词频统计(tree).c
标签: c
词频统计(tree实现)
标签: c
词频统计(tree实现)
主要是读取文本,然后进行分词、词干提取、去停用词、计算词频,有界面,很实用
下载解压,运行文件夹中的exe就行,每次要查询的默认词语和打开文件的默认路径可以在config.ini中修改
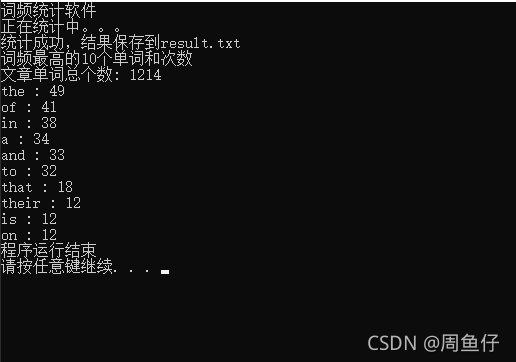
词频统计,统计英文文档中单词的数目并按字母排序输出



中英文词频统计软件,可以统计一批Word文档(.doc;.docx)、网页文件(.htm;.html)或文本文件(.txt)中所有中英文单词出现的总次数,或分别在各文件中出现的频率。统计结果可以按出现次数排序输出为Excel表格或Word...
@WordCount词频统计详解 WordCount主要分三部分: WordCountMain、WordCountMapper、WordcountReducer WordCountMain: 用来统筹map逻辑以及reducer逻辑 WordCountMapper: 切分,编写map逻辑使得<k1,v1>...
小文件输入——从控制台由用户输入到文件中,再对文件进行统计;2.支持命令行输入英文作品的文件名;3.支持命令行输入存储有英文作品文件的目录名,批量统计;4.从控制台读入英文单篇作品,重定向输入流。实现:1....

(有一些是安装好python电脑自带有哦)有一些会出现一种情况就是安装不了词云展示库有下面解决方法,需看请复制链接查看:https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud第三步:1.准备好你打算统计的文件...

使用UU在线工具的英文单词词频统计工具,可以一键统计所有单词的出现频率。
2001-2024年绿色环保词频统计数据,结合政府工作报告文本的词频分析法,可以 进行一系列深入而富有意义的研究。以下是四点可能的研究方向:绿色环保政策演变与趋势 分析:通过对历年政府工作报告中的绿色环保词汇...
机器学习之文本分类-从词频统计到神经网络(一)-附件资源

利用C++面向对象思想设计并编程实现一套中文文本分词和词频统计系统
该文件是一个基于python的词频统计源码,支持各种文件格式,实现对单文件词频统计及排序,也可以对文件夹下的多文件同时进行统计。关于文件编码在文件中有相关提示,也可以网上自查。
完整的词频统计MapReduce版本。基于Hadoop2.2.0,包含一个十万单词左右的测试文件。请参照 http://blog.csdn.net/zythy/article/details/17888439 获取详细解说。
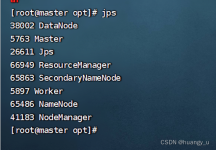


需要统计一本小说中某个人(主角)名字,或者某个关键词在文章中出现的次数,由于字数太多我们不可能人为的慢慢去计数,这时我们可以根据程序来自动获得其次数。...Python实现英文词频统计。简单高效实用字典几行代码
1.首先是这样写的: import jieba txt = open(D:/python程序/threekingdoms.txt,rt,encoding='utf-8').read() words=jieba.lcut(txt) counts={} for word in words: if len(word)==1: continue ...
【更新至2022】2001-2022上市公司年报文本分析与数字经济词频统计 (全套代码+数据) 更新时间:2023年5月5日 处理软件:Python 3.1 0 年度区间:2001-2022变量个数:64(详见样本数据——免费下载查阅) 年报数量...