12 备份和恢复数据库_greenplum fullbaclup-程序员宅基地
技术标签: Greenplum-Admin Greenplum 管理员指南
1 备份和恢复数据库
本主题介绍如何使用Greenplum的备份和恢复功能。
定期执行备份,确保您可以恢复你的数据,或者数据损坏或系统故障发生重建Greenplum的数据库系统。您还可以使用备份将数据迁移从一个Greenplum数据系统到另一个。
1.1 备份和恢复概述
With non-parallel backup and restore operations,the data must be sent over the network from the segments to the master, whichwrites all of the data to its storage. In addition to restricting I/O to onehost, non-parallel backup requires that the master have sufficient local diskstorage to store the entire database.
Greenplum数据引擎支持备份和恢复数据库的并行和非并行的方法。并行操作规模不会受限于系统中的段数,因为段上的主机每个同时写入他们的数据到本地磁盘存储。在非并行备份和恢复操作时,数据必须在从段服务器到master,其中所有的数据都是通过网络进行发送。除了受限于一个主机的I/O之外,非并行备份要求master必须有足够的本地磁盘空间以存储整个数据库。
1.1.1 并行备份和恢复
GDPB的并行dump程序同时备份master实例和所有的活动段实例。
默认情况下,gpcrondump在每个段实例的gp_dump子目录中创建转储文件。对于master, gpcrondump创建若干个转储文件,包含数据库的信息,如DDL语句,系统目录表,和元数据文件。在每个段上,gpcrondump创建一个转储文件,其中包含的命令来重新创建该段的数据。每个文件都包含一个14位的时间戳用以标识这个备份文件的归属。
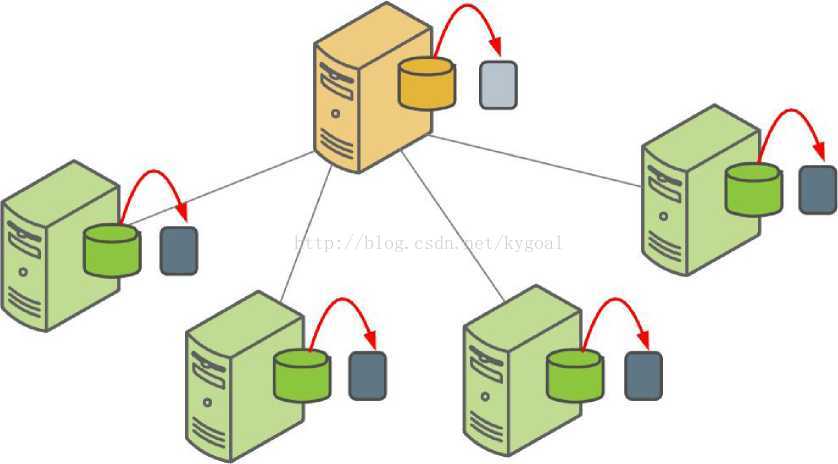
Figure 11: Parallel Backups in Greenplum Database
The gpdbrestore parallel restore utility takes thetimestamp key generated by gpcrondump, validates the backup set, and restoresthe database objects and data into a distributed database. Parallel restoreoperations require a complete backup set created by gpcrondump, a full backup,and any required incremental backups. As the following figure illustrates, allsegments restore data from local backup files simultaneously.
该gpdbrestore并行恢复工具需要通过gpcrondump产生的时间戳键,验证备份集,将数据库对象和数据恢复到一个分布式数据库。并行恢复操作需要由gpcrondump创建一个完整的备份集。一个完整的备份及,以及任何所需的增量备份。如下图所示,所有段同时从本地备份文件恢复数据。
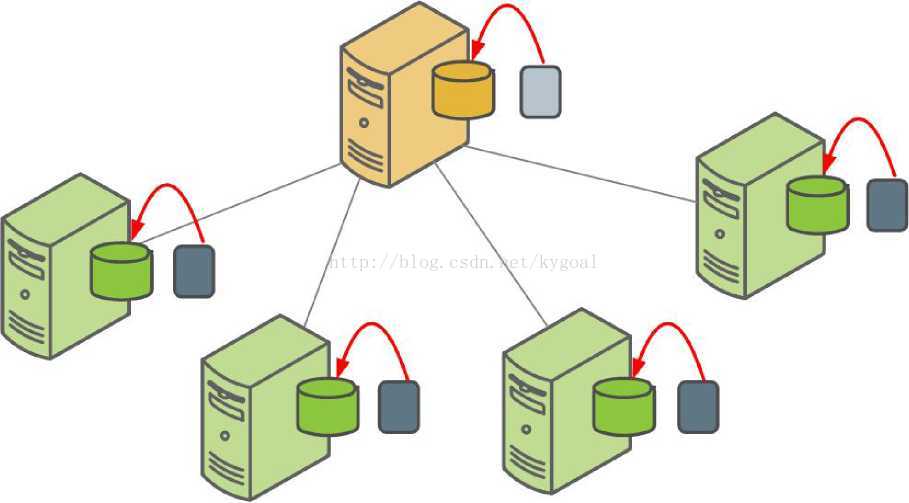
Figure 12: Parallel Restores in Greenplum Database
该gpdbrestore工具提供了灵活性和验证的选项与通过gpcrondump或从Greenplum的集群移动到其他位置的备份文件生成的自动备份文件的使用。请参阅恢复Greenplum的数据库。 gpdbrestore也可用于将文件复制到备用位置。
1.1.2 非并行备份和恢复
PostgreSQL的pg_dump和pg_dumpall非并行备份实用程序可以用来在master上创建一个包含所有活动段中的所有数据的dump文件。
PostgreSQL的非并行实用程序仅限在特殊情形下使用。它们比使用Greenplum备份工具慢很多,因为所有的数据都必须通过master。此外,master主机往往没有足够的空间来存储整个集群的数据。
pg_restore的实用程序需要一个由pg_dump或pg_dumpall创建的压缩转储文件。在开始恢复之前,您应该修改转储文件的CREATE TABLE语句使其包含Greenplum的distributed子句。如果不包括distributed子句,Greenplum数据分配缺省值,这可能不是最优的。有关详细信息,请参阅Greenplum数据参考指南CREATE TABLE。see create table inthe Greenplum Database Reference Guide.
要执行非并行恢复使用并行备份文件,可以备份文件从每段主机到主主机复制,然后通过主加载它们。请参阅恢复到不同的Greenplum的系统配置。See Restoring to a Different Greenplum System Configuration.
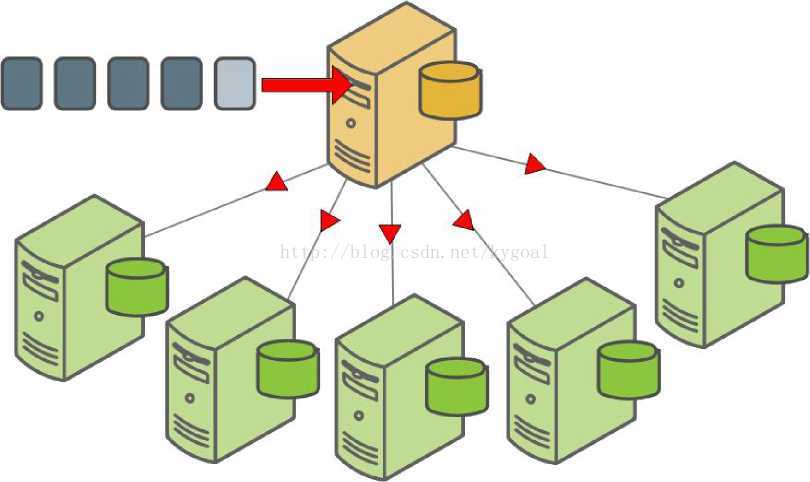
Figure 13: Non-parallel Restore Using ParallelBackup Files
备份数据库的Greenplum数据的另一种非并行的方法是使用复制到SQL命令表的全部或部分从数据库中拷贝到分隔的文本文件在master主机上。
1.1.3 备份和恢复选项
Greenplum的数据库备份和恢复工具支持备份文件不同的位置:
• 使用 gpcrondump utility, 备份文件可以保存在默认位置, 在master和每个setment上的db_dumps 子目录,或者使用gpcrondump -u 选项来保存到另一个目录。
• gpcrondump 和gpdbrestore utilities 都集成了EMC Data Domain Boost 和 Symantec NetBackup 系统的支持.
• 备份文件可以通过命名管道到任何网络访问的位置保存。
• 保存到默认位置备份文件可以被移动到在网络上归档服务器。这使得在最高传输速率执行备份时(段写入备份数据快速本地磁盘阵列),然后将文件移动到远程存储释放磁盘空间。
• 您可以创建转储包含选定的数据库对象:
• 你可以通过命令行或文本文件指定一个或多个schema包含的表。
• 你可以在备份是通过命令行或文本文件将指定的schema排除。
• 你可以在命令行或文本文件中列出需要备份的表。表和schema不能在同一次备份中同时使用。
• 对于数据库对象,gpcrondump 可以备份pg_hba.conf,pg_ident.conf, and postgresql.conf,以及全局数据库对象,如角色和表空间。
你也可以创建增量备份:
• 增量备份只包含追加优化和自最近一次增量备份或完全备份之后发生变化的面向列的表。
• 对于分区追加优化表,只改追加优化/面向列的表分区进行备份。
• 增量备份包括所有堆表。
• 使用gpchrondump --incremental标志指定增量备份。
• 还原增量备份需要一个完全备份和所有后续增量备份,最多要还原的备份。
该gpdbrestore工具提供了很多选项:
•默认情况下,gpdbrestore恢复数据,这是从备份的数据库。
• --redirect标志允许您备份还原到不同的数据库。
•恢复的数据库可以被删除并重新创建,但默认是恢复到现有的数据库。
•选定表可以从备份通过列出在命令行上的表或通过在文本文件中列出它们并指定命令行的文本文件被恢复。
•从备份文件移动到归档服务器可以恢复数据库。备份文件复制回原处主控主机上和每个段主机,然后恢复到数据库。
1.2 使用gpcrondump备份
使用gpcrondump备份数据库,数据以及数据库角色和服务器配置文件等对象。
gpcrondump实用程序将Greenplum数据库的内容转储成SQL脚本文件并存在master和各个段服务器上。这些脚本文件可以被用来恢复数据库。
master备份文件包含SQL命令来创建数据库schema。段数据转储文件包含SQL语句将数据加载到表中。段转储文件都是使用gzip压缩的。另外,服务器配置文件postgresql.conf,pg_ident.conf和pg_hba.conf以及角色和表空间也可以包含在备份中。
该gpcrondump实用程序所需的一个标志,-x,其中指定数据库转储:
gpcrondump -x MYDB
这对指定数据库的默认位置完全备份。
默认情况下,gpcrondump在data_directory创建在主服务器上的数据目录中的备份文件和每段实例/db_dumps目录。您可以使用-u标志指定不同的备份位置。例如,下面的命令将保存备份文件到/备份目录:
gpcrondump MYDB -u /backups
gpcrondump会在指定目录下的子目录db_dumps。如果每个主机的多个主段,所有的主机上的段写的备份文件到同一目录。这不同于默认,其中每个段将备份写入其自己的数据的目录。这可以被用来合并备份以单个目录或装载的存储设备。
在db_dumps目录,备份保存到一个目录中的YYYYMMDD格式,例如
data_directory/db_dumps / 20151012对2015年10月12日,创建目录中的备份文件名包含一个完整的时间戳,格式为YYYYMMDDHHMMSS的备份,例如gp_dump_0_2_20151012195916.gz备份。该gpdbrestore命令默认使用最近的备份,但你可以指定一个较早的备份来恢复。
如果包括了-g选项,gpcrondump保存与备份的配置文件。这些配置文件转储在主或段的数据目录db_dumps/YYYYMMDD/config_files_timestamp.tar。如果指定--ddboost,备份位于由--ddboost-BACKUPDIR设置的目录的存储单元。-G选项备份全局对象,如角色和表空间在指定gp_global_1_1_timestamp的主备份目录中的文件。
如果指定--ddboost,备份位于由--ddboost-BACKUPDIR指定的目录的默认的存储单元。
有许多可用来配置备份的更多gpcrondump选项。请参阅Greenplum的实用参考指南有关所有可用选项的信息。请参阅备份与Data Domain的升压数据库与Data Domain的加速备份的详细信息。
1.3 备份一系列的表
可以创建一个备份,其包括在一个数据库中的模式或表的子集,通过使用
以下gpcrondump选项:
•-t schema.tablename - 指定表的备份中包含。您可以使用-t选项多次。
•--table文件=文件名 - 指定包含表的列表在备份中包含文件。
•-T schema.tablename - 指定表从备份中排除。您可以使用-t选项多次。
•--exclude表文件=文件名 - 指定包含表的列表,以从备份中排除的文件。
•-s SCHEMA_NAME - 包括备份一个指定的架构名称限定的所有表。您可以使用-s选项多次。
•--schema文件=文件名 - 指定包含模式列表的备份中包含的文件。
•-S SCHEMA_NAME - 排除从备份指定的架构名称限定表。您可以使用-S选项多次。
•--exclude-架构文件=文件名 - 指定包含架构名称从备份中排除的文件。
只有一组表或模式的组可以被指定。例如,-s选项不能与-t选项指定。
请参阅增量备份与设置有关使用与增量备份这些gpcrondump选项的其他信息。
1.4 创建增量备份
gpcrondump和gpdbrestore实用程序支持增量备份并附加优化表,包括面向列的表的恢复。使用gpcrondump --incremental选项来创建一个增量备份。
如果下列操作之一是上次完全备份或增量备份后的表执行增量备份只备份追加优化或面向列的表:
• ALTER TABLE
• DELETE
• INSERT
• TRUNCATE
• UPDATE
• DROP and then re-create thetable
对于分区的附加优化表,仅将更改分区备份。
堆表是与每一个完全备份和增量备份备份。
增量备份对于追加优化表分区或面向列的表中少量数据变化的情况下是非常有效的。
每次gpcrondump运行时,它会创建一个包含数据库中每个追加优化表和列存储表以及分区表的行数的状态文件。这个状态文件也保存着元数据的操作例如truncate和alter。当gpcrondump在使用--incremental选项运行时,它的当前状态与存储的状态进行比较,以确定该表或分区是否应当包括在增量备份中。
一个唯一的14位数字时间戳标识包括增量备份集文件。
要创建一个增量备份或从增量备份恢复数据,您需要的完整备份集。一个完整的备份集包括一个完全备份和上次完全备份创建的所有增量备份。当您存档增量备份,上次完全备份和目标增量备份之间的所有增量备份必须归档。您必须存档在主服务器和所有段创建的所有文件。
重要提示:对于增量备份集,完整备份和相关的增量备份,备份集必须在单个设备上。例如,备份集必须全部Data Domain系统上。备份集不能有Data Domain系统和其他本地文件系统或NetBackup系统上的一些备份。
注意:您可以使用Data Domain的服务器作为NFS文件系统(不包括Data Domain的升压)执行增量备份。
改变Greenplum数据段的配置无效增量备份。您更改分段配置后必须创建一个完整备份,然后才能创建增量备份。
1.4.1 增量备份示例
每个备份集都有一个键,它是在创建备份时采取了时间戳。例如,如果你在2012年5月14日,创建一个备份,备份设置文件名包含20120514hhmmss。该HHMMSS表示时间:小时,分钟和秒。
在这个例子中,假设你已经创建的数据库mytest的两个全备份和增量备份。要创建完整备份,您使用以下命令:
gpcrondump -x mytest -u /backupdir
到后来,已经做了一些修改后追加优化的表,创建使用下面的命令的增量备份:
gpcrondump -x mytest -u /backupdir --incremental
当您指定-u选项,在每个Greenplum数据主机上的/ BACKUPDIR目录中创建备份。该文件名称包括以下时间戳密钥。全备份有时间戳关键20120514054532和20121114064330.其他的备份是增量备份。
• 2 0120514054532 (full backup)
• 20120714095512
• 20120914081205
• 20121114064330 (full backup)
• 20130114051246
要创建新的增量备份,你既需要最新的增量备份20130114051246和前面的完全备份20121114064330.此外,还必须指定是备份集的一部分的任何增量备份相同的-u选项。
恢复与增量备份20120914081205的数据库,你需要的增量备份
20120914081205和01207140955122,和完全备份20120514054532。
为了与增量备份20130114051246恢复mytest的数据库,你只需要增量备份和完全备份20121114064330. restore命令将类似于此命令。
gpdbrestore -t 20130114051246 -u /backupdir
1.4.2 增量备份集
要备份一组数据库表与增量备份,确定备份,当您创建完整备份与gpcrondump与--prefix选项设置。例如,创建增量备份在MYSCHEMA模式中的表,首先创建一个完整备份用一个前缀,如MYSCHEMA:
gpcrondump -x mydb -s myschema --prefix myschema
-s选项指定由MYSCHEMA模式来限定表都将包含在备份中。请参阅备份一组表以获得更多选项来指定一组表进行备份的。
一旦你有一个完整的备份,你可以通过指定gpcrondump --incremental和--prefix选项,指定您为完整备份集前缀为同一组表的增量备份。增量备份会自动限制为只能在完全备份的表。例如:
gpcrondump -x mydb --incremental --prefix myschema
下面的命令列出了包含或排除了完全备份的表。
gpcrondump -x mydb --incremental --prefix myschema--list-filter-tables
1.4.3 从增量备份中恢复
当gpdbrestore备份进行恢复时,命令行输出显示是否恢复类型是增量或完全数据库恢复。您不必指定备份的增量。例如,下面的gpdbrestore命令恢复最近的mydb数据库的备份。 gpdbrestore搜索db_dumps目录,找到它找到的备份最新的转储和显示信息。
$ gpdbrestore -s mydb
...
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-
[INFO]:-------------------------------------------
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-[INFO]:-Greenplum databaserestore
parameters
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-
[INFO]:-------------------------------------------
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-[INFO]:-Restore type =
Incremental Restore
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-[INFO]:-Database to berestored =
mydb
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-[INFO]:-Drop and re-createdb =
Off
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-[INFO]:-Restore method =
Search for latest
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-[INFO]:-Restore timestamp=
20151014194445
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-[INFO]:-Restore compresseddump =
On
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-[INFO]:-Restore globalobjects =
Off
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-[INFO]:-Array faulttolerance =
f
20151015:20:10:34:002664 gpdbrestore:mdw:gpadmin-
[INFO]:-------------------------------------------
Continue with Greenplum restore Yy|Nn (default=N):
gpdbrestore确保完整备份和其他所需的增量备份恢复备份前可用。随着--list备份选项,您可以显示执行恢复所需的完整备份和增量备份集。
如果指定了gpdbrestore选项-q,备份的类型信息被写入到日志文件中。随着gpdbrestore选项--noplan,只能还原包含在增量备份中的数据。
1.5 备份过程中的数据库锁
当备份数据库,Greenplum的数据库锁定下表:
1.当备份开始时,一个排它锁exclusive lock加在获取目录表的pg_class,其中包含数据库的相关信息。独占锁只允许并发读取操作。如表,索引和视图关系不能创建或数据库中删除。
在pg_class被锁定后,schema information会收集将要备份的数据库表。
当所有要备份的表都获取到access share lock之后,在pg_classs上的exclusive lock被释放。
2. ACCESS SHARE锁在段实例级别的并行操作获得的。该数据已备份在一个段中的表之后,对在该段的表中的锁被释放。
一个访问共享锁是由只有从表中读取查询,获取了锁。
一个访问共享锁只能用ACCESS EXCLUSIVE锁冲突。下面的SQL语句获得一个ACCESS EXCLUSIVE锁:
• ALTER TABLE
• CLUSTER
• DROP TABLE
• REINDEX
• TRUNCATE
• VACUUM FULL
1.6 使用 Direct I/O
操作系统通常在内存中缓存文件I / O操作,因为内存访问比磁盘访问速度更快。应用程序写入到稍后刷新到存储装置中,通常是在一个Greenplum数据系统中的RAID控制器的一个内存块中。当应用访问的块仍驻留在内存中时,就避免了设备的访问。Direct I / O,您可以让应用程序直接写入到存储设备绕过缓存。这降低CPU消耗,消除了数据复制操作。Direct I / O对那些像备份文件等只需要一次处理的操作时非常有效的。
注意:Direct I / O仅在Red Hat,CentOS的,和SUSE支持。
开启 Direct I/O
通过设置gp_backup_directIO 系统参数为 on来为备份启用Direct I/O:
$ gpconfig -c gp_backup_directIO -v on
如需检查direct I/O是否启用,用如下命令:
$ gpconfig -s gp_backup_directIO
启用Direct I / O时,gp_backup_directIO_read_chunk_mb配置参数设置大小对于I / O块是以MB为单位。默认的块大小是20MB,此参数已经过测试的最佳参数。
降低这个参数会增加了备份时间,导致了增加了变化不大的备份时间。
要查找当前直接I / O块大小,输入以下命令:
$ gpconfig-s gp_backup_directIO_read_chunk_mb
下面的示例更改默认的块大小为10MB。
$ gpconfig-c gp_backup_directIO_read_chunk_mb-v10
1.7 Using Named Pipes
Greenplum的数据库允许使用与gpcrondump和gpdbrestore备份和恢复的Greenplum数据库命名管道。当备份与常规文件的数据库,包含备份信息的文件被放置在了Greenplum数据段目录。如果段上的主机没有可用的备份足够的本地磁盘空间来的文件,你可以使用命名管道备份到外地的存储,例如存储在另一台主机在网络上或备份设备。
备份与命名管道如果指定了--ddboost选项不被支持。
要使用命名管道备份Greenplum数据库:
1. 运行 gpcrondump 命令并带 -Ktimestamp 和 --list-backup-files.
这个命令会创建两个文本文件包含了需要备份的文件,每行一个。文件名包含了你用-k timestamp指定的timestamp,并且包含有后缀后缀_pipes和_regular_files。例如:
gp_dump_20150519160000_pipes
gp_dump_20150519160000_regular_files
在_pipes文件中列出的文件名命名管道被创建。在文件名_regular_files文件不应该命名管道创建。 gpcrondump和gpdbrestore使用备份期间在这些文件中的信息和还原操作。
2. 在Greenplum所有的段上使用创建使用_pipes里的文件名来创建命名文件(named pipes)。
3. 重定向每个命名管道的输出到目标进程或文件对象。
4. 运行gpcrondump使用命名管道备份数据库。
要建立一套完整的Greenplum的数据库备份文件,这些在_regular_files文件的文件也必须也被备份。
如果要在还原备份过程中使用命名管道数据库
To restore a database that used named pipes duringbackup
1. 直接每个备份文件到它的命名管道的输入的内容,例如 cat filename >pipename, 如果备份文件是作为本地文件对象访问。
2. 运行gpdbrestore命令恢复使用命名管道数据库。
1.7.1 示例
这个例子展示了如何通过使用命名管道和netcat的(NC)Linux命令网络备份数据库。该段写入备份文件命名管道的投入。命名管道的输出通过NC命令,这使得对TCP端口可用的文件输送。然后在其他主机上的进程可以连接到指定的端口段上的主机接收备份文件。此示例要求nc package软件包安装在所有Greenplum的主机。
1.输入以下命令gpcrondump生成的备份文件列表,以便在/备份目录testdb数据库
$ gpcrondump -x testdb -K 20150519160000--list-backup-files -u /backups
2. 查看gpcrondump在/ backup目录下创建的文件:
$ ls -lR /backups
/backups:
total 4
drwxrwxr-x 3gpadmin gpadmin 4096 May 19 21:49 db_dumps
/backups/db_dumps:
total 4
drwxrwxr-x 2gpadmin gpadmin 4096 May 19 21:49 20150519
/backups/db_dumps/20150519:
total 8
-rw-rw-r-- 1gpadmin gpadmin 256 May 19 21:49 gp_dump_20150519160000_pipes
-rw-rw-r-- 1gpadmin gpadmin 391 May 19 21:49 gp_dump_20150519160000_regular_files
3. 查看_pipes文件的内容。
$ cat/backups/db_dumps/20150519/gp_dump_20150519160000_pipes
sdw1:/backups/db_dumps/20150519/gp_dump_0_2_20150519160000.gz
sdw2:/backups/db_dumps/20150519/gp_dump_0_3_20150519160000.gz
mdw:/backups/db_dumps/20150519/gp_dump_1_1_20150519160000.gz
mdw:/backups/db_dumps/20150519/gp_dump_1_1_20150519160000_post_data.gz
4. 创建对Greenplum数据段指定的命名管道。同时设立了命名管道读者。
gpssh -h sdw1
[sdw1] mkdir -p/backups/db_dumps/20150519/
[sdw1] mkfifo/backups/db_dumps/20150519/gp_dump_0_2_20150519160000.gz
[sdw1] cat/backups/db_dumps/20150519/gp_dump_0_2_20150519160000.gz | nc -l 21000
[sdw1] exit
完成这些步骤为每个在_pipes文件中列出的命名管道。一定要选择一个可用的TCP端口为每个文件。
5. 在目标主机,接收像下面的命令备份文件:
nc sdw1 21000> gp_dump_0_2_20150519160000.gz
6.运行gpcrondump开始备份:
gpcrondump -xtestdb -K 20150519160000 -u /backups
与命名管道恢复的数据库,通过发送备份文件中的内容的命名管道的输入端反向备份文件的方向和运行gpdbrestore命令:
gpdbrestore -xtestdb -t 20150519160000 -u /backups
gpdbrestore readsfrom the named pipes' outputs.
1.8 使用Data Domain Boost备份数据库
EMC Data Domain Boost (DD Boost)是可以与gpcrondump和gpdbrestore实用工具一起工作用于执行更快的备份到EMC的Data Domain存储设备的EMC软件。 Data Domain在其存储的数据上执行数据去重,所以最初的备份操作后,各个应用程序就只指向那些不变的数据。这减少了在磁盘上的备份的大小。当在gpchrondump中使用DD Boost,Greenplum数据库参与了重复数据删除过程,减少了通过网络发送的数据量。当您从Data Domain系统中使用 Data Domain Boost恢复文件时,有些文件被复制到master本地磁盘并从那里被恢复,剩余的直接恢复。
使用Data Domain Boost来管理文件复制,你可以复制一个Greenplum并存储到Data Domain系统以便进行灾难恢复。gpmfr程序管理Greenplumz在primary和远程的Data Domain系统中的数据备份集。有关gpmfr信息,请参阅Greenplum的数据库实用程序指南。
当两个Data Domain系统之间使用的复制网络时,需要网络配置。
•在Greenplum数据引擎系统需要使用gpcrondump配置Data Domain的登录凭据。证书必须为本地和远程Data Domain系统创建。
•当非管理网络接口用于复制的Data Domain系统,静态路由必须在系统配置为复制数据流量传递到正确的接口。
不要在pg_dump或者是pg_dumpall中使用Data Domain Boost。
请参阅的Data Domain Boost文档的详细信息。
重要提示:对于增量备份集,完整备份和相关的增量备份必须在单个设备上。例如,备份集都必须在文件系统上。备份集不能有本地文件系统和其他Data Domain系统上的一些备份。
注意:您可以使用Data Domain的服务器作为NFS文件系统(不包括Data Domain的升压)执行增量备份。
1.8.1 Data Domain Boost Requirements
使用Data DomainBoost 需要以下。
• Data Domain Boost in included only with PivotalGreenplum Database.
• 在Data Domain中购买并安装 EMCData Domain Boost 和 Replicator licenses.
• 获取对Data Domain Boost 推荐的大小。确保DataDomain 系统能支持你的Greenplum集群中所有的段的足够的写和读。
1.8.2 One-Time Data Domain Boost Credential Setup
There is a one-time process to set up credentialsto use Data Domain Boost. Credential setup connects one Greenplum Databaseinstance to one Data Domain instance. If you are using the gpcrondump -replicateoption or Data Domain Boost managed file replication capabilities for disasterrecovery purposes, you must set up credentials for both the local and remoteData Domain systems.
To set up credentials, run gpcrondump with thefollowing options:
一一ddboost-hostbdboost_ho stnaioe--ddboost-user--ddboost-backupdir backup_directory
To remove credentials, run gpcrondump with the--ddboost-config-remove option.
To manage credentials for the remote Data Domainsystem that is used for backup replication, include the - -ddboost-remoteoption with the other gpcrondump options. 例如, thefollowing options set up credentials for a Data Domain system that is used forbackup replication. The system IP address is 172.28.8.230, the user ID isddboostmyuser, and the location for the backups on the system is gpdb/
gp_production:
--ddboost-host 172.28.8.230 --ddboost-userddboostmyuser --ddboost-backupdir gp_production --ddboost-remote
For details, see gpcrondump in the Greenplum Database Utility Guide.
If you use two or more network connections toconnect to the Data Domain system, use gpcrondump to set up the logincredentials for the Data Domain hostnames associated with the networkinterfaces. To perform this setup for two network connections, run gpcrondumpwith the following options:
--ddboost-host ddboost_hostnamel
--ddboost-host ddboost_hostname2 --ddboost-userddboost_user --ddboost-backupdir backup_directory
1.8.3 Configuring Data Domain Boostfor Greenplum Database
After you set up credentials for Data Domain Boost onthe Greenplum Database, perform the following tasks in Data Domain to allowData Domain Boost to work with Greenplum Database:
• Configuring Distributed Segment Processing in DataDomain
• Configuring Advanced Load Balancing and LinkFailover in Data Domain
• Export the Data Domain Path to the DCA Network
Configuring Distributed Segment Processing in Data Domain
Configure the distributed segment processing optionon the Data Domain system. The configuration applies to all the DCA servers andthe Data Domain Boost plug-in installed on them. This option is enabled bydefault, but verify that it is enabled before using Data Domain Boost backups:
# ddboost option show
To enable or disable distributed segmentprocessing:
# ddboost option set distributed-segment-processing{enabled 丨 disabled}
ConfiguringAdvanced Load Balancing and Link Failover in Data Domain
If you have multiple network connections on anetwork subnet, you can create an interface group to provide load balancing andhigher network throughput on your Data Domain system. When a Data Domain systemon an interface group receives data from the media server clients, the datatransfer is load balanced and distributed as separate jobs on the privatenetwork. You can achieve optimal throughput with multiple 1 GbE connections.
Note: To ensure that interface groups functionproperly, use interface groups only when using multiple network connections onthe same networking subnet.
To create an interface group on the Data Domainsystem, create interfaces with the net command. If interfaces do not alreadyexist, add the interfaces to the group, and register the Data Domain systemwith the backup application.
1. Add the interfaces to the group:
# ddboost ifgroup add interface 192.168.1.1
# ddboost ifgroup add interface 192.168.1.2
# ddboost ifgroup add interface 192.168.1.3
# ddboost ifgroup add interface 192.168.1.4
Note: You can create only one interface group andthis group cannot be named.
2. Select one interface on the Data Domain system toregister with the backup application. Create a failover aggregated interfaceand register that interface with the backup application.
Note: You do not have to register one of theifgroup interfaces with the backup application. You can use an interface thatis not part of the ifgroup to register with the backup application.
3. Enable ddboost on the Data Domain system:
# ddboost ifgroup enable
4. Verify the Data Domain system configuration asfollows:
# ddboost ifgroup show config
Results similar to the following are displayed.
Interface
192.168.1.1
192.168.1.2
192.168.1.3
192.168.1.4
You can add or delete interfaces from the group atany time.
Note: Manage Advanced Load Balancing and LinkFailover (an interface group) using the ddboost ifgroup command or from theEnterprise Manager Data Management > DD Boost view.
1.8.4 Export the Data Domain Path to the DCA Network
The commands and options in this topic apply toDDOS 5.0.x and 5.1.x. See the Data Domain documentation for details.
Use the following Data Domain commands to exportthe /backup/ost directory to the DCA for Data Domain Boost backups.
# nfs add /backup/ost 172.28.8.0/24, 172.28.12.0/24(insecure)
Note: The IP addresses refer to the Greenplumsystem working with the Data Domain Boost system.
Createthe Data Domain Login Credentials for the DCA
Create a username and password for the DCA toaccess the DD Boost Storage Unit (SU) at the time of backup and restore:
# user add user [password password] [priv {admin 丨 security丨 user}]
1.8.5 Backup Options for Data DomainBoost
Specify the gpcrondump options to match the setup.
Data Domain Boost backs up files to the Data Domainsystem. Status and report files remain on the local disk.
To configure Data Domain Boost to remove old backupdirectories before starting a backup operation, specify a gpcrondump backupexpiration option:
• The -c option clears all backup directories.
• The -o option clears the oldestbackup directory.
To remove the oldest dump directory, specifygpcrondump --ddboost with the -o option. 例如, ifyour retention period is 30 days, use gpcrondump --ddboost with the -o option on day 31.
Use gpcrondump --ddboost with the -c option toclear out all the old dump directories in db_dumps. The - c option deletes alldump directories that are at least one day old.
1.8.6 Using CRON to Schedule a DataDomain Boost Backup
1. Ensure the One-Time Data DomainBoo^t Credential S^tup is complete.
2. Add the option --ddboost to the gpcrondump option:
gpcrondump -x mydatabase -z -v --ddboost
Important: Do not use compression with Data DomainBoost backups. The -z option turns backup compression off.
Some of the options available in gpcrondump havedifferent implications when using Data Domain Boost. For details, seegpcrondump in the GreenplumDatabase Utility Reference.
1.8.7 Restoring From a Data DomainSystem with Data Domain Boost
1. Ensure the One-Time Data DomainBoo^t Credential S^tup is complete.
2. Add the option --ddboost to the gpdbrestorecommand:
$ gpdbrestore -t Vackup_timestamp -v -ddboost
Note: Some of the gpdbrestore options availablehave different implications when using Data Domain. For details, seegpdbrestore in the Greenplum Database Utility Reference.
1.9 使用Symantec NetBackup备份数据库
有关红帽企业Linux Greenplum数据引擎,您可以配置Greenplum数据与赛门铁克的NetBackup执行备份和还原操作。您配置Greenplum数据引擎和NetBackup,然后运行Greenplum数据gpcrondump或gpdbrestore命令。以下主题介绍了如何设置NetBackup和备份或还原的Greenplum数据库。
•关于NetBackup软件
•系统要求
•限制
•为NetBackup配置Greenplum数据主机
•配置NetBackup for Greenplum数据引擎
•利用NetBackup执行备份或恢复
•实例的NetBackup备份和恢复命令
1.9.1 关于NetBackup软件
NetBackup中将包括以下服务器和客户端软件:
•NetBackup主服务器管理的NetBackup备份,归档和恢复。主服务器负责媒体和设备为NetBackup选择。
•NetBackup介质服务器是允许NetBackup使用连接到它们的存储设备,提供额外的存储NetBackup设备主机。
•驻留在包含数据的Greenplum数据主机NetBackup客户端软件来进行备份。
查看赛门铁克的NetBackup入门指南关于NetBackup信息。Symantec NetBackup Getting started Guide
1.9.2 系统要求
注:Greenplum数据使用NetBackup API(XBSA)与NetBackup进行通信。
Greenplum的数据库使用的SDK版本的Symantec XBSA 1.1.0。
•NetBackup客户端软件安装和Greenplum的数据库主主机和所有段上的主机上配置。
NetBackup客户端软件必须能够与NetBackup服务器软件进行通信。
•NetBackup主服务器版本7.5和NetBackup介质服务器7.5版
•NetBackup客户端7.1或更高版本。
• NetBackup将不兼容DDBoost。 NetBackup和DDBoost不能在单个使用备份或恢复操作。
• 对于增量备份集,完整备份和相关的增量备份,备份集必须在单个设备上。例如,备份集都必须是NetBackup系统上。备份集不能有NetBackup系统和其他本地文件系统或Data Domain系统上的一些备份。
1.9.3 为NetBackup配置Greenplum数据主机
您安装和Greenplum的数据库主主机和所有段上的主机上配置NetBackup客户端软件。
1.安装在Greenplum数据主机上的NetBackup客户端软件。请参阅在UNIX系统上安装NetBackup客户端的信息,NetBackup安装文档。
2.对Greenplum数据引擎主段上的主机NetBackup配置文件的/usr/openv/netbackup/bp.conf设置参数。设置每个Greenplum的数据库主机上的下列参数。
| Parameter |
Description |
| SERVER |
Host name of the NetBackup Master Server |
| MEDIA SERVER |
Host name of the NetBackup Media Server |
| CLIENT NAME |
Host name of the Greenplum Database Host |
请参见Symantec NetBackup管理指南有关bp.conf文件的信息。Seethe Symantec NetBackup Administrator's Guide for information about the bp.conf file.
3.设置Greenplum数据LD_LIBRARY_PATH环境变量主机使用NetBackup客户端
7.1或7.5。 Greenplum的数据库附带的NetBackupSDK与NetBackup 7.1兼容的库文件
和7.5客户端。要使用NetBackup 7.1或7.5客户端附带的Greenplum数据引擎,添加
下面一行到文件$ GPHOME/greenplum_path.sh:
LD_LIBRARY_PATH=$GPHOME/lib/nbuNN/lib:$LD_LIBRARY_PATH
根据与您需要使用NetBackup客户端上75或71更换NN。
该LD_LIBRARY_PATH行应这一行$GPHOME/greenplum_path.sh前加入:
exportLD_LIBRARY_PATH
4.执行此命令删除当前LD_LIBRARY_PATH值:
unsetLD_LIBRARY_PATH
5.执行这个命令来更新数据库Greenplum的环境变量:
source$GPHOME/greenplum_path.sh
请参见Symantec NetBackup管理指南有关配置的NetBackup服务器的信息。
1.确保Greenplum数据引擎的主机被列为NetBackup服务器NetBackup客户端。
在NetBackup管理控制台中,为NetBackup客户端的信息,媒体服务器,以及主服务器是在主机属性节点内的NetBackup管理节点。
2.配置NetBackup存储单元。存储单元必须配置为指向一个可写的磁盘位置。
在NetBackup管理控制台中,NetBackup存储单元的信息是NetBackup
存储节点内部的管理节点。
3.配置策略中的NetBackup备份策略和日程表。
在NetBackup管理控制台中,在主服务器节点下的策略节点是你创建策略和策略的日程表。
• In the Policy Attributes tab, these values arerequired for Greenplum Database:
The value in the Policy type field must beDataStore
The value in the Policy storage field is thestorage unit created in the previous step.
The value in Limit jobs per policy field must be atleast 3.
• In the Policy Schedules tab, create a NetBackupschedule for the policy.
1.9.4 使用NetBackup执行备份或恢复
在Greenplum数据gpcrondump和gpdbrestore实用程序支持选项来备份或恢复数据发送到NetBackup存储单元。当进行备份,Greenplum数据传输数据文件直接到NetBackup存储单元。没有备份的数据文件在Greenplum数据主机上创建。
备份文件的元数据都存储在主机和备份到NetBackup存储单元。
执行还原时,这些文件从NetBackup服务器检索,然后还原。
以下是NetBackup的gpcrondump实用程序选项:
--netbackup-service-host netbackup_master_server
--netbackup-policy policy_name
--netbackup-schedule schedule_name
--netbackup-block-size size (optional)
--netbackup-keyword keyword (optional)
The gpdbrestore utility provides the followingoptions for NetBackup:
--netbackup-service-host netbackup_master_server
--netbackup-block-size size (optional)
Note: When performing a restore operation fromNetBackup, you must specify the backup timestamp with the gpdbrestore utility-t option.
The policy name and schedule name are defined onthe NetBackup master server. SeeConfiguringNetBackupfor Greenplum Database for information about policy name and schedulename. See the Greenplum DatabaseUtility Guide for information about the Greenplum Databaseutilities.
Note: You must run the gpcrondump or gpdbrestorecommand during a time window defined for the NetBackup schedule.
During a back up or restore operation, a separateNetBackup job is created for the following types of Greenplum Database data:
• Segment data for each segment instance
• C database data
• Metadata
• Post data for the master
• State files Global objects (gpcrondump -g option)
• Configuration files for master and segments(gpcrondump -g option)
• Report files (gpcrondump -h option)
In the NetBackup Administration Console, theActivity Monitor lists NetBackup jobs. For each job, the job detail displaysGreenplum Database backup information.
1.9.5 Example NetBackup Back Up and Restore Commands
This gpcrondump command backs up the database customer andspecifies a NetBackup policy and schedule that are defined on the NetBackupmaster server nbu_serveri. A block size of 1024 bytes is used to transfer datato the NetBackup server.
gpcrondump -x customer--netbackup-service-host=nbu_server1
--netbackup-policy=gpdb_cust--netbackup-schedule=gpdb_backup --netbackup-block-size=1024
This gpdbrestore command restores GreenplumDatabase data from the data managed by NetBackup master server nbu_server1. The option -t 20130530090000specifies the timestamp generated by gpcrondump when the backup was created.The -e option specifies that the target database is dropped before it isrestored.
gpdbrestore -t 20130530090000 -e--netbackup-service-host=nbu_server1
1.10 恢复Greenplum数据库
如何还原从并行备份文件的数据库取决于你如何回答以下问题。
1. 你备份的文件在哪? 如果你使用了gpcrondump在段服务器上创建了备份文件,那你可以用gpdbrestore来恢复数据库。如果你将利用gpcrondump将备份文件从Greenplum数据库集群移到了归档服务器,则使用gpdbrestore来恢复。
2. 你是要重新创建Greenplum数据库系统,还是仅仅是恢复数据。如果Greenplum 系统在运行并且你仅需恢复数据,则使用gpdbrestore 。如果你丢失了整个集群并且需要从备份中重建数据库系统,则使用gpinitsystem。
3. 是否将备份集恢复到具有相同数量的段的集群?如果你要还原到具有相同数量的段实例并且每个主机上都有相同的段实例,则使用gpdbrestore。如果你要将其迁移到一个不同配置的集群,则你只能使用非并行恢复。详情参阅See Restoring to a Different Greenplum SystemConfiguration.
1.11 Restoring a Database Usinggpdbrestore
gpdbrestore实用程序恢复由pcrondump创建的备份文件的数据库。
该gpdbrestore需要以下选项来确定备份集来还原一个:
• -t timestamp -指定的时间戳恢复备份。
• -b YYYYYMMDr -还原段数据目录中的子目录db_dumps指定的日期的转储文件中。
• -s database_name - 恢复最新转储文件在他的段数据目录中找到指定的数据库。
• -r hostname:path - 恢复位于远程主机的指定目录中的备份集。
要还原增量备份,你需要一套完整的备份文件,一个完全备份和任何所需的增量备份。您可以使用--list的备份选项列出由时间戳所指定的增量备份所需的全面,cremental备份集。 例如:
$ gpdbrestore -t 20151013195916 --list-backup
您可以使用--redirect数据库选项备份还原到不同的数据库。如果不存在,该数据库中创建。下面的示例恢复最新的mydb数据库到新的数据库名为mydb_snapshot的备份:
$ gpdbrestore -s grants --redirect grants_snapshot
您还可以还原备份到一个不同的Greenplum的数据库系统。请参阅恢复到不同的Greenplum的系统配置有关此选项的信息。 See Restoring to a Different Greenplum SystemConfiguration for information about this option.
1.11.1 使用 gpdbrestore从归档服务器恢复
使用gpdbrestore可以使用-R选项从保存在Greenplum集群之外的归档主机的备份进行恢复。尽管Greenplum的数据库软件不必须在远程主机上安装,远程主机必须有密码的ssh访问所有主机的Greenplum的集群中配置一个gpadmin帐户。
这是必需的,因为每个段的主机将使用SCP从存档主机复制其段的备份文件。看到Greenplum的数据库实用程序指南(Greenplum Database Utility Guide)中gpssh-exkeys添加远程主机到群集的帮助。
此过程假定备份集移出Greenplum的阵列到网络中的另一台主机。
1. 确保归档主机是从Greenplum的master主机访问::
$ping archive_host
2. 确保您可以ssh与gpadmin账号,没有密码的远程主机。
$ sshgpadmin@archive_host
3. 确保您可以ping从归档主机主控主机:
$ pingmdw
4. 确保恢复的目标数据库中存在。例如:
$createdb database name
5. 从master运行gpdbrestore实用程序。 -r选项指定主机名和路径,一个完整的备份集:
$gpdbrestore -R archive_host:/gpdb/backups/archive/20120714 -edbname
如果数据库已创建,省略-e DBNAME选项。
1.12 Restoring to a Different Greenplum System Configuration
要使用gpdbrestore执行并行还原操作时,您要还原到系统必须具有相同的配置作为备份的系统。要还原数据库对象和数据到不同的系统配置,例如,将数据导入到一个更多段实例的系统,需要将并行备份文件加载到master节点并执行恢复。要执行非并行恢复,您必须:
• 由gpcrondump操作创建一个完整的备份集。主的备份文件包含DDL来重新创建数据库对象。该段的备份文件包含的数据。
• 一个运行着的Greenplum数据库系统。
• 需要还原的数据库在系统中。
段转储文件包含一个COPY命令的每个表,然后在分隔文本格式的数据。收集所有的转储文件的所有段的实例并运行它们通过主恢复你的数据和整个新的系统配置重新分配。
1. 首先确保具备了全部的备份文件。包括Master的备份文件(gp_dump_1_1_timestamp, gp_dump_1_1_timestamp_post_data) and one for eachsegment instance gp_dump_0_2_timestamp,gp_dump_0_3_timestamp,gp_dump_0_4_timestamp,等等).。每个转储文件必须具有相同的时间戳关键。gpcrondump每段实例的数据目录下创建转储文件。你必须收集所有的转储文件,并将其移动到master的一个位置。你可以复制一个段的dump数据到master,加载后,删除,再复制其他段的数据。
2. 确保在系统中,需要恢复的数据库已经存在. 例如:
$createdb database_name
3. 装载Master备份文件以恢复数据库对象。例如:
$ psqldatabase_name -f /gpdb/backups/gp_dump_1_1_20120714
4. 加载每段转储文件来恢复数据。例如:
$ psqldatabase_name -f /gpdb/backups/gp_dump_0_2_20120714
$ psqldatabase_name -f /gpdb/backups/gp_dump_0_3_20120714
$ psqldatabase_name -f /gpdb/backups/gp_dump_0_4_20120714
$ psqldatabase_name -f /gpdb/backups/gp_dump_0_5_20120714
...
5. 加载后的数据文件来恢复数据库对象,如索引,触发器,主键约束,等等.
$ psql database_name -f/gpdb/backups/gp_dump_0_5_20120714_post_data
6. 更新基于从原始数据库中的值的数据库序列。您可以使用系统工具,并用gunzipegrep的从原来的Greenplum数据主转储文件gp_dump_1_1_timestamp.gz序列值信息提取到一个文本文件中。此命令提取的信息到文件schema_path_and_seq_next_val。
gunzip-c path_to_master_dump_directory/gp_dump_1_1_timestamp.gz | egrep "SETsearch_path|SELECT pg_catalog.setval"
>schema_path_and_seq_next_val
这个例子命令假定原来的Greenplum数据主转储文件是 /data/gpdb/master/gpseg-1/db_dumps/20150112.
gunzip-c /data/gpdb/master/gpseg-1/db_dumps/20150112/
gp_dump_1_1_20150112140316.gz
|egrep "SET search_path|SELECT pg_catalog.setval" >
schema_path_and_seq_next_val
提取信息后,使用Greenplum数据PSQL工具来更新数据库中的序列。这个例子命令更新数据库test_restore的序列信息:
psqltest_restore -f schema_path_and_seq_next_val
智能推荐
KG摘要--大白话_event detection (ed) 提出的概念-程序员宅基地
文章浏览阅读169次。什么是事件抽取?怎么做?EE主要有两种方法:joint approach和 pipelined approach;前者同时predicts event triggers and arguments;后者首先performs trigger prediction,然后identifies arguments in separate stages.联合抽取的好处是,可以阻止error propagation,以及从全局对 inter-dependencies 建模Event Detection(ED)._event detection (ed) 提出的概念
HTML5生日快乐祝福网页制作【蛋糕烟花+蓝色梦幻海洋3D相册】HTML+CSS+JavaScript-程序员宅基地
文章浏览阅读462次,点赞8次,收藏9次。1 网页简介:基于HTML+CSS+JavaScript 制作七夕情人节表白网页、生日祝福、七夕告白、 求婚、浪漫爱情3D相册、炫酷代码,快来制作一款高端的表白网页送(他/她)浪漫的告白,制作修改简单,可自行更换背景音乐,文字和图片即可使用等任意html编辑软件进行运行及修改编辑等操作)。
IDEA搭建SpringMvc详解_springmvc jetbrain-程序员宅基地
文章浏览阅读94次。工具(IDEA)下载地址:https://www.jetbrains.com/idea/download/#section=windows本文截取文章来源:https://www.cnblogs.com/wormday/p/8435617.html考虑对方可能删了博客看不到的情况,这里自己截图保存一份,对方写的很仔细.初学的朋友可以看看,老鸟忽略...._springmvc jetbrain
基于模型的聚类和R语言中的高斯混合模型_bic高斯混合模型计算p值怎么算-程序员宅基地
文章浏览阅读828次。方法是用于估计有限混合概率密度的参数的最广泛使用的方法。基于模型的聚类框架提供了处理此方法中的几个问题的主要方法,例如密度(或聚类)的数量,参数的初始值(EM算法需要初始参数值才能开始),以及分量密度的分布(例如,高斯分布)。基于概率模型的聚类技术已被广泛使用,并且已经在许多应用中显示出有希望的结果,从图像分割,手写识别,文档聚类,主题建模到信息检索。在使用不同的聚类方法将数据拟合到聚类中之后,您可能希望测量聚类的准确性。四种最常见的聚类方法模型是层次聚类,k均值聚类,基于模型的聚类和基于密度的聚类 ._bic高斯混合模型计算p值怎么算
操作系统实验:线程的创建与撤销_线程的创建与撤销实验报告-程序员宅基地
文章浏览阅读1.1w次,点赞16次,收藏103次。一、实验目的(1)熟悉windows系统提供的线程创建与撤销系统调用。(2)掌握windows系统环境下线程的创建与撤销方法。(3)掌握CreateThread()函数和ExitThread()函数。..._线程的创建与撤销实验报告
vue渲染动态渲染图片_动态/动态渲染视频和音频-程序员宅基地
文章浏览阅读1.9k次。vue渲染动态渲染图片 Vue-Viaudio (vue-viaudio)Dynamically/Reactively render videos and audios. 动态/动态渲染视频和音频。 View Documentation查看文档 Reactive exampleReact性示例 Dynamically Render Video source动态渲染视频源 项目设置 (..._vue render 一个视频
随便推点
NavigationView的依赖_navigationview依赖-程序员宅基地
文章浏览阅读1.4k次。NavigationView的依赖将如下代码添加到app/build.gradle中的dependencise闭包中即可 def nav_version = "2.1.0" implementation "androidx.navigation:navigation-fragment:$nav_version" implementation "androidx.navigati..._navigationview依赖
63.html+css+js网页设计实例/“商城”主题水果商城介绍/web前端期末大作业/-程序员宅基地
文章浏览阅读745次,点赞13次,收藏20次。本实例以水果商城为主题设计,响应式网页,应用html+css+js,包括DIV、图片轮翻效果、留言表单、购物车等,供大家参考。html+css+js网页设计、大学生网页课程设计、期末大作业、毕业设计、网页模板,DW网页成品源代码等,2000+套Web案例源码,优质文章,关注作者获取更多源码,点赞收藏博文,您的支持是我创作的动力!3Q!
LRU淘汰策略执行过程-程序员宅基地
文章浏览阅读559次。Redis无论是惰性删除还是定期删除,都可能存在删除不尽的情况,无法删除完全,比如每次删除完过期的 key 还是超过 25%,且这些 key 再也不会被客户端访问。这样的话,定期删除和堕性删除可能都彻底的清理掉。如果这种情况长时间持续下去,可能会导致内存耗尽,所以Redis必须有一个完善的内存淘汰机制来保障。这就是我们这一篇的重点,Redis内存自动淘汰机制。
2023企业Hyper-V备份解决方案!_truenas scale 备份hper-v-程序员宅基地
文章浏览阅读171次。对于希望确保Hyper-V虚拟机数据安全并且保障企业业务连续不中断的企业或组织来说,找到一个专业好用的Hyper-V备份解决方案是很重要的。 _truenas scale 备份hper-v
FDS8960C-NL-VB一种N+P沟道SOP8封装MOS管-程序员宅基地
文章浏览阅读332次,点赞9次,收藏8次。1. **电源管理模块:** FDS8960C-NL-VB可用于电源管理模块,作为电源开关或电源调整器件,提供中功率的电源管理。- **电流控制:** FDS8960C-NL-VB可作为电流控制的关键元件,通过调整其导通电阻来实现对电路中电流的双向控制。- **功率调整:** 适用于中功率的功率电子模块,可用于调整电路中的功率,满足不同应用场景的需求。2. **电机控制模块:** 适用于中功率的电机控制模块,可在电机驱动中提供可靠的电流支持。- **型号:** FDS8960C-NL-VB。
2023深圳杯(东三省)数学建模D题思路 - 基于机理的致伤工具推断_锐器对人体伤口模型-程序员宅基地
文章浏览阅读2k次。致伤工具的推断一直是法医工作中的热点和难点。由于作用位置、作用方式的不同,相同的致伤工具在人体组织上会形成不同的损伤形态**,**不同的致伤工具也可能形成相同的损伤形态。致伤工具品种繁多、形态各异,但大致可分为两类:锐器(如刀、刺等)和钝器(如锤子、铁棍、石头等)。_锐器对人体伤口模型