C++ | 手把手带你从C语言到C++-程序员宅基地
目录
前言
在正式学习C++之前,我们首先得认识了解我们学习的C++创始人,Bjarne Stroustrup(本贾尼·斯特劳斯特卢普),本贾尼博士在使用C语言的过程中发现了C语言有许多方面上使用的不便,于是在C语言的基础上创立了C++,也就是说,C++文件中可以编译C语言代码,而C语言文件中也可以编译C++代码,可以理解为C++继承了许多C语言的特点。
一、C++关键字
与C语言相比,C++新增了一些关键字,从C语言的32个关键字到C++的63个关键字,我们之前也了解过关键字的概念,此处就不详细讲解,大概列出关键字,以供参考,具体每个关键字在后面的学习中慢慢了解;

二、命名空间
1、命名空间的引入
我们的C++祖师爷本贾尼博士在使用C语言的过程中,发现了我们在定义变量名或者函数名的时候经常会与库函数重名,比如如下代码;
#include <stdio.h>
int main()
{
int rand = 10;
printf("%d\n", rand);
return 0;
}在编写C语言代码时,我们定义一个名叫rand的变量,但是库函数中也有一个叫rand的函数名,因此,在编译以上代码时,会发生编译错误。在项目工程的开发中,经常是以多人分工完成同一个项目,最后将所有人的项目代码总和,实现项目工程,而在总和过程中,经常会发生同名的情况,因此我们的祖师爷本贾尼在设计C++的时候,提出了命名空间这一该概念。
2、命名空间的概念
为了防止多个库将名字都放在全局命名空间(全局作用域)内引起的命名空间污染,命名空间提供了可控的机制,将全局命名空间进行了分割,其中每个命名空间都是一个作用域。
3、命名空间的定义
命名空间的定义有关键字+命名空间名+{}组成,具体定义如下;
namespace zhangsan
{
//声明或定义(命名空间成员)
int a;
char c;
void Swap(int* p1, int* p2);
}以上代码定义了一个名叫zhangsan的命名空间,该命令空间有三个成员,分别声明了一个整型a,一个字符型c和一个函数Swap;
注意:命名空间不可定义在函数和类的内部
4、命名空间的性质
(1) 可以不连续性
所谓可以不连续性也就是命名空间不必定义在同一块空间,我可以在这个文件定义zhangsan这个名字的命名空间,也可以在别的文件定义zhangsan这个名字的命名空间,编译器最后会将这些同名的命名空间合并成一个命名空间。
(2)可嵌套性
命名空间是可嵌套的,也就是我们平时说的套娃 ,具体如下代码;
namespace stu
{
namespace zhangsan
{
int a;
}
namespace lisi
{
int a;
}
}以上代码在全局作用域内定义了一个叫stu的命名空间,该命名空间里定义了两个子命名空间,分别为zhangsan和lisi,这两个命名空间分别有自己的成员;
5、命名空间的使用
(1)using声明
using声明语句一次只引入命名空间的一个成员
格式: using 命名空间名 :: 引入成员名
//std为标准库的命名空间名
//cout为其中的一个成员名
using std::cout;
以上代码意思可理解为将命名空间名为std中的成员cout引入全局命名空间(全局作用域)中来。
注:其中::(双冒号)为域操作符;
//引入标准库
#include <iostream>
//using声明
using std::cout;
using std::endl;
int main()
{
cout << "hello world" << endl;
return 0;
}以上代码段首先引入了iostream标准库,暂时可将其理解为C语言中引入stdio库一样的作用,std为标准库中变量存在的命名空间的名字,我们接着通过using声明将命名空间名为std中的cout(输出对象)和endl(换行符)引入到全局命名空间(全局作用域)中,所以接下来我们在局部作用域main函数中使用了cout和endl。
注:cout暂时可理解为输出的一种手段,类似C语言中的printf;
(2)using指示
using指示语句一次可引入一个命名空间的所有成员
格式:using namespace 命名空间名
using namespace std;
以上代码将命名空间名为std的所有成员都引入到了全局作用域(全局命名空间)中;
阅读以下代码,让你对命名空间有更深刻的认识;
#include <iostream>
namespace A
{
int i = 0;
int j = 1;
int k = 2;
}
int j = 15;
int main()
{
//将命名空间A中所有成员引入全局作用域(全局命名空间)中
using namespace A;
i++; //对命名空间i++
j++; // 错误 因为这里无法确定是对刚引入全局作用域中j++,还是对原本全局作用域中的j++
A::j++; // 正确 对命名空间A的那个j++
::j++; // 正确 对原本全局作用域中的j++
int k = 0;
k++; // 对上一行的k++
A::k++; // 对命名空间A中的k++
return 0;
}在以上变量中,尤其是 j 变量更能让你深刻体会到 j 变量是确确实实的被引入全局作用域(全局命名空间)中,当 j 变量被引入全局作用域中,因为原本全局作用域有一个 j 变量, 因此在我们使用 j 变量时应该指出我们使用的是那个 j 变量,确保程序的严谨性;
注:其实在我们平常写代码的过程中还有第三种引入方法,如下
#includ <iostream>
int main()
{
//在我们使用的变量或函数名前加域作用符,并指定其来自的命名空间
std::cout << "hello C++" << std::endl;
}以上代码使用的cout和endl是来自于std命名空间,我们可以在其语句的每个变量、对象或函数名前指定其命名空间来使用它;
三、C++的输入与输出
一提到C++的输入与输出,我们就不得不提cout和cin了,本文讲解此处的目的主要是浅浅的教大家学会用这两个对象,没错这两个并不是函数,而是两个对象,此处不做深入讲解,此文主要带着大家入门C++。
1、cout
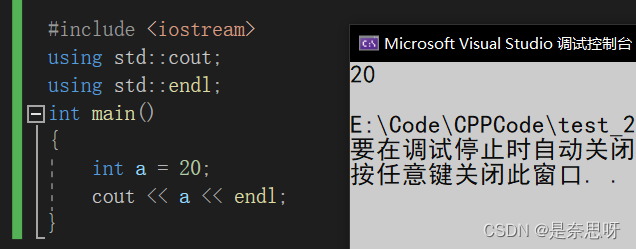
该对象用于输出打印,功能类似于C语言中的printf,使用前需引入头文件 iostream,用法如下;
#include <iostream>
using std::cout;
using std::endl;
int main()
{
int a = 20;
cout << a << endl;
return 0;
}既然要使用iostream里的成员,就必须将其引入作用域内,iostream的命名空间为std,因此使用前我们通过using声明引入了cout对象和endl(换行符),接着我们用流插入将a变量插入到cout对象中就可打印出结果;
注:
- cout是一个全局对象,并不是函数,使用前需包含头文件iostream,以及声明其所在命名空间std;
- <<是流插入运算符,目前无需对其了解;
- cout会自动识别对象类型,因此无需提供类型参数;
2、cin
cin为C++的输入对象,功能类似于C语言中的scanf函数,使用前也许引用头文件iostream,其命名空间名为std,其具体用法如下;
#include <iostream>
using std::cin;
int main()
{
int a = 0;
cin >> a;
return 0;
}通过以上代码,我们可以通过输入,对a进行赋值,cin的特点于cout类似,其中特别强调的是>>为流提取运算符;
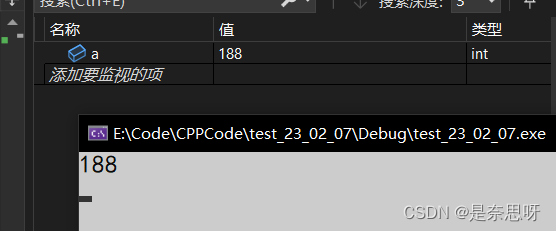
通过调试我们确实发现a的值被我们修改为了188;
四、缺省参数 (默认实参)
1、缺省参数的概念
相比于C,缺省参数是C++特有的一种参数,该参数可以在函数调用函数时不传实参,而有一个默认的实参
#include <iostream>
using namespace std;
int func(int a = 1)
{
return a;
}
int main()
{
cout << func() << endl; // 输出1
cout << func(10) << endl; // 输出10
return 0;
}在上面代码中,当我们不给func函数传参时,a的默认值便为1,传参时,传过去的实参将会代替缺省参数,此时a便为10;
2、缺省参数的分类
(1) 全缺省参数
void func1(int a = 1, int b = 2, int c = 3)
{
cout << "a" << a << endl;
cout << "b" << b << endl;
cout << "c" << c << endl;
}(2)半缺省参数
void func2(int a, int b = 2, int c = 3)
{
cout << "a" << a << endl;
cout << "b" << b << endl;
cout << "c" << c << endl;
}注:
- 半缺省参数必须从右往左依次来给出,不能间隔着给;
- 缺省参数不能在函数声明和定义中同时出现,定义和声明都有时,缺省参数建议给在声明部分,而不给在定义部分;
- 缺省值必须是常量或者全局变量
五、函数重载
1、函数重载的概念
函数重载是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
以下我们用函数重载实现不同类型的相加函数;
int Add(int a, int b)
{
return a + b;
}
double Add(double a, double b)
{
return a + b;
}
int main()
{
Add(1, 3); // 调用第一个Add函数
Add(2.6, 5.7); // 调用第二个Add函数
return 0;
}在调用Add函数时,编译器会通过形参找到对应的函数重载;
2、函数重载的分类
(1)函数参数个数不同构成重载
int Add(int a, int b)
{
return a + b;
}
int Add(int a, int b, int c)
{
return a + b + c;
}函数参数个数不同可以构成重载;
(2)函数参数类类型不同构成重载
int Add(int a, int b)
{
return a + b;
}
double Add(double a, double b)
{
return a + b;
}函数参数类型不同也可以构成重载;
(3)函数参数顺序不同构成重载
void func(int a, double b)
{
}
void func(double a, int b)
{
}函数参数顺序不同构成重载;
注意:相同类型参数顺序不同不能构成重载,比如两个int型,先后顺序不同不能构成重载
问题:函数返回值不同是否能构成重载呢?
假设可以构成重载,有以下两个函数;
int func(int a, double b)
{
}
void func(double a, int b)
{
}
int main()
{
func();
return 0;
}那么以上代码调用func函数时,会调用哪个函数呢?显而易见,这样的程序是有歧义的,调用函数时,编译器会通过参数来区分同名函数,而参数相同时,编译器也无法区分应该调用哪个函数了,因此返回值不同是不能构成函数重载的;
3、函数重载的深刻理解
问:编译器是如何通过函数参数的不同来区分调用不同的函数呢?
实际上,在函数编译的过程中,编译器会对每个函数进行修饰,不同的编译器修饰规则也不同,接下来我会带着大家在linux的环境下,用gcc(C语言编译)和g++(C++编译)带着大家来观察函数重载的过程;

以下为gcc(C语言方式)编译后形成的汇编代码;
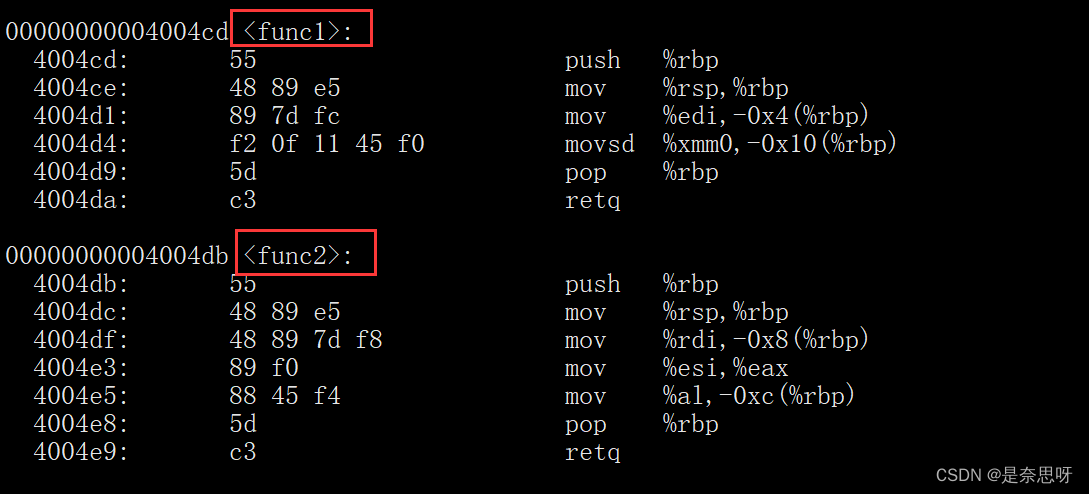
很显然,我们发现,用C语言方式编译后的汇编指令中的函数名并没有发生改变,函数名依然为原函数名;
接下来,我们用g++(C++方式)编译上述代码,以下为生成的汇编代码结果;

在以上汇编指令中,我们发现用C++编译放是进行编译生成的汇编指令中,函数的名字发生了变化,比如func1(int a, double b)中,func1变成了_Z5func1id,其中_Z为linux修饰函数特有前缀,5为函数名字符数,i为第一个参数类型int,d为第二个参数类型double,func2函数名依此类推
问:函数重载是否会影响程序的运行速度呢?
实际上,函数名的修饰是在编译过程中形成的,而只有在运行中的操作才会影响程序的运行速度,因此函数名的重载对运行速度并没有什么影响;
六、引用
1、引用的基本概念
引用不是新定义了一个变量,而是为一个已存在的变量取了别名,编译器不会为引用重新开辟一块空间,而是和引用对象共同管理一块空间;
int main()
{
int a = 0;
int& ra = a; //定义一个引用类型变量
return 0;
}以上代码定义了一个引用类型变量ra,当改变a的值时,ra的值也相应发生改变,因为他们共用一块内存空间;
2、引用的特性
(1)定义引用时必须初始化
int main()
{
int a = 0;
int& ra1; // err 未初始化
int& ra2 = a; // 正确
return 0;
}(2)一个变量可以有多个引用
int main()
{
int a = 0;
int& ra1 = a;
int& ra2 = a;
int& ra3 = a;
return 0;
}ra1、ra2、ra3都是a变量的引用,也就是a的别名;
(3)引用一旦引用一个实体,再不能引用其他实体
int main()
{
int a = 0;
int b = 2;
int& ra1 = a;
ra1 = b; //此时仅仅只是将b变量的值赋值给引用变量ra1,而不会让ra1称为b的引用变量
return 0;
}3、常引用
所谓常引用指的是在普通引用对象前加上const修饰;
int main()
{
const int a = 10;
int& ra1 = a; //err 权限放大,有只读到可写可读
const int& ra2 = a; // 正确
int b = 20;
int& rb1 = b; // 正确
const int& ra2 = b; // 正确 权限缩小,由可读可写到只读
return 0;
}第四行代码是错误的,因为原本的a变量是一个const修饰的变量,其只具有只读功能,而当赋值给他的引用ra1后,除了读以外还赋予ra写的功能,这本身并不合理,因此我们只能用一个常引用的变量来接收这个a变量;
总结:权限可以缩小和平移,不可以放大
4、引用的使用场景
(1)作形参
void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}(2)作返回值
int& count()
{
static int count = 0;
count++;
return count;
}注意:选择引用作返回值时一定要当心,比如以下代码;
int& Add(int a, int b)
{
int c = a + b;
return c;
}此时明显是有问题的,当c变量以引用的方式返回时,出了作用域以后c变量被销毁,而返回的是c变量的引用,用的是同一块空间,可是这块空间在出作用域的时候被销毁了,这么做明显是不合理的;
5、引用与指针的对比
引用与指针的不同点:
- 引用只是定义了一个变量的别名,而指针是储存一个变量的地址;
- 引用在定义时必须要初始化,而指针没有要求
- 引用在初始化时引用一个实体后,不可再引用别的实体,而指针可以随时改变其指向;
- 没有NULL引用,而有NULL指针
- sizeof中的含义不同,引用中sizeof结果为引用类型的大小,而指针的大小始终是固定的,再32位机器是4字节,在64位机器上是8字节
- 引用自加及是引用实体加1,而指针是往后偏移类型大小
- 有多级指针,没有多级引用
- 访问实体不同,指针需要解引用,而引用有编译器处理
- 引用比指针用起来更安全
七、内联函数
1、内联函数的概念
在C语言的学习中,我们学习过一种由宏定义的函数,但是宏定义的函数由种种缺陷,因此C++语言的设计中,定义了一种类似于宏函数的函数,取名为内联函数;内联函数是以关键字inline开头,如以下代码;
inline void Swap(int& a, int b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 10;
int b = 20;
Swap(a, b);
return 0;
}接下来,我带着大家一起观察内联函数确实是取消调用了函数,而是在原处展开;首先我们要知道的是函数的调用在汇编语言中一般会有call语句,我的编译器(vs2022)默认在debug模式下不会对内联函数进行展开,因此需要进行如下设置;

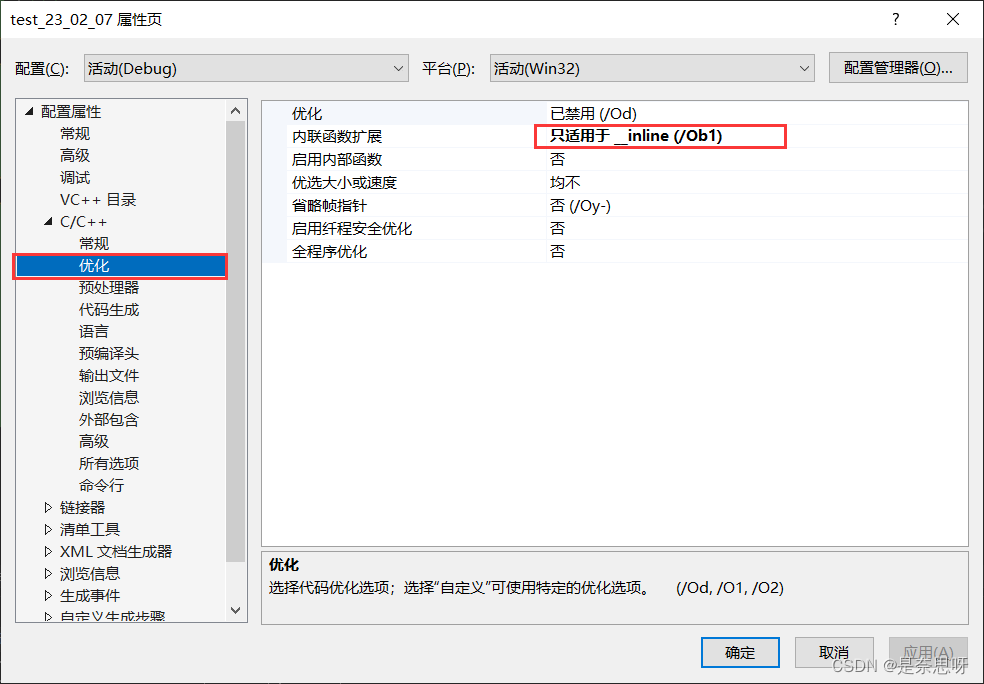
完成了上述两步步骤后就可在debug模式下,观察内联函数的展开;
首先我们按F10进入调试模式(有些电脑需要按fn+f10),然后右键鼠标选择反汇编,我们在反汇编模式下进行调试。
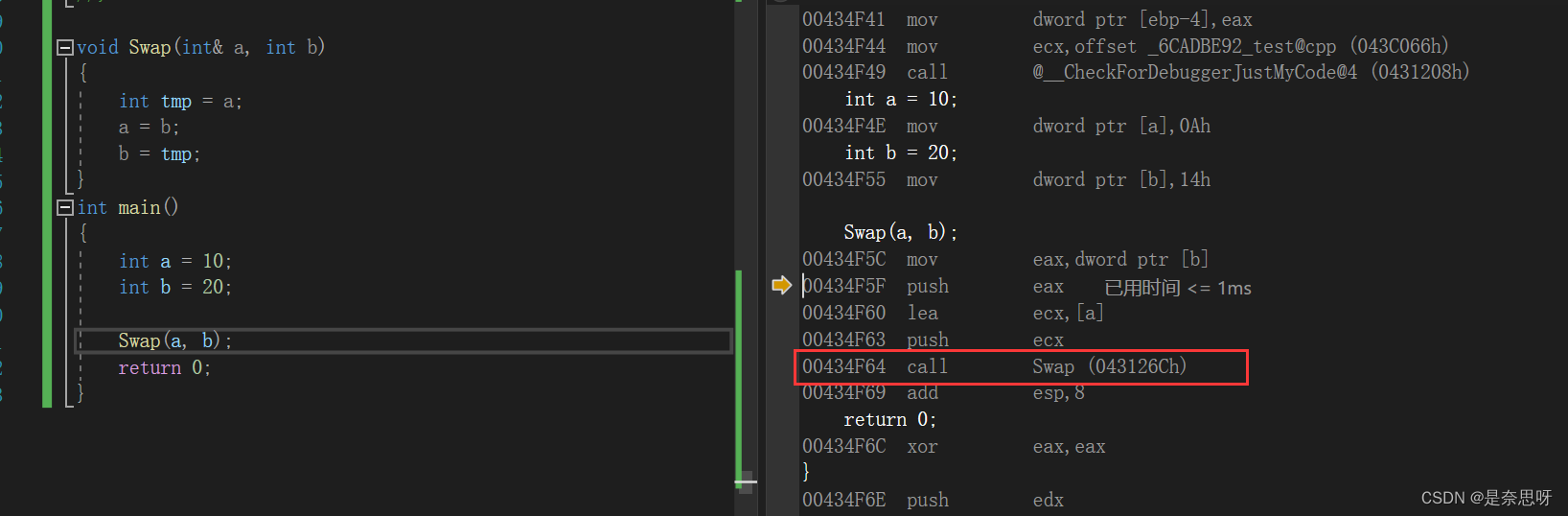
在汇编代码中,我们发现了call指令,其为函数调用函数,说明了函数开辟了栈帧空间调用函数,接着我们加上关键字再进行如上调试。

在我们加入inline关键字后,我们并未在汇编指令中发现call指令,因此我们可以推断出在加入inline关键字后,函数并未采取开辟栈帧空间的方式进行调用,而是在原处展开。
2、内联函数的特性
1、inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。(其中的空间指的是程序空间)
2、inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
3.、inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
八、auto关键字
1、auto简介
C++使用auto修饰变量能自动识别变量类型,也就是说定义auto的变量接收赋值后,编译器会自动识别定义变量类型;
int main()
{
auto a = 10;
auto b = 'a';
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
return 0;
}
typeid是打印变量类型的函数,通过打印结果,我们确实发现auto能通过赋值的数据来自定义类型。
2、auto使用过程中需要注意的细节
(1)auto必须要初始化;
int main()
{
int a= 10;
//auto x; //err 错误写法,未初始化
//x = a;
auto y = a; //正确
return 0;
}其实仔细想想也知道,如果不初始化,编译器又怎么知道auto应该是什么类型呢,要开多大空间呢?
(2)auto和auto*以及auto&
int main()
{
int a = 10;
auto p1 = &a; //auto 与 auto* 是等价的写法,他们都表示一级指针
auto* p2 = &a;
cout << typeid(p1).name() << endl;
cout << typeid(p2).name() << endl;
auto ra1 = a; // auto 与 auto& 也是如此,他们都表示a的别名
auto& ra2 = a;
cout << typeid(ra1).name() << endl;
cout << typeid(ra2).name() << endl;
return 0;
}许多初学者会误以为auto*是二级指针,其实并不是的,是否加*两者没有什么本质上的区别;
(3)同一行定义多个变量必须未同类型
int main()
{
auto a = 4, b = 8;
auto a = 2, b = 4.9; // err auto只会对第一个变量进行类型推测
return 0;
}在同一行中,auto只会对其第一个变量进行类型推测,默认认为后面的变量与第一个变量同类型,因此,在同一行auto语句中,只能存在一种类型;
注:除上面三点以外,还有以下两点要特别注意;
auto不能作为函数的形参,编译器无法对形参进行类型推导 ;
void test(auto a) // err
{
}auto不能用于直接申请数组;
auto arr[] = { 1, 2, 4 }; // err
九、范围for语句
在C++11中,为我们提供了一种更简单的for语句,我们可以将这种新的for语句理解成为传统for语句的语法糖,具体用法如下;
for ( 变量 : 数组等) { 循环体 }
int main()
{
int arr[] = { 1,2,3,4,5,6 };
for (int e : arr)
{
cout << e << endl;
}
return 0;
}以上for语句会自动将数组的每个元素依次赋值给变量e,实际上我们可以int e写成 auto e,这样写可以增加代码的通用性;但我们发现如果我们想将数组的每个元素乘以2并打印出来单纯的拿e*2并不能做到,因此又有以下写法;
int main()
{
int arr[] = { 1,2,3,4,5,6 };
for (auto& e : arr)
{
e *= 2;
cout << e << endl;
}
return 0;
}使用引用就使得每个e变量都是数组每个元素的别名,共同维护同一块空间,因此可以进行*2操作;
十、指针空值nullptr
在C++发展中,推出了一种新的空指针------nullptr,相当于NULL,实际上,这是C++填补C语言的坑,在传统的C头文件中,是这么对NULL进行定义的;
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif也就是说C++文件中,NULL会被定义为整型0,而非((void*)0),可能有人认为这并没有上面大碍,因为有时0确实就是我们所说的NULL,但是在某些情况下会出现很大的BUG,如下代码;
void f(int)
{
cout<<"f(int)"<<endl;
}
void f(void*)
{
cout<<"f(void*)"<<endl;
}
int main()
{
f(0);
f(NULL);
f((void*)NULL);
return 0;
}在以上代码中,形成了函数重载,而在我们调用函数时,我们发现,我们传入整型时,调用的第一个函数,而我们传入NULL时,也是调用的第一个函数,这明显不符合我们的预期的,因此C++推出了nullptr,并将nullptr定义成((void*)0);
智能推荐
一个ngrok如何穿透多个端口?_ngrok多个端口-程序员宅基地
文章浏览阅读2.7k次,点赞2次,收藏4次。如何不充钱就可以穿透多个端口?./ngrok authtoken 授权码之前这个操作的生成的yml文件中修改 端口可添加多个addr:port端口可随意配置_ngrok多个端口
C语言 char转uint8_t-程序员宅基地
文章浏览阅读5.9k次。char转uint8_t:static int char2uint(char *input, uint8_t *output){ for(int i = 0; i < 24; i++) { output[i] &= 0x00; for (int j = 1; j >= 0; j--) { char hb = input[i*2 + 1 - j]; if (hb >= '0' &..._char转uint8_t
android 陀螺仪简单使用,判读手机是否静止状态_安卓陀螺仪多少才算静止-程序员宅基地
文章浏览阅读6.5k次,点赞5次,收藏13次。陀螺仪允许您在任何给定时刻确定Android设备的角速度。简单来说,它告诉您设备绕X,Y和Z轴旋转的速度有多快。最近,即使是预算手机正在制造,陀螺仪内置,增强现实和虚拟现实应用程序变得如此受欢迎。通过使用陀螺仪,您可以开发可以响应设备方向的微小更改的应用程序。创建陀螺仪对象和管理器manager// Register it, specifying the polling interv..._安卓陀螺仪多少才算静止
lib静态库逆向分析_libtersafe-程序员宅基地
文章浏览阅读4.7k次,点赞3次,收藏16次。当我们要分析一个lib库里的代码时,首先需要判断这是一个静态库还是一个导入库。库类型判断lib文件其实是一个压缩文件。我们可以直接使用7z打开lib文件,以查看里面的内容。如果里面的内容是obj文件,表明是静态库。如果里面的内容是dll文件,表明是导入库。导入库里面是不包含代码的,代码包含在对应的dll文件中。从lib中提取obj静态库是一个或者多个obj文件的打包,这里有两个方法从中提取obj:Microsoft 库管理器 7z解压Microsoft 库管理器(li_libtersafe
Linux的网络适配器_linux 查询网络适配器-程序员宅基地
文章浏览阅读5.3k次,点赞3次,收藏3次。了解一下,省的脑壳痛 桥接模式对应的虚拟网络名称“VMnet0” 桥接模式下,虚拟机通过主机的网卡进行通信,若物理主机有多块网卡(有线的和无线网卡),应选择桥结哪块物理网卡桥接模式下,虚拟机和物理主机同等地位,可以通过物理主机的网卡访问外网(局域网),一个局域网的其他计算机可以访问虚拟机。为虚拟机设置一个与物理网卡在同个网段的IP,则虚拟机就可以与物理主机以及局域..._linux 查询网络适配器
【1+X Web前端等级考证 】 | Web前端开发中级理论 (附答案)_1+xweb前端开发中级-程序员宅基地
文章浏览阅读3.4w次,点赞77次,收藏438次。# 前言2020 12月 1+X Web 前端开发中级 模拟题大致就更这么多,我的重心不在这里,就不花太多时间在这里面了。但是,说说1+X Web前端开发等级考证这个证书,总有人跑到网上问:这个证书有没有用? 这个证书含金量高不高?# 关于考不考因为这个是工信部从2019年才开始实施试点的,目前还在各大院校试点中,就目前情况来看,知名度并不是很高,有没有用现在无法一锤定音,看它以后办的怎么样把,软考以前也是慢慢地才知名起来。能考就考吧,据所知,大部分学校报考,基本不用交什么报考费(小部分学校,个别除._1+xweb前端开发中级
随便推点
项目组织战略管理及组织结构_项目组织的具体形态的是战略管理层-程序员宅基地
文章浏览阅读1.7k次。组织战略是组织实施各级项目管理,包括项目组合管理、项目集管理和项目管理的基础。只有从组织战略的高度来思考,思考各个层次项目管理在组织中的位置,才能够理解各级项目管理在组织战略实施中的作用。同时战略管理也为项目管理提供了具体的目标和依据,各级项目管理都需要与组织的战略保持一致。..._项目组织的具体形态的是战略管理层
图像质量评价及色彩处理_图像颜色质量评价-程序员宅基地
文章浏览阅读1k次。目录基本统计量色彩空间变换亮度变换函数白平衡图像过曝的评价指标多视影像因曝光条件不一而导致色彩差异,人眼可以快速区分影像质量,如何利用图像信息辅助算法判断影像优劣。基本统计量灰度均值方差梯度均值方差梯度幅值直方图图像熵p·log(p)色彩空间变换RGB转单通道灰度图像 mean = 225.7 stddev = 47.5mean = 158.5 stddev = 33.2转灰度梯度域gradMean = -0.0008297 / -0.000157461gr_图像颜色质量评价
MATLAB运用规则,利用辛普森规则进行数值积分-程序员宅基地
文章浏览阅读1.4k次。Simpson's rule for numerical integrationZ = SIMPS(Y) computes an approximation of the integral of Y via the Simpson's method (with unit spacing). To compute the integral for spacing different from one..._matlab利用幸普生计算积分
【AI之路】使用huggingface_hub优雅解决huggingface大模型下载问题-程序员宅基地
文章浏览阅读1.2w次,点赞28次,收藏61次。Hugging face 资源很不错,可是国内下载速度很慢,动则GB的大模型,下载很容易超时,经常下载不成功。很是影响玩AI的信心。经过多次测试,终于搞定了下载,即使超时也可以继续下载。真正实现下载无忧!究竟如何实现?且看本文分解。_huggingface_hub
mysql数据库查看编码,mysql数据库修改编码_查看数据库编码-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏7次。其中 `DEFAULT CHARSET` 和 `COLLATE` 分别指定了表的默认编码和排序规则。其中 `DEFAULT CHARACTER SET` 指定了数据库的默认编码。其中 `Collation` 列指定了字段的排序规则,这也是字段的默认编码。此命令将更改表的默认编码和排序规则。此命令将更改字段的编码和排序规则。此命令将更改数据库的默认编码。_查看数据库编码
机器学习(十八):Bagging和随机森林_bagging数据集-程序员宅基地
文章浏览阅读1.3k次,点赞7次,收藏24次。本文深入探讨了集成学习及其在随机森林中的应用。对集成学习的基本概念、优势以及为何它有效做了阐述。随机森林,作为一个集成学习方法,与Bagging有紧密联系,其核心思想和实现过程均在文中进行了说明。还详细展示了如何在Sklearn中利用随机森林进行建模,并对其关键参数进行了解读,希望能帮助大家更有效地运用随机森林进行数据建模。_bagging数据集