下载 stanford-corenlp-full-2018-10-05.zip 提取码:isyg stanford-chinese-corenlp-2018-10-05-models.jar 提取码:uaed 下载完成后解压stanford-corenlp-full-2018-10-05.zip,并将stanford-chinese-corenlp-...
下载 stanford-corenlp-full-2018-10-05.zip 提取码:isyg stanford-chinese-corenlp-2018-10-05-models.jar 提取码:uaed 下载完成后解压stanford-corenlp-full-2018-10-05.zip,并将stanford-chinese-corenlp-...
遇到问题:/anaconda3/envs/tensorflow/bin/python3 /anaconda3/demo/demo/gcn_eca/gcn_model_tf/get_w2v_corpus.py Traceback (most recent call last): File “/anaconda3/demo/demo/gcn_eca/gcn_model_tf/get_w2v...
stanfordcorenlp报错: RuntimeError: Java not found. 具体如下所示: Traceback (most recent call last): File "D:\Users\user\AppData\Local\Anaconda3\lib\site-packages\IPython\core\interactiveshell....
代码就这样没法运行,我根据网上的教程一步步安装,但是出现了这样的问题,求帮忙,真的不知道问题应该怎么解决
目录 NLP分词工具集锦 分词实例用文件 ...(5)StanfordCoreNLP分词工具 (6)Hanlp分词工具 二、英文分词工具 1. NLTK: 2. SpaCy: 3. StanfordCoreNLP: NLP分词工具集锦 分词实例用文件...
1.pip install stanfordcorenlp2.去官网https://stanfordnlp.github.io/CoreNLP/下载两个东西,如图:一个是最新版的CoreNLP,一个是中文包。3.下载后解压前者,把中文包(.jar文件)放在前者解压后的文件夹。然后注意...
stanfordcorenlp 的parse()方法返回的是字符串,所以就算拿到了数据,也没发做判断分析。 唯一的解决方案是改源码 首先找到corenlp文件下的parse()方法: def parse(self, sentence): r_dict = self._request('...
StanfordCoreNLP是Stanford开发的关于自然语言处理的工具包,其包括分词、词性还原以及词性标注等很多功能。具体可参考官网:https://stanfordnlp.github.io/CoreNLP/。 这里主要是将其词性还原功能的简单使用。 二...
中文系小白使用StanfordCoreNLP学习笔记 本人中文系语言学方向大学生一枚,正在自学NLP。最近听说斯坦福nlp太挺火的。但是一搜stanfordnlp发现支持的语言里有繁体中文但没有简体,却发现stanfordcorenlp有简体中文...
安装了 'stanfordcorenlp',但模块导入不进去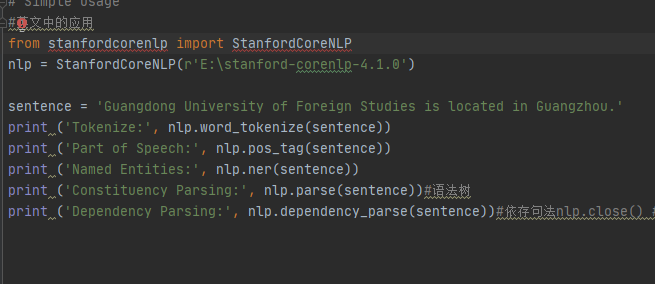
step1 :安装stanfordCorenlp 使用pip安装stanfordcorenlp: 简单使用命令:pip install stanfordcorenlp 选择USTC镜像安装(安装速度很快,毕竟国内镜像): pip install stanfordcorenlp -i ...
python 调用stanfordcorenlp 报错 nlp_st=StanfordCoreNLP(’/Users/kevin/stanford-nlp/stanford-corenlp-full-2018-10-05’,lang=“zh”) 出现一下错误, corenlp AccessDenied: psutil.AccessDenied (pid=20576) ...
stanfordcorenlp是一个用于自然语言处理的Java工具包,可以进行分词、词性标注、命名实体识别、句法分析等任务。而stanfordcorenlp python是一个Python接口,可以方便地使用stanfordcorenlp进行自然语言处理。
python+stanfordcorenlp简单应用 需要自己到官网下载对应的语言工具包 from stanfordcorenlp import StanfordCoreNLP def nlp_test(data): nlp = StanfordCoreNLP(r'D:\\Py\\stanford-corenlp-full-2018-02-27', ...
from stanfordcorenlp import StanfordCoreNLP nlp = StanfordCoreNLP(r'G:\JavaLibraries\stanford-corenlp-full-2018-02-27') sentence = 'Guangdong University of Foreign Studies is located in
这句代码是用来创建一个StanfordCoreNLP对象的实例,用于执行自然语言处理(Natural Language Processing,NLP)任务。StanfordCoreNLP是由斯坦福大学自然语言处理组开发的一款NLP工具包,该工具包提供了一系列的NLP...
Python中可以使用stanfordcorenlp库来连接Stanford CoreNLP服务,进行依存句法分析。 安装stanfordcorenlp库: ```bash pip install stanfordcorenlp ``` 使用代码: ```python import stanfordcorenlp # 连接...
至此,解决问题,啊这个问题困扰我一整天,终于解决了,这个linux自己太不了解了,以后要多学学。JAVA也要拾起来,而且debug的错误信息日志也很重要,不报错,就要想办法看怎么能看到log日志文件,来分析它的错误,...
运行python make_datafiles.py /path/to/cnn/stories /path/to/dailymail/stories,报上图所示错误。再尝试运行echo “Please tokenize this text.” | java edu.stanford.nlp.process.PTBTokenizer ...
您可以通过以下步骤安装stanfordcorenlp中文分词: 1. 下载stanfordcorenlp的最新版本,可以从官方网站或GitHub上下载。 2. 解压下载的文件,并将其放置在您的项目文件夹中。 3. 在您的项目中引入stanford-...
自己安装的Stanfordcorenlp显示第一行不能引入StanfordcoreNLP
这个错误通常是由于缺少StanfordCoreNLP库导致的。你需要先安装StanfordCoreNLP库才能解决这个问题。 你可以使用以下命令来安装StanfordCoreNLP库: ``` pip install stanfordcorenlp ``` 确保你已经正确安装了...
将 stanfordcorenlp 目录下的所有 jar 包路径添加到 CLASSPATH中的方法: 编辑 .bash_profile 文件: for file in `find /Users/mingliangwang/Documents/stanfordcorenlp -name "*.jar"` do # echo $file...
你可以通过以下步骤下载Stanford CoreNLP的中文模型: ... ... 4. 下载完毕后,解压缩文件,你将得到一个名为“stanford-chinese-corenlp-xxx-models.jar”的文件。 其中,xxx代表的是Stanford CoreNLP的版本号。...
1. Stanford CoreNLP介绍 转载于:https://www.cnblogs.com/yspworld/p/10625324.html
Stanford CoreNLP 是一个自然语言处理工具包,可以生成句法树。句法树是一种树形结构,用于表示句子中单词之间的语法关系。Stanford CoreNLP 可以通过分析句子中的词性、句法和语义信息,生成句法树。...
这是我在JDK1.9版本下运行斯坦福自然语言处理工具处理中文文本时,遇到问题的解决步骤: 首先,官网下载stanford-corenlp-full-2017-06-09压缩包并解压 其次,下载stanford-corenlp-3.8.0-models-chinese.jar放到...
from stanfordcorenlp import StanfordCoreNLP # 启动StanfordCoreNLP模型 nlp = StanfordCoreNLP(r'stanford-corenlp-full-2018-10-05') # 加载停用词 with open('stopwords.txt', 'r') as f: stopwords = set(f...
这个错误通常是因为StanfordCoreNLP的版本不兼容导致的。请确保你使用的StanfordCoreNLP版本与你的代码兼容。你可以尝试从Stanford CoreNLP的官方网站下载最新版本并更新你的代码。此外,你也可以检查你的代码中是否...