Java 中HashMap 详解_java hashmap-程序员宅基地
本篇重点:
1.HashMap的存储结构
2.HashMap的put和get操作过程
3.HashMap的扩容
4.关于transient关键字
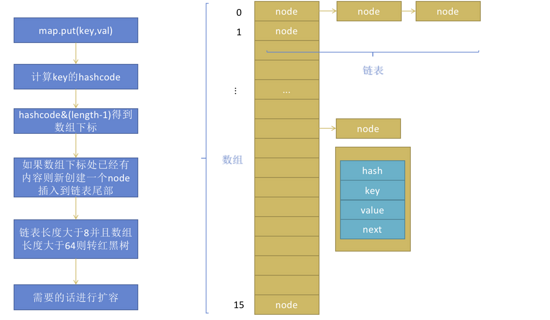
HashMap的存储结构
1. HashMap 总体是数组+链表的存储结构, 从JDK1.8开始,当数组的长度大于64,且链表的长度大于8的时候,会把链表转为红黑树。
2. 数组的默认长度是16。数组中的每一个元素为一个node,也就是链表的一个节点,node的数据包含: key的hashcode, key, value,指向下一个node节点的指针。
部分源码如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
...
}
3. 随着put操作的进行,如果数组的长度超过64,且链表的长度大于8的时候, 则将链表转为红黑树,红黑树节点的结构如下,TreeNode继承的LinkedHashMap.Entry是继承HashMap.Node的,所以TreeNode是上面Node的子类。
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
//...
}
4. HashMap类的主要成员变量:
/* ---------------- Fields -------------- */
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
View Code
HashMap的put操作过程
本小节讲述put操作中的主要步骤,细小环节会忽略。
1. map.put(key, value),首先计算key的hash,得到一个int值。
2.如果Node数组为空则初始化Node数组。这里注意,Node数组的长度length始终应该是2的n次方,比如默认的16, 还有32,64等
3.用 hash&(length-1) 运算得到数组下标,这里要提一句,其实正常我们最容易想到的,而且也是我之前很长一段时间以为的,这一步应该进行的是求模运算: hash % length ,这样得到的正好是0~length-1之间的值,可以作为数组的下标, 那么为何此处是位与运算呢?
先说结论: 上面提到数组的长度length始终是2^n,在这个前提下,hash & (length-1) 与hash % length是等价的。 而位与运算更快。这里后面会另开一遍进行详解。
4. 如果Node[hash&(length-1)]处为空,用传入的的key, value创建Node对象,直接放入该下标;如果该下标处不为空,且对象为TreeNode类型,证明此下标处的元素们是按照红黑树的结构存储的,将传入的key,value作为新的红黑树的节点插入到红黑树;否则,此处为链表,用next找到链表的末尾,将新的元素插入。如果在遍历链表的过程中发现链表的长度超过了8,此时如果数组长度<64则进行扩容,否则转红黑树。
5. 如果key的hash和key本身都相等则将该key对应的value更新为新的value
6. 需要扩容的话则进行扩容。
注意:
1. 如果key是null则返回的hash为0,也就是key为null的元素一直被放在数组下标为0的位置。
2. 在JDK 1.8以前,链表是采用的头部插入的方式,从1.8改成了在链表尾部插入新元素的方式。 这么做是为了防止在扩容的时候,多线程时出现循环链表死循环。具体会新开一遍进行详细演绎。
HashMap的get操作过程
get的过程比较简单。
1. map.get(key). 首先计算key的hash。
2. 根据hash&(length-1)定位到Node数组中的一个下标。如果该下标的元素(也就是链表/红黑树的第一个元素)中 key的hash的key本身 都和传入的key相同,则证明找到了元素,直接返回即可。
3.如果第一个元素不是要找的,如果第一个元素的类型是TreeNode,则按照红黑树的查找方法查找元素,如果不是则证明是链表,按照next指针找下去,直到找到或者到达队尾。
HashMap的扩容
先说这里的两个概念: size, length.
size:是map.size() 方法返回的值,表示的是map中有多少个key-value键值对儿
length: 这里是指Node数组的长度,比如默认长度是16.
如下面的代码:
Map<Integer,String> map = new HashMap<>();
map.put(1,"a");
map.put(2,"b");
map.put(3,"c");
没有在构造函数中指定HashMap的大小,则数组的长度length取默认的16,put了3个元素,则size为3.
Q: 何时需要扩容呢?
A: 在put方法中,每次完成了put操作,都判断一下++size是否大于threshold,如果大于则进行扩容: 调用resize()方法。
Q: 那么threshold又是如何得到的呢?
A: 简单来讲threshold = length * loadfactor(默认为0.75)。 也就是说默认情况下,map中的键值对的个数(size)大于Node数组长度(length)的75%时,就需要扩容了。
Q: 扩容时具体做什么呢?
A: 首先计算出新的数组长度和新的threshold(阈值). 简单来讲,新的length/capacity 是原来的2倍(位运算左移一位),新的threshold为原来的2倍。 还有一些细节此处不再赘述。创建新的Node数组,将原来数组中的元素重新映射到新的数组中。
关于transient关键字
transient关键字的作用:用transient关键字修饰的字段不会被序列化
查看下面的例子:
public class TransientExample implements Serializable{
private String firstName;
private transient String middleName;
private String lastName;
public TransientExample(String firstName,String middleName,String lastName) {
this.firstName = firstName;
this.middleName = middleName;
this.lastName = lastName;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("firstName:").append(firstName).append("\n")
.append("middleName:").append(middleName).append("\n")
.append("lastName:").append(lastName);
return sb.toString();
}
public static void main(String[] args) throws Exception {
TransientExample e = new TransientExample("Adeline","test","Pan");
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("/path/testObj"));
oos.writeObject(e);
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("/path/testObj"));
TransientExample e1 = (TransientExample) ois.readObject();
System.out.println("e:"+e.toString());
System.out.println("e1:"+e1.toString());
}
}
View Code
输出结果:
e:firstName:Adeline middleName:test lastName:Pan e1:firstName:Adeline middleName:null lastName:Pan
被transient关键字修饰的middleName字段没有被序列化,反序列化回来的值是null
Q:HashMap类是实现了Serializable接口的,那么为何其中的table, entrySet变量都标为transient呢?
A:我们知道,table数组中元素分布的下标位置是根据元素中key的hash进行散列运算得到的,而hash运算是native的,不同平台得到的结果可能是不相同的。举一个简单的例子,假设我们在目前的平台有键值对 key1-value1,计算出key1的hash为1, 计算后存在table数组中下标为1的地方,假设table被序列化了,并传输到了另外的平台,并反序列化为了原来的HashMap,key1-value1仍然存在下标1的位置,当在这个平台运行get("key1")的时候,可能计算出key1的hash为2,就有可能到下标为2的地方去找该元素,这样就出错了。
Q:那么HashMap是如何实现的序列化呢?
A:HashMap是通过实现如下方法直接将元素数量(size), key, value等写入到了ObjectOutputStream中,实现的定制化的序列化和反序列化。在Serializable接口中有关于这种做法的说明。
private void writeObject(java.io.ObjectOutputStream out)
throws IOException
private void readObject(java.io.ObjectInputStream in)
throws IOException, ClassNotFoundException;
智能推荐
PHP-生成缩略图和添加水印图-学习笔记-程序员宅基地
文章浏览阅读82次。1.开始 在网站上传图片过程,经常用到缩略图功能。这里我自己写了一个图片处理的Image类,能生成缩略图,并且可以添加水印图。2.如何生成缩略图 生成缩略图,关键的是如何计算缩放比率。 这里,我根据图片等比缩放,宽高的几种常见变化,得出一个算缩放比率算法是,使用新图(即缩略图)的宽高,分别除以原图的宽高,看哪个值大,就取它作为缩放比率:...
dyld: Library not loaded: @rpath/libswiftCore.dylib ... Reason: image not found 解决-程序员宅基地
文章浏览阅读2.7k次。在室友Xcode继承一些framework时,爆出了如下错误:dyld: Library not loaded: @rpath/libswiftCore.dylib Referenced from: /private/var/containers/Bundle/Application/1761A6FE-9D6B-45F7-9F9F-922C94BF54A3/demo.app/Framewor..._library not loaded: @rpath/libswiftcore.dylib
linux gvim 快捷键tab,Linux中Vim的常用命令及快捷键-程序员宅基地
文章浏览阅读356次。光标控制命令h或^h向左移一个字符j或^j或^n向下移一行k或^p向上移一行l或空格向右移一个字符G移到文件的最后一行nG移到文件的第n行w..._gvim itab
umi4 项目使用umi-plugin-keep-alive缓存页面(react-activation)-程序员宅基地
文章浏览阅读1k次,点赞12次,收藏10次。按 name 卸载缓存状态下的 节点,name 可选类型为 String 或 RegExp,注意,仅卸载命中 的第一层内容,不会卸载 中嵌套的、未命中的。按 name 刷新缓存状态下的 节点,name 可选类型为 String 或 RegExp,注意,仅刷新命中 的第一层内容,不会刷新 中嵌套的、未命中的。按 name 卸载缓存状态下的 节点,name 可选类型为 String 或 RegExp,将卸载命中 的所有内容,包括 中嵌套的所有。true: 卸载时缓存。获取所有缓存中的节点。_umi-plugin-keep-alive
memory compiler使用流程-程序员宅基地
文章浏览阅读3k次,点赞2次,收藏25次。用了几天的memory compiler,搞清楚了它的使用流程。因为这个软件是不开源的,而且手册又很长,没有快速阅读指南,所以就花了挺多时间学习手册细节,想把其中比较主要的流程记录下来,供大家学习参考。它是一个用来综合一些IP核的软件,它里面各种各样的memory compiler,可以根据自己的选择选中一个,设置好参数之后就能生成想要的参数的memory。 因为每个memory compiler可能工艺不一样,端口数不一样,所以里面有手册告诉你这些细节的。(手册很多,每个手册几百页上下)1、首先就是要安装_memory compiler
Android 读取csv格式数据文件-程序员宅基地
文章浏览阅读5.6k次,点赞5次,收藏16次。前言什么是csv文件呢?百度百科上说 CSV是逗号分隔值文件格式,也有说是电子表格的,既然是电子表格,那么就可以用Excel打开,那为什么要在Android中来读取这个.csv格式的文件呢?因为现在主流数据格式是采用的JSON,但是另一种就是.csv格式的数据,这种数据通常由数据库直接提供,进行读取。下面来看看简单的使用吧正文首先还是先来创建一个项目,名为ReadCSV准备.csv格式的文件,点击和风APILocationList下载ZIP,保存到本地,然后解压,这个时候在你的项目文件中新建_android 读取csv
随便推点
Hive与HBase之间的区别和联系_hive hbase-程序员宅基地
文章浏览阅读2.7w次,点赞36次,收藏161次。首先要知道Hive和HBase两者的区别,我们必须要知道两者的作用和在大数据中扮演的角色概念Hive1.Hive是hadoop数据仓库管理工具,严格来说,不是数据库,本身是不存储数据和处理数据的,其依赖于HDFS存储数据,依赖于MapReducer进行数据处理。2.Hive的优点是学习成本低,可以通过类SQL语句(HSQL)快速实现简单的MR任务,不必开发专门的MR程序。3.由于Hive是依赖于MapReducer处理数据的,因此有很高的延迟性,不适用于实时数据处理(数据查询,数据插_hive hbase
【故障诊断】BP神经网络电机数据特征提取与故障诊断【含Matlab源码 2569期】_故障特征量为无编码比值的bp神经网络-程序员宅基地
文章浏览阅读402次。BP神经网络电机数据特征提取与故障诊断完整的代码,方可运行;可提供运行操作视频!适合小白!_故障特征量为无编码比值的bp神经网络
BIOS、Legacy BIOS和UEFI BIOS:你需要知道的一切-程序员宅基地
文章浏览阅读1.1k次。BIOS 是计算机历史上的一个重要组成部分。这个术语最早是在 20 世纪 70 年代作为 Gary Kildall 开发的 CP/M(微型计算机控制程序)操作系统的一部分使用的。但 BIOS 至今仍在使用。然而,成功的技术现在越来越多地用于现代计算机。Legacy BIOS 和 UEFI BIOSBIOS 的含义是什么?该术语是 Basic Input/Output System(基本输入/输出系统)的首字母缩写,它描述的是作为非易失性存储器储存在计算机主板上的固件。_legacy bios
GitLab集成gitlab-runner_gitlab-runner 16.1.2-程序员宅基地
文章浏览阅读2k次。GitLab Runner是一个开源项目,用于运行您的作业并将结果发送回GitLab。它与GitLab CI结合使用,GitLab CI是GitLab随附的用于协调作业的开源持续集成服务。。_gitlab-runner 16.1.2
缓存数据库的意义、作用与种类详解-程序员宅基地
文章浏览阅读449次,点赞7次,收藏7次。Redis、Memcached等常见的缓存数据库,以及它们各自的特点和优势,使得开发人员可以根据应用场景选择最适合的解决方案。通过合理地配置和使用缓存数据库,可以有效地改善应用程序的性能,降低数据库负载,为用户提供更流畅的体验。缓存数据库允许应用程序在需要数据时,首先从缓存中查询数据,如果数据存在,则可以避免直接访问主数据库,从而显著提高数据访问速度。主数据库通常面临大量读写请求,而缓存数据库可以分担部分读请求,减轻主数据库的负载,提高其稳定性和可靠性。缓存数据库可以作为主数据库的备份,以防止数据丢失。
手把手教你安装VSCode(附带图解步骤)_vscode安装包-程序员宅基地
文章浏览阅读3.3w次,点赞38次,收藏158次。前端开发是创建Web页面或app等前端界面呈现给用户的过程,通过HTML,CSS及JavaScript以及衍生出来的各种技术、框架、解决方案,来实现互联网产品的用户界面交互[1]。它从网页制作演变而来,名称上有很明显的时代特征。在互联网的演化进程中,网页制作是Web1.0时代的产物,,用户使用网站的行为也以浏览为主。随着互联网技术的发展和HTML5、CSS3的应用,现代网页更加美观,交互效果显著,功能更加强大。[2]..._vscode安装包