大数据实验总结(六)--搭建Mapreduce(YARN)环境,运行Wordcount示例_hdfs dfs -rm -r /output-程序员宅基地
搭建Mapreduce(YARN)环境,运行Wordcount示例
搭建Mapreduce(YARN)环境
- 修改yarn-site.xml文件:
cd /usr/local/hadoop/etc/hadoop/
vim yarn-site.xml
如图:

具体内容:
<!-- Site specific YARN configuration properties -->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class </name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
其中名称yarn.resourcemanager.hostname指的是ResourceManager机器所在的节点位置;名称yarn.nodemanager.aux-services在hadoop2.2.0版本中是mapreduce_shuffle.
测试YARN环境
- 启动hdfs
start-dfs.sh - 启动hdfs
Start-yarn.sh
使用浏览器打开页面:
http://master:8088/
或http://192.168.50.100:8088/
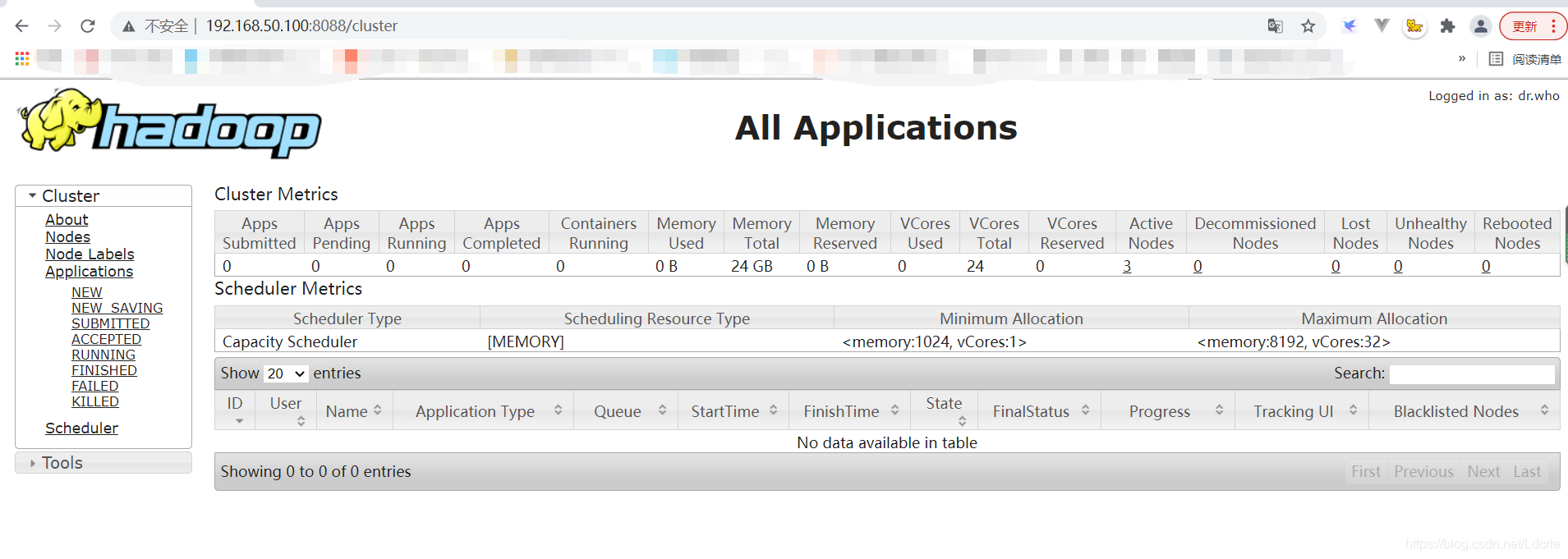
测试Mapreduce环境(运行Wordcount示例)
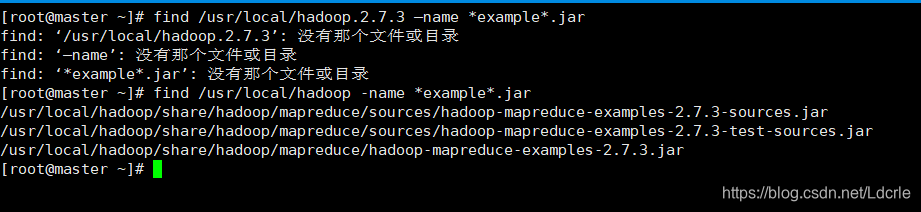
find /usr/local/hadoop -name *example*.jar
//查找示例程序,目录名需根据自己环境适当调整。

- 在HDFS上创建input目录
hdfs dfs -mkdir input - 在HDFS上创建output目录
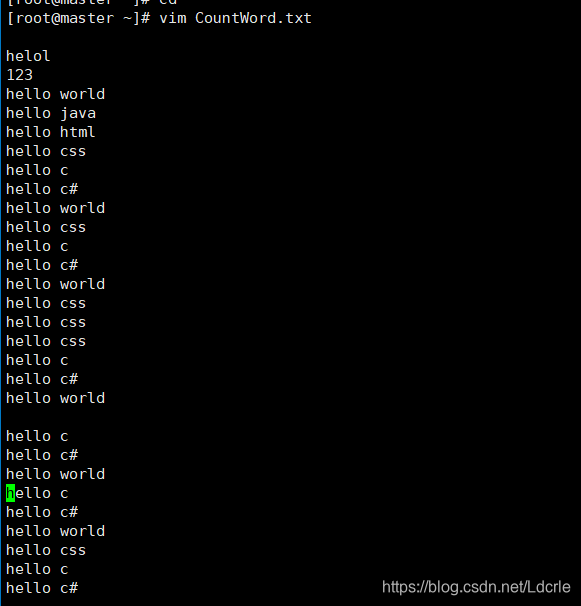
hdfs dfs -mkdir output - 创建运行示例文档CountWord.txt并进行编写:
例:
helol
123
hello world
hello java
hello html
hello css
hello c
hello c#
hello world
hello css
hello c
hello c#
hello world
hello css
hello css
hello css
hello c
hello c#
hello world
hello c
hello c#
hello world
hello c
hello c#
hello world
hello css
hello c
hello c#
hello world
hello css
hello c
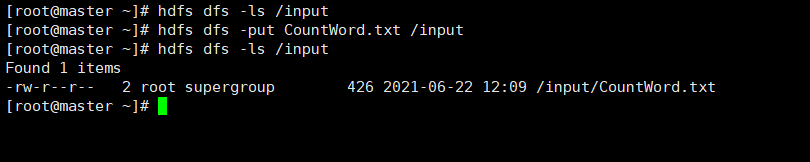
- 将CountWord.txt上传到HDFS中input目录下:
hdfs dfs -put CountWord.txt /input
- 查看:
hdfs dfs -ls /input
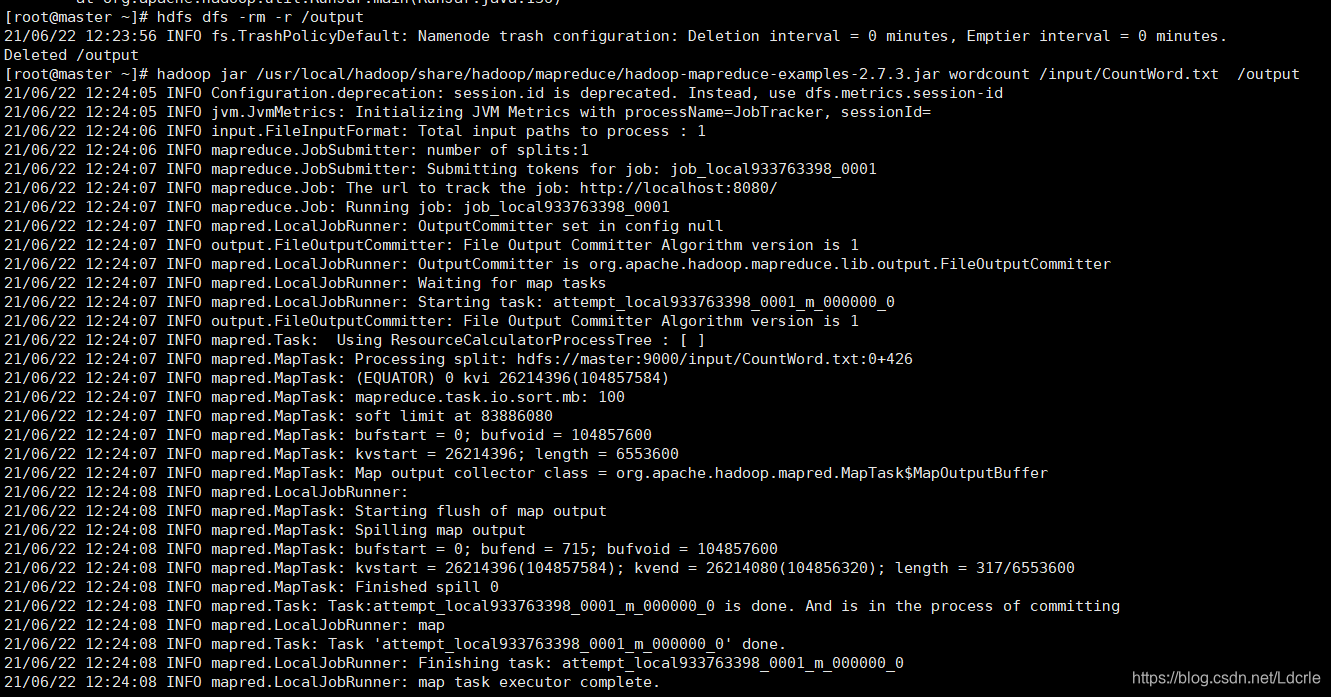
- 运行Wordcount示例程序:
输入为:/input/CountWord.txt ,运行结果输出目录为: /output
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/CountWord.txt /output
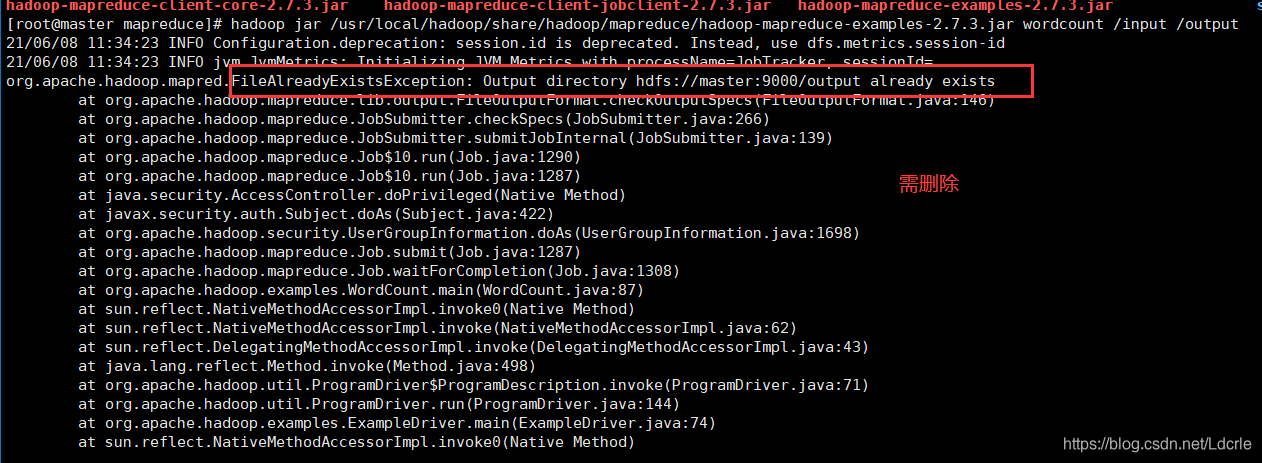
出现错误(FileAlreadyExistsException: Output directory hdfs://master:9000/output already exists):

原因:
上次运行的输出目录也是output,没有进行删除。(好像每次运行的输出目录不能存在,运行过程中自动创建,若存在则运行失败,也有可能是我重复执行同一个文件的原因)
解决方法:
将/output目录删除:
hdfs dfs -rm -r /output
-
再次运行,成功:
-
-
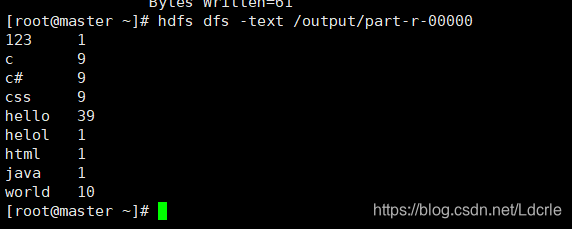
查看运行结果:
hdfs dfs -text /output/part-r-00000
注意事项:
每次运行前,请确保运行结果的输出目录不存在
[root@master mapreduce]# hdfs dfs -rm -r /output
执行的txt文件是需要自己上传到HDFS后才能运行的。
[root@master ~]# hdfs dfs -put CountWord.txt /input
运行成功详细信息:
[root@master ~]# hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /inpu/tCountWord.txt /output
21/06/08 11:42:49 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
21/06/08 11:42:49 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
21/06/08 11:42:50 INFO mapreduce.JobSubmitter: Cleaning up the staging area file:/var/hadoop/mapred/staging/root284026624/.staging/job_local284026624_0001
org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://master:9000/inpu/tCountWord.txt
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:323)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:265)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:387)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:301)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:318)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:196)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at org.apache.hadoop.examples.WordCount.main(WordCount.java:87)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71)
at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
[root@master ~]# hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/CountWord.txt /output
21/06/08 11:43:35 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
21/06/08 11:43:35 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
21/06/08 11:43:36 INFO input.FileInputFormat: Total input paths to process : 1
21/06/08 11:43:36 INFO mapreduce.JobSubmitter: number of splits:1
21/06/08 11:43:36 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local764084505_0001
21/06/08 11:43:36 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
21/06/08 11:43:36 INFO mapreduce.Job: Running job: job_local764084505_0001
21/06/08 11:43:36 INFO mapred.LocalJobRunner: OutputCommitter set in config null
21/06/08 11:43:36 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
21/06/08 11:43:36 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
21/06/08 11:43:36 INFO mapred.LocalJobRunner: Waiting for map tasks
21/06/08 11:43:36 INFO mapred.LocalJobRunner: Starting task: attempt_local764084505_0001_m_000000_0
21/06/08 11:43:37 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
21/06/08 11:43:37 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
21/06/08 11:43:37 INFO mapred.MapTask: Processing split: hdfs://master:9000/input/CountWord.txt:0+426
21/06/08 11:43:37 INFO mapreduce.Job: Job job_local764084505_0001 running in uber mode : false
21/06/08 11:43:37 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
21/06/08 11:43:37 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
21/06/08 11:43:37 INFO mapred.MapTask: soft limit at 83886080
21/06/08 11:43:37 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
21/06/08 11:43:37 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
21/06/08 11:43:37 INFO mapreduce.Job: map 0% reduce 0%
21/06/08 11:43:37 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
21/06/08 11:43:38 INFO mapred.LocalJobRunner:
21/06/08 11:43:38 INFO mapred.MapTask: Starting flush of map output
21/06/08 11:43:38 INFO mapred.MapTask: Spilling map output
21/06/08 11:43:38 INFO mapred.MapTask: bufstart = 0; bufend = 715; bufvoid = 104857600
21/06/08 11:43:38 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214080(104856320); length = 317/6553600
21/06/08 11:43:38 INFO mapred.MapTask: Finished spill 0
21/06/08 11:43:38 INFO mapred.Task: Task:attempt_local764084505_0001_m_000000_0 is done. And is in the process of committing
21/06/08 11:43:38 INFO mapred.LocalJobRunner: map
21/06/08 11:43:38 INFO mapred.Task: Task 'attempt_local764084505_0001_m_000000_0' done.
21/06/08 11:43:38 INFO mapred.LocalJobRunner: Finishing task: attempt_local764084505_0001_m_000000_0
21/06/08 11:43:38 INFO mapred.LocalJobRunner: map task executor complete.
21/06/08 11:43:38 INFO mapred.LocalJobRunner: Waiting for reduce tasks
21/06/08 11:43:38 INFO mapred.LocalJobRunner: Starting task: attempt_local764084505_0001_r_000000_0
21/06/08 11:43:38 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
21/06/08 11:43:38 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
21/06/08 11:43:38 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@5eb258cc
21/06/08 11:43:38 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=363285696, maxSingleShuffleLimit=90821424, mergeThreshold=239768576, ioSortFactor=10, memToMemMergeOutputsThreshold=10
21/06/08 11:43:38 INFO reduce.EventFetcher: attempt_local764084505_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
21/06/08 11:43:39 INFO mapreduce.Job: map 100% reduce 0%
21/06/08 11:43:39 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local764084505_0001_m_000000_0 decomp: 97 len: 101 to MEMORY
21/06/08 11:43:39 INFO reduce.InMemoryMapOutput: Read 97 bytes from map-output for attempt_local764084505_0001_m_000000_0
21/06/08 11:43:39 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 97, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->97
21/06/08 11:43:39 WARN io.ReadaheadPool: Failed readahead on ifile
EBADF: Bad file descriptor
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posix_fadvise(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posixFadviseIfPossible(NativeIO.java:267)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX$CacheManipulator.posixFadviseIfPossible(NativeIO.java:146)
at org.apache.hadoop.io.ReadaheadPool$ReadaheadRequestImpl.run(ReadaheadPool.java:206)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
21/06/08 11:43:39 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
21/06/08 11:43:39 INFO mapred.LocalJobRunner: 1 / 1 copied.
21/06/08 11:43:39 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
21/06/08 11:43:39 INFO mapred.Merger: Merging 1 sorted segments
21/06/08 11:43:39 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 91 bytes
21/06/08 11:43:39 INFO reduce.MergeManagerImpl: Merged 1 segments, 97 bytes to disk to satisfy reduce memory limit
21/06/08 11:43:39 INFO reduce.MergeManagerImpl: Merging 1 files, 101 bytes from disk
21/06/08 11:43:39 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
21/06/08 11:43:39 INFO mapred.Merger: Merging 1 sorted segments
21/06/08 11:43:39 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 91 bytes
21/06/08 11:43:39 INFO mapred.LocalJobRunner: 1 / 1 copied.
21/06/08 11:43:39 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
21/06/08 11:43:39 INFO mapred.Task: Task:attempt_local764084505_0001_r_000000_0 is done. And is in the process of committing
21/06/08 11:43:39 INFO mapred.LocalJobRunner: 1 / 1 copied.
21/06/08 11:43:39 INFO mapred.Task: Task attempt_local764084505_0001_r_000000_0 is allowed to commit now
21/06/08 11:43:39 INFO output.FileOutputCommitter: Saved output of task 'attempt_local764084505_0001_r_000000_0' to hdfs://master:9000/output/_temporary/0/task_local764084505_0001_r_000000
21/06/08 11:43:39 INFO mapred.LocalJobRunner: reduce > reduce
21/06/08 11:43:39 INFO mapred.Task: Task 'attempt_local764084505_0001_r_000000_0' done.
21/06/08 11:43:39 INFO mapred.LocalJobRunner: Finishing task: attempt_local764084505_0001_r_000000_0
21/06/08 11:43:39 INFO mapred.LocalJobRunner: reduce task executor complete.
21/06/08 11:43:40 INFO mapreduce.Job: map 100% reduce 100%
21/06/08 11:43:40 INFO mapreduce.Job: Job job_local764084505_0001 completed successfully
21/06/08 11:43:40 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=592184
FILE: Number of bytes written=1149995
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=852
HDFS: Number of bytes written=61
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Map-Reduce Framework
Map input records=44
Map output records=80
Map output bytes=715
Map output materialized bytes=101
Input split bytes=103
Combine input records=80
Combine output records=9
Reduce input groups=9
Reduce shuffle bytes=101
Reduce input records=9
Reduce output records=9
Spilled Records=18
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=46
Total committed heap usage (bytes)=242360320
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=426
File Output Format Counters
Bytes Written=61
[root@master ~]# hdfs dfs -text /output/part-r-00000
123 1
c 9
c# 9
css 9
hello 39
helol 1
html 1
java 1
world 10
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范