mapr 和cdh对比
PySpark是一个Spark API,可让您通过Python Shell与Spark进行交互。 如果您具有Python编程背景,那么这是入门Spark数据类型和并行编程的绝佳方法。 PySpark是探索性大数据分析的一种特别灵活的工具,因为它与Python数据分析生态系统的其余部分集成在一起,包括pandas(DataFrames),NumPy(数组)和Matplotlib(可视化)。 在此博客文章中,您将获得使用PySpark和MapR Sandbox的动手经验。
示例:在网络数据上使用聚类来识别异常行为
无监督学习是探索性的数据分析领域。 这些方法用于了解数据的结构和行为。 请记住,这些方法不是用来预测或分类,而是用来解释和理解。
聚类是一种流行的无监督学习方法,其中算法尝试识别数据中的自然组。 K均值是使用最广泛的聚类算法,其中“ k”是数据所属的组数。 在k均值中, k由分析师分配,选择k的值就是数据解释起作用的地方。
在此示例中,我们将使用来自年度数据挖掘竞赛的数据集,即KDD Cup( http://www.sigkdd.org/kddcup/index.php )。 一年(1999年)的主题是网络入侵,数据集仍然可用( http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html )。 数据集将是kddcup.data.gz文件,由42个要素和大约490万行组成。
在网络数据上使用聚类来识别异常行为是无监督学习的一种常见用法。 收集到的大量数据使得无法遍历每个日志或事件来正确确定该网络事件是正常还是异常。 入侵检测系统(IDS)和入侵防御系统(IPS)通常是网络必须过滤该数据的唯一应用程序,并且该过滤器通常是根据异常签名分配的,这些签名可能需要花费一些时间才能更新。 在更新发生之前,拥有分析技术来检查网络数据中最近的异常活动非常有价值。
K-means还用于分析社交媒体数据,金融交易和人口统计数据。 例如,您可以使用聚类分析来确定使用纬度,经度和情感分数从特定地理区域发布推文的Twitter用户组。
在很多书籍和博客中都可以找到使用Scala在Spark中计算k均值的代码。 在PySpark中实现此代码使用的语法略有不同,但是许多元素相同,因此看起来很熟悉。 MapR沙盒提供了一个绝佳的环境,其中已经预装了Spark,使您可以直接进行分析,而不必担心软件安装。
安装沙箱
本示例中的说明将使用Virtual Box中的沙盒,但可以使用VMware或Virtual Box。 有关在Virtual Box中安装沙箱的说明,请单击此链接。
http://maprdocs.mapr.com/51/#SandboxHadoop/t_install_sandbox_vbox.html
在您的虚拟机中启动沙箱
首先,启动使用VMware或Virtual Box安装的MapR沙盒。 可能需要一两分钟才能完全启动。
注意:您需要按MacOS中的“命令”键或Windows中的右“控制”键,以将鼠标光标移出控制台窗口。
沙盒启动后,看看会发生什么。 沙盒本身是一个可以与数据进行交互的环境,但是如果您访问http://127.0.0.1:8443/ ,则可以访问文件系统并熟悉数据的存储方式。
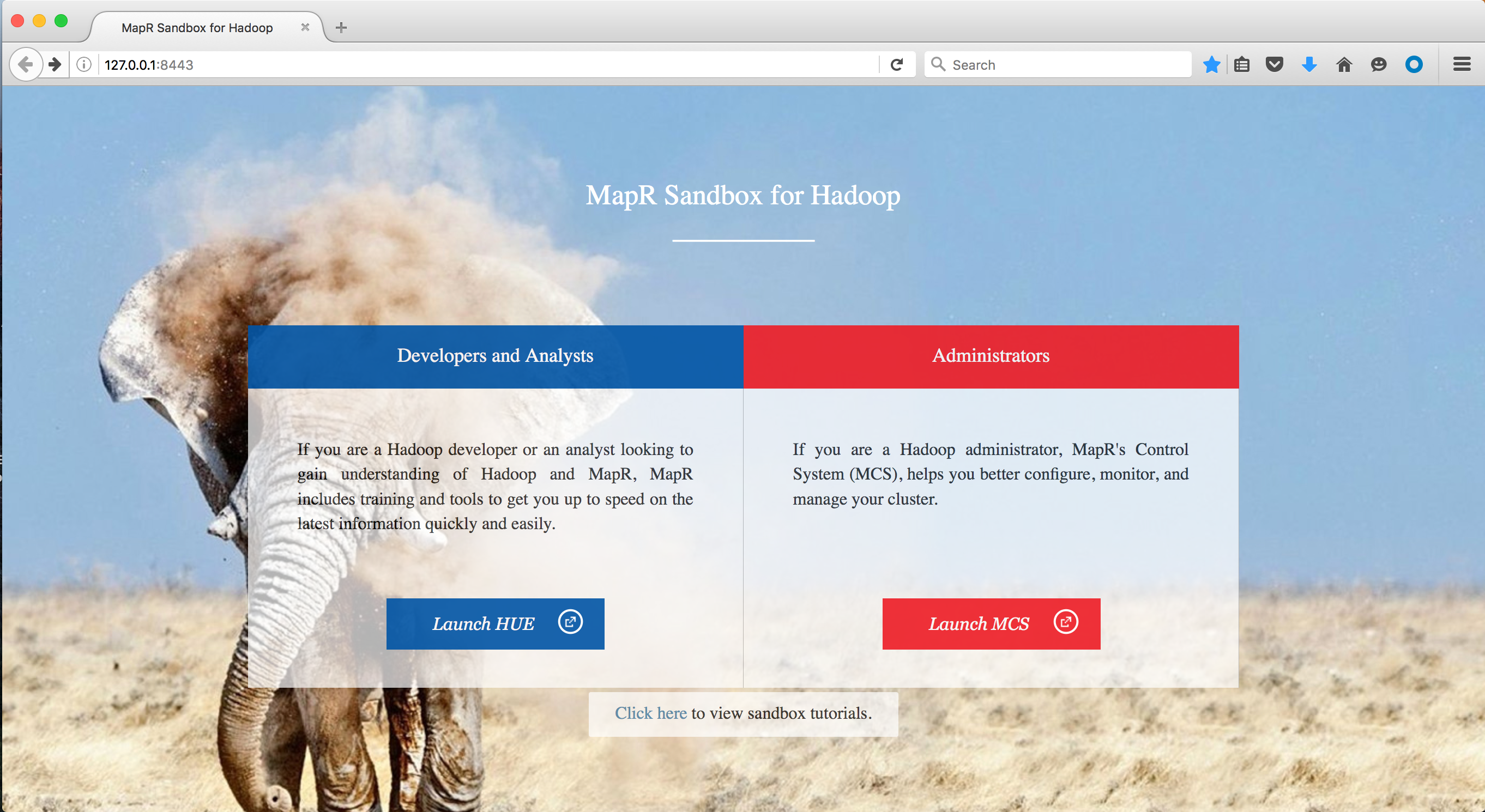
对于本教程,我们将在HUE中进行。 启动HUE并输入用户名/密码组合:用户名:
Username: mapr
Password: mapr打开HUE后,转到文件浏览器:
在文件浏览器中的时,您将看到您在/ user / mapr目录中。
我们将以user01的身份运行。 要进入该目录,请单击/ user目录
确保您看到user01。
现在,我们可以在沙箱中访问user01了。 在这里,您可以创建文件夹并存储用于测试Spark代码的数据。 在使用沙箱本身时,可以选择使用沙箱命令行,也可以通过终端或计算机上的PuTTY作为“ user01”进行连接。 如果选择通过终端连接,请使用ssh和以下命令: $ ssh user01@localhost -p 2222密码为: mapr
Welcome to your Mapr Demo Virtual machine.
[user01@maprdemo ~]$对于本教程,我使用的是Mac笔记本电脑和名为iTerm2的终端应用程序。 我也可以在Mac中使用普通的默认终端。
沙盒已安装Spark。 沙箱上还安装了Python,Python版本为2.6.6。
[user01@maprdemo ~]$ python --version
Python 2.6.6PySpark使用Python和Spark; 但是,还需要一些其他软件包。 要安装这些其他软件包,我们需要成为沙箱的root用户。 (密码是:映射器)
[user01@maprdemo ~]$ su -
Password:
[root@maprdemo ~]#
[root@maprdemo ~]# yum -y install python-pip
[root@maprdemo ~]# pip install nose
[root@maprdemo ~]# pip install numpynumpy安装可能需要一两分钟。 NumPy和Nose是允许在Python中进行数组操作和单元测试的软件包。
[root@maprdemo ~]# su - user01
[user01@maprdemo ~]$沙箱中的PySpark
要启动PySpark,请输入以下内容:
[user01@maprdemo ~]$ pyspark --master yarn-client
下面是您的输出大致的屏幕快照。 您将处于Spark中,但具有Python shell。
以下代码将在>>>提示符下在PySpark中执行。
复制并粘贴以下内容以加载此练习的依赖程序包:
from collections import OrderedDict
from numpy import array
from math import sqrt
import sys
import os
import numpy
import urllib
import pyspark
from pyspark import SparkContext
from pyspark.mllib.feature import StandardScaler
from pyspark.mllib.clustering import Kmeans, KmeansModel
from pyspark.mllib.linalg import DenseVector
from pyspark.mllib.linalg import SparseVector
from collections import OrderedDict
from time import time 
接下来,我们将检查我们的工作目录,将数据放入其中,并检查以确保它存在。
检查目录:
os getcwd()
>>>> os.getcwd()
'/user/user01'获取数据
f = urllib.urlretrieve ("http://kdd.ics.uci.edu/databases/kddcup99/kddcup.data.gz", "kddcup.data.gz")检查数据是否在当前工作目录中
os.listdir('/user/user01')
现在,您应该在目录“ user01”中看到kddcup.data.gz 。 您也可以签入HUE。
数据导入与探索
PySpark可以将压缩文件直接导入RDD。
data_file = "./kddcup.data.gz"
kddcup_data = sc.textFile(data_file)
kddcup_data.count() 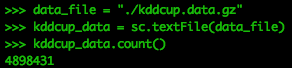
查看RDD的前5条记录
kddcup_data.take(5)

此输出很难读取。 这是因为我们要求PySpark向我们显示RDD格式的数据。 PySpark具有DataFrame功能。 如果Python版本是2.7或更高版本,则可以使用pandas软件包。 但是,pandas在2.6版本的Python上不起作用,因此我们使用Spark SQL功能来创建DataFrame进行探索。
from pyspark.sql.types import *
from pyspark.sql import DataFrame
from pyspark.sql import SQLContext
from pyspark.sql import Row
kdd = kddcup_data.map(lambda l: l.split(","))
df = sqlContext.createDataFrame(kdd)
df.show(5) 
现在我们可以更好地看到数据的结构。 没有数据的列标题,因为它们不包含在我们下载的文件中。 它们在单独的文件中,可以附加到数据中。 对于本练习,这不是必需的,因为我们更关注数据中的组而不是特征本身。
此数据已被标记,这意味着恶意网络行为的类型已分配给一行。 该标签是上面的屏幕截图中的最后一个功能_42。 数据集的前五行标记为“正常”。 但是,我们应该确定整个数据集的标签计数。
现在让我们了解一下此数据中标签的不同类型,以及每个标签的总数。 让我们花时间多长时间。
labels = kddcup_data.map(lambda line: line.strip().split(",")[-1])
start_label_count = time()
label_counts = labels.countByValue()
label_count_time = time()-start_label_count 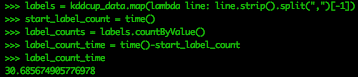
sorted_labels = OrderedDict(sorted(label_counts.items(), key=lambda t: t[1], reverse=True))
for label, count in sorted_labels.items(): #simple for loop
print label, count 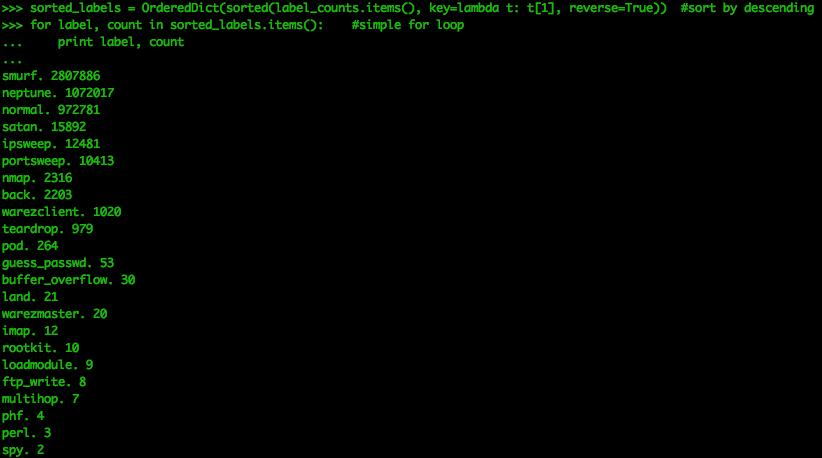
我们看到有23个不同的标签。 蓝精灵攻击被称为定向广播攻击,是DoS数据包泛滥的一种流行形式。 该数据集显示“正常”事件是第三多发生的事件。 虽然这对于学习资料很好,但不应将此数据集误认为是真实的网络日志。 在真实的网络数据集中,将没有标签,并且正常流量将比任何异常流量大得多。 这导致数据不平衡,从而使识别恶意行为者更具挑战性。
现在,我们可以开始为聚类算法准备数据了。
数据清理
K均值仅使用数字值。 该数据集包含三个分类的特征(不包括攻击类型特征)。 在本练习中,将从数据集中删除它们。 但是,可以执行一些特征转换,在这些特征转换中,这些分类分配将被赋予其自己的特征,并根据是否为“ tcp”为它们分配二进制值1或0。
首先,我们必须解析数据,方法是将原始RDD kddcup_data拆分为列,并删除从索引1开始的三个分类变量,并删除最后一列。 然后将其余的列转换为数值数组,然后将其附加到最后的标签列,以形成数字数组和元组中的字符串。
def parse_interaction(line):
line_split = line.split(",")
clean_line_split = [line_split[0]]+line_split[4:-1]
return (line_split[-1], array([float(x) for x in clean_line_split]))
parsed_data = kddcup_data.map(parse_interaction)
pd_values = parsed_data.values().cache() 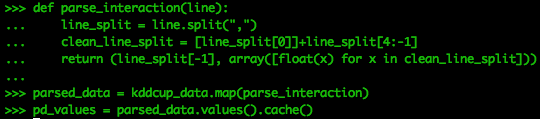
我们将解析器中的值放入缓存中以便于调用。
沙盒没有足够的内存来处理本教程的整个数据集,因此我们将抽取数据样本。
kdd_sample = pd_values.sample(False, .10, 123)
kdd_sample.count() 
我们已获取了10%的数据。 sample()函数采用不替换(假)的值(占总数据的10%),并使用123 set.seed功能重复此样本。
接下来,我们需要标准化数据。 StandardScaler通过缩放到单位方差并使用训练集中样本的列汇总统计信息将均值设置为零来对特征进行标准化。 标准化可以提高优化过程中的收敛速度,还可以防止差异很大的特征在模型训练过程中产生影响。
standardizer = StandardScaler(True, True)
通过安装StandardScaler计算摘要统计信息
standardizer_model = standardizer.fit(kdd_sample)
标准化每个特征以具有单位标准偏差。
data_for_cluster = standardizer_model.transform(kdd_sample)

集群数据
在Python的scikit-learn中进行k均值与在Spark中进行k均值有何不同? Pyspark的MLlib实现包括k-means ++方法的并行化变体(这是Scikit-Learn的实现的默认设置),称为k-means ||。 这是k均值的并行化版本。 在《 Scala数据分析食谱》(Packt Publishing,2015年)中 ,Arun Manivannan解释了它们之间的区别:
K均值++
与随机选择所有质心不同,k-means ++算法执行以下操作:
- 它随机选择第一个质心(均匀)
- 它从当前质心计算出其余所有点的距离的平方
- 根据这些点的距离,将它们附加到每个点上。 质心候选者越远,其可能性就越高。
- 我们从步骤3中的分布中选择第二个质心。在第i个迭代中,我们有1 + i个簇。 通过遍历整个数据集并基于这些点与所有预先计算的质心的距离来形成分布,从而找到新的质心。 在k-1次迭代中重复这些步骤,直到选择了k个质心。 K-means ++以显着提高质心的质量而闻名。 但是,正如我们看到的那样,为了选择质心的初始集合,该算法遍历了整个数据集k次。 不幸的是,对于大型数据集,这成为一个问题。
K-均值||
在k均值(K-means ||)平行的情况下,对于每次迭代,在计算数据集中每个点的概率分布之后,不选择单个点,而是选择更多的点。 对于Spark,每步选择的样本数为2 * k。 一旦选择了这些初始质心候选,就对这些数据点运行k-均值++(而不是遍历整个数据集)。
对于此示例,我们将继续使用k-means ++,因为我们仍在沙箱中而不是集群中。 您会在代码的初始化中看到以下内容:
initializationMode="random"
如果我们想并行执行k均值:
initializationMode="k-means||"
有关更多信息,请参考MLlib文档。 ( http://spark.apache.org/docs/1.6.2/api/python/pyspark.mllib.html#pyspark.mllib.clustering.KMeans )
在执行k均值时,分析人员选择k的值。 但是,我们可以将其打包成循环遍历k值数组的循环,而不是每次都为k运行算法。 在本练习中,我们只是在做k的三个值。 我们还将创建一个称为指标的空列表,该列表将存储循环中的结果。
k_values = numpy.arange(10,31,10)
metrics = []评估k选择的一种方法是确定平方误差的集合内总和(WSSSE)。 我们正在寻找最小化WSSSE的k值。
def error(point): center = clusters.centers[clusters.predict(point)] denseCenter = DenseVector(numpy.ndarray.tolist(center)) return sqrt(sum([x**2 for x in (DenseVector(point.toArray()) - denseCenter)]))
在您的沙箱中运行以下命令。 处理可能需要一段时间,这就是为什么我们仅使用k的三个值的原因。
for k in k_values:
clusters = Kmeans.train(data_for_cluster, k, maxIterations=4, runs=5, initializationMode="random")
WSSSE = data_for_cluster.map(lambda point: error(point)).reduce(lambda x, y: x + y)
results = (k,WSSSE)
metrics.append(results)
metrics 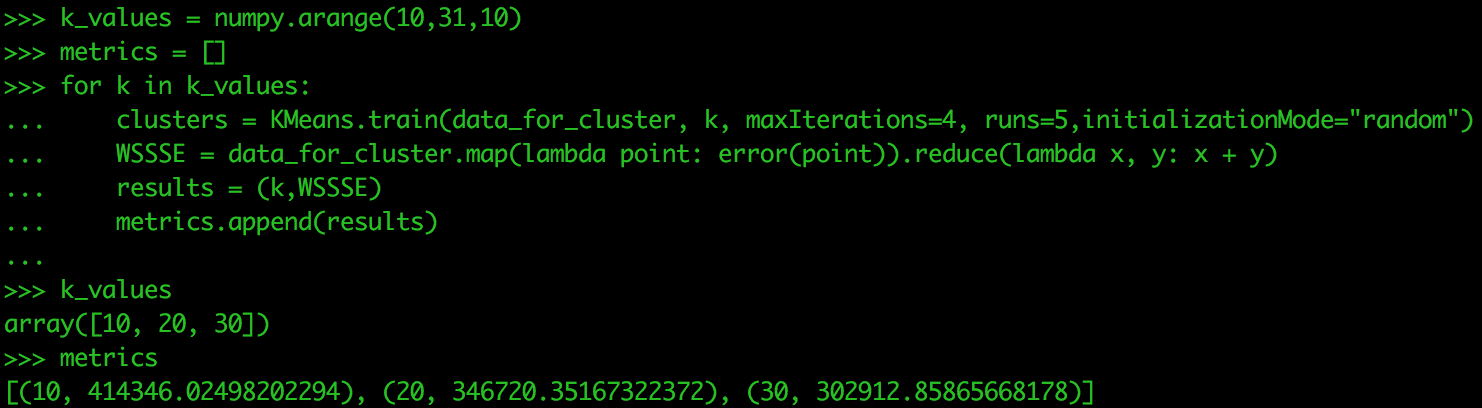
在这种情况下,30是k的最佳值。 当我们有30个集群时,让我们检查每个数据点的集群分配。 下一个测试将针对k的30、35、40值进行测试。k的三个值并不是您在单次运行中最多测试的值,而是仅用于本教程。
k30 = Kmeans.train(data_for_cluster, 30, maxIterations=4, runs=5, initializationMode="random")
cluster_membership = data_for_cluster.map(lambda x: k30.predict(x))
cluster_idx = cluster_membership.zipWithIndex()
cluster_idx.take(20) 
您的结果可能会略有不同。 这是由于当我们第一次开始聚类算法时质心的随机放置。 多次执行此操作,您可以查看数据中的点如何更改其k值或保持不变。
我希望您能够使用PySpark和MapR Sandbox获得一些动手经验。 这是测试代码并进行效率调整的绝佳环境。 此外,在从在本地计算机上使用PySpark过渡到群集时,了解算法的扩展方式也是重要的知识。 MapR平台已集成了Spark,这使开发人员更轻松地将代码移植到应用程序中。 MapR还支持Spark中的流式k均值,而不是我们在本教程中执行的批处理k均值。
翻译自: https://www.javacodegeeks.com/2016/08/tutorial-using-pyspark-mapr-sandbox.html
mapr 和cdh对比