Prophet: forecasting at scale——Prophet:大规模预测_forecasting at scale翻译-程序员宅基地
技术标签: 数据科学 机器学习 prophet 人工智能 预测算法
 Facebook开源了一个预测工具,一个可用Python语言编写的预测工具。例如,像Facebook这样的大型组织必须进行容量规划,以便有效地分配稀缺资源和目标设置,以便度量相对于基准的性能。对机器或大多数分析师来说,做出高质量的预测都不是一个容易的问题。在编制各类业务预测时,我们发现两个主要的主题:
Facebook开源了一个预测工具,一个可用Python语言编写的预测工具。例如,像Facebook这样的大型组织必须进行容量规划,以便有效地分配稀缺资源和目标设置,以便度量相对于基准的性能。对机器或大多数分析师来说,做出高质量的预测都不是一个容易的问题。在编制各类业务预测时,我们发现两个主要的主题:
- 完全自动化的预测技术可能很脆弱,而且它们往往过于死板,无法纳入有用的假设或启发
- 能够做出高质量预测的分析师非常罕见,因为预测是一种需要大量经验的专业数据科学技能
这些主题的结果是,对高质量预测的需求往往远远超过分析师做出预测的速度。这一观察结果是我们工作的动机建筑先知:我们想让专家和非专家更容易做出高质量的预测,以跟上需求
“规模”所包含的典型考虑因素(计算和存储)对预测的影响并不大。我们发现预测大量时间序列的计算和基础设施问题相对简单——通常这些拟合过程并行化非常容易,而且预测不难存储在关系数据库(如MySQL)或数据仓库(如Hive)中。
我们在实践中所观察到的规模问题涉及预测问题的多样性所带来的复杂性,以及一旦预测产生,人们对大量预测建立信任。prophet是提高Facebook创造大量可靠预测的关键因素,这些预测可用于决策,甚至用于产品功能。
prophet亮点
并不是所有的预测问题都能用同样的方法解决。Prophet针对我们在Facebook遇到的业务预测任务进行了优化,这些任务通常具有以下任何特征:
- 每小时、每天或每周进行至少几个月(最好一年)的观察
- 强烈的多样性“人类规模——季节性:一周中的一天和一年中的时间
- 提前知道的不定期的重要节日(如超级碗)
- 合理数量的缺失观测值或较大的异常值
- 历史趋势的变化,例如由于产品发布或日志记录的变化
- 趋势是非线性增长曲线,趋势达到自然极限或饱和
我们发现,Prophet的默认设置可以生成与熟练预测者一样准确的预测,所需的工作量要少得多。使用Prophet,如果预测不令人满意,您就不会被完全自动的过程的结果所困——没有接受过时间序列方法培训的分析师可以使用各种易于解释的参数来改进或调整预测。我们发现,通过将针对特殊情况的自动预测与循环分析预测相结合,可以覆盖各种各样的业务用例。下面的图
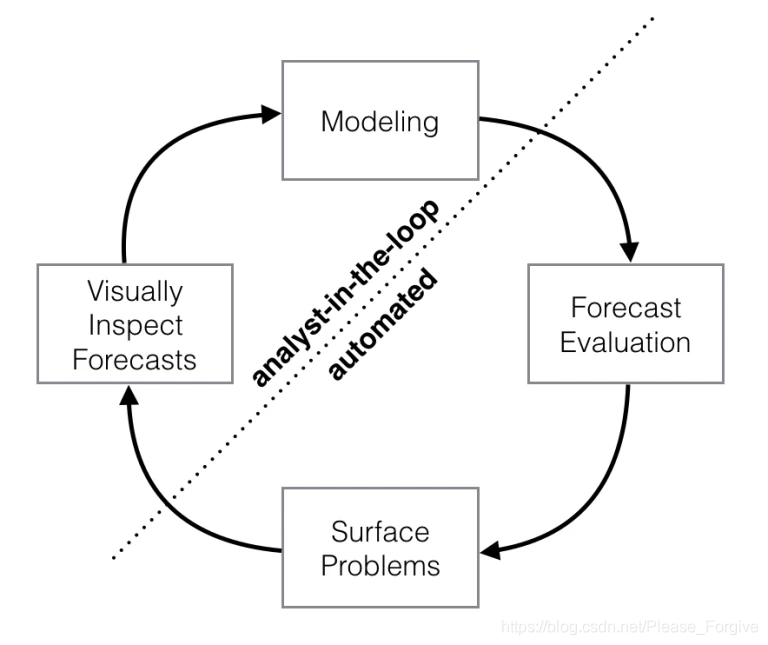
对于预测过程的建模阶段,目前可用的工具数量有限。Rob Hyndman在R中出色的预测包可能是最受欢迎的选择,谷歌和Twitter都发布了具有更具体的时间序列功能的包——分别是因果影响和异常检测。据我们所知,在Python中很少有用于预测的开源软件包
我们在很多情况下经常使用Prophet作为预测包的替代品,主要有两个优点:
- prophet使创建一个合理、准确的预测变得更加直接。预测包包括许多不同的预测技术(ARIMA、指数平滑等),每种技术都有自己的优点、缺点和调优参数。我们发现,选择错误的模型或参数往往会产生糟糕的结果,即使是经验丰富的分析师,也不太可能在给定这一系列选择的情况下有效地选择正确的模型和参数。
- prophet的预测是可定制的方式,是直观的非专业人士。季节性的平滑参数允许您调整与历史周期的匹配程度,趋势的平滑参数允许您调整跟踪历史趋势变化的力度。对于增长曲线,您可以手动指定“容量”或增长曲线的上限,从而允许您输入关于预测将如何增长(或下降)的预先信息。最后,您可以指定不定期的假日来建模,比如超级碗(Super Bowl)、感恩节(thanksgiving giv)的日期
prophet如何工作
Prophet过程的核心是一个加性回归模型,包含四个主要部分:
- 段线性或逻辑增长曲线的趋势。Prophet通过从数据中选择变更点来自动检测趋势的变化。
- 用傅里叶级数建模的年季节性成分。
- 使用虚拟变量的每周季节性成分。
- 用户提供的重要假期列表。
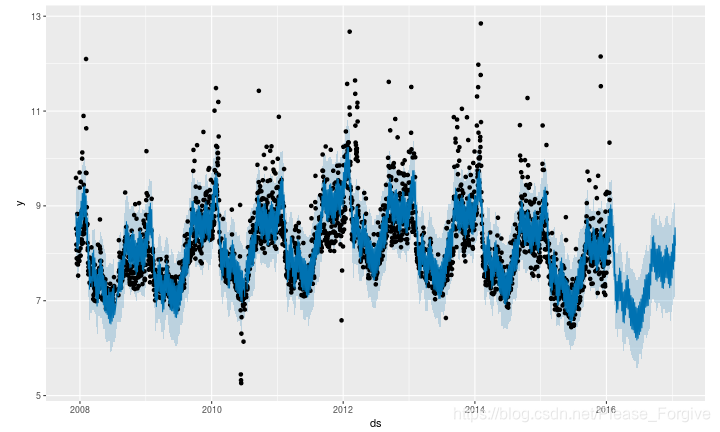
例如,这里有一个典型的预测:我们使用wikirend包下载的Peyton Manning的Wikipedia页面的日志级页面视图。由于佩顿·曼宁是一名美国足球运动员,所以你可以看到,每年的季节性发挥着重要的作用,而每周的周期性也很明显。最后你看到某些事件(比如他出现在季后赛)也可能被模仿。
Prophet将提供一个组件图,图形化地描述它所适合的模型:
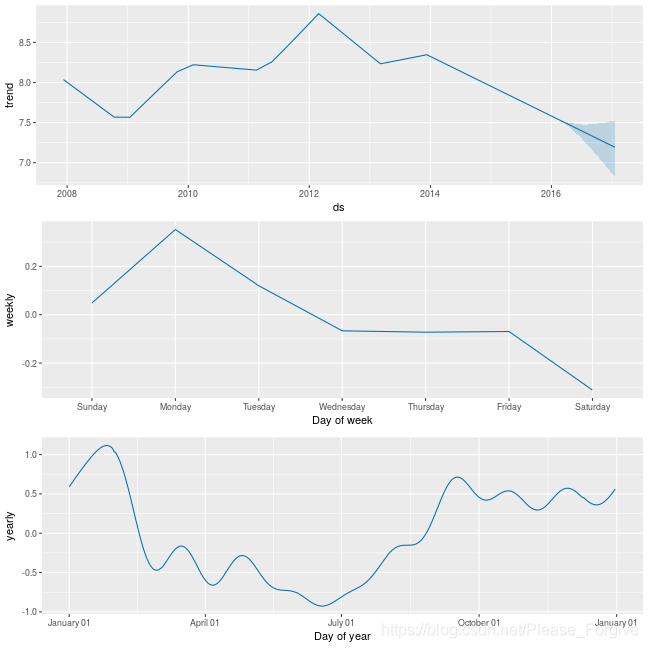
这张图更清楚地显示了与浏览Peyton Manning的页面(足球赛季和季后赛)相关的年度季节性,以及每周的季节性:更多的访问发生在比赛的当天和之后(周日和周一)。您还可以注意到趋势组件的向下调整,因为他最近退休了。
prophet的一个重要观点是,通过非常灵活地对趋势分量进行更好的拟合,我们可以更准确地对季节性进行建模,从而得到更准确的预测结果。我们更喜欢使用非常灵活的回归模型(有点像曲线拟合),而不是传统的时间序列模型,因为它为我们提供了更多的建模灵活性,使模型更容易拟合,并更优雅地处理丢失的数据或异常值。
默认情况下,Prophet将通过模拟时间序列的未来趋势变化,为趋势组件提供不确定性区间。如果您希望对未来季节性或假日效应的不确定性建模,您可以运行几百次HMC迭代(这需要几分钟),并且您的预测将包括季节不确定性估计。
我们使用Stan对Prophet模型进行了拟合,并用Stan的概率编程语言实现了Prophet过程的核心。Stan对参数进行MAP优化的速度非常快(<1秒),为我们提供了使用哈密顿蒙特卡罗算法估计参数不确定性的选项,并允许我们跨多种接口语言重用拟合过程。目前,我们在Python和r中都提供了Prophet的实现
如何使用prophet
使用Prophet最简单的方法是从PyPI (Python)或CRAN 安装包。您可以阅读我们的快速入门指南并深入了解我们的综合文档,如果您正在寻找一个有趣的时间序列数据来源,我们建议您尝试wikirend包,它将下载Wikipedia页面上的历史页面视图。
帮助我们改善prophet
有两种主要的方法来帮助我们改善prophet。首先,你可以自己试试,告诉我们你的结果。我们总是在寻找更多的用例,以便理解Prophet什么时候表现得好,什么时候表现得不好。其次,还有很多特性需要构建!,我们欢迎带有bug修复和新特性的拉请求。看看如何作出贡献,我们期待与社区的参与,使先知更广泛地有用。
PS:本文翻译是来自Facebook的关于prophetresearch,目的是为了方便自己阅读。
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象