graylog使用总结这一篇就够了-程序员宅基地
技术标签: spring boot graylog
graylog使用总结.md
大纲
- 概念
- springboot集成graylog
- gelf详细配置说明
- graylog搜索语法
- graylog控制台使用
- 问题总结
概念
Graylog 官网 https://www.graylog.org/
Graylog 教程 https://docs.graylog.org/docs/lookuptables
选择graylog的原因是:
- 1 轻量化,springboot可以直接接入到graylog不需要其他的配置
- 2 简单,单机版可以满足大部分非高并发行公司的业务日志查询
部署 graylog 最简单的架构就是单机部署(足够满足医蟹这种体量的公司使用),复杂的也是部署集群模式
Graylog 的组件主要有3个
- Elasticsearch
- MongoDb
- Graylog
Elasticsearch 用来持久化存储和检索日志文件数据(IO 密集)
MongoDb 用来存储关于 Graylog 的相关配置
Graylog 来提供 Web 界面和对外接口的(CPU 密集)

graylog的安装见《Graylog安装总结.md》此处假设已经将graylog安装完成
springboot集成graylog
基础概念
springboot集成graylog 主要是使用logback-gelf (搭建graylog的指定GELF 暴露的端口就是为此处使用的)
step1 项目引入logback-gelf
pom.xml文件中加入
<dependency>
<groupId>de.siegmar</groupId>
<artifactId>logback-gelf</artifactId>
<version>3.0.0</version>
</dependency>
这样就可以再logback配置文件中加入 GelfTcpAppender GelfUdpAppender
step2 项目logback文件中加入 Gelf Appender
1 在application.properties 中指定logback的配置文件
logging.config=classpath:logback-logstash-graylog.xml
2 在 logback-logstash-graylog.xml 配置文件中加入GelfTcpAppender
<appender name="GELF_TCP" class="de.siegmar.logbackgelf.GelfTcpAppender">
<!-- Graylog服务的地址 -->
<graylogHost>192.168.0.211</graylogHost>
<!-- TCP Input端口 -->
<graylogPort>12201</graylogPort>
<encoder class="de.siegmar.logbackgelf.GelfEncoder">
<!-- 是否发送原生的日志信息 -->
<includeRawMessage>false</includeRawMessage>
<includeMarker>true</includeMarker>
<includeMdcData>true</includeMdcData>
<includeCallerData>false</includeCallerData>
<includeRootCauseData>false</includeRootCauseData>
<!-- 是否发送日志级别的名称,否则默认以数字代表日志级别 -->
<includeLevelName>true</includeLevelName>
<shortPatternLayout class="ch.qos.logback.classic.PatternLayout">
<pattern>%m%nopex</pattern>
</shortPatternLayout>
<fullPatternLayout class="ch.qos.logback.classic.PatternLayout">
<pattern>#[%level] %d{yyyy-MM-dd HH:mm:ss.SSS } %thread %logger{35} - %msg %n</pattern>
</fullPatternLayout>
<!--
配置应用名称(服务名称),通过staticField标签可以自定义一些固定的日志字段
-->
<staticField>app_name:saas-task-server-AKA-TCP</staticField>
<staticField>my_field1:9991</staticField>
</encoder>
</appender>
也可以使用UDP通信的 GelfUdpAppender 见logback-logstash-graylog.xml 中的配置
区分项目过滤
使用app_name:saas-task_server 固定项目名称

此时项目部分就配置完成了
step3 配置GrayLog
此时需要配置GrayLog 的input选择 新增TCP 或 UDP 的输入



如果创建UDP的输入同理


step4 测试日志收集
访问 GraylogController 中的mapping
http://127.0.0.1:8881/g/t3?b=2


gelf详细配置说明
GELF是一种日志格式,能避免传统意义上的 syslogs的一些问题,而我们引入的Maven依赖则是把日志格式化成GELF格式然后append到GrayLog上。
graylog 搜索语法
语法搜索: https://docs.graylog.org/docs/query-language (用chorme打开)
输入框中输入内容默认是搜索 message字段中的内容

这里主要是注意 空格表示OR ""框起来表示整体
- 输入一个单词MM 表示message内容中有MM
- 输入两个单词MM KFC 表示message内容中有MM 或者 KFC
- 输入"MM KFC" 表示精确匹配
** 1 字段查询**
字段名称:内容
例如
app_name:saas-task-server-FFFJJ 精确匹配app_name字段内容为saas-task-server-FFFJJ
app_name:med* 使用正则匹配pp_name字段内容为med开头的
app_name:(med* saas-task*) 可以配置app_name字段内容为多个的
** 2 范围查询**
http_response_code:[500 TO 504]
http_response_code:{400 TO 404}
bytes:{0 TO 64]
http_response_code:[0 TO 64}
或者这是大于小于号
http_response_code:>400
http_response_code:<400
http_response_code:>=400
http_response_code:<=400
http_response_code:(>=400 AND <500)
** 3 关键字**
- AND
- OR
- NOT
注意需要大写
4 通配符
Use ? to replace a single character or * to replace zero or more characters:
graylog控制台使用
查询控制面板的使用

报警与通知

创建email通知
graylog配置支持
创建邮件通知前需要先在graylog配置中开启并配置邮件发送相关配置 (见《Graylog安装总结.md》)
transport_email_enabled = true
transport_email_hostname = smtp.mxhichina.com
transport_email_port = 587
transport_email_use_auth = true
transport_email_auth_username = [email protected]
transport_email_auth_password = xxxxx
transport_email_subject_prefix = [graylog-mail]
transport_email_from_email = [email protected]
transport_email_use_tls = true
**注意选择邮件服务器和端口可能是587 465 具体看邮件服务器提供商 阿里云使用587端口 **
选择创建通知

配置邮件



创建http通知
配置http通知
http 通知可以警告消息发送给自己的服务器

消息通知的数据格式
graylog会发送一个http post json请求到对应的url地址,json数据内容如下
{
"event_definition_id": "this-is-a-test-notification",
"event_definition_type": "test-dummy-v1",
"event_definition_title": "Event Definition Test Title",
"event_definition_description": "Event Definition Test Description",
"job_definition_id": "<unknown>",
"job_trigger_id": "<unknown>",
"event": {
"id": "NotificationTestId",
"event_definition_type": "notification-test-v1",
"event_definition_id": "EventDefinitionTestId",
"origin_context": "urn:graylog:message:es:testIndex_42:b5e53442-12bb-4374-90ed-0deadbeefbaz",
"timestamp": "2020-05-20T11:35:11.117Z",
"timestamp_processing": "2020-05-20T11:35:11.117Z",
"timerange_start": null,
"timerange_end": null,
"streams": [
"000000000000000000000002"
],
"source_streams": [],
"message": "Notification test message triggered from user <admin>",
"source": "000000000000000000000001",
"key_tuple": [
"testkey"
],
"key": "testkey",
"priority": 2,
"alert": true,
"fields": {
"field1": "value1",
"field2": "value2"
}
},
"backlog": []
}
服务器端接收数据的方式
- 直接使用inputstream
- 基于graylog发送的json 自定义bean
直接使用inputstream

基于graylog发送的json 自定义bean (推荐)

创建报警
创建报警配置

基础配置

配置匹配条件与频率

配置匹配结果
- Filter has results : 匹配一个就报警
- Aggregation of results reaches a threshold: 满足聚合后的量才报警(例如出现几次异常才报警)

配置自定字段
配置自定义字段内容是一个关键,可以把日志中的一些数据发送出去!便于问题排查


自定义自定会以fields Map 作用json发送

可以使用以下字段作为 自定义字段数据(即graylog 当前search支持的显示字段即可)

配置通知方式
选择已经配置好的通知即可 可以是邮件 可以是http


最后点击 Done完成配置
输入input 数据流streams 索引index
默认情况下是需要配置一个input 就可以自动与all-message streams绑定 做到开箱即用
但是我们有可能想对不同的项目,使用不同的streams 使用不同的索引管理日志,例如 nginx的日志保存3天 业务日志保存一个月
input streams index 的关系如下

注意数据
配置一个自定义的streams 做日志管理
Step1 创建一个 input
理论上只需要一个input即可

以下是为了展示多个input的使用

注意 如果是docker安装 要提前暴露端口
Step2 创建一个 index 索引



Step3 创建一个 streams 数据流

注意 一定要勾选 Remove matches from ‘All messages’ stream 这样数据不会到All messages中
创建完成后 点击管理规则


**规则的匹配方式有很多 **
例如 可以匹配某个字段是否是某个值
比如 app_name 是否是 saas-task-server-FFF 这样可以做项目间的区分
这里我们使用匹配 input

配置完规则后 可以测试下是否匹配成功


Step4 search面板中找到自己创建的stream
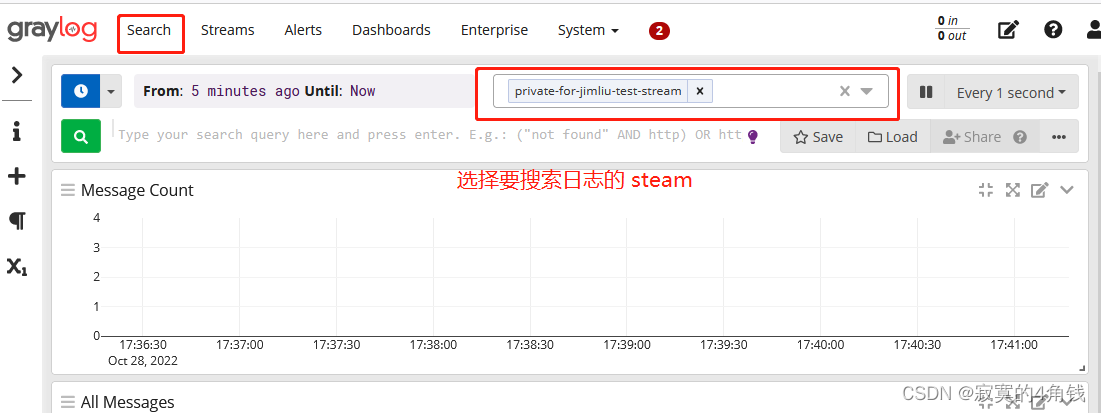
问题总结
如果Graylog宕机后 会影响程序么
测试发现应该没有影响,只会打印连接失败,对正常业务没有影响
Graylog与文件配置使用方式
见配置《logback-logstash-graylog-tcp-file.xml》
打印ip
支持gl2_remote_ip 打印远程ip

智能推荐
如何设置EXCEL表格单元格的内容可以换行显示_电脑里面的文本控制自动换行在哪里-程序员宅基地
文章浏览阅读1.6k次。点击单元格,选择“设置单元格格式”,然后选择“对齐”,在“文本控制”中勾选“自动换行”就可以了,当然你也可以选择水平对齐和垂直对齐的“居中”哦。..._电脑里面的文本控制自动换行在哪里
虚拟机安装Mac Ox 10.6 之后的驱动安装vmware tool 安装_苹果笔记本装虚拟机后设备驱动也是虚拟吗-程序员宅基地
文章浏览阅读2.3k次。在虚拟机上成功安装Mac OX 10.6 系统之后,还有一些的需要的驱动。在安装vmare tool , 在启动界面,将setting->CD/DVD(IDE)选项中drawin.iso, 将上面的对话框connect 选中,之后会在系统的桌面上看到VMware Tool( Drawin) , 双击进去,直接双击Install VMware tools, 之后就可以的,重新启动,如下图所示_苹果笔记本装虚拟机后设备驱动也是虚拟吗
CentOS7安装docker 启动失败:Job for docker.service failed... 解决办法_job for docker.service failed because a fatal sign-程序员宅基地
文章浏览阅读7.5k次。https://blog.csdn.net/lixiaoyaoboy/article/details/82667510_job for docker.service failed because a fatal signal was delivered to the co
swagger访问路径_swaager访问路径-程序员宅基地
文章浏览阅读2k次。swagger访问路径:localhost:服务端口号/服务名/swagger-ui.html。_swaager访问路径
Jsp 表单如何设计_jsp页面表格设计-程序员宅基地
文章浏览阅读3.8k次。目录杂七杂八语法<%= %>相同点:不同点:语法< form >(生成表单)杂七杂八加!表示全局变量不加表示局部变量<% 这个中间是java代码 %>语法<%= %>表达式语法:<%= %>作用:向浏览器输出数据用jsp的表达式和Java输出的比较相同点:都是向浏览器输出数据不同点:1.语法范畴不同out.println()属于Java语法范畴 <% %><%= %>表达式输_jsp页面表格设计
(node-red)pm2的日志管理及使用pm2-logrotate进行日志分割_pm2 日志-程序员宅基地
文章浏览阅读1.8k次,点赞20次,收藏22次。通过pm2的日志管理插件(pm2-logrotate)实现node-red的日志分割管理_pm2 日志
随便推点
会议论文出版地和出版者_论文中会议的出版者怎么写-程序员宅基地
文章浏览阅读5.7k次,点赞9次,收藏7次。国内的期刊和毕业论文写作格式要求在参考文献中会议论文一律以论文集的形式著录,需注明论文集的出版地、出版者和出版年,但是国外论文的参考文献中一般不会标注论文集的出版地和出版社,他们只标注会议的举行时间和地点。为了满足毕业论文的格式要求,整理了常见计算机领域论文集的出版者及其出版地。出版者:出版地Internet Society: Rosten, VA, USASpringer: Berlin,GermanACM:New York, NYIEEE:Piscataway, NJUSENIX:Berk_论文中会议的出版者怎么写
spark-sql实现Kudu同步数据到mysql_sparksql 数据同步-程序员宅基地
文章浏览阅读1.7k次。Kudu同步数据到mysql实施方案简介目前kudu导出到mysql没有比较好的方案,临时借助spark-sql进行数据导出,处理逻辑是会把老的数据给删除再导入,已经完成了生产环境的上线。需要传入的参数程序参数 参数序号 字段含义 备注 1 同步的source表(含schema),必选 ..._sparksql 数据同步
Linux基础:xargs命令-I选项使用技巧_xargs -i-程序员宅基地
文章浏览阅读1.1w次,点赞3次,收藏17次。这篇文章使用具体示例来介绍一下xargs命令-I参数的常见使用方法。_xargs -i
[译]Kinect for Windows SDK开发入门(五):景深数据处理 下-程序员宅基地
文章浏览阅读60次。1. 简单的景深影像处理 在上篇文章中,我们讨论了如何获取像素点的深度值以及如何根据深度值产生影像。在之前的例子中,我们过滤掉了阈值之外的点。这就是一种简单的图像处理,叫阈值处理。使用的阈值方法虽然有点粗糙,但是有用。更好的方法是利用机器学习来从每一帧影像数据中计算出阈值。Kinect深度值最大为4096mm,0值通常表示深度值不能确定,一般应该将0值过滤掉。微软建议在开发中使用1220...
JavaScript 总结【面试笔记 + 经典面试题 ,超全前端中高级面试复习大纲-程序员宅基地
文章浏览阅读823次,点赞19次,收藏18次。阿里十分注重你对源码的理解,对你所学,所用东西的理解,对项目的理解。CodeChina开源项目:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】CodeChina开源项目:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
python爬虫入门--odoo内应用_odoo爬虫-程序员宅基地
文章浏览阅读506次。此文章向大家介绍一个python入门级爬虫,本人也是初次尝试,如有缺陷,欢迎指正。_odoo爬虫