机器学习-李宏毅| 回归演示 | python_李宏毅线性回归python-程序员宅基地
技术标签: python 机器学习 logistic regression
回归的定义
Regression就是指找到一个函数 f u n c t i o n function function,通过输入特征x,输出一个数值 S c a l a r Scalar Scalar
看了李宏毅老师的机器学习课程视频,其中的Regression demo部分,关于预测宝可梦的CP值的应用代码,在jupyter notebook中实现。
现在假设有10个x_data和y_data,x和y之间的关系是y_data=b+w*x_data。b,w都是参数,是需要学习出来的。现在我们来练习用梯度下降找到b和w。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['Simhei'] # 显示中文
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
x_data= [ 338., 333., 328., 207., 226., 25., 179., 60., 208., 606.]
y_data= [ 640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
# ydata =b + w * xdata
x = np.arange(-200, -100, 1) #bias
y = np.arange(-5,5,0.1) #weight
Z = np.zeros((len(x), len(y)))
X, Y = np.meshgrid(x, y)
for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
Z[j][i] = 0
for n in range(len(x_data)):
Z[j][i] = Z[j][i] + (y_data[n] - b - w*x_data[n]) **2
Z[j][i] = Z[j][i] /len(x_data)
# ydata = b + w * xdata
b = -120 # initial b
w = -4 #intial w
lr =0.0000001
iteration = 100000
# Store initial values for plotting.
b_history = [b]
w_history = [w]
#lr_b = 0 #客制化b的learning rate 的初始值
#lr_w = 0 #客制化w的learning rate 的初始值
# Iterations
for i in range(iteration):
b_grad = 0.0
w_grad = 0.0
for n in range(len(x_data)):
b_grad = b_grad - 2.0*(y_data[n] - b - w*x_data[n]) *1.0
w_grad = w_grad - 2.0*(y_data[n] - b - w*x_data[n])*x_data[n]
# lr_b = lr_b + b_grad ** 2 #客制化b的learning rate
# lr_w = lr_w + w_grad ** 2 #客制化w的learning rate
# Update parameters.
b = b - lr * b_grad
w = w - lr * w_grad
# Store parameters for plotting
b_history.append(b)
w_history.append(w)
# plot the figure
plt.contourf(x, y, Z, 50, alpha = 0.5, cmap=plt.get_cmap('jet'))
plt.plot([-188.4], [2.67], 'x', ms = 12, markeredgewidth = 3, color='orange')
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5,5)
plt.xlabel(r'$b$', fontsize=16)
plt.ylabel(r'$w$', fontsize=16)
plt.title("线性回归")
plt.show()
输出结果图:
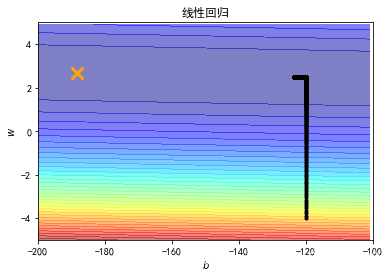
横坐标是b,纵坐标是w,标记×位最优解,显然,在图中我们并没有运行得到最优解,最优解十分的遥远。那么我们就调大learning rate,lr = 0.000001(调大10倍),得到结果如下图。
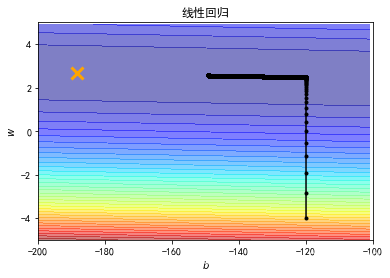
我们再调大learning rate,lr = 0.00001(调大10倍),得到结果如下图。
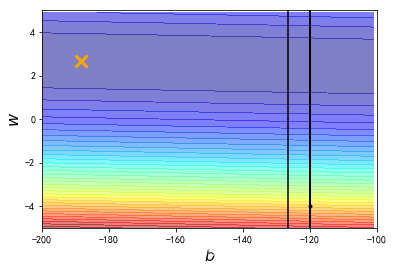
结果发现learning rate太大了,结果很不好。
所以我们给b和w特制化两种learning rate
修改后代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['Simhei'] # 显示中文
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
x_data= [ 338., 333., 328., 207., 226., 25., 179., 60., 208., 606.]
y_data= [ 640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
# ydata =b + w * xdata
x = np.arange(-200, -100, 1) #bias
y = np.arange(-5,5,0.1) #weight
Z = np.zeros((len(x), len(y)))
X, Y = np.meshgrid(x, y)
for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
Z[j][i] = 0
for n in range(len(x_data)):
Z[j][i] = Z[j][i] + (y_data[n] - b - w*x_data[n]) **2
Z[j][i] = Z[j][i] /len(x_data)
# ydata = b + w * xdata
b = -120 # initial b
w = -4 #intial w
lr =1 #learning rate设为1
iteration = 100000
# Store initial values for plotting.
b_history = [b]
w_history = [w]
lr_b = 0 #客制化b的learning rate 的初始值
lr_w = 0 #客制化w的learning rate 的初始值
# Iterations
for i in range(iteration):
b_grad = 0.0
w_grad = 0.0
for n in range(len(x_data)):
b_grad = b_grad - 2.0*(y_data[n] - b - w*x_data[n]) *1.0
w_grad = w_grad - 2.0*(y_data[n] - b - w*x_data[n])*x_data[n]
lr_b = lr_b + b_grad ** 2 #客制化b的learning rate
lr_w = lr_w + w_grad ** 2 #客制化w的learning rate
# Update parameters.
b = b - lr/np.sqrt(lr_b ) * b_grad
w = w - lr/np.sqrt(lr_w ) * w_grad
# Store parameters for plotting
b_history.append(b)
w_history.append(w)
# plot the figure
plt.contourf(x, y, Z, 50, alpha = 0.5, cmap=plt.get_cmap('jet'))
plt.plot([-188.4], [2.67], 'x', ms = 12, markeredgewidth = 3, color='orange')
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5,5)
plt.xlabel(r'$b$', fontsize=16)
plt.ylabel(r'$w$', fontsize=16)
plt.title("线性回归")
plt.show()
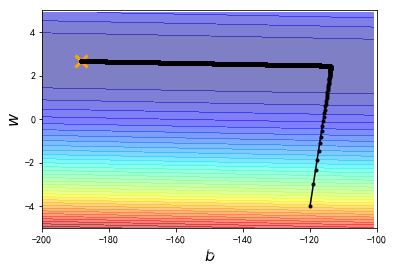
这样有了新的特制化两种learning rate就可以在10w次迭代之内到达最优点了。
智能推荐
LSTM介绍_lstm的定义-程序员宅基地
文章浏览阅读936次。LSTM是RNN的一种。它的出现解决了梯度失真的问题。而且使得RNN的收敛速度比普通的RNN要快上不少。LSTM的名称有些奇特,叫长短时记忆。这个实际反应了这个算法的原理:保持记忆的长短。我们的大脑并不是记忆所有的信息,有短时记忆,也有长时间记忆。LSTM就是利用这个原理来设计的。普通的RNN只是保持了短时的记忆(h),在LSTM中增加了对记忆的处理。这个增加的部分控制的逻辑比较复杂。简单的来说就是通过3个门:遗忘门、输入门和输出门来控制增加的记忆单元。需要注意的是,增加的门都是用来控制记忆单元的。_lstm的定义
计算机科学终审多长时间,一些计算机科学核心期刊的投稿经验-程序员宅基地
文章浏览阅读4.7k次。1. 计算机工程与应用: 评审费为100元,评审期为60-70天左右,布局费为930-1100元. 该杂志为期十年,从雇用到出版大约需要12个月. 有时这取决于运气. 如果幸运的话,大约四个月. 最大的特点是该期刊载有大量论文,相对来说比较好,但每个人都看中此功能,所以就论文数量而言,一定要有创新性,并且要更加重视博士论文. 论文. 可以加快发布速度,但是成本更高. 摘要: 简单.2. 计算机工程..._计算机科学审稿
手机开发实战197——CTS认证测试3_cts refapp-程序员宅基地
文章浏览阅读467次。4、配置和使用CTS4.1、配置CTS1.6及以上版本才能运行CTS。解压ZIP包,编辑android-cts/tools/startcts脚本,修改变量SDK_ROOT来与环境相匹配。例如:SDK_ROOT=/home/myuser/android-sdk-linux_x86-1.6_r1即,指向SDK的根目录。4.2、配置设备下面_cts refapp
完全二叉树的结点数计算_完全二叉树结点数计算公式-程序员宅基地
文章浏览阅读1.6w次,点赞13次,收藏33次。完全二叉树有一个很有趣的性质:结点从1开始编号,层序。那么分每一个结点(编号为i)的左孩子结点是2i,右孩子结点编号是2i+1. 反之,根据孩子结点的编号可以推知父结点的编号:孩子结点编号的下取整。下面是较聪明的应用: 一棵完全二叉树有1001个结点。其中叶结点的个数是:501个。分析:1001个结点,则最后一个结点的编号是1001,那么它的父亲结点编号是500,注意,这个并不一定是倒数第二_完全二叉树结点数计算公式
HTML——表单详解_html表单-程序员宅基地
文章浏览阅读1.3w次,点赞46次,收藏294次。HTML——表单的详细解析_html表单
快解析的ERP远程管理解决方案_erp远程交付-程序员宅基地
文章浏览阅读289次。快解析有24小时不间断技术服务支持,用户遇到任何技术商问题都可以随时得到帮助,而这项专业的1V1定制服务是行业内独有的,它的各项功能在同类型的品牌产品中是极具性价比的。另外,要特别一提的是,随着企业对人力资源管理重视的加强,已经有越来越多的 ERP 厂商将人力资源管理纳入了 ERP 系统的一个重要组成部分。ERP是指建立在信息技术基础上,通过先进管理思想和方法,对企业内部资源和外部资源进行整合,通过标准化的数据和业务操作流程,把企业的人、财、物等进行紧密集成,最终实现资源优化配置和业务流程优化目的的方法。_erp远程交付
随便推点
智能经济时代,百度智能云在升级计算产业的竞争门槛-程序员宅基地
文章浏览阅读1.1k次。文 | 曾响铃来源 | 科技向令说(xiangling0815)“数学是自然科学中最基础的学科,计算随处可见、可用。”依稀记得,在学生时代,数学老师开课必会强调那么一句。事实上,回顾我们日常生活的场景,也确实如此。数学计算与我们息息相关,乃至于我们有时候甚至忽视了它的存在。在互联网高度发达的今天,计算产业的处境也大抵如此。基本上,我们的每一个网络操作,都离不开数字计算的支持。但是,对于计算产业的认知,大众又往往会不可避免的将其忽视。然而,对于科技企业而言,却是刚好相反,计算产业是最不能被
Chrome插件抓取:解锁无限可能_chrome 解锁csdn-程序员宅基地
文章浏览阅读86次。1.什么是Chrome插件抓取? Chrome插件抓取是指利用Chrome浏览器的扩展程序(插件)功能,实现对网页内容的自动化获取和处理的技术。通过编写和安装适当的插件,用户可以方便地从网页中提取所需的信息,如文字、图片、链接等。2. Chrome插件抓取有哪些应用场景? -_chrome 解锁csdn
Windows 技术篇 - windows日期和时间设置里没有Internet 时间页签原因和解决方法_“internet时间”选项卡 没有-程序员宅基地
文章浏览阅读2.4w次,点赞5次,收藏10次。因为工作关系设置了一下系统时间,然后想用网络获取最新的时间来自动更正下,然后发现没有这个功能…,百度后发现其实是有一个Internet时间页签的,在这个页签里才可以设置,那为什么我这里没有呢?因为我的计算机加入了域,加入了域就不能用这个功能了。如何查看自己的计算机有没有加入域呢?在计算机属性里的系统属性里就能看到_“internet时间”选项卡 没有
opencv warpAffine()函数详解 -- 图像旋转与平移-程序员宅基地
文章浏览阅读4.6w次,点赞15次,收藏91次。简述仿射变换是二维坐标间的线性变换,故而变换后的图像仍然具有原图的一些性质,包括“平直性”以及“平行性”,常用于图像翻转(Flip)、旋转(Rotations)、平移(Translations)、缩放(Scale operations)等,然而其实现的函数就是cv::warpAffine()下面我们将对warpAffine()函数进行介绍,并且实现图像的旋转和平移。warpAffine..._warpaffine
电池的寿命-程序员宅基地
文章浏览阅读317次。电池的寿命链接:http://ybt.ssoier.cn:8088/problem_show.php?pid=1229时间限制: 1000 ms 内存限制: 65536 KB【题目描述】小S新买了一个掌上游戏机,这个游戏机由两节5号电池供电。为了保证能够长时间玩游戏,他买了很多5号电池,这些电池的生产商不同,质量也有差异,因而使用寿命也有所不同,有的能使用5个小时,..._电池的寿命csdn
Android studio64新建APP项目时,报错 junit:junit:4.12_testimplementation 'junit:junit:4.12' 指定源-程序员宅基地
文章浏览阅读4.4k次。大家都是要求注释掉,但不想这样,看了很多博客,快绝望的时候,用这个办法成功了文件:E:\android\app (工程文件目录) 下面的 build.gradle 文件 在这个文件中加入最后划线3行,保存即可,然后再retryapply plugin: 'com.android.application'android { compileSdkVersion 26 ..._testimplementation 'junit:junit:4.12' 指定源