基于深度学习的驾驶行为检测(玩手机) 毕业设计_玩手机数据集-程序员宅基地
技术标签: python
0 简介
今天学长向大家分享一个毕业设计项目
毕业设计 基于深度学习的驾驶行为检测(玩手机)
项目运行效果:
毕业设计 深度学习的驾驶行为检测(玩手机)
项目获取:
https://gitee.com/sinonfin/algorithm-sharing
1 系统设计原则
为了使本次设计的吸烟检测系统具有更好的实用性、准确性和稳定性,同时能够让相关操作人员在使用时感受到便捷并且容易上手,在设计本系统时,主要遵循了以下五项基本原则:
(1)规范性原则:
在系统开发的过程当中所用到的控制协议、传输协议,编码类型等都应该符合国家标准和行业标准。在代码撰写时,应该符合一般的技术规范。
(2)模块化设计原则
模块化设计是指在系统设计时,尽可能的将多个基本功能设计为多个独立运行的模块,并且每一个模块只负责一件事情。这样就可以让系统结构更加清晰,同时在实际的运行过程中可以实现不同模块之间的调用,大大增加了系统的灵活性。这样做既可以用有限的模块来最大限度的完成用户的要求,同时对系统后期的维护以及功能的增加都非常有利。
(3)可操作性与可维护性原则
一个好的系统应该具有很好的可操作性,所以在符合用户使用习惯的基础上,对每一个具体操作进行简化。同时,为了使系统可以更加便于维护,在系统设计的过程当中,应该提前想清楚各个功能模块之间的难点与逻辑,这样才能在日后的维护当中减少工作量。
(4)可拓展性原则
系统开发将多个基本功能尽可能的设计为多个独立运行的模块,大大增加了系统的可拓展性。与此同时,开发过程当中,前端和后端的功能是分开进行的,通过提前设计好的可供数据传输的接口,以 JSON 数据格式在各个模块之间进行数据交换操作,使前后端之间具有解耦关系,这样做可以保证了系统具有比较良好的可扩展能力和稳定能力。
(5)经济性原则
在系统设计的时候,首先是要考虑用户的具体需求,设计实用的功能,发挥系统的最大性能。但是在满足用户所需的功能后,也应该尽可能的减少开发成本,采用更加经济的技术设备,不能只是一味地追求更高级更复杂的设计
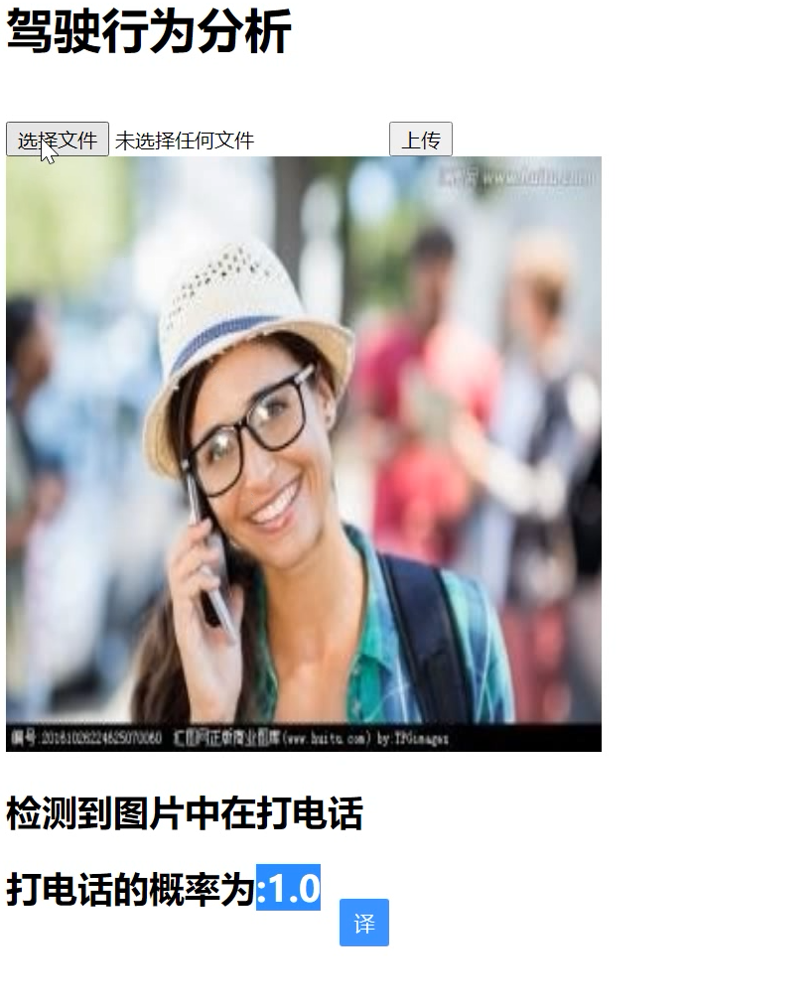
玩手机检测结果可视化:


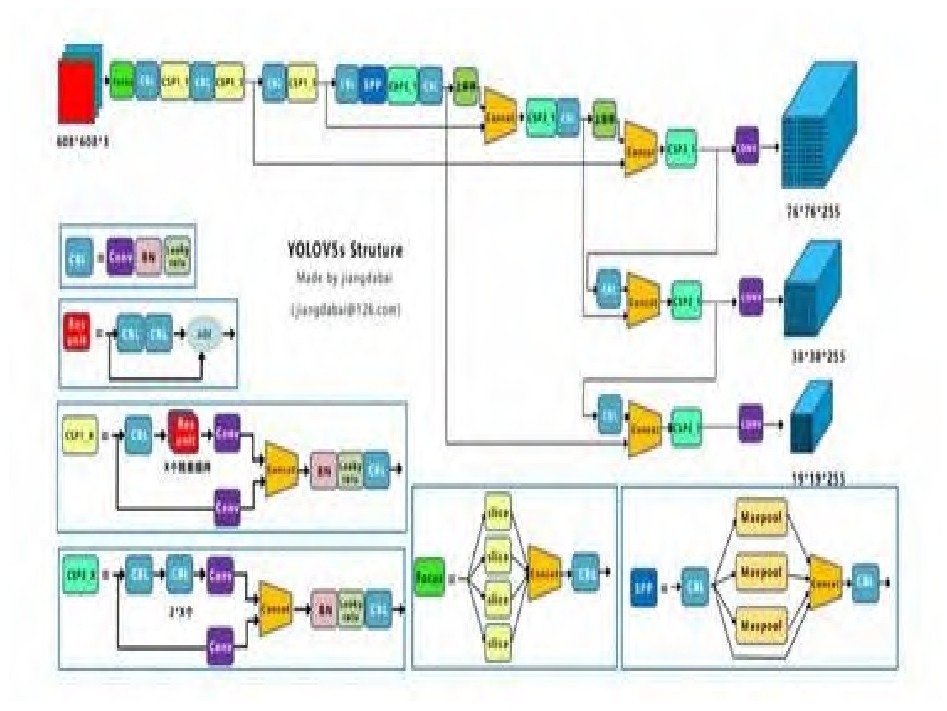
2 Yolov5算法
4.1 简介
YOLO系列是基于深度学习的回归方法。该系列陆续诞生出YOLOv1、YOLOv2、YOLOv3、YOLOv4、YOLOv5。YOLOv5算法,它是一种单阶段目标检测的算法,该算法可以根据落地要求灵活地通过chaneel和layer的控制因子来配置和调节模型,所以在比赛和落地中应用比较多。同时它有YOLOv5x、YOLOv5l、YOLOv5m、YOLOv5s四种模型。
具有以下优点:
- 在pytorch环境下编写;
- 可以很容易编译成ON⁃NX和Core ML;
- 运行速度很快,每秒可以达到140FPS的速度;
- 模型精度高;
- 集成了YOLOv3和YOLOv4的部分优秀特性,进行了推陈出新的改进。
2.2 相关技术
Mosaic数据增强
Mosaic数据增强技术采用了四张图片的随机缩放、随机剪裁、随机排布的方式对数据进行拼接,相比CutMix数据增强多用了两张图片。在目标识别过程中,要识别的目标有大目标、中等目标、小目标,并且三种目标的占比例不均衡,其中,小目标的数量是最多的,但是出现的频率很低,这种情况就会导致在bp时对小目标的优化不足,模型正确识别小目标的难度比识别中、大目标的难度要大很多,于是对于小目标来说很容易出现误检和漏检的情况。Mosaic数据增强技术做出改进后,上述的问题得到有效的解决。
该技术的优点是:
- 丰富了数据集,采用“三个随机”的方式对数据进行拼接丰富了检测的数据集,尤其是随机缩放增加了很多小目标,克服了小目标的不足,让网络的鲁棒性得到提高;
- 减少GPU的使用,在Mosaic增强训练时,四张图片拼接在一起,GPU可以直接计算四张图片的数据,让Mini-batch的大小减少了很多,这使得一个GPU就可以达到比较可观的效果。
自适应anchor
自适应anchor是check_anchors函数通过遗传算法与Kmeans迭代算出的最大可能召回率的anchor组合。在网络模型的训练过程中,网络在初始化的锚框的基础上输出预测框,然后与真实框groundtruth进行对比,计算两个框之间的差值,再根据差值进行反向更新,迭代网络参数,最后求出最佳的锚框值。自适应的anchor能够更好地配合网络训练,提高模型的精度,减少对anchor的设计难度,具有很好的实用性。
自适应图片缩放
为了提高模型的推理速度,YOLOv5提出自适应图片缩放,根据长宽比对图像进行缩放,并添加最少的黑边,减少计算量。该方法是用缩放后的长边减去短边再对32进行取余运算,求出padding。在训练时并没有采用缩减黑边的方法,该方法只是在测试模型推理的时候才使用,这样提高了目标检测的准确率和速度。
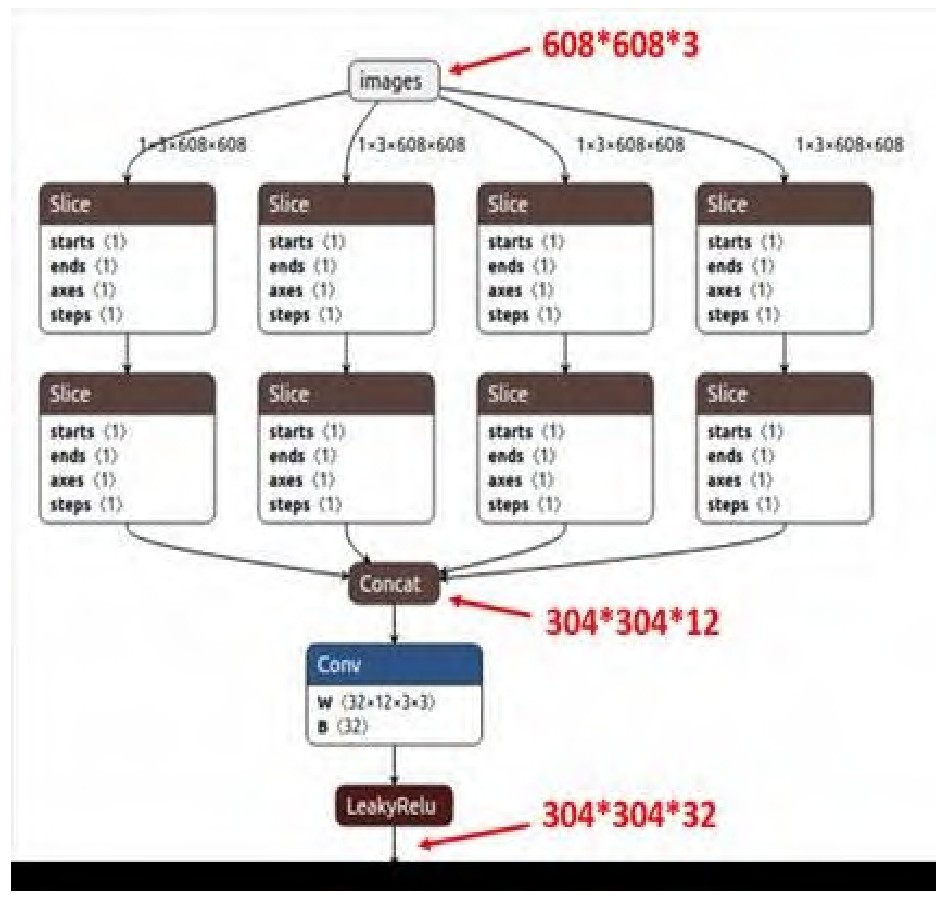
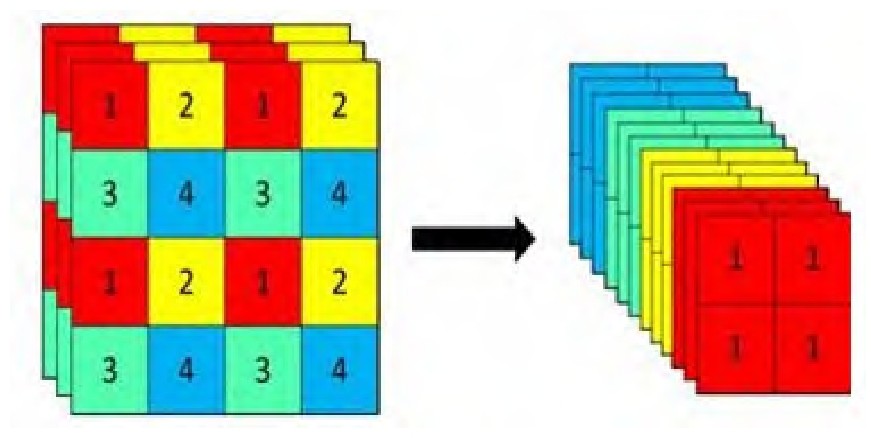
Focus结构
该结构采用切片操作,将特征切片成四份,每一份将当成下采样的特征,然后在channel维度进行concat。例如:原始6086083的数据图片,经过切片操作先变成30430412的特征图,再经过一次32个卷积核的卷积操作,变成30430432的特征图。
CSP结构
YOLOv5中的CSP[5]结构应用于两处,一处是CSP1_X结构应用于Backbone的主干网络中,另一处的CSP2_X结构应用于Neck中,用于加强网络的特征融合的能力。CSPNet主要从网络结构设计的角度解决推理中从计算量很大的问题。该结构的优点有:1)增强CNN的学习能力,使得模型在轻量化的同时保持较高的准确性;2)减低计算的瓶颈问题;3)减低内存的分险。
PFN+PAN结构
这个结构是FPN和PAN的联合。FPN是自顶向下的,将高层的特征信息通过上采样的方式进行传递融合,得到进行预测的特征图,而PAN正好与FPN的方向是相反的方向,它是自底向上地采取特征信息。两个结构各自从不同的主干层对不同的检测层进行参数聚合。两个结构的强强联合让得到的特征图的特征更加明显和清楚。
Bounding box的损失函数
Bounding box损失函数[6]增加了相交尺度的衡量方式,有效缓解了当两个框不相交和两个框大小完全相同的两种特殊情况。因为当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近的时候,此时的损失函数不可导;两个框大小完全相同,两个IOU也相同,IOU_LOSS无法区分以上两种特殊情况。
nms非极大值抑制
在目标检测过程的后续处理中,对于大量的目标框的筛选问题,通常会进行nms操作,以此来达到一个不错的效果。YO⁃LOv5算法同样采用了加权的nms操作。
3 数据集处理及实验
数据集准备
由于目前针对吸烟图片并没有现成的数据集,我们使用Python爬虫利用关键字在互联网上获得的图片数据,编写程序爬了1w张,筛选下来有近1000张可用,以及其他途径获取到的,暂时可用数据集有5k张,
深度学习图像标注软件众多,按照不同分类标准有多中类型,本文使用LabelImg单机标注软件进行标注。LabelImg是基于角点的标注方式产生边界框,对图片进行标注得到xml格式的标注文件,由于边界框对检测精度的影响较大因此采用手动标注,并没有使用自动标注软件。
考虑到有的朋友时间不足,博主提供了标注好的数据集和训练好的模型,需要请联系。
数据标注简介
通过pip指令即可安装
pip install labelimg
在命令行中输入labelimg即可打开

4 部分核心代码
# data/smoke.yaml
# COCO 2017 dataset http://cocodataset.org
# Download command: bash yolov5/data/get_coco2017.sh
# Train command: python train.py --data ./data/coco.yaml
# Dataset should be placed next to yolov5 folder:
# /parent_folder
# /coco
# /yolov5
# train and val datasets (image directory or *.txt file with image paths)
train: data\train.txt # 上面我们生成的train,根据自己的路径进行更改
val: data\test.txt # 上面我们生成的test
#test: ../coco/test-dev2017.txt # 20k images for submission to https://competitions.codalab.org/competitions/20794
# number of classes
nc: 1 #训练的类别
# class names
names: ['smoke']
# Print classes
# with open('data/coco.yaml') as f:
# d = yaml.load(f, Loader=yaml.FullLoader) # dict
# for i, x in enumerate(d['names']):
# print(i, x)
# model/yolov5s.yaml
# parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [116,90, 156,198, 373,326] # P5/32
- [30,61, 62,45, 59,119] # P4/16
- [10,13, 16,30, 33,23] # P3/8
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
]
# YOLOv5 head
head:
[[-1, 3, BottleneckCSP, [1024, False]], # 9
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 18 (P3/8-small)
[-2, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 22 (P4/16-medium)
[-2, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 26 (P5/32-large)
[[], 1, Detect, [nc, anchors]], # Detect(P5, P4, P3)
]
# 训练部分主函数
if __name__ == '__main__':
check_git_status()
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='*.cfg path')
parser.add_argument('--data', type=str, default='data/smoke.yaml', help='*.data path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='train,test sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', action='store_true', help='resume training from last.pt')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--weights', type=str, default='', help='initial weights path')
parser.add_argument('--name', default='', help='renames results.txt to results_name.txt if supplied')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--adam', action='store_true', help='use adam optimizer')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
opt = parser.parse_args()
opt.weights = last if opt.resume else opt.weights
opt.cfg = check_file(opt.cfg) # check file
opt.data = check_file(opt.data) # check file
print(opt)
opt.img_size.extend([opt.img_size[-1]] * (2 - len(opt.img_size))) # extend to 2 sizes (train, test)
device = torch_utils.select_device(opt.device, apex=mixed_precision, batch_size=opt.batch_size)
if device.type == 'cpu':
mixed_precision = False
# Train
if not opt.evolve:
tb_writer = SummaryWriter(comment=opt.name)
print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
train(hyp)
# Evolve hyperparameters (optional)
else:
tb_writer = None
opt.notest, opt.nosave = True, True # only test/save final epoch
if opt.bucket:
os.system('gsutil cp gs://%s/evolve.txt .' % opt.bucket) # download evolve.txt if exists
for _ in range(10): # generations to evolve
if os.path.exists('evolve.txt'): # if evolve.txt exists: select best hyps and mutate
# Select parent(s)
parent = 'single' # parent selection method: 'single' or 'weighted'
x = np.loadtxt('evolve.txt', ndmin=2)
n = min(5, len(x)) # number of previous results to consider
x = x[np.argsort(-fitness(x))][:n] # top n mutations
w = fitness(x) - fitness(x).min() # weights
if parent == 'single' or len(x) == 1:
# x = x[random.randint(0, n - 1)] # random selection
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
# Mutate
mp, s = 0.9, 0.2 # mutation probability, sigma
npr = np.random
npr.seed(int(time.time()))
g = np.array([1, 1, 1, 1, 1, 1, 1, 0, .1, 1, 0, 1, 1, 1, 1, 1, 1, 1]) # gains
ng = len(g)
v = np.ones(ng)
while all(v == 1): # mutate until a change occurs (prevent duplicates)
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
hyp[k] = x[i + 7] * v[i] # mutate
# Clip to limits
keys = ['lr0', 'iou_t', 'momentum', 'weight_decay', 'hsv_s', 'hsv_v', 'translate', 'scale', 'fl_gamma']
limits = [(1e-5, 1e-2), (0.00, 0.70), (0.60, 0.98), (0, 0.001), (0, .9), (0, .9), (0, .9), (0, .9), (0, 3)]
for k, v in zip(keys, limits):
hyp[k] = np.clip(hyp[k], v[0], v[1])
# Train mutation
results = train(hyp.copy())
# Write mutation results
print_mutation(hyp, results, opt.bucket)
# Plot results
# plot_evolution_results(hyp)
项目运行效果:
毕业设计 深度学习的驾驶行为检测(玩手机)
最后
项目获取:
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法