Hadoop 平台搭建完整步骤_/opt/app/hadoop-3.1.4/etc/hadoop/hadoop-env.sh:行98-程序员宅基地
Hadoop 平台搭建完整步骤
环境准备
也可以用VMware.
创建三台虚拟机 hd-master、hd-node1、hd-node2 三台虚拟机服务器中的主机名(hostname)分别更改为master、node1、node2。
创建好虚拟机之后
(1) 我们为了能够更加方便来识别主机,我们使用主机名而不是使用IP地址,以免多处配置带来更多的麻烦。把hd-master、hd-node1、hd-node2三台虚拟机服务器中的主机名(hostname)分别更改为master、node1、node2。
命令如下:
cd /etc/? ?// 进入配置目录
vi hostname? // 编程hostname 配置文件

先点击 Esc : wq 保存
在另外两个节点上进行相同的操作
(2)开启主机的DHCP模式,自动获取ip地址。方法如下:
cd /etc/sysconfig/network-scripts/ //进入网卡编辑目录
vi ifcfg-enp16777736 //编辑网卡enp0s3的配置文件

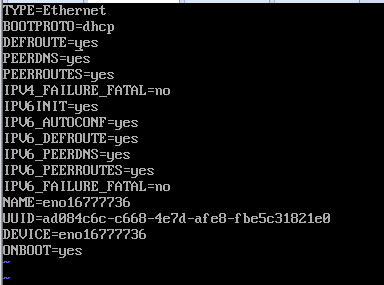
重启网卡 service network restart
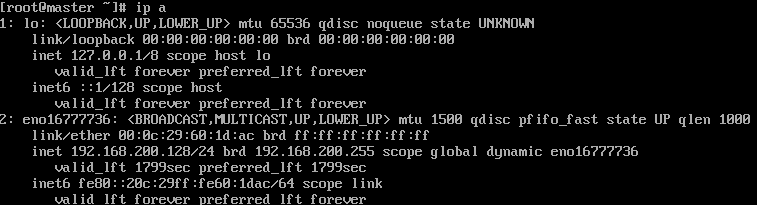
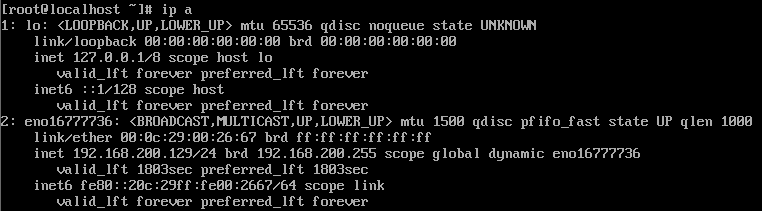
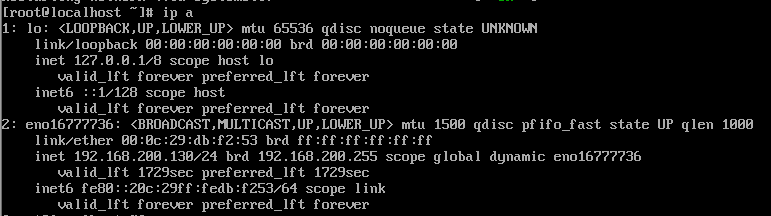
三个虚拟机的ip都记一下
master
node1
node2
(3) 配置hosts
配置 hosts 主要是为了让机器能够相互识别主机
_注:_hosts__文件是域名解析文件,在__hosts__文件内配置了 ip__地址和主机名的对应关系,配置之后,通过主机名,电脑就可以定位到相应的__ip__地址 。
vi /etc/hosts
在hosts配置文件内容输入如下内容:使用同样的方式更改node1和node2的网卡配置。

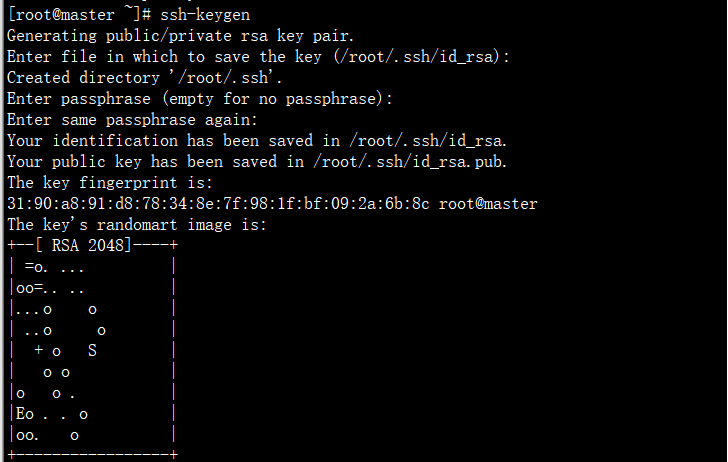
(4) ssh 免密登录
ssh 一路回车
ssh-keygen
使用如下命令将公钥复制要node1和node2节点中:
ssh-copy-id root@node1
ssh-copy-id root@localhost
ssh-copy-id root@node2
使用 ssh node1 实验是否能免密登录
_注意:_ssh__免密设置后会在如下目录生成四个文件

(5) JDK环境安装(环境配置好后, 拷贝带其他节点)
在 master 中新建目录 /opt/bigdata/, 此目录下存放 hadoop 大数据所需要的环境包.
- 把下载好的JDK包和hadoop上传至master主机中,JDK是安装Hadoop的基础环境,所以需要优先安装好JDK环境(最好把包考到opt目录下下)

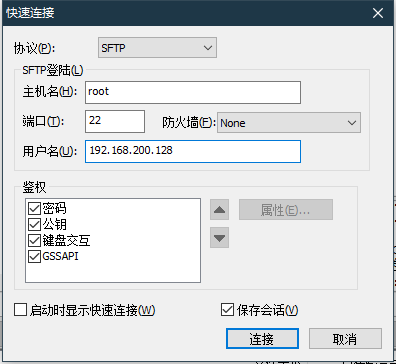
连接好后将文件拖到opt目录下即可
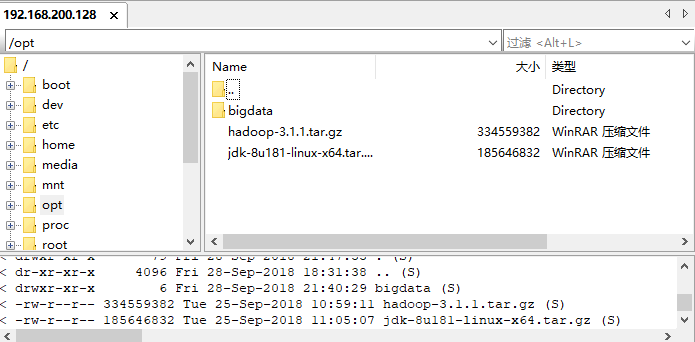
-
解压 JDK 并配置环境变量
tar -zxvf jdk-8u181-linux-x64.tar.gz
mv jdk1.8.0_181/ bigdata/
-
然后我们配置环境变量
vi /etc/profile
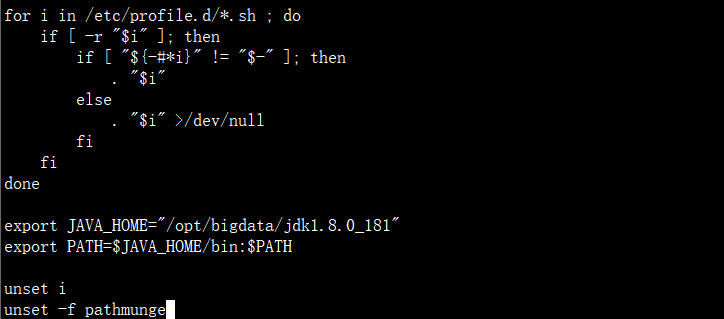
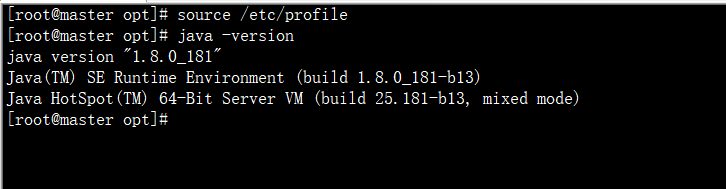
source /etc/profile
java -version #验证环境是否配置成功
(6)Hadoop 安装(环境配置好后, 拷贝带其他节点)
- 把 hadoop 的压缩包解压在当前文件夹然后移动到 bigdata 目录下
tar -zxvf hadoop-3.1.1.tar.gz
mv hadoop-3.1.1 bigdata/
- 配置 hadoop 环境变量
- 注:环境变量是让系统变量,在环境变量配置的命令目录后,该目录的命令将可以在任何位置都可以使用。
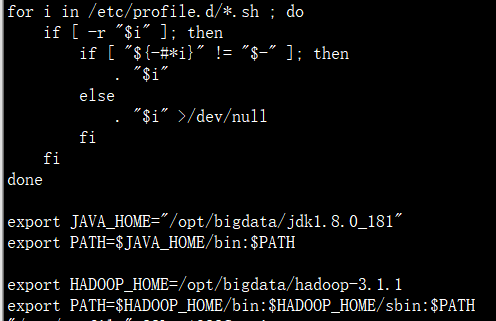
source profile
hadoop verison
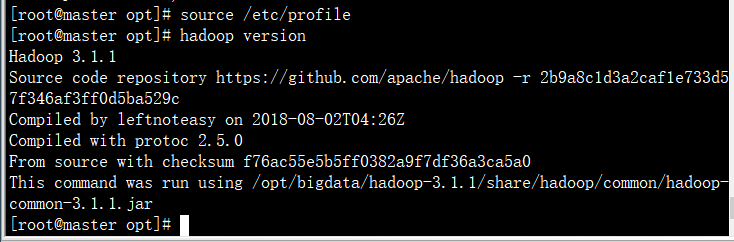
配置 hadoop
cd /opt/bigdata/hadoop-3.1.1/etc/hadoop/
我们需要对 core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xml进行配置
(1) 配置hadoop-env.sh
编辑hadoop-env.sh文件。
命令如下:
vi hadopp-env.sh
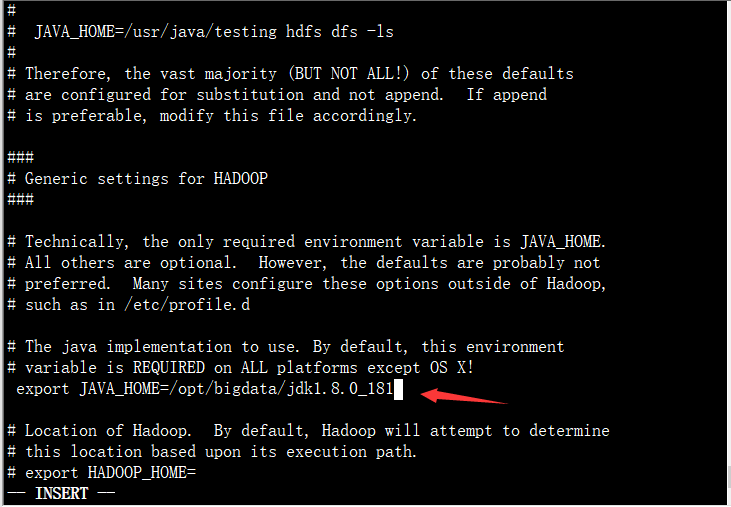
查找JAVA_HOME 配置的位置
:/export JAVA_HOME
输入JAVA_HOME的绝对路径。
export JAVA_HOME=/opt/bigdata/jdk1.8.0_181 (要把前面的注释#去掉)
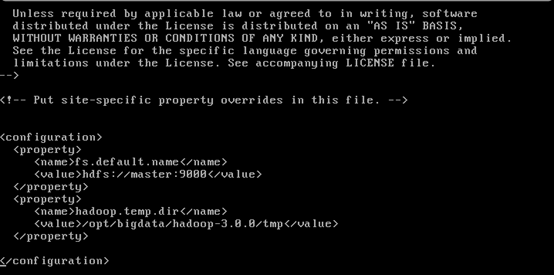
(2)配置core-site.xml
编辑core-site.xml文件。
vi core-site.xml
进入core-site.xml文件中结构如下所示,找到configuration的位置。
<configuration> <property> <name>fs.default.name</name> <value>localhost:9000</value> </property> <property> <name>hadoop.temp.dir</name> <value>/opt/bigdata/hadoop-3.1.1/temp</value> </property> </configuration>
(3) 配置 hdfs-site.xml
vihdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/opt/bigdata/hadoop-3.1.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/bigdata/hadoop-3.1.1/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0.50070</value>
</property>
</configuration>
(3)配置mapred-site.xml
vimapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
</property>
</value>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/bigdata/hadoop-3.1.1/etc/hadoop,
/opt/bigdata/hadoop-3.1.1/share/hadoop/common/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/common/lib/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/hdfs/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/hdfs/lib/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/mapreduce/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/mapreduce/lib/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/yarn/*,
/opt/bigdata/hadoop-3.1.1/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
(5)配置yarn-sit.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8099</value>
</property>
(6)配置workers
此处因为前面配置了hosts,所以此处可以直接写主机名,如果没有配置,必须输入相应主机的ip地址。配置的workers,hadoop会把配置在这里的主机当作datanode。
node1
node2
(7)hadoop****复制到其他host
把hadoop复制到所有datanode节点,此处是node1和node2。
命令如下:
scp -r * node1:/opt/ scp -r * node2:/opt/
starta-all.sh 启动
智能推荐
SQL Server导入导出不丢主键和视图的方法_sqlyog导出数据库时忽略主键-程序员宅基地
文章浏览阅读1k次。SQL Server导入导出不丢主键和视图的方法SQLServer导入导出SQLServer导入导出工具/原料使用MicrosoftSQLServerManagementStudio导入导出数据。直接使用MicrosoftSQLServerManagementStudio导入导出数据会丢失主键、视图等等。正确的保存方法如下:一、选择本地的..._sqlyog导出数据库时忽略主键
13位时间戳接口(淘宝、京东、苏宁、华为、美团)2023-4-2更新_京东时间戳-程序员宅基地
文章浏览阅读1.1w次,点赞16次,收藏59次。淘宝http://api.m.taobao.com/rest/api3.do?api=mtop.common.getTimestamp苏宁 http://quan.suning.com/getSysTime.do_京东时间戳
微信小程序:uni-app 小程序打包超过2M限制的方法—分包加载_uni-app有没有必要分包-程序员宅基地
文章浏览阅读1.8w次,点赞4次,收藏32次。起初小程序上线时,微信限制了代码包不能超过1MB,后来功能变大变成了2M了,限制大小是出于对小程序启动速度的考虑,希望用户在使用任何一款小程序时,都能获得一种“秒开”体验。但是,2MB也限制了小程序功能的扩展,小程序业务的发展可能需要更大的体积。为了解决这个问题,微信推出了—分包加载。_uni-app有没有必要分包
Git从入门到放不下_git 是一种分布式版本控制系统,它可以不受网络连接的限制,加上其它众多优点,目前-程序员宅基地
文章浏览阅读366次。Git简介Git是一种分布式版本控制系统,它可以不受网络连接的限制,加上其它众多优点,目前已经成为程序开发人员做项目版本管理时的首选,非开发人员也可以用Git来做自己的文档版本管理工具。2013年,淘宝前端团队开始全面采用Git来做项目管理,我也是那个时候开始接触和使用,从一开始的零接触到现在的重度依赖,真是感叹Git的强大。Git的api很多,但其实平时项目中90%的需求都只需要用到几个基本的功能即可,所以本文将从实用主义和深入探索2个方面去谈谈如何在项目中使用Git..._git 是一种分布式版本控制系统,它可以不受网络连接的限制,加上其它众多优点,目前
SM2(国密)非对称(公钥私钥)在线加密解密_sm2在线加密-程序员宅基地
文章浏览阅读6.9k次。SM2是中国国产的公钥私钥加解密算法,采用的是ECC 256位的一种,其秘钥长度256bit,包含数字签名、密钥交换和公钥加密,用于替换RSA/DH/ECDSA/ECDH等国际算法_sm2在线加密
BurpSuite安装和配置_burpsuite社区版-程序员宅基地
文章浏览阅读969次,点赞20次,收藏18次。BurpSuite安装和配置_burpsuite社区版
随便推点
casperjs使用说明-使用命令行_casperjs清除缓存-程序员宅基地
文章浏览阅读1.7k次。Casperjs使用内置的phantomjs命令行解析器,在cli模块里,它传递参数位置的命名选项 但是不要担心不能熟练操控CLI模块的API,一个casper实例已经包含了cli属性,允许你很容易的使用他的参数让我们来看这个简单的casper脚本:var casper = require("casper").create();casper.echo("Casper CLI passed_casperjs清除缓存
股票量化交易软件:什么是趋势,行情结构是基于趋势还是横盘?_横盘的股票是被量化了吗-程序员宅基地
文章浏览阅读62次。他们认为:“好吧,我简单地令获利成交的平均规模比亏损成交的平均规模大两倍,并开仓 ... 或是说,在移动平均线的交点处(此处的入场算法并不重要)。由于赫兹股票量化交易的价格变化以点数(最小可能的价格变化)为基础,并且利润取决于价格已覆盖了多少点数,因此我们需要远离以蜡烛/柱线表示价格的标准方式,因为它们会极大地扭曲图形,令过程难以理解。在经济学中,趋势是经济指标的总体方向。这意味着,如果获利成交的概率为 50%,而获利成交的平均大小等于亏损成交的大小,则期望值为 0,这意味着赫兹股票量化一无所获。_横盘的股票是被量化了吗
ICCV 2023|PViC:构建交互谓词视觉上下文,高效提升HOI Transformer检测性能_predicate visual context-程序员宅基地
文章浏览阅读216次。在本文中,作者首先分析了现有基于DETR框架的两阶段HOI检测器中的视觉特征建模效果,并得出结论,它们的主要弱点是缺乏与当前谓词动作相关的上下文信息,因为它们原来是专门针对定位任务设计和训练的。因此本文提出了一种改进的设计,通过交叉注意力将图像特征重新引入人-物体对表示中,为此,本文作者对注意力计算中的键和查询向量的构建进行了重新设计,并引入边界框的位置编码作为空间引导,来实现更加明确的计算人-物交互的交叉注意力。_predicate visual context
KVM安装Windows11系列(一)_kvm windows-程序员宅基地
文章浏览阅读9k次,点赞4次,收藏22次。本教程系列为KVM安装Windows11,会分成两部分,第一部分会跳过Windows11的硬件要求TPM和安全启动,第二部分会安装TPM模拟器进行模拟。_kvm windows
SiamFT:通过完全卷积孪生网络进行的RGB红外融合跟踪方法-程序员宅基地
文章浏览阅读4.7k次,点赞11次,收藏52次。SiamFT:通过完全卷积孪生网络进行的RGB红外融合跟踪方法_siamft
【软考高项】【教材知识梳理】- 13 - 第13章 - 项目资源管理-程序员宅基地
文章浏览阅读384次,点赞10次,收藏11次。项目资源管理(合理分配实物和人力资源)1:资源管理包括()资源和()资源?(1)实物资源特点:有效和高效地分配、使用完成项目所需的实物资源。包含:设备、材料、设施和基础设施。(2)团队资源(又称人力资源)特点(1)有技能和能力的要求(2)可能全职或者兼职(3)可能随项目增加或者减少目的a.按需要组建团队b.对团队绩效有效的指导和管理c.保证他们完成任务,实现目标2:项目经理的权力有5种来源,是什么?(1)职位权力(2)惩罚权力(3)奖励权力(4)专家权力。