670万点云数据,又从1500个 3D模型通过GWS(抓手运行空间分析)得到手爪的运行规划 2、设计Grasp Quality Convolutional Neural Network (GQ-CNN),去得到一系列鲁棒性良好的抓取规划 3、设置一种抓取机制,可以对得到的鲁棒性良好的一组抓取规划进行 rank排序,_deep learning a grasp function for grasping under gripper pose uncertainty
JJwt生成Token-程序员宅基地
文章浏览阅读646次。JJwt生成tokenjava中通过jjwt生成tokenpackage com.zom.statistics.tools;import com.zom.statistics.DTO.JwtParams;import com.zom.statistics.DTO.RtvConsoleUser;import com.zom.statistics.exception.LogonException;import io.jsonwebtoken.*;import org.slf4j.Logger_jjwt生成token