计算机毕设 大数据 电影数据分析与可视化系统 - python Django 大数据 可视化_基于大数据的电影数据分析与可视化系统-程序员宅基地
0 前言
这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
**基于大数据的电影数据分析与可视化系统 **
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:4分
- 创新点:4分
选题指导, 项目分享:
https://gitee.com/yaa-dc/warehouse-1/blob/master/python/README.md
1 课题背景
研究中国用户电影数据,有助于窥探中国电影市场发展背后的规律,理解其来龙去脉,获知未来走向。如今互联网上中国用户的电影数据集缺失,缺少如MovieLens、Kaggle等独立机构完成长期收集电影数据工作,研究人员只能自行收集或下载来自国外的公共电影数据集,不具有本地属性。
本项目爬取豆瓣网相关电影信息,建立数据库。并根据此数据库进行了可视化分析,从中提取出大量数据背后信息,多维度分析了电影在公映时间、观众分布、类别占比、各国市场情况的关系,从评论词云、文本情感角度挖掘单部电影呈现的规律。
2 效果实现
评论情感得分随时间变化情况如下
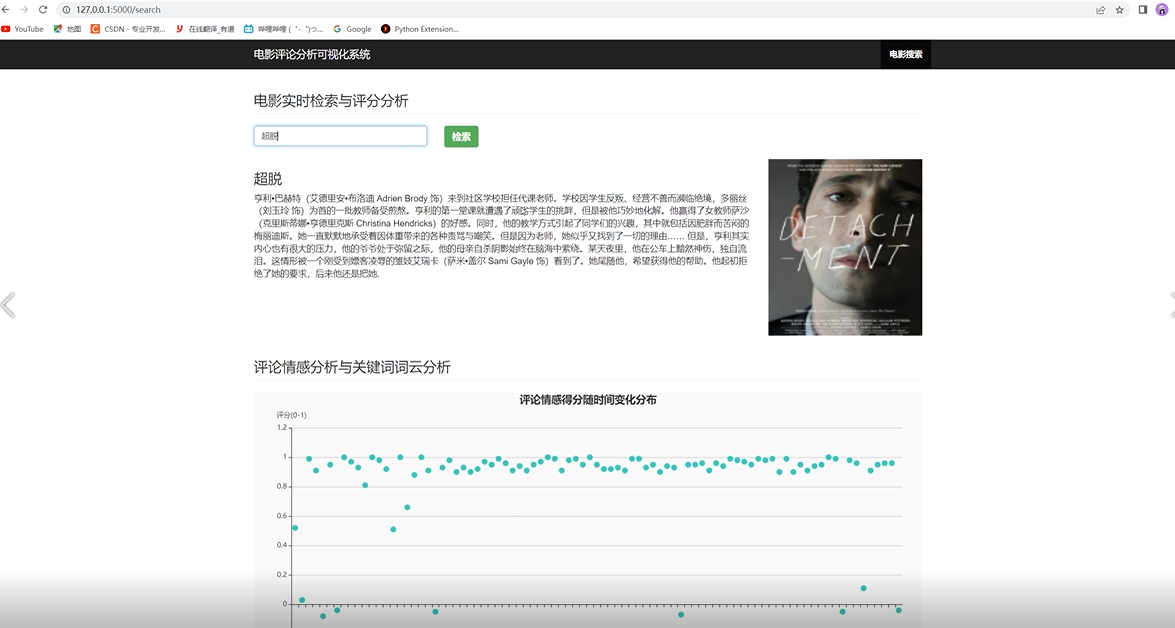

热门评论列表情况如下
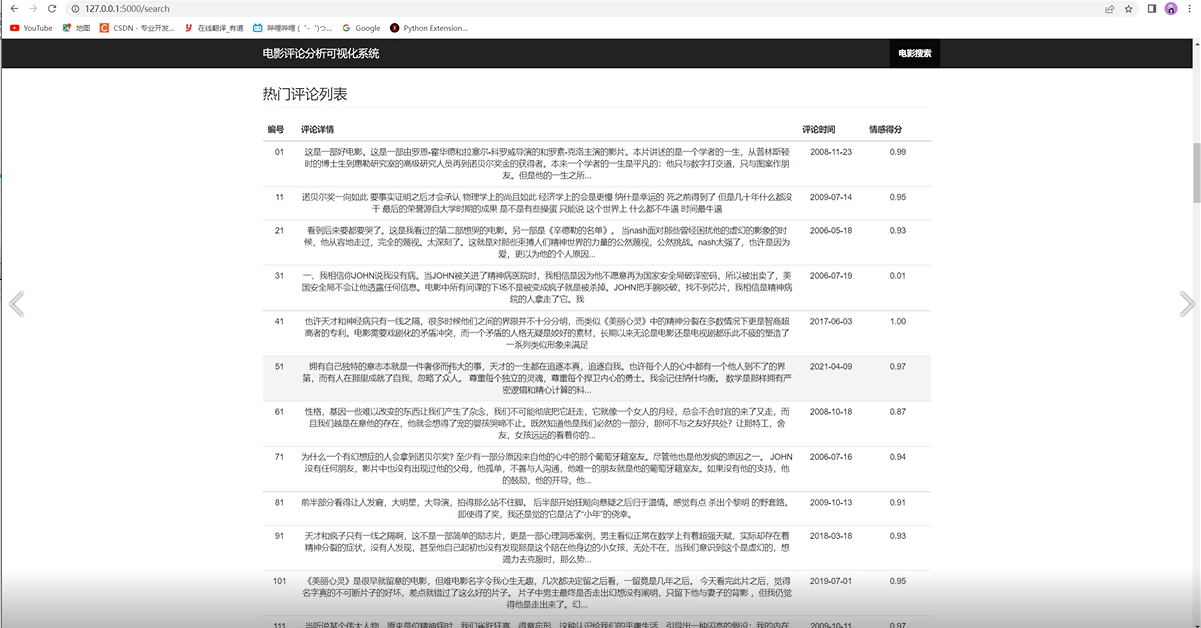
3 爬虫及实现
简介
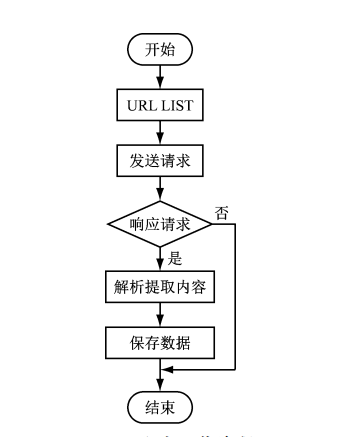
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫对某一站点访问,如果可以访问就下载其中的网页内容,并且通过爬虫解析模块解析得到的网页链接,把这些链接作为之后的抓取目标,并且在整个过程中完全不依赖用户,自动运行。若不能访问则根据爬虫预先设定的策略进行下一个 URL的访问。在整个过程中爬虫会自动进行异步处理数据请求,返回网页的抓取数据。在整个的爬虫运行之前,用户都可以自定义的添加代理,伪 装 请求头以便更好地获取网页数据。
爬虫流程图如下:
部分代码实现
import re
import requests
import json
import time
from openpyxl import load_workbook, Workbook
from requests import RequestException
def get_detail_page(html):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
cookies = {
}
response = requests.get(url=html, headers=headers, cookies=cookies)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
return None
except RequestException:
print('获取详情页错误')
time.sleep(3)
return get_detail_page(html)
def parse_index_page(html):
html = get_detail_page(html)
html = html[12:-1]
data = json.loads(html)
id_list = []
if data:
for item in data:
id_list.append(item['url'])
return id_list
def parse_detail_page(data):
html = get_detail_page(data)
info = []
# 获取电影名称
name_pattern = re.compile('<span property="v:itemreviewed">(.*?)</span>')
name = re.findall(name_pattern, html)
info.append(name[0])
# 获取评分
score_pattern = re.compile('rating_num" property="v:average">(.*?)</strong>')
score = re.findall(score_pattern, html)
info.append(score[0])
# 获取导演
director_pattern = re.compile('rel="v:directedBy">(.*?)</a>')
director = re.findall(director_pattern, html)
print(director)
info.append(str(director[0]))
# 获取演员
actor_pattern = re.compile('rel="v:starring">(.*?)</a>')
actor = re.findall(actor_pattern, html)
info.append(str(actor[0]))
# 获取年份
year_pattern = re.compile('<span class="year">\((.*?)\)</span>')
year = re.findall(year_pattern, html)
info.append(year[0])
# 获取类型
type_pattern = re.compile('property="v:genre">(.*?)</span>')
type = re.findall(type_pattern, html)
info.append(type[0].split(' /')[0])
# 获取时长
try:
time_pattern = re.compile('property="v:runtime" content="(.*?)"')
time = re.findall(time_pattern, html)
info.append(time[0])
except:
info.append('1')
# 获取语言
language_pattern = re.compile('pl">语言:</span>(.*?)<br/>')
language = re.findall(language_pattern, html)
info.append(language[0].split(' /')[0])
# 获取评价人数
comment_pattern = re.compile('property="v:votes">(.*?)</span>')
comment = re.findall(comment_pattern, html)
info.append(comment[0])
# 获取地区
area_pattern = re.compile(' class="pl">制片国家/地区:</span>(.*?)<br/>')
area = re.findall(area_pattern, html)
info.append(area[0].split(' /')[0])
return info
html = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E5%86%B7%E9%97%A8%E4%BD%B3%E7%89%87&sort=rank&page_limit=20&page_start='
wc = Workbook()
sheet = wc.active
sheet.title = "New"
ws = wc['New']
sheet['A1'] = 'name'
sheet['B1'] = 'score'
sheet['C1'] = 'director'
sheet['D1'] = 'actor'
sheet['E1'] = 'year'
sheet['F1'] = 'type'
sheet['G1'] = 'time'
sheet['H1'] = 'language'
sheet['I1'] = 'comment'
sheet['J1'] = 'area'
ws = wc[wc.sheetnames[0]]
wc.save('豆瓣电影.xlsx')
ti = 1
for i in range(20, 50):
print(i)
html1 = html+str(i*20)
u = parse_index_page(html1)
print(u)
for t in u:
time.sleep(0.5)
b = parse_detail_page(t)
print(b)
ws.append(b)
wc.save('豆瓣电影.xlsx')
ti += 1
4 Flask框架
简介
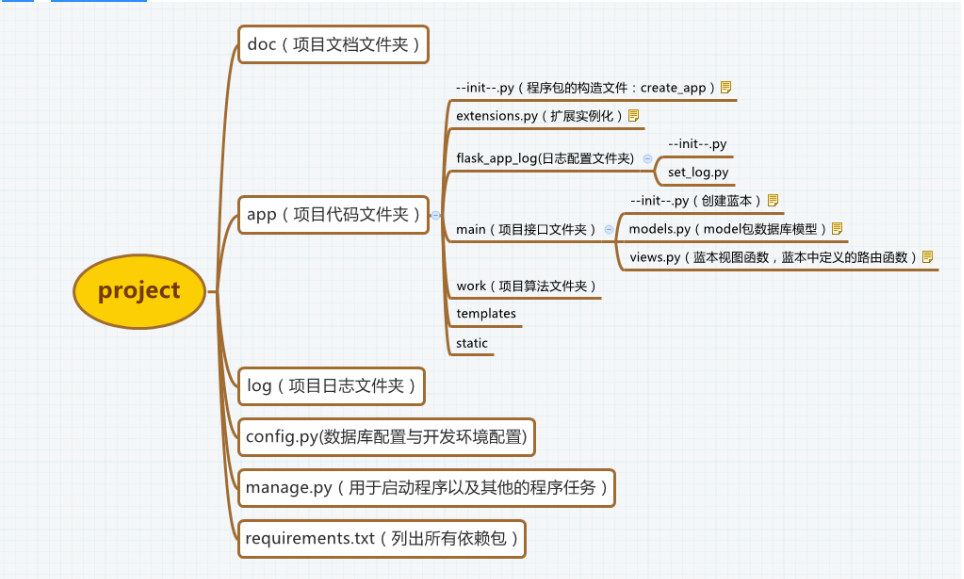
Flask是一个基于Werkzeug和Jinja2的轻量级Web应用程序框架。与其他同类型框架相比,Flask的灵活性、轻便性和安全性更高,而且容易上手,它可以与MVC模式很好地结合进行开发。Flask也有强大的定制性,开发者可以依据实际需要增加相应的功能,在实现丰富的功能和扩展的同时能够保证核心功能的简单。Flask丰富的插件库能够让用户实现网站定制的个性化,从而开发出功能强大的网站。
Flask项目结构图
部分相关代码
from flask import Flask, render_template, jsonify
import requests
from bs4 import BeautifulSoup
from snownlp import SnowNLP
import jieba
import numpy as np
app = Flask(__name__)
app.config.from_object('config')
# 中文停用词
STOPWORDS = set(map(lambda x: x.strip(), open(r'./stopwords.txt', encoding='utf8').readlines()))
headers = {
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
'accept-language': "en-US,en;q=0.9,zh-CN;q=0.8,zh-TW;q=0.7,zh;q=0.6",
'cookie': 'll="108296"; bid=ieDyF9S_Pvo; __utma=30149280.1219785301.1576592769.1576592769.1576592769.1; __utmc=30149280; __utmz=30149280.1576592769.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); _vwo_uuid_v2=DF618B52A6E9245858190AA370A98D7E4|0b4d39fcf413bf2c3e364ddad81e6a76; ct=y; dbcl2="40219042:K/CjqllYI3Y"; ck=FsDX; push_noty_num=0; push_doumail_num=0; douban-fav-remind=1; ap_v=0,6.0',
'host': "search.douban.com",
'referer': "https://movie.douban.com/",
'sec-fetch-mode': "navigate",
'sec-fetch-site': "same-site",
'sec-fetch-user': "?1",
'upgrade-insecure-requests': "1",
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36 Edg/79.0.309.56"
}
login_name = None
# --------------------- html render ---------------------
@app.route('/')
def index():
return render_template('index.html')
@app.route('/search')
def search():
return render_template('search.html')
@app.route('/search/<movie_name>')
def search2(movie_name):
return render_template('search.html')
@app.route('/hot_movie')
def hot_movie():
return render_template('hot_movie.html')
@app.route('/movie_category')
def movie_category():
return render_template('movie_category.html')
# ------------------ ajax restful api -------------------
@app.route('/check_login')
def check_login():
"""判断用户是否登录"""
return jsonify({
'username': login_name, 'login': login_name is not None})
@app.route('/register/<name>/<pasw>')
def register(name, pasw):
conn = sqlite3.connect('user_info.db')
cursor = conn.cursor()
check_sql = "SELECT * FROM sqlite_master where type='table' and name='user'"
cursor.execute(check_sql)
results = cursor.fetchall()
# 数据库表不存在
if len(results) == 0:
# 创建数据库表
sql = """
CREATE TABLE user(
name CHAR(256),
pasw CHAR(256)
);
"""
cursor.execute(sql)
conn.commit()
print('创建数据库表成功!')
sql = "INSERT INTO user (name, pasw) VALUES (?,?);"
cursor.executemany(sql, [(name, pasw)])
conn.commit()
return jsonify({
'info': '用户注册成功!', 'status': 'ok'})
@app.route('/login/<name>/<pasw>')
def login(name, pasw):
global login_name
conn = sqlite3.connect('user_info.db')
cursor = conn.cursor()
check_sql = "SELECT * FROM sqlite_master where type='table' and name='user'"
cursor.execute(check_sql)
results = cursor.fetchall()
# 数据库表不存在
if len(results) == 0:
# 创建数据库表
sql = """
CREATE TABLE user(
name CHAR(256),
pasw CHAR(256)
);
"""
cursor.execute(sql)
conn.commit()
print('创建数据库表成功!')
sql = "select * from user where name='{}' and pasw='{}'".format(name, pasw)
cursor.execute(sql)
results = cursor.fetchall()
login_name = name
if len(results) > 0:
return jsonify({
'info': name + '用户登录成功!', 'status': 'ok'})
else:
return jsonify({
'info': '当前用户不存在!', 'status': 'error'})
5 Ajax技术
Ajax 是一种独立于 Web 服务器软件的浏览器技术。
Ajax使用 JavaScript 向服务器提出请求并处理响应而不阻塞的用户核心对象XMLHttpRequest。通过这个对象,您的 JavaScript 可在不重载页面的情况与 Web 服务器交换数据,即在不需要刷新页面的情况下,就可以产生局部刷新的效果。
前端将需要的参数转化为JSON字符串,再通过get/post方式向服务器发送一个请并将参数直接传递给后台,后台对前端请求做出反应,接收数据,将数据作为条件查询,但会j’son字符串格式的查询结果集给前端,前端接收到后台返回的数据进行条件判断并作出相应的页面展示。
$.ajax({
url: 'http://127.0.0.1:5000/updatePass',
type: "POST",
data:JSON.stringify(data.field),
contentType: "application/json; charset=utf-8",
dataType: "json",
success: function(res) {
if (res.code == 200) {
layer.msg(res.msg, {
icon: 1});
} else {
layer.msg(res.msg, {
icon: 2});
}
}
})
6 Echarts
ECharts(Enterprise Charts)是百度开源的数据可视化工具,底层依赖轻量级Canvas库ZRender。兼容了几乎全部常用浏览器的特点,使它可广泛用于PC客户端和手机客户端。ECharts能辅助开发者整合用户数据,创新性的完成个性化设置可视化图表。支持折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)等,通过导入 js 库在 Java Web 项目上运行。
选题指导, 项目分享:
https://gitee.com/yaa-dc/warehouse-1/blob/master/python/README.md
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线