监督式机器学习与无监督式机器学习-程序员宅基地
监督式机器学习
监督式机器学习是指数据集中的每条记录都包含标签或标志的问题类型。
请考虑下表,其中包含有关最高温度、最低温度和最大振动的信息。
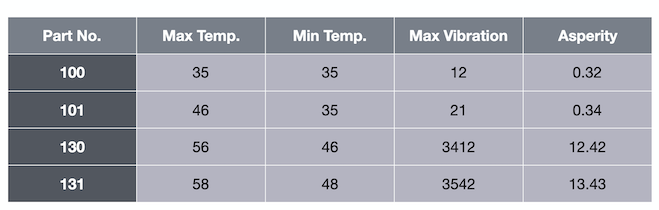
最后一列 asperity 是标签。给定温度和振动数据,我们想要预测粗糙度。这是一个带标签的数据集。
使用这个包含标签的数据集,我们可以训练一种算法来预测未标记数据的未来。你把它拟合到你的算法中,算法现在会预测这个数据的标签。这称为监督学习。回归和分类是监督学习的两种类型。
回归
必须预测连续值的用例类型称为回归。例如,如果我们向算法传递值 35、35 和 12,则预测粗糙度的值为 0.32。
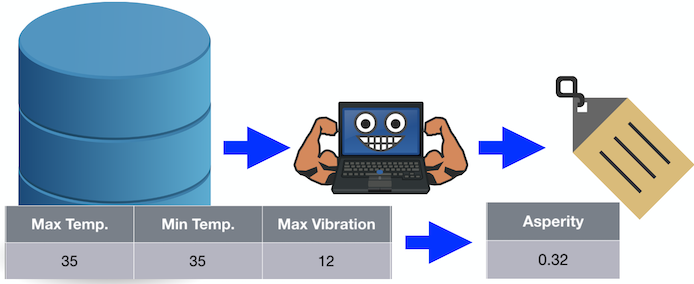
分类
输出为二进制值或至少是离散值而不是连续值的用例类型称为分类。换句话说,该算法不预测数字,而是预测类变量。
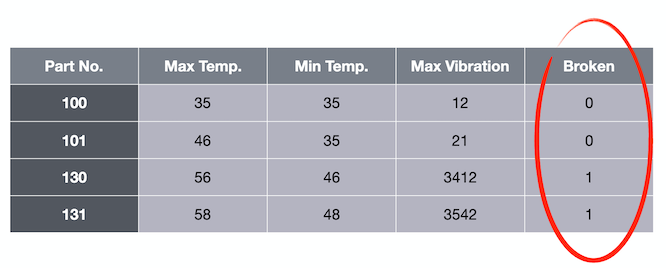
例如,如果我们将值 35、35 和 12 传递给算法,则预测值 0 表示损坏。

如果只有两个类,则称为二元分类。如果有两个以上的类,则具有多类分类。
无监督学习
无监督机器学习是指数据集中没有记录包含任何标签或标志的问题类型。聚类是一种无监督机器学习。
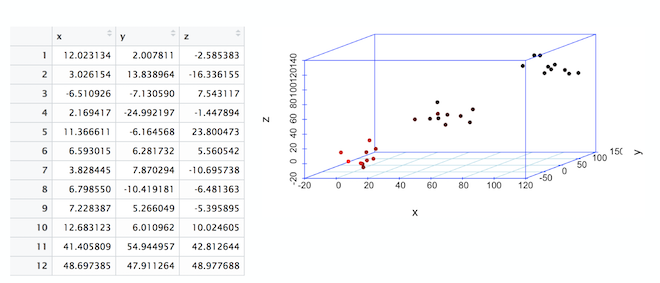
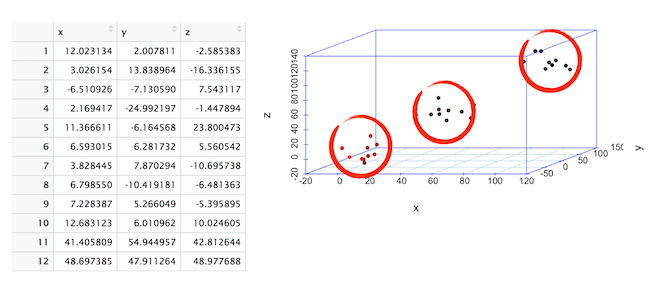
聚类
在前面显示的 3 维图中,请注意 3 个数据簇或云。仅通过绘制表格,我们就可以看到数据以三个聚类为中心。此过程称为聚类分析。
构建模型
机器学习模型是指使用以前看到的数据构建的数学配置,并设置为以先前计算的一定程度的精度预测新数据。
以下是从头开始构建模型时迭代执行的步骤序列。
-
数据探索
-
数据预处理
-
拆分数据以进行训练和测试
-
准备分类模型
-
使用管道组装所有这些步骤
-
训练模型
-
对模型运行预测
-
评估和可视化模型性能
使用 Python 和 scikit-learn 生成和测试第一个机器学习模型中介绍了生成模型的更详细的实践方法。
管道
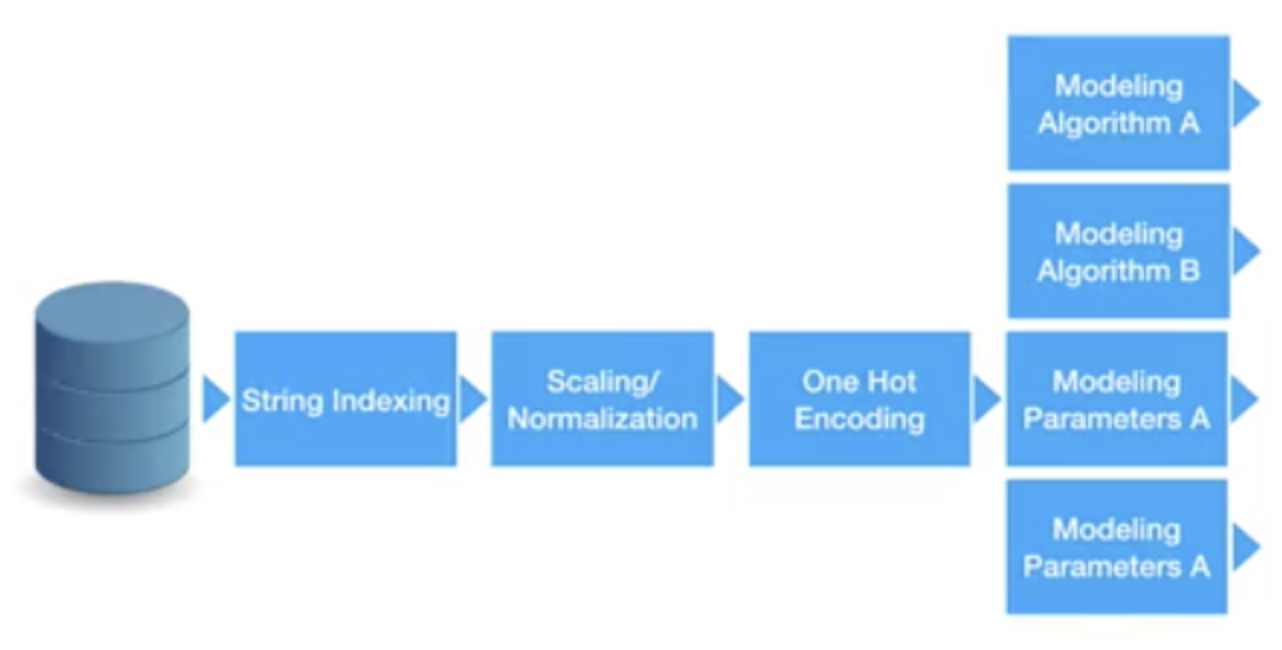
管道是在机器学习流中设计数据处理的一个非常方便的过程。数据预处理是一个繁琐的步骤,每次训练开始之前都必须对数据应用,无论将应用哪种算法。下图显示了每次在数据建模开始之前应用的典型预处理步骤序列。

这个想法是,在使用管道时,您可以保留预处理,只需切换不同的建模算法或建模算法的不同参数集即可。总体思路是,您可以将整个数据处理流程融合到一个管道中,并且该管道可以在下游使用。
与机器学习算法类似,管道具有称为拟合、评估和评分的方法。基本上,fit 开始训练,score 返回预测值。

交叉验证是使用管道的最大优势之一。它是指使用同一管道更改或调整多个超参数的过程,从而加速算法的优化。有几个超参数可以调整为性能更好的模型。与这些主题相关的详细信息将在以后的文章中介绍。
总结
本教程提供了机器学习的一些基本概念。它提供了一种实用的方法来理解必要的概念,以帮助您入门。
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取


人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取


智能推荐
Xwiki使用说明书_xwiki使用教程-程序员宅基地
文章浏览阅读7.1k次。XWIKI使用说明书 2015-05-05 目录1 用户管理... 21.1 添加用户... 21.2 用户分组... 31.3 用户权限... 41.3.1 wiki管理权限... 41.3.2 空间权限_xwiki使用教程
Qt删除,复制当前路径下所有文件(夹)_qfile::remove文件夹-程序员宅基地
文章浏览阅读1.2k次,点赞4次,收藏6次。Qt删除路径下所有文件,复制路径下所有文件方法的封装.//删除当前文件路径下的文件bool KQProductHelper::RemoveFiles(QString sfilePath){ if(sfilePath.isEmpty()) return false; QFileInfo fileinfo(sfilePath); QString bas..._qfile::remove文件夹
真·simulink车辆仿真基础教程-这玩意真不难:仿真基础知识(1)_真simulink车辆仿真基础教程-程序员宅基地
文章浏览阅读1.1k次,点赞25次,收藏29次。汽车动力性概括来讲,是指汽车在良好路面上直线行驶时,由汽车受到的纵向外力决定、所能达到的平均行驶速度。通常用最高车速、爬坡能力、加速时间表征。_真simulink车辆仿真基础教程
Swagger2总结(Swagger2引入、Spring-Swagger2整合、Swagger2常用注解与插件)-程序员宅基地
文章浏览阅读2.4k次,点赞2次,收藏12次。Swagger2引入、Spring-Swagger2整合、Swagger2常用注解与插件_swagger2
JVM原理讲解和调优_jvm原理及性能调优-程序员宅基地
文章浏览阅读881次。一、什么是JVMJVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。一般的高级语言如果要在不同的平台上运行,至少需要编译成不同的目标代码。而引入Java语言虚拟机后,Java_jvm原理及性能调优
社交网络分析重要概念简介、相关资料和前沿研究(持续更新ing...)_social network的bei 和ei-程序员宅基地
文章浏览阅读804次。社交网络分析重要概念简介、相关资料和前沿研究_social network的bei 和ei
随便推点
PYTHON常用库简介_python常用库介绍-程序员宅基地
文章浏览阅读8.3k次,点赞6次,收藏80次。Python科学计算基础库:Numpy,Pandas,Scipy,Matplotlib1.NumPy支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库,线性代数,傅里叶变换和随机数功能底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,效率远高于纯Python代码。2.PandasPandas是一个强大的基于Numpy分析结构化数据的工具集;Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Micros_python常用库介绍
Anaconda创建Pytorch虚拟环境(排坑详细)_anaconda创建pytorch环境-程序员宅基地
文章浏览阅读5.9w次,点赞150次,收藏1.4k次。利用conda指令搭建Pytorch环境,并在Pytorch环境中安装GPU版Pytorch相关包。_anaconda创建pytorch环境
Linux: 磁盘状态观察命令lsblk、blkid-程序员宅基地
文章浏览阅读955次,点赞12次,收藏32次。有时我们在磁盘规划前会想要确定一下当前系统的文件系统或磁盘分区情况。这时,就有几个命令可以供选择,通过本文,可以学习这些命令的使用。_lsblk
构造方法与方法的区别详解_构造方法和普通方法之间的区别-程序员宅基地
文章浏览阅读5.7k次,点赞11次,收藏46次。结论!!!学生类当中虽然没有构造方法 但是测试代码当中Student对象也创建完成了。是因为当类中没有任何构造方法的时候系统默认构造一个无参数的构造方法构造方法和普通方法结构的区别如下:调用构造方法怎么调用呢?..._构造方法和普通方法之间的区别
高维数据惩罚回归方法:主成分回归PCR、岭回归、lasso、弹性网络elastic net分析基因数据...-程序员宅基地
文章浏览阅读199次。全文链接:http://tecdat.cn/?p=23378在本文中,我们将使用基因表达数据。这个数据集包含120个样本的200个基因的基因表达数据。这些数据来源于哺乳动物眼组织样本的微阵列实验(点击文末“阅读原文”获取完整代码数据)。相关视频1 介绍在本文中,我们将研究以下主题证明为什么低维预测模型在高维中会失败。进行主成分回归(PCR)。使用glmnet()进行岭回归、lasso 和弹性网el..._高维数据回归方法
中科数安 | 防泄密软件-程序员宅基地
文章浏览阅读419次,点赞16次,收藏3次。此外,中科数安防泄密软件还具有智能加密功能,可以识别散落在企业不同位置的机密文件,并对其强制加密,非核心数据不被过分加密,防止敏感内容泄漏。同时,它还支持离网办公,针对出差人员或网络故障等原因引起的客户端离网,用户可以发起离网审批,确保终端密文在出差过程中保持可用状态,不影响正常办公。它采用了多种加密机制和技术手段,确保企业数据的安全性、完整性和机密性。总之,中科数安防泄密软件是一种功能强大、技术先进的企业数据保护软件,可以有效地防止敏感数据的泄露和非法访问,保障企业的信息安全和业务连续性。