【Java项目】1000w数据量的表如何做到快速的关键字检索?_java千万数据量查询-程序员宅基地
技术标签: 算法 java elasticsearch mysql 数据结构
需求
ok,这个需求是我提的,然后我问了我的一位杭州的朋友,然后我们最后一起敲定这个方法。
我的项目有一个根据关键字进行商品名称的搜索功能,用户输入部分关键字之后,那么就需要查询出这个关键字对应的所有商品。假设我现在有1000w行记录,并且不能使用ES做倒排索引解决这个问题。
那么你会如何解决这个问题?
我们先分析,如果我们使用数据库提供的 % 这种模糊匹配机制,首先我们的索引会失效,并且这基本意味着会走全表扫描,对于1000w行的记录如果我们走全表扫描,那么效率可想而知。
并且如果使用分库分表技术,那么维护的难度也大了,不论是业务代码还是数据库都得跟着修改,非常麻烦,那么如何解决这个问题?
解决思路
基本设计
大概流程如下:
我们可以自己实现一个倒排索引的算法,用户创建商品之后,将商品名称进行细粒度的分词,比如输入 “Java技术指导”,那么分词为“Java”,“技术”,“指导”。粒度越细越好。
可以看到此时我们得到的是一个数组,对吧。
然后我们创建两张表,一张表是商品表,存储商品的完整信息。
另一张表是倒排索引表,里面是什么内容?
包括id,word,goods_ids
这里的word就是我们的分词数据,goods_ids也就是我们这个关键字下面对应的所有商品id。
上面我们对一个字符串进行分词后得到的,其实是一个数组对吧,那么我们此时就可以向数据库中插入这三行的数据了,大概格式如下。
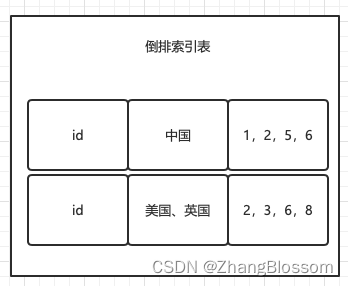
然后我们得到goods_ids是一个集合,我们在使用这个集合去商品表中查询出所有在这个集合中的记录即可。
查询流程
那么我现在大概简述一下一个数据的查询流程:
我们查询一个商品,通过关键字的方式,经过倒排索引的算法得到word值,去数据库中查询是否有这个word值,如果有,那么直接查询出来这个关键字对应的goods_ids这一段字符串,我们对字符串进行处理得到字符串包含的所有id,然后用这些id去商品表查询数据即可。
ok,那么如果有插入和修改,删除等操作怎么办呢?
插入流程
先说插入流程,一样的,当我们要插入一个数据的时候,我们先得到这个商品对应的word,也就是我们取出商品的name商品名称字段,然后对这个name字段进行分词算法,得到细粒度的分词。之后,我们我们将这个记录插入到商品表中,得到插入的id之后,返回id成功后,我们在将分词得到的数组,配合上我们得到的商品id,循环的去插入到这个分词表中,如果分词表中出现了重复的word,那么我们做的是取出goods_ids这个字段,然后再字段尾巴上补上这个id,而如果不存在这个字段,则新建一行记录,word为当前分词,goods_ids直接为刚才返回的id。
修改流程
修改流程其实已经和上面的流程差不多了,依旧是经过分词,然后去精确判断分词对应的行,然后修改对应的ids字段即可。
当然,其实没有必要这样子,因为会让代码更加复杂,我们只需要拿到所有的id之后,去商品表中判断的时候判断删除标志位即可,也就是使用逻辑删除即可。
删除流程
删除流程也差不多,只不过我们如何删除对应的goods_ids中的哪一个id呢?
我们首先取出goods_ids这个字段值,然后通过 “ ,”分隔符得到每一个id,然后我们删除指定的id即可,当然,为了加快速度,我们的商品表中的id是自增的,所以这样子就能尽可能快的删除指定数据了。
优化思路
其实,顺着上面的思路,我忽然想到。其实我们的数据库其实作用就是为了保存一个分词,然后分词后面对应的是一堆的id,这些id是字符串,也就是我们取出来之后还得先经过处理才能得到真正可用的id。
我想的是,上面的结构其实很简单,就是一个 word—goods_ids的结构,这种结构用Redis肯定可以呀对吧。
但是如果你直接K-V结构或者hash,那么结构其实相当于就是把磁盘空间变成了内存空间,我觉得也没有多好。当然,处理起来可能比刚才那个转字符串完毕之后,然后再查询来的快。
然后我就我想到了我常用的Bitmap结构,0101啊,对吧,我只需要把如果说存在这个id,那么我把对应的位置置1即可,这样子增删改的速度全都加快了不是嘛。
当然,有一个缺点就是,查询Redis是有网络开销的。
但是我觉得如果使用Redis的bitmap,那么由于增删改查的速度都更快了,并且也不需要字符串的处理了,可能效果更优。
当然,也可以直接使用Java提供的BitSet。
但是我实现了一下发现,BitSet的缺点在于,我不能很快的得到到底那些索引位为1,我需要不断的通过位运算的方式才能得到为1的位。
Redis的问题在于,如果我使用RedisTemplate然后去获取bitmap结构整个结构,会报错,就导致我依旧可能需要去循环遍历每个可能位1的位。
代码实现
代码单纯只是为了验证这种方式的可行性,对于数据库字段的设计,以及其他性能方面的考虑,代码方面的优化都还没有做。大致代码如下:
POJO类
@Data
@TableName("goods")
@AllArgsConstructor
@NoArgsConstructor
public class Goods implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
private String goodName;
@TableLogic(value = "false", delval = "true")
private boolean deleted;
}
@Data
@TableName("word_goods")
public class WordGoods implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
private String goodsId;
private String word;
}
Service代码
package ebuy.campus.deal.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import ebuy.campus.deal.mapper.GoodsMapper;
import ebuy.campus.deal.mapper.WordGoodsMapper;
import ebuy.campus.deal.model.pojo.Goods;
import ebuy.campus.deal.model.pojo.WordGoods;
import ebuy.campus.deal.service.GoodsService;
import ebuy.campus.framework.core.constant.DealConstant;
import ebuy.campus.framework.core.util.HanLPUtil;
import ebuy.campus.framework.redis.service.RedisService;
import org.jetbrains.annotations.NotNull;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.io.IOException;
import java.util.*;
/**
* @author: 张锦标
* @date: 2023/6/13 15:26
* GoodsServiceImpl类
*/
@Service
public class GoodsServiceImpl implements GoodsService {
@Autowired
private GoodsMapper goodsMapper;
@Autowired
private WordGoodsMapper wordGoodsMapper;
@Autowired
private RedisService redisService;
@Transactional
public boolean add(Goods goods) {
try {
//分词操作
List<String> texts = HanLPUtil.parse(goods.getGoodName());
//取出数据库中包含该分词的所有行
LambdaQueryWrapper<WordGoods> lqw = new LambdaQueryWrapper<>();
lqw.in(WordGoods::getWord, texts.toArray());
List<WordGoods> wordGoods = wordGoodsMapper.selectList(lqw);
//得到数据库中已有的所有分词
List<String> words = wordGoods.stream().map(x -> x.getWord()).toList();
//得到数据库中没有的分词
List<String> newWords = texts.stream().dropWhile(x -> words.contains(x)).toList();
//插入当前新数据
int success = goodsMapper.insert(goods);
if (success <= 0) {
return false;
}
Long id = goods.getId();
;
//修改数据库已有分词的数据
wordGoods.stream().forEach(x -> {
x.setGoodsId(x.getGoodsId() + "," + id);
wordGoodsMapper.updateById(x);
String goodsId = x.getGoodsId();
//保存到redis
for (String s : goodsId.split(",")) {
redisService.setBit(DealConstant.DEAL_SEARCH_KEY + x.getWord(), Long.valueOf(s), true);
}
});
//插入没有的分词
newWords.stream().forEach(word -> {
WordGoods x = new WordGoods();
x.setGoodsId(String.valueOf(id));
x.setWord(word);
wordGoodsMapper.insert(x);
//保存到redis
redisService.setBit(DealConstant.DEAL_SEARCH_KEY + x.getWord(), id, true);
});
} catch (IOException e) {
throw new RuntimeException(e);
}
return true;
}
@Override
public List<Goods> listByWord(String word) {
//分词操作
List<String> texts = null;
Set<Long> ids = new HashSet<>();
try {
texts = HanLPUtil.parse(word);
for (String x : texts) {
List<Long> bitsIndexes = redisService
.getBitIndexesByKey(DealConstant.DEAL_SEARCH_KEY + x);
ids.addAll(bitsIndexes);
}
//redis里面没有存储id
if (ids.isEmpty()) {
//取出数据库中包含该分词的所有行
LambdaQueryWrapper<WordGoods> lqw = new LambdaQueryWrapper<>();
lqw.in(WordGoods::getWord, texts.toArray());
List<WordGoods> wordGoods = wordGoodsMapper.selectList(lqw);
ids = getIds(wordGoods);
LambdaQueryWrapper<Goods> lqw1 = new LambdaQueryWrapper<>();
lqw1.in(!ids.isEmpty(), Goods::getId, ids);
List<Goods> goodsList = goodsMapper.selectList(lqw1);
return goodsList;
} else {
//redis里面有id了,直接查询
LambdaQueryWrapper<Goods> lqw1 = new LambdaQueryWrapper<>();
lqw1.in(!ids.isEmpty(), Goods::getId, ids);
List<Goods> goodsList = goodsMapper.selectList(lqw1);
return goodsList;
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@NotNull
private Set<Long> getIds(List<WordGoods> wordGoods) {
Set<Long> ids = new HashSet<>();
for (WordGoods wordGood : wordGoods) {
String goodsId = wordGood.getGoodsId();
String[] split = goodsId.split(",");
for (int i = 0; i < split.length; i++) {
ids.add(Long.valueOf(split[i]));
}
}
return ids;
}
}
智能推荐
settext 下划线_Android TextView 添加下划线的几种方式-程序员宅基地
文章浏览阅读748次。总结起来大概有5种做法:将要处理的文字写到一个资源文件,如string.xml(使用html用法格式化)当文字中出现URL、E-mail、电话号码等的时候,可以将TextView的android:autoLink属性设置为相应的的值,如果是所有的类型都出来就是**android:autoLink="all",当然也可以在java代码里 做,textView01.setAutoLinkMask(Li..._qaction::settext 无法添加下划线
TableStore时序数据存储 - 架构篇_tablestore 时间类型处理-程序员宅基地
文章浏览阅读6.3k次,点赞2次,收藏10次。摘要: 背景 随着近几年物联网的发展,时序数据迎来了一个不小的爆发。从DB-Engines上近两年的数据库类型增长趋势来看,时序数据库的增长是非常迅猛的。在去年我花了比较长的时间去了解了一些开源时序数据库,写了一个系列的文章(综述、HBase系、Cassandra系、InfluxDB、Prometheus),感兴趣的可以浏览。背景随着近几年物联网的发展,时序数据迎来了一个不小的爆发。从DB..._tablestore 时间类型处理
Ubuntu20.04下成功运行VINS-mono_uabntu20.04安装vins-mono-程序员宅基地
文章浏览阅读5.7k次,点赞8次,收藏49次。可以编译成功但是运行时段错误查找原因应该是ROS noetic版本中自带的OpenCV4和VINS-mono中需要使用的OpenCV3冲突的问题。为了便于查找问题,我只先编译feature_tracker包。解决思路历程:o想着把OpenCV4相关的库移除掉,但是发现编译feature_tracker的时候仍然会关联到Opencv4的库,查找原因是因为cv_bridge是依赖opencv4的,这样导致同时使用了opencv3和opencv4,因此运行出现段错误。oo进一步想着(1)把vins-mon_uabntu20.04安装vins-mono
TMS320C6748_EMIF时钟配置_tms 6748-程序员宅基地
文章浏览阅读3.6k次,点赞3次,收藏12次。创龙TL6748开发板中,EMIFA模块使用默认的PLL0_SYSCLK3时钟,使用AISgen for D800K008工具加载C6748配置文件C6748AISgen_456M_config(Configuration files,在TL_TMS6748/images文件夹下),由图可以看到DIV3等于4,注意这里的DIV3就是实际的分频值(x),而不是写入相应PLL寄存器的值(x-1)。_tms 6748
eigen稀疏矩阵拼接(基于块操作的二维拼接)的思考-程序员宅基地
文章浏览阅读5.9k次,点赞4次,收藏13次。转载请说明出处:eigen稀疏矩阵拼接(块操作)eigen稀疏矩阵拼接(块操作)关于稀疏矩阵的块操作:参考官方链接 However, for performance reasons, writing to a sub-sparse-matrix is much more limited, and currently only contiguous sets of columns..._稀疏矩阵拼接
基于Capon和信号子空间的变形算法实现波束形成附matlab代码-程序员宅基地
文章浏览阅读946次,点赞19次,收藏19次。波束形成是天线阵列信号处理中的一项关键技术,它通过对来自不同方向的信号进行加权求和,来增强特定方向的信号并抑制其他方向的干扰。本文介绍了两种基于 Capon 和信号子空间的变形算法,即最小方差无失真响应 (MVDR) 算法和最小范数算法,用于实现波束形成。这些算法通过优化波束形成权重向量,来最小化波束形成输出的方差或范数,从而提高波束形成性能。引言波束形成在雷达、声纳、通信和医学成像等众多应用中至关重要。它可以增强目标信号,抑制干扰和噪声,提高系统性能。
随便推点
Ubuntu好用的软件推荐_ubuntu开发推荐软件-程序员宅基地
文章浏览阅读3.4w次。转自:http://www.linuxidc.com/Linux/2017-07/145335.htm使用Ubuntu开发已经有些时间了。写下这篇文章,希望记录下这一年的小小总结。使用Linux开发有很多坑,同时也有很多有趣的东西,可以编写一些自动化脚本,添加定时器,例如下班定时关机等自动化脚本,同时对于服务器不太了解的朋友,建议也可以拿台Linux来实践下,同时Ubuntu在Androi_ubuntu开发推荐软件
Nginx反向代理获取客户端真实IP_nginx获取到的是交换机的ip-程序员宅基地
文章浏览阅读2.2k次。一,问题 nginx反向代理后,在应用中取得的ip都是反向代理服务器的ip,取得的域名也是反向代理配置的url的域名,解决该问题,需要在nginx反向代理配置中添加一些配置信息,目的将客户端的真实ip和域名传递到应用程序中。二,解决 Nginx服务器增加转发配置 proxy_set_header Host $host;_nginx获取到的是交换机的ip
Wireshark TCP数据包跟踪 还原图片 WinHex应用_wireshark抓包还原图片-程序员宅基地
文章浏览阅读1.4k次。Wireshark TCP数据包跟踪 还原图片 WinHex简单应用 _wireshark抓包还原图片
Win8蓝屏(WHEA_UNCORRECTABLE_ERROR)-程序员宅基地
文章浏览阅读1.5k次。Win8下安装VS2012时,蓝屏,报错WHEA_UNCORRECTABLE_ERROR(P.S.新的BSOD挺有创意":("),Google之,发现[via]需要BIOS中禁用Intel C-State,有严重Bug的嫌疑哦原因有空再看看..._win8.1 whea_uncorrectable_error蓝屏代码
案例课1——科大讯飞_科大讯飞培训案例-程序员宅基地
文章浏览阅读919次,点赞21次,收藏22次。科大讯飞是一家专业从事智能语音及语音技术研究、软件及芯片产品开发、语音信息服务的软件企业,语音技术实现了人机语音交互,使人与机器之间沟通变得像人与人沟通一样简单。语音技术主要包括语音合成和语音识别两项关键技术。此外,语音技术还包括语音编码、音色转换、口语评测、语音消噪和增强等技术,有着广阔的应用。_科大讯飞培训案例
perl下载与安装教程【工具使用】-程序员宅基地
文章浏览阅读4.7k次。Perl是一个高阶程式语言,由 Larry Wall和其他许多人所写,融合了许多语言的特性。它主要是由无所不在的 C语言,其次由 sed、awk,UNIX shell 和至少十数种其他的工具和语言所演化而来。Perl对 process、档案,和文字有很强的处理、变换能力,ActivePerl是一个perl脚本解释器。其包含了包括有 Perl for Win32、Perl for ISAPI、PerlScript、Perl。_perl下载