Hadoop环境搭建(保姆级教学)_hadoop平台搭建步骤-程序员宅基地
Hadoop大数据
Hadoop环境搭建
一、基本配置
1、首先需要的环境:Centos7-版本不限,克隆三台配置好的机子、hadoop、jdk安装包、Xftp软件(缺一不可)
二、任务部署
1、安装VMware虚拟机
2、安装Centos7版本的虚拟机
3、准备3台配置完毕的虚拟机
4、搭建3台节点的Hadoop集群
三、Hadoop搭建的安装包
1、链接: https://pan.baidu.com/s/1gWpQ7Dh5dgXyjKfHUYuC5Q
提取码:k2q8
四、知识讲解
简单说明:
在搭建的过程中,小伙伴们统一保持和博主一样的配置
VMware版本:
- VMware建议使用博主给的安装包里面都有
- 关于VMware的安装,我已经把安装包放在了链接大家自取就行,里面是包含了VMware版本密钥的
linux版本:
- linux版本我就直接放这大家自取就行
- 链接: http://mirrors.aliyun.com/centos/7/isos/x86_64/
- 若链接失效请找博主索要镜像
1、linux系统的安装:
1、安装VMware
呃,博主这安装过了
vmware安装链接: https://blog.csdn.net/Alger_/article/details/111193639
- 配置
- 处理器数量:1
- 处理器的内核数量2
- 网络配置:NAT
- 虚拟机的内存:4096(4GB)
- 磁盘容量:40,将虚拟机磁盘存储为单个文件
- 软件安装:最小安装,除智能卡取消其他全选
- KDUMP:取消勾选
- Root密码:123123
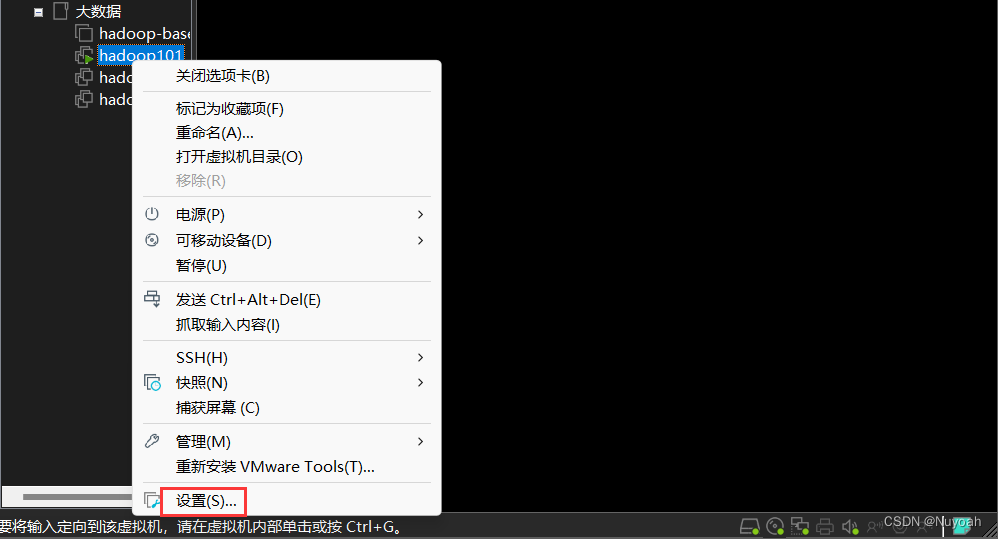
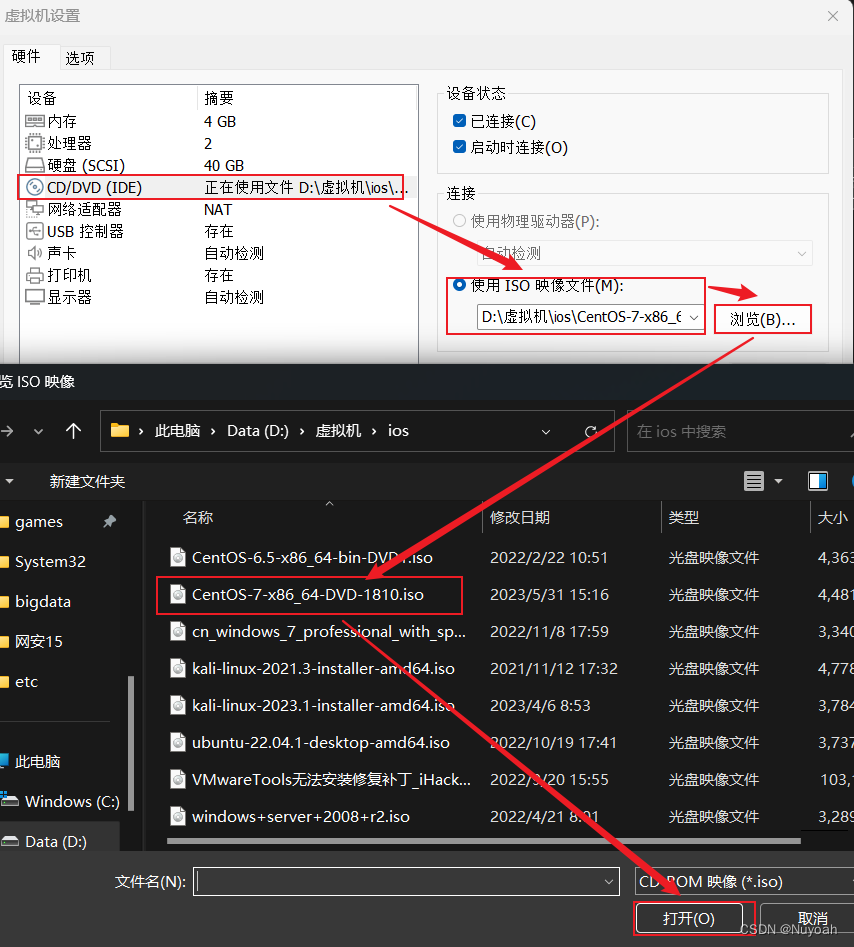
2、linux虚拟机配置ios
1:通过设置来配置ios镜像
3、linux虚拟机设置网络配置
1、设置虚拟机的虚拟网络配置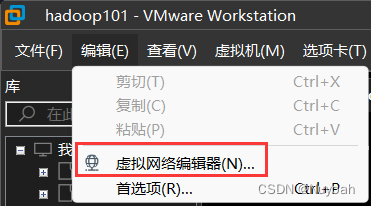
2、查看NAT的默认网关、ip地址以及子网掩码
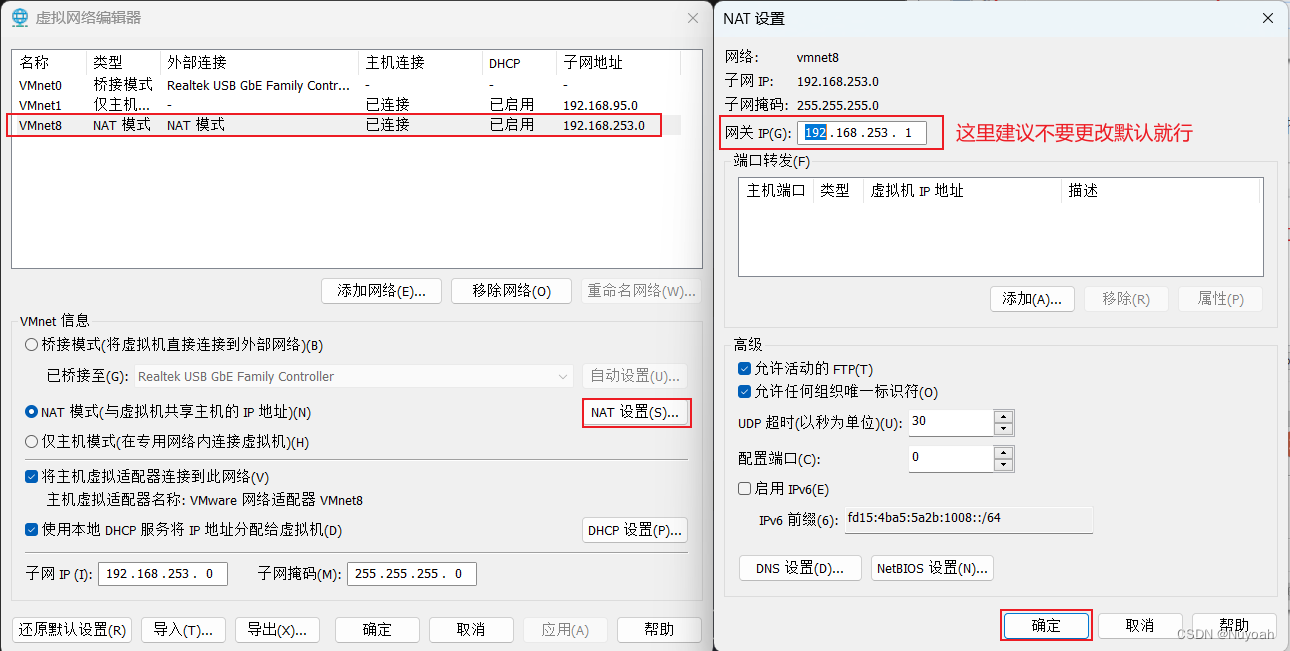
3、设置windwos的VMNet8网络地址
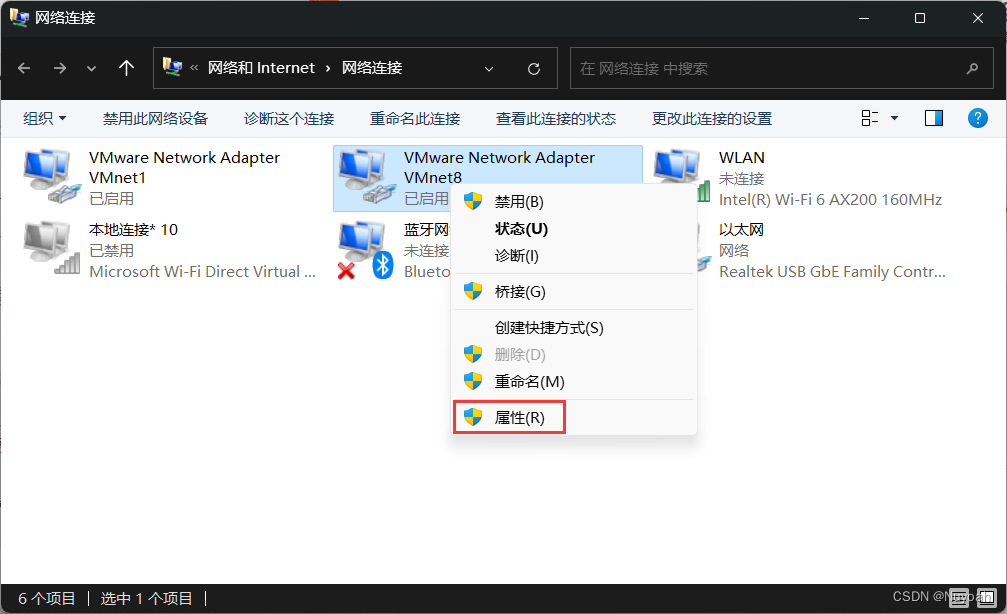
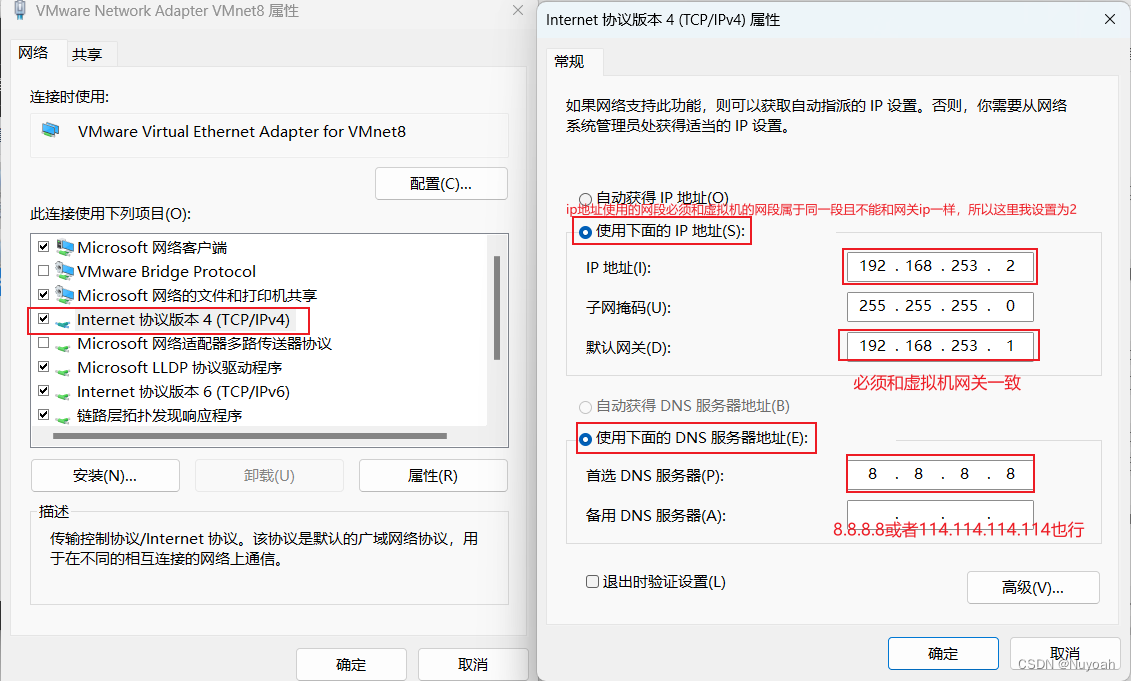
4、linux设置网络配置
- 网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
添加网络必备
IPADDR=192.168.253.100 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
编辑静态IP和开机自启
BOOTPROTO=static
NOBOOT=yes
重启网络服务
systemctl restart network
安装vim和常用软件
yum -y install vim
yum -y install net-tools
4、克隆虚拟机
- 反复创建虚拟机很难受,直接克隆最干脆
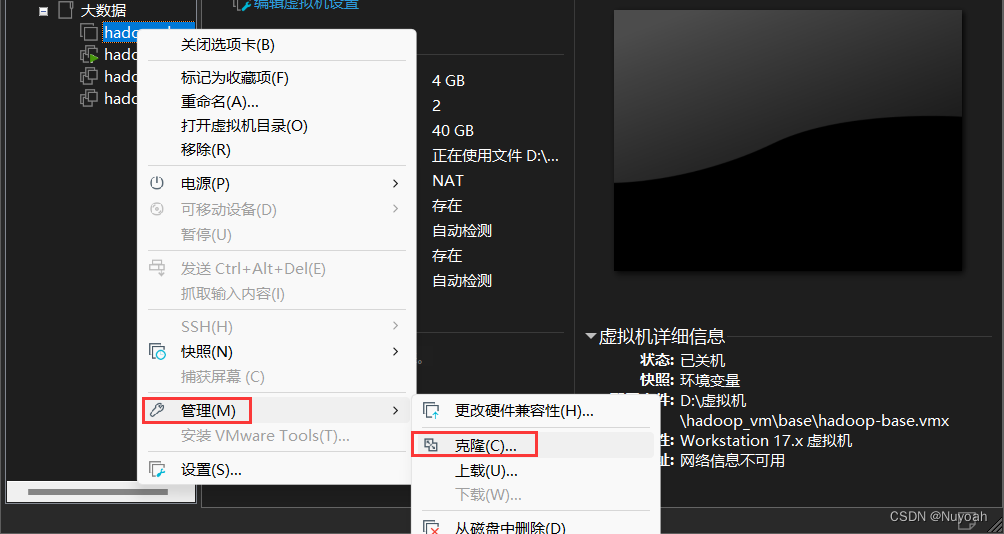
- 克隆搭建好的虚拟机的快照即可
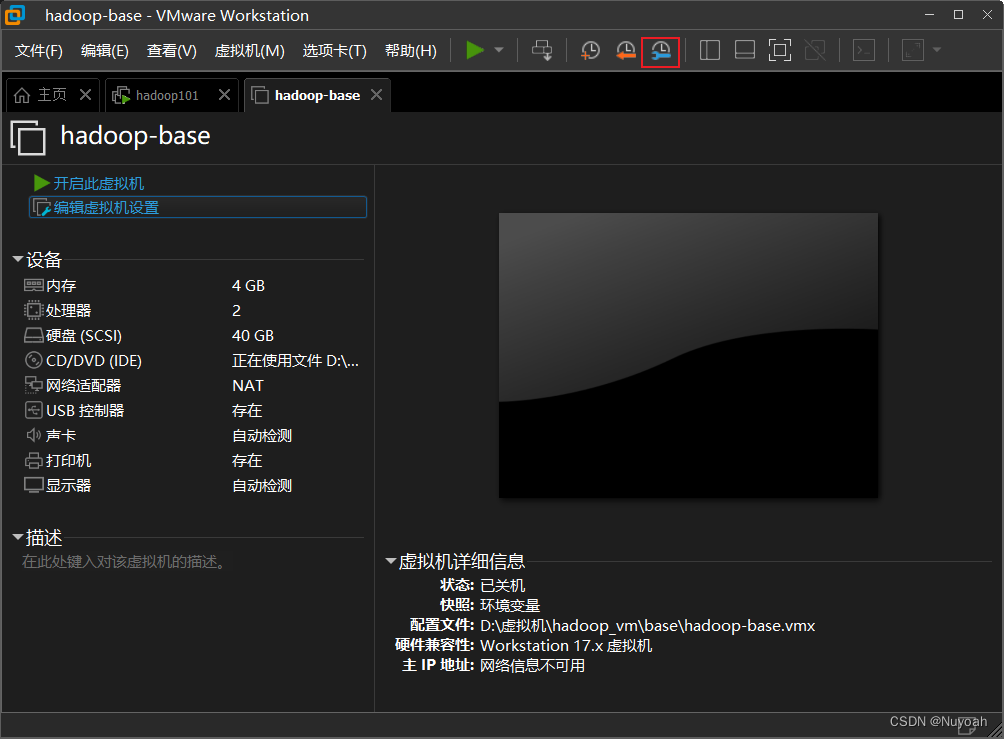
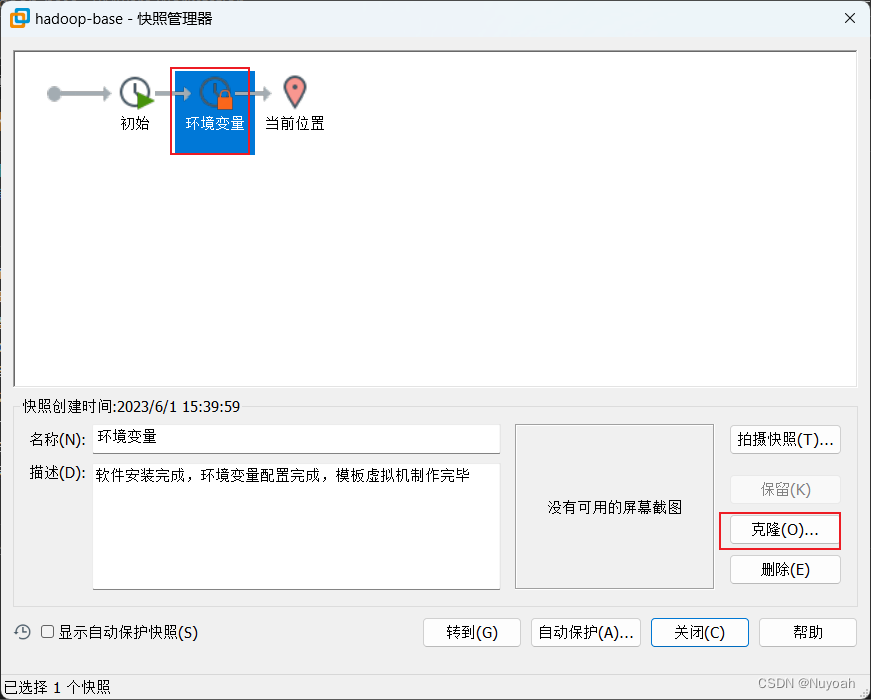

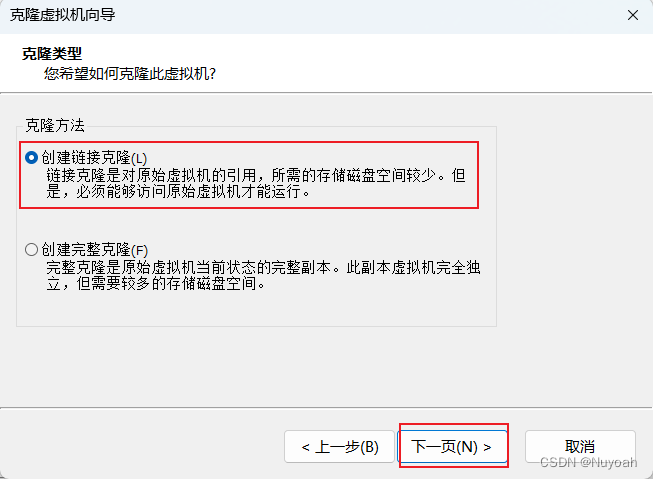
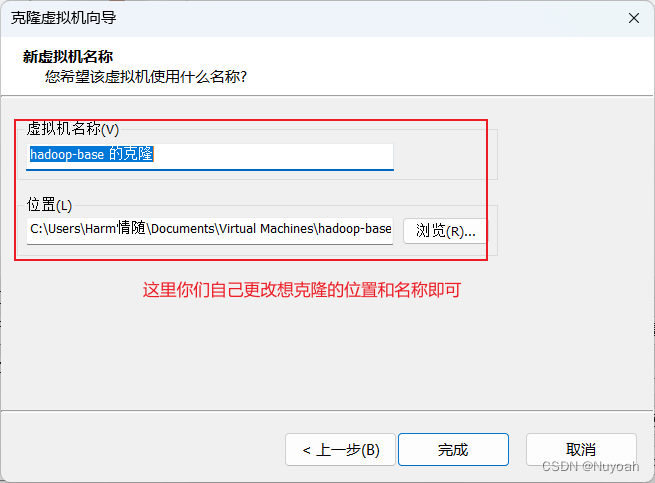
- 反复克隆出三台机子就够用了
5、克隆机更改ip地址
- 三台克隆机ip地址分别为:192.168.253.101、192.168.253.102、192.168.253.103
- 名称分别为:hadoop101、hadoop102、hadoop103
- 因克隆的虚拟机ip地址都相同,更改ip地址即可,其他可不要更改
- 启动虚拟机,用户为root,密码为123123
更改ip地址配置文件
hadoop101
vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.253.101 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
hadoop102
IPADDR=192.168.253.102 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
hadoop103
IPADDR=192.168.253.103 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
2、安装大数据集群环境基本配置
1、三台虚拟机关闭防火墙
systemctl status firewalld
若呈现绿色字样及未关闭
若现呈黑色字样及为关闭
systemctl stop firewalld
systemctl disable firewalld
2、三台虚拟机更改主机名
vim /etc/hostname
克隆机1
hadoop101
克隆机2
hadoop102
克隆机3
hadoop103
3、三台虚拟机更改主机名与ip映射地址
vim /etc/hosts
192.168.253.100 hadoop-base
192.168.253.101 hadoop101
192.168.253.102 hadoop102
192.168.253.103 hadoop103
192.168.253.104 hadoop104
192.168.253.105 hadoop105
4、三台虚拟机添加普通用户
- 三台虚拟机统一添加普通用户user001,并给予sudo权限,用于以后所有的大数据安装(避免root执行危险的操作)
- 普通用户密码为123123
useradd user001
passwd user001
5、三台虚拟机为普通用户添加sudo权限
vim /etc/sudoers
添加如下内容
user001 ALL=ALL(ALL) NOPASSWD:ALL
6、三台虚拟机在根目录统一目录
三台克隆机在根目录下创建bigdata目录—project、software
目录权限更改为user001
chown user001:user001 project/ software/
三台克隆机通过su命令切换user001用户
su user001
123123
7、三台虚拟机普通用户免密登录
- 先重启三台虚拟机使主机名生效
- 重启命令:reboot
- ssh免密登录方式
hadoop101:
ssh-keygen
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop101
hadoop102:
ssh-keygen
ssh-copy-id hadoop101
ssh-copy-id hadoop103
ssh-copy-id hadoop102
hadoop103:
ssh-keygen
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
8、通过Xftp传输hadoop、jdk软件包
- 使用方法
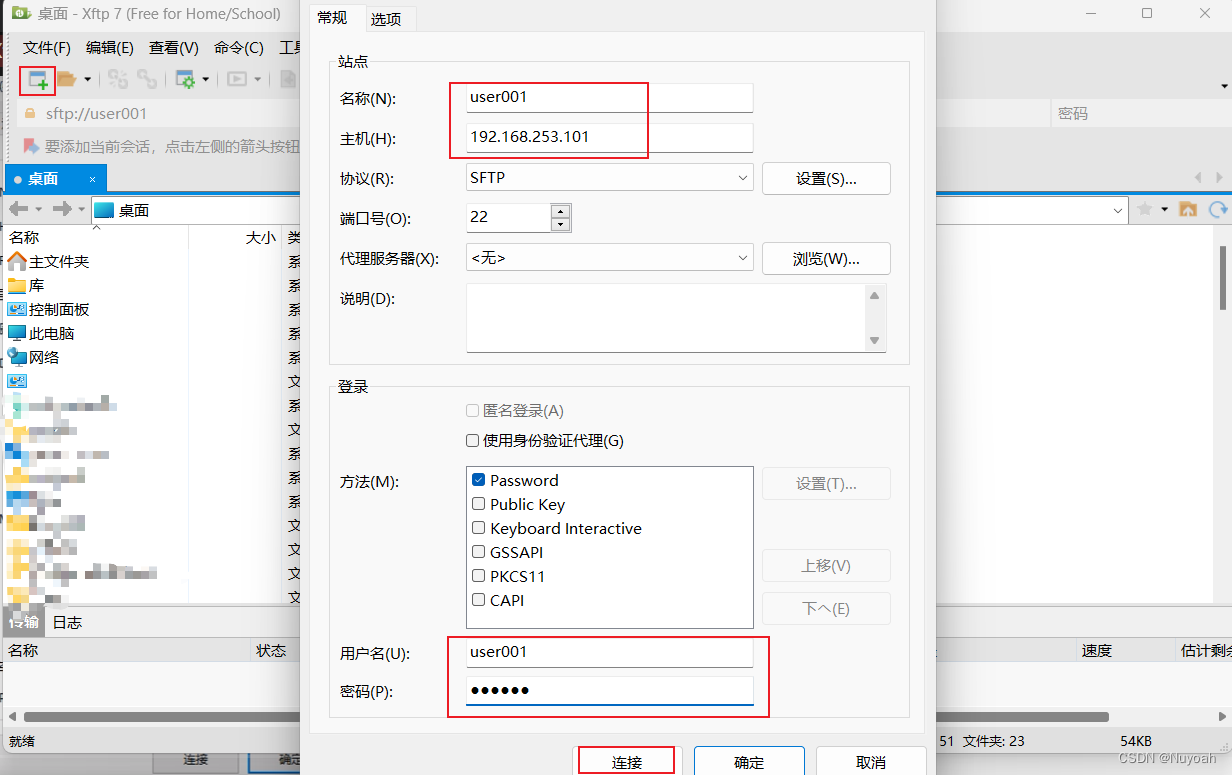
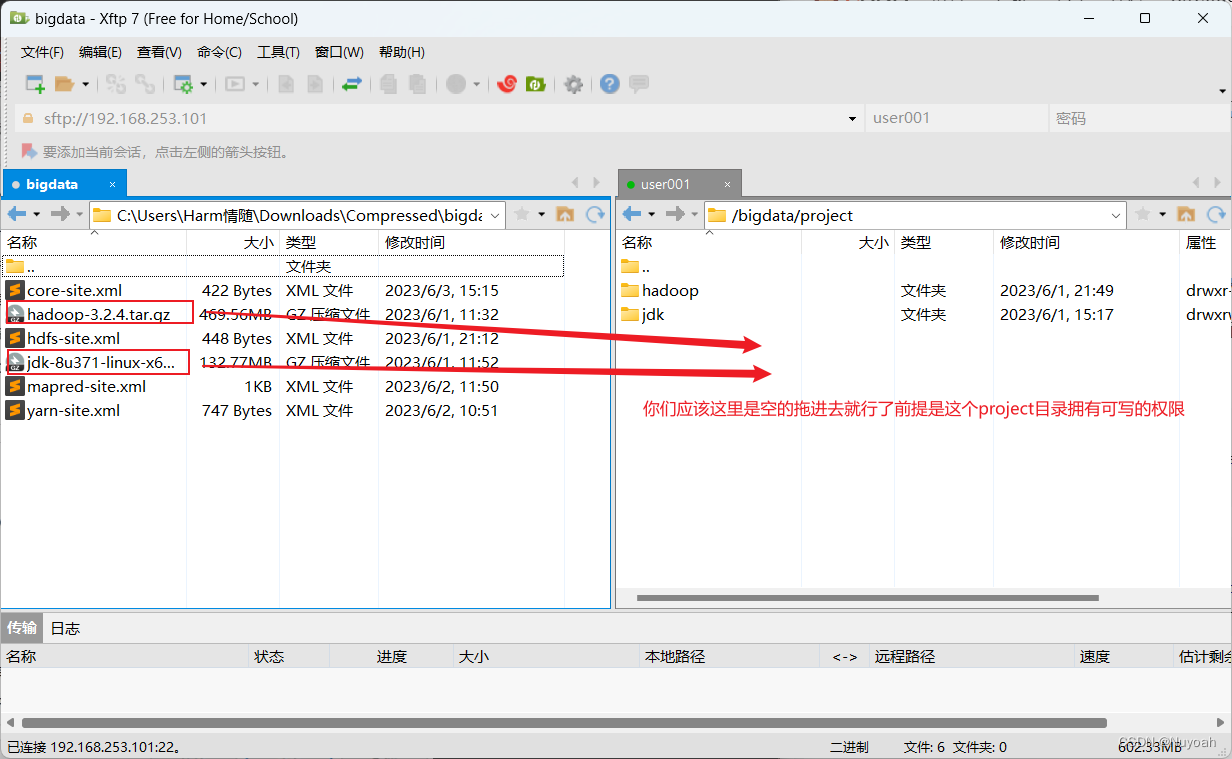
9、三台虚拟机安装jdk
- 使用user001来重新连接三台机器,使用user001来安装jdk软件
- 上传压缩包到第一台服务器的/bigdata/project/下面,进行解压,配置环境变量即可,三台都依次安装即可
cd //bigdata/project
cd …
cd /software
ll:tarX2(hadoop\jak)
tar -zxvf jdk----------------------.tar.gz -C /bigdata/project
tar -zxvf hadoop-------------------.tar.gz -C /bigdata/project
cd /project
mv hadoop---- /hadoop
mv jdk------- /jdk
- 配置jdk和hadoop环境变量
sudo vim /etc/profile.d/my_env.sh
内容:
JAVA_HOME
export JAVA_HOME=/bigdata/project/jdk
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
HADOOP_HOME
export HADOOP_HOME=/bigdata/project/hadoop
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin
export PATH= P A T H : PATH: PATH:HADOOP_HOME/sbin

source /etc/profile 更新源
- 建议三台克隆机都拍个快照
3、hadoop集群的安装
1、上传压缩包并解压
cd //bigdata/software
tar -zxvf hadoop-------------------.tar.gz -C /bigdata/project
2、修改hadoop配置文件
修改core-site.xml
- 第一台克隆机执行以下命令
vim core-site.xml
core-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/project/hadoop/data</value>
</property>
</configuration>
修改hdfs-site.xml
- 第一台克隆机执行以下命令
vim hdfs-site.xml
hdfs-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 2nn wen段访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
</configuration>
修改mapred-site.xml
- 第一台克隆机执行以下命令
vim mapred-site.xml
mapred-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
第一台克隆机执行以下命令
vim yarn-site.xml
yarn-site.xml:
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
</value>
</property>
</configuration>
修改workers文件
第一台克隆机执行以下命令
vim workers
替换
hadoop101
hadoop102
hadoop103
Xftp覆盖配置文件
把core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml这四个配置文件通过xftp覆盖到/bigdata/project/hadoop/etc/hadoop/下面
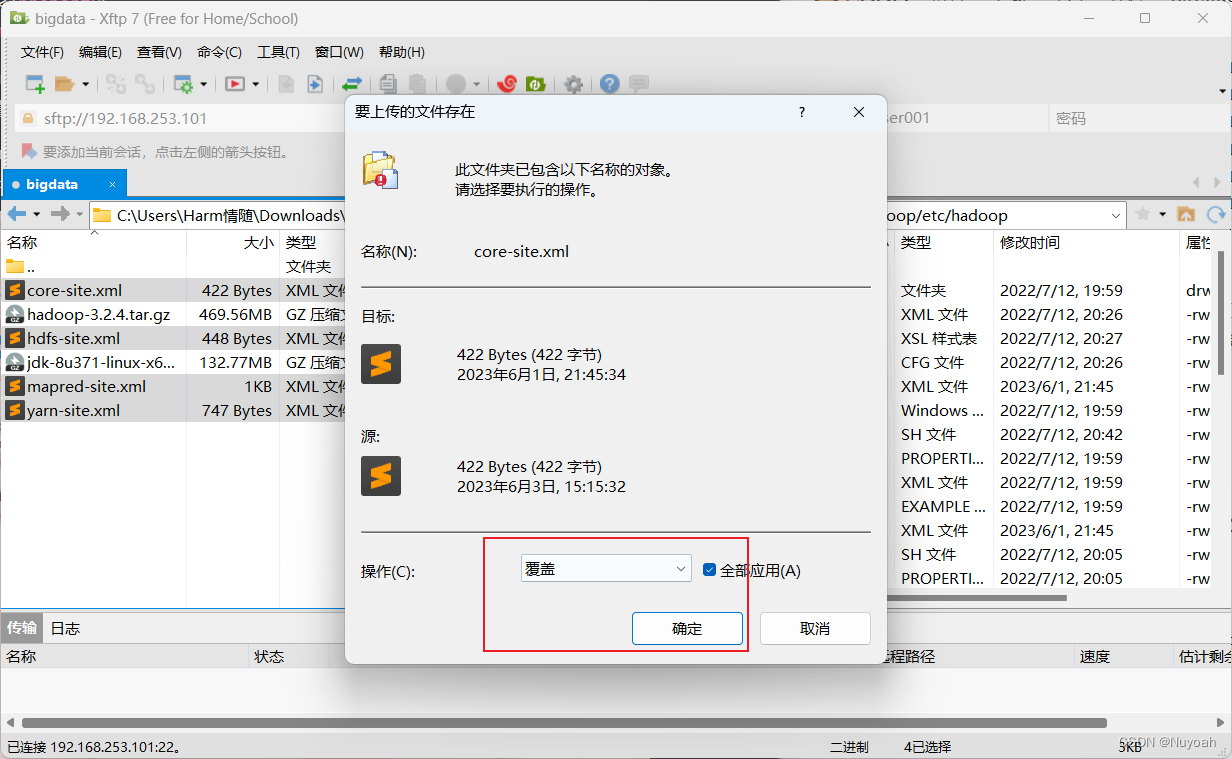
分发rsync
分发101配置文件给102和103的克隆机
hint:前提是要在/bigdata/project/Hadoop/etc/hadoop目录下
rsync -a -v ./ hadoop102:/bigdata/project/hadoop/etc/hadoop
rsync -a -v ./ hadoop103:/bigdata/project/hadoop/etc/hadoop
执行完之后在/bigdata/project/hadoop目录执行
hdfs namenode -format (对namenode进行格式化)=(对hdfs文件系统格式化)
没有报错则格式成功
4、Hadoop集群环境启动
101克隆机:hadoop的根目录下执行:sbin/start-dfs.sh 启动hdfs
102克隆机:hadoop的根目录下执行:sbin/start-yarn.sh 启动yarn
在浏览器上访问:
hadoop101:9870或ip+:9870
hadoop102:8088或ip+:8088
关闭服务
hadoop根目录下执行:stop-dfs.sh
hadoop根目录下执行:stop-yarn.sh
- ps 制作文章实属不易如帮助到你,请你给我个关注谢谢
智能推荐
vue引入原生高德地图_前端引入原生地图-程序员宅基地
文章浏览阅读556次,点赞2次,收藏3次。由于工作上的需要,今天捣鼓了半天高德地图。如果定制化开发需求不太高的话,可以用vue-amap,这个我就不多说了,详细就看官网 https://elemefe.github.io/vue-amap/#/zh-cn/introduction/install然而我们公司需要英文版的高德,我看vue-amap中好像没有这方面的配置,而且还有一些其他的定制化开发需求,然后就只用原生的高德。其实原生的引入也不复杂,但是有几个坑要填一下。1. index.html注意,引入的高德js一定要放在头部而_前端引入原生地图
ViewGroup重写大法 (一)-程序员宅基地
文章浏览阅读104次。本文介绍ViewGroup重写,我们所熟知的LinearLayout,RelativeLayout,FrameLayout等等,所有的容器类都是ViewGroup的子类,ViewGroup又继承View。我们在熟练应用这些现成的系统布局的时候可能有时候就不能满足我们自己的需求了,这是我们就要自己重写一个容器来实现效果。ViewGroup重写可以达到各种效果,下面写一个简单的重写一个Vi..._viewgroup 重写
Stm32学习笔记,3万字超详细_stm32笔记-程序员宅基地
文章浏览阅读1.8w次,点赞279次,收藏1.5k次。本文章主要记录本人在学习stm32过程中的笔记,也插入了不少的例程代码,方便到时候CV。绝大多数内容为本人手写,小部分来自stm32官方的中文参考手册以及网上其他文章;代码部分大多来自江科大和正点原子的例程,注释是我自己添加;配图来自江科大/正点原子/中文参考手册。笔记内容都是平时自己一点点添加,不知不觉都已经这么长了。其实每一个标题其实都可以发一篇,但是这样搞太琐碎了,所以还是就这样吧。_stm32笔记
CTS(13)---CTS 测试之Media相关测试failed 小结(一)_mediacodec框架 cts-程序员宅基地
文章浏览阅读1.8k次。Android o CTS 测试之Media相关测试failed 小结(一)CTSCTS 即兼容性测试套件,CTS 在桌面设备上运行,并直接在连接的设备或模拟器上执行测试用例。CTS 是一套单元测试,旨在集成到工程师构建设备的日常工作流程(例如通过连续构建系统)中。其目的是尽早发现不兼容性,并确保软件在整个开发过程中保持兼容性。CTS 是一个自动化测试工具,其中包括两个主要软件组件:CTS tra..._mediacodec框架 cts
chosen.js插件使用,回显,动态添加选项-程序员宅基地
文章浏览阅读4.5k次。官网:https://harvesthq.github.io/chosen/实例化$(".chosen-select").chosen({disable_search_threshold: 10});赋值var optValue = $(".chosen-select").val();回显1.设置回显的值$(".chosen-select").val(“opt1”);2.触发cho..._chosen.js
C++ uint8_t数据串如何按位写入_unit8_t 集合 赋值 c++-程序员宅基地
文章浏览阅读1.9k次。撸码不易,网上找不到,索性自己写,且撸且珍惜!void bitsWrite(uint8_t* buff, int pos, int size, uint32_t value){ uint32_t index[] = { 0x80000000, 0x40000000, 0x20000000, 0x10000000, 0x8000000, 0x4000000, 0x2000000, 0x1000000, 0x800000, 0x400000, 0_unit8_t 集合 赋值 c++
随便推点
Javaweb框架 思维导图_javaweb框架图-程序员宅基地
文章浏览阅读748次。javaweb知识点_javaweb框架图
adb的升级与版本更新_adb iptabls怎么升级-程序员宅基地
文章浏览阅读1.1w次,点赞3次,收藏16次。adb是没有自动升级的命令的,如果想要更新adb的版本,我们可以在网上找到自己想要的版本进行更新给大家提供几个版本https://pan.baidu.com/s/1yd0dsmWn5CK08MlyuubR7g&shfl=shareset 提取码: 94z81、下载解压后我们可以找到下面几个文件,并复制2、找到adb安装的文件夹下的platform-tools文件夹,我这里是..._adb iptabls怎么升级
微信苹果版删除所有的聊天记录的图文教程_mac微信怎么删除聊天列表-程序员宅基地
文章浏览阅读3.8k次。很多用户可能都知道怎么在Windows系统上删除微信的聊天记录,那么苹果电脑上的微信软件怎么删除所有的聊天记录呢?下面小编就专门来给大家讲下微信mac版删除所有的聊天记录的图文教程。点击后会弹出提示窗口,点击这里的确认按钮就可以将其清理掉了。在这里选择要清理的数据,然后点击下方右边的清理按钮就行了。在mac上打开微信后,点击左下角的横线图标。然后再点击这里的管理微信聊天数据按钮。打开了设置窗口,点击上方的“通用”。在这里点击下方的前往清理按钮。点击弹出菜单里的“设置”。_mac微信怎么删除聊天列表
【报错笔记】数据类型转换时报错:Request processing failed;nested exception is java.lang.NumberFormatException:..._request processing failed; nested exception is jav-程序员宅基地
文章浏览阅读7.7k次。数据类型转换时报错:Request processing failed;nested exception is java.lang.NumberFormatException:For input String “20151512345”报错原因:数字格式异常,接着后面有 For input string: “201515612343” 提示,这就告诉我们你当前想把 “201515612343” 转换成数字类型时出错了。解决方案:使用2015151612343这个数字太大了,所以直接使用string_request processing failed; nested exception is java.lang.numberformatexcepti
qml 自定义消息框_Qt qml 自定义消息提示框-程序员宅基地
文章浏览阅读387次。版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。本文链接:https://blog.csdn.net/a844651990/article/details/78376767Qt qml 自定义消息提示框QtQuick有提供比较传统的信息提示框MessageDialog,但是实际开发过程并不太能满足我们的需求。下面是根据controls2模块中..._qml 自定义 messagedialog
Redis.conf 默认出厂内容_默认出厂的原始redis.conf文件全部内容-程序员宅基地
文章浏览阅读599次。# Redis configuration file example.## Note that in order to read the configuration file, Redis must be# started with the file path as first argument:## ./redis-server /path/to/redis.conf # Note on units: when memory size is needed, it is pos._默认出厂的原始redis.conf文件全部内容