(超详细) Spark环境搭建(Local模式、 StandAlone模式、Spark On Yarn模式)-程序员宅基地
技术标签: 大数据学习之路 Spark学习之路 spark hadoop 大数据
Spark环境搭建
JunLeon——go big or go home

目录
目录
(4)配置log4j.properties 文件 [可选配置]
前言:
Spark部署模式主要有4种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、Spark On Yarn模式(使用YARN作为集群管理器)和Spark On Mesos模式(使用Mesos作为集群管理器)。
本教程做前三种环境搭建的详细讲解。
一、环境准备
1、软件准备
Linux:CentOS-7-x86_64-DVD-1708.iso
Hadoop:hadoop-2.7.3.tar.gz
Java:jdk-8u181-linux-x64.tar.gz
Anaconda:Anaconda3-2021.11-Linux-x86_64.sh
Spark:spark-2.4.0-bin-without-hadoop.tgz
2、Hadoop集群搭建
请查看 大数据学习——Hadoop集群完全分布式的搭建(超详细)_IT路上的军哥的博客-程序员宅基地_hadoop完全分布式搭建
注:本教程中使用Hadoop完全分布式集群,主机名分别为spark-master、spark-slave01、spark-slave02
3、Anaconda环境搭建
(1)下载Anaconda3
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
注:如果打不开网页,可以尝试换浏览器打开
(2)上传Anaconda的文件到Linux
上传到指定目录:/opt/software #没有的话就创建
(3)Anaconda On Linux 安装
在该目录下,执行Anaconda文件
cd /opt/software
sh ./Anaconda3-2021.11-Linux-x86_64.sh进入以下界面:直接回车即可
接下来 阅读许可条款 ,一直空格

在此处是询问是否同意许可条款,输入 yes

指定 anaconda3 安装路径:
将路径修改为
/opt/anaconda3目录下
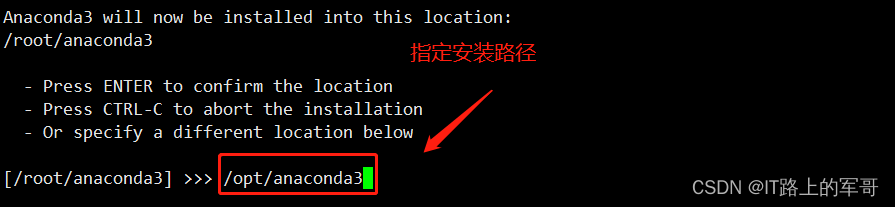
此处需要初始化,输入 yes

最后,使用exit退出远程连接工具,重新连接,如果出现以下base字样,说明安装成功!

注:base是默认的虚拟环境。
以上单台 Anaconda On Linux 环境搭建成功,即可开始安装spark。
(4)配置国内源:
vi ~/.condarc这个文件,追加以下内容:
注:该文件是一个空文件,直接添加即可
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud(5)创建pyspark环境
conda create -n pyspark python=3.6 # 基于python3.6创建pyspark虚拟环境
conda activate pyspark # 激活(切换)到pyspark虚拟环境注:如果执行 conda create -n pyspark python=3.6 命令下载失败,可能是你的虚拟机不能ping通网络,可以看看ping www.baidu.com是否能够ping通
(6)pip下载pyhive、pyspark、jieba包
在pyspark环境中使用pip下载pyhive、pyspark、jieba包
pip install pyspark==2.4.0 jieba pyhive -i https://pypi.tuna.tsinghua.edu.cn/simple二、Spark Local模式搭建
Spark Local模式也称单机或者本地模式,仅供测试用。并在spark-master主机进行操作。
1、Spark下载、上传和解压
(1)Spark版本下载
该环境搭建spark使用spark-2.4.0版本
(2)上传Spark压缩包
上传到指定目录:/opt/software
(3)解压上传好的压缩包
cd /opt/software
tar -zxvf spark-2.4.0-bin-without-hadoop.tgz -C /opt
mv spark-2.4.0-bin-without-hadoop/ spark-2.4.0解压之后进行重命名,重命名为
spark-2.4.0
2、配置环境变量
配置Spark由如下5个环境变量需要设置
-
SPARK_HOME: 表示Spark安装路径在哪里
-
PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
-
JAVA_HOME: 告知Spark Java在哪里
-
HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
-
HADOOP_HOME: 告知Spark Hadoop安装在哪里
这5个环境变量 都需要配置在: /etc/profile中
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_181
# HADOOP_HOME
export HADOOP_HOME=/opt/hadoop-2.7.3
# SPARK_HOME
export SPARK_HOME=/opt/spark-2.4.0
# HADOOP_CONF_DIR
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# PYSPARK_PYTHON
export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$PATHPYSPARK_PYTHON和JAVA_HOME 需要同样配置在: ~/.bashrc中
vi ~/.bashrc
# 默认启动pyspark虚拟环境
conda activate pyspark
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_181
# PYSPARK_PYTHON
export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python
export PATH=$JAVA_HOME/bin:$PATH配置好环境变量记得使文件生效:
source /etc/profile
source ~/.bashrc3、配置Spark配置文件
(1)spark-env.sh
cd /opt/spark-2.4.0/conf
cp spark-env.sh.template spark-env.sh在该文件最后追加以下内容:
export JAVA_HOME=/opt/jdk1.8.0_181
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.3/bin/hadoop classpath)4、测试
(1)验证Spark是否安装成功
pyspark进入pyspark虚拟环境后,输入pyspark后出现spark的logo则说明已成功:
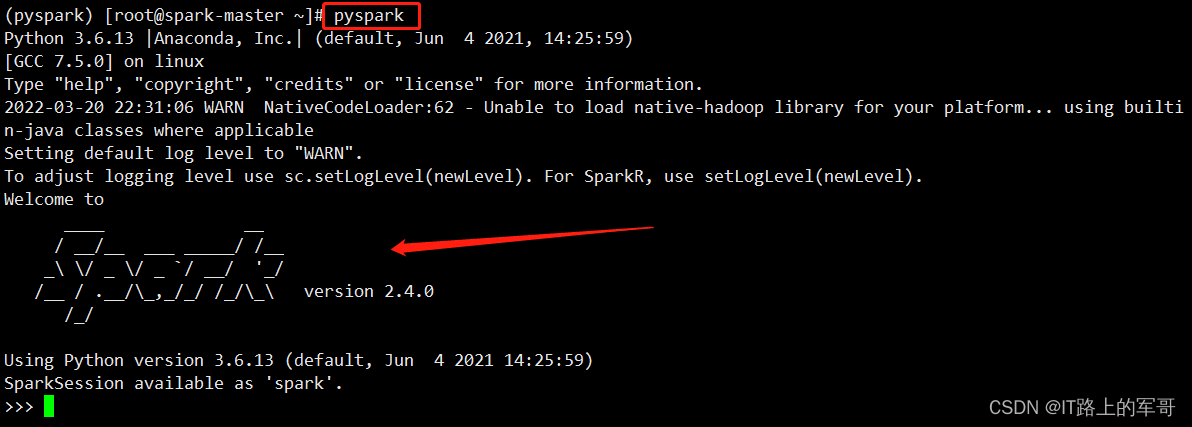
(2)运行Spark自带的Pi实例
run-example SparkPi
run-example SparkPi 2>&1 | grep "Pi is roughly" # 过滤日志信息(3)运行WordCount.py文件
在家目录下,创建一个.py文件,添加以下代码:
附:WordCount.py代码
# ~/WordCount.py
if __name__ == '__main__':
# 导入相关依赖包
from pyspark import SparkConf, SparkContext
# 创建SparkConf,创建一个SparkContext对象
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
# 设置文件路径
logFile = "file:///opt/spark-2.4.0/README.md"
# 负责读取README.md文件生成RDD
logData = sc.textFile(logFile, 2).cache()
# 统计RDD元素中包含字母a和字母b的行数
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
# 打印输出统计结果
print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))执行任务提交:
spark-submit ~/WordCount.py5、补充:spark-shell、spark-submit
(1)spark-shell
同样是一个解释器环境, 和pyspark不同的是, 这个解释器环境运行的不是python代码, 而是scala程序代码。
scala> sc.parallelize(Array(1,2,3,4,5)).map(x=> x + 1).collect()
res0: Array[Int] = Array(2, 3, 4, 5, 6)(2)spark-submit
作用: 提交指定的Spark代码到Spark环境中运行
使用方法:
# 语法
bin/spark-submit [可选的一些选项] jar包或者python代码的路径 [代码的参数]
# 示例
bin/spark-submit /opt/spark-2.4.0/examples/src/main/python/pi.py 10
# 此案例运行Spark官方所提供的示例代码,来计算圆周率值。后面的10是主函数接受的参数, 数字越高, 计算圆周率越准确。(3)pyspark、spark-shell、spark-submit对比
| 功能 | bin/spark-submit | bin/pyspark | bin/spark-shell |
|---|---|---|---|
| 功能 | 提交java\scala\python代码到spark中运行 | 提供一个python |
|
| 解释器环境用来以python代码执行spark程序 | 提供一个scala |
||
| 解释器环境用来以scala代码执行spark程序 | |||
| 特点 | 提交代码用 | 解释器环境 写一行执行一行 | 解释器环境 写一行执行一行 |
| 使用场景 | 正式场合, 正式提交spark程序运行 | 测试\学习\写一行执行一行\用来验证代码等 | 测试\学习\写一行执行一行\用来验证代码等 |
三、Spark StandAlone模式搭建
1、Hadoop集群与Spark集群节点规划
(1)集群主机名、IP规划
| 主机名 | IP地址 | 节点类型 |
|---|---|---|
| spark-master | 192.168.83.100 | Master |
| spark-slave01 | 192.168.83.101 | Slave |
| spark-slave02 | 192.168.83.102 | Slave |
(2)节点规划
| 节点进程 | spark-master | spark-slave01 | spark-slave02 |
|---|---|---|---|
| NameNode | |||
| Secondary NameNode | |||
| DataNode | |||
| ResourceManager | |||
| NodeManager | |||
| JobHistoryServer(YARN) | |||
| Master | |||
| Worker | |||
| HistoryServer(Spark) |
注:
JobHistoryServer:YARN资源管理器的历史服务器,将YARN运行的程序的历史日志记录下来,通过历史服务器方便用户查看程序运行的历史信息。
HistoryServer:Spark的历史服务器,将Spark运行的程序的历史日志记录下来, 通过历史服务器方便用户查看程序运行的历史信息。
2、三台虚拟机分别安装Anaconda3环境
此Anaconda环境搭建参考以上 环境准备中的第3点。也可以从第一台分发到另外两台:
scp -r /opt/anaconda3 root@spark-slava01:/opt
scp -r /opt/anaconda3 root@spark-slava02:/opt3、配置Spark配置文件
可以在spark-master主机操作,最后再进行分发。
注:Spark安装路径为:/opt/spark-2.4.0
spark配置文件路径为:/opt/spark-2.4.0/conf
cd /opt/spark-2.4.0/conf(1)配置spark-env.sh文件
# 1. 改名
mv spark-env.sh.template spark-env.sh
# 2. 编辑spark-env.sh, 在底部追加如下内容
vi spark-env.sh在spark-env.sh文件底部追加以下内容
## 设置JAVA安装目录
export JAVA_HOME=/opt/jdk1.8.0_181
## 设置hadoop命令路径
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.3/bin/hadoop classpath)
## 以上两行在local模式中已经添加,如果有请勿重复配置
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop
YARN_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=spark-master
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://spark-master:9000/sparklog/ -Dspark.history.fs.cleaner.enabled=true"(2)配置spark-defaults.conf文件
# 1. 改名
mv spark-defaults.conf.template spark-defaults.confvi spark-defaults.conf # 2. 修改内容, 追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://spark-master:9000/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true(3)配置slaves文件(新版本为workers文件)
# 改名, 去掉后面的.template后缀
mv slaves.template slaves# 编辑worker文件 vi slaves # 将文件里面最后一行的localhost删除
追加从节点worker运行的服务器,配置三台主机名
spark-master
spark-slave01
spark-slave02(4)配置log4j.properties 文件 [可选配置]
# 1. 改名
mv log4j.properties.template log4j.properties# 2. 修改内容 参考下图
vi log4j.properties定位到19行:将INFO修改为WARN
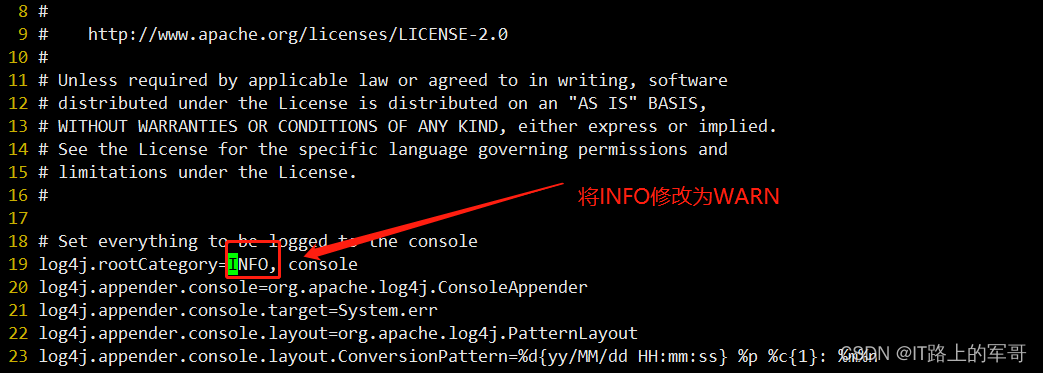
4、将配置好的spark分发到其他两台服务器上
将在spark-master主机上配置好的spark分发到另外两台服务器上:
scp -r /opt/spark-2.4.0/ root@spark-slave01:/opt/
scp -r /opt/spark-2.4.0/ root@spark-slave02:/opt/将主机的/etc/profile文件和~/.bashrc文件也同时分发到另外两台:
scp /etc/profile root@spark-slave01:/etc/
scp /etc/profile root@spark-slave02:/etc/
scp ~/.bashrc root@spark-slave01:~/
scp ~/.bashrc root@spark-slave02:~/分发过去之后需要分别在两台使配置文件生效:
source /etc/profile
source ~/.bashrc5、启动节点
1)启动Hadoop集群
start-all.sh # 只在spark-master主机上执行2)启动spark集群
cd /opt/spark-2.4.0/sbin
./start-all.sh开启全部节点后,如图所示:
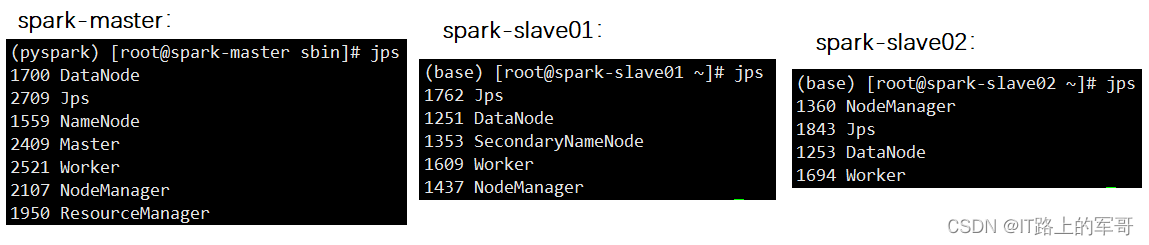
6、web端访问:
web端访问需要关闭防火墙:
systemctl stop firewalld1)访问HDFS
192.168.83.100:50070 # IP:端口号2)访问YARN
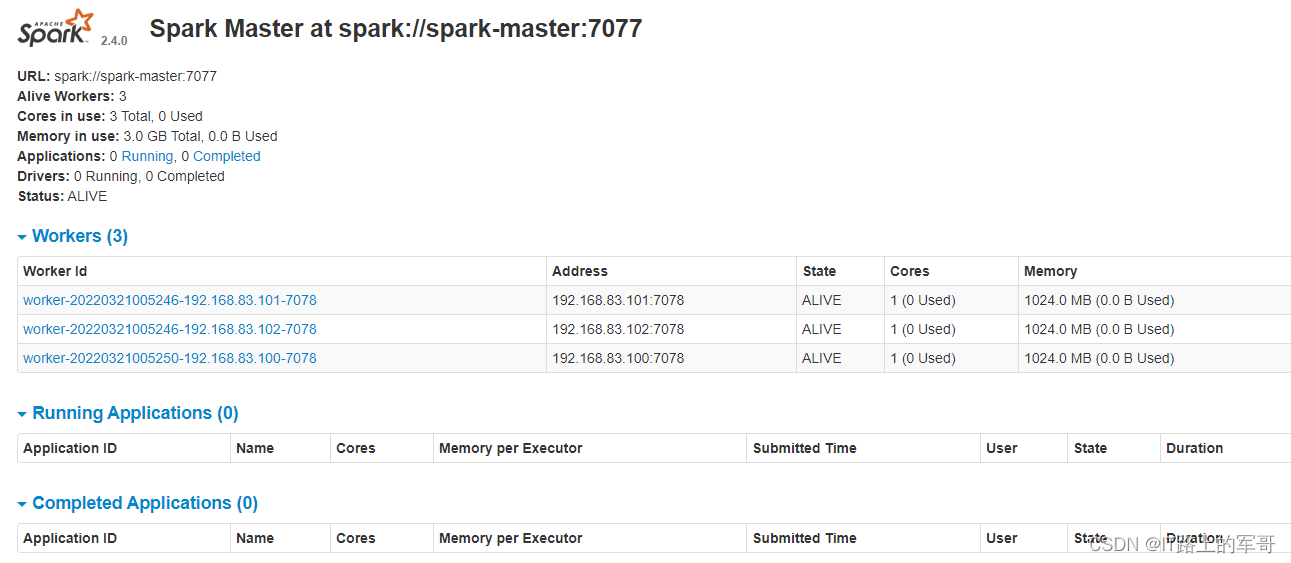
192.168.83.100:8088 # IP:端口号3)访问Spark
192.168.83.100:8080 # IP:端口号如图所示说明成功:
四、Spark On Yarn模式搭建
智能推荐
python服务器端开发面试_【网易游戏Python面试】python 服务端开发-看准网-程序员宅基地
文章浏览阅读145次。10.21终面已参加,希望能顺利通过终面拿到offer~一共三轮,电话面试+笔试+视频面试,视频面试3V110月19日投的新媒体运营的简历,HR说因为是周末,等工作日再联系我,在周一下午三点我接到了电话成功通过简历筛选和电话面试,整个电话面试的过程长,大概10分钟左右,因为前期稍微做了一些准备,所以还算对答如流,整个过程顺利,HR现场告诉我通过面试,并随即给我发了笔试题,让我准备一下,最晚三天之..._网易 python游戏服务器
MVC层次划分简述_mvc分层-程序员宅基地
文章浏览阅读6.5k次,点赞12次,收藏38次。MVC层次划分简述写在前面的一段话:首先要知道MVC和三层架构之间有什么关系:MVC:【 Model(数据模型) - View(视图) - Controller(控制器) 】三层架构:【 Presentation tier(展现层) - Application tier(应用层)+Date tier(数据访问层) 】很多人都有一个误解,认为Spring MVC的M、V、C对..._mvc分层
Flink的sink实战之三:cassandra3_flink cassandra-程序员宅基地
文章浏览阅读2.9k次。实践flink数据集sink到cassandra3_flink cassandra
使用docker安装codimd,搭建你自己的在线协作markdown编辑器_群晖 docker 搭建 codimd-程序员宅基地
文章浏览阅读7.1k次,点赞4次,收藏12次。文章目录一、前言二、codimd是什么?2.1 源于hackmd的超好用markdown编辑器2.2 codimd的作用三、安装和使用3.1 安装前需要知道的3.2 安装步骤3.2.1 创建数据库3.2.2 安装git3.2.3 安装docker3.2.4 安装docker compose3.2.5 安装codimd3.2.6 检查是否安装成功3.2.7 放行端口3.2.8 测试使用3.3 开始写..._群晖 docker 搭建 codimd
Json和ajax-程序员宅基地
文章浏览阅读335次。Json json 可以定义多种类型 var jsonObj = { "key1":123, "key2":"name", "key3":[12,"age",true], //数组 "key4":false, "key5":{ //存一个json对象 "key6":456, "key7":"number" }} json其实就是一个Object对象, 他的key值 可以看成对象的一个属性, 获取他的value值...
ssm超市账单管理系统a2e96【独家源码】 应对计算机毕业设计困难的解决方案-程序员宅基地
文章浏览阅读87次。选题背景:超市账单管理系统是一种针对超市行业的管理工具,旨在提供高效、准确、便捷的账单管理服务。随着城市化进程的加快和人们生活水平的提高,超市作为日常生活必需品的主要供应渠道之一,扮演着重要的角色。然而,传统的超市账单管理方式存在一些问题,如手工记录容易出错、数据整理繁琐、信息不透明等。因此,开发一个科技化的超市账单管理系统成为了必要之举。选题意义:首先,超市账单管理系统的开发可以提高账单管理的效率。传统的超市账单管理方式通常需要员工手动记录商品销售信息,并进行数据整理和汇总。这种方式容易出现人为错
随便推点
bookmarks_2021_9_28_拾度智能科技 att7022eu-程序员宅基地
文章浏览阅读1.7k次。书签栏通讯 s7-1200与s7-200smart通讯-工业支持中心-西门子中国IO_deviceS7-1200PROFINET通信ET 200SP 安装视频 - ID: 95886218 - Industry Support Siemens云平台接入在线文档 - 低代码开发嵌入式设备 | 物一世 WareExpress在linux下使用c语言实现MQTT通信(一.MQTT原理介绍及流程图)_qq_44041062的博客-程序员宅基地C mqtt_百度搜索开发快M_拾度智能科技 att7022eu
国家取消职称英语与计算机,全国职称英语考试取消-程序员宅基地
文章浏览阅读1.6k次。职称英语全称为全国专业技术人员职称英语等级考试,是由国家人事部组织实施的一项国家级外语考试。1.概述全国专业技术人员职称英语等级考试是由人力资源和社会保障部组织实施的一项外语考试,它根据英语在不同专业领域活动中的应用特点,结合专业技术人员掌握和应用英语的实际情况,对申报不同级别职称的专业技术人员的英语水平提出了不同的要求。该考试根据专业技术人员使用英语的实际情况,把考试的重点放在了阅读理解上面。全..._全国专业技术人员职称英语等级考试 北京 取消
where里能用max吗_网络里能找到真爱吗?-程序员宅基地
文章浏览阅读42次。恋爱指导篇 知心的小爱“真爱”是一个永不过时的话题,古代的人找对象,靠的是媒妁之言,父母定婚姻。现代的人靠的是相亲,自由恋爱,按理找一个喜欢的人结婚会很幸福,近几年反而离率更高了。古代人认识的人少,交流工具少,最多信鸽传书,信物传情。现代要认识一个人很容易了,最初是电话信息联系。前几年是qq,微信摇一摇,近两年是抖音,快手随便找一找。虽然找对象,寻伴侣更方便了,为何大部分人还是感觉更迷茫,不快乐...
刷题记录第八十天-修剪二叉搜索树-程序员宅基地
文章浏览阅读109次。【代码】刷题记录第八十天-修剪二叉搜索树。
dcm4che,WADO相关-程序员宅基地
文章浏览阅读248次。关于 dcm4che WADO WADO:Web Access to DICOM Objects dcm4che 是一个为医疗保健企业的开源应用程序和工具集合。这些应用程序已经开发了Java编程语言的性能和便携性,在JDK 1.6及更高版本支持部署。在dcm4che项目的核心是一个强大的执行DICOM标准的。该dcm4che-1.x和dcm4che-2.X DICOM Tool..._dcm4che实现wado服务
linux查看zk日志,14.1 zookeeper日志查看-程序员宅基地
文章浏览阅读2.2k次。zookeeper服务器会产生三类日志:事务日志、快照日志和log4j日志。在zookeeper默认配置文件zoo.cfg(可以修改文件名)中有一个配置项dataDir,该配置项用于配置zookeeper快照日志和事务日志的存储地址。在官方提供的默认参考配置文件zoo_sample.cfg中,只有dataDir配置项。其实在实际应用中,还可以为事务日志专门配置存储地址,配置项名称为dataLogD..._linux查看zookeeper日志