”spark“ 的搜索结果
Spark系列之SparkSubmit提交任务到YARN
数据分析_基于Spark的外卖大数据平台分析系统实现
数据分析_基于Spark实现对全国历史气象数据进行分析

一、SparkSQL相关 1.在执行insert 语句时报错,堆栈信息为:FileSystem closed。常常出现在ThriftServer里面。 原因:由于hadoop FileSystem.get 获得的FileSystem会从缓存加载...2.在执行Spark过程中抛出:Failed t
注意:Spark2.4.0依赖Scala2.11环境,Spark3.0.0依赖Scala2.12环境,这里适用2.4.0和3.0.0两个版本。(img-yT2SoQn2-1714918297543)](img-1QeQN7AV-1714918297544)](img-aU34W4KZ-1714918297544)]五、HDFS上传Spark ...
互联网行业分析,数据源于前程无忧招聘网站,数据分析基于spark平台,数据大屏基于echarts 数据源 各个城市的精度data/BaiduMap_cityCenter.txt来源于百度地图开放平台,crawler/cityInfo.py含爬取前程无忧各个城市...

该文件为Spark编程基础所用到的数据集,里面为一个txt文件
所以低效率的文件存储格式就像是一个赖媳妇,家里被管的一塌糊涂,东西越多越脏乱差,高效率的文件存储格式就是勤快且聪明的媳妇,一切都管的井然有序,取东西方便,放东西也容易,还会根据不同的物品特征进行摆放,...
spark安装&部署过程
Standalone 模式是 Spark 自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone 模式是真实地在多个机器之间搭建 Spark 集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大...
林子雨 VirtualBox + Ubuntu[linux] 配置 java、hadoop、Spark、pyspark流程
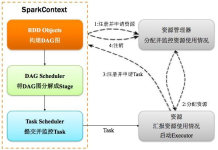
什么是Spark Spark特点 Spark运行模式 Spark编写代码 SparkCore 什么是RDD RDD的主要属性 RDD的算子分为两类: Rdd数据持久化什么作用? cache和Checkpoint的区别 什么是宽窄依赖 什么是DAG DAG边界 ...
自行查看
一、环境准备。
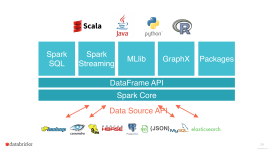
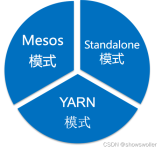
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器...
大数据 hadoop spark hbase ambari全套视频教程(购买的付费视频)
一、面试题Spark通常来说,Spark与MapReduce相比,Spark运行效率更高。请说明效率更高来源于Spark内置的哪些机制?hadoop和spark使用场景?spark如何保证...


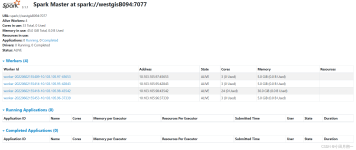
spark任务运行后,会将Driver所在机器绑定到4040端口,提供当前任务的监控页面。 此端口号默认为4040,展示信息如下: 调度器阶段和任务列表 RDD大小和内存使用情况 环境信息 正在运行的executors的信息 ...
推荐文章
- linux查看系统编码和修改系统编码的方法_linux 机器编码设置-程序员宅基地
- 企业微信小程序_小程序开发工具及真机调试_host配置及代理_微信开发者工具 本地代理-程序员宅基地
- 详解C语言自定义类型——结构体struct_struct结构体定义和声明-程序员宅基地
- kettle-基本使用_kettle箭头-程序员宅基地
- python输入两个数值区间若能合并区间_【python-leetcode57-区间合并】插入区间-程序员宅基地
- IDM免费安装注册使用,两步注册成功_idm注册-程序员宅基地
- SM4国密算法原理及python代码实现_根据sm4_s计算sm4_sbox_t-程序员宅基地
- DMA映射 dma_addr_t-程序员宅基地
- XSS跨站脚本攻击漏洞_小明是公司的开发工程师,发现公司网站存在xss漏洞,通过修改javascript代码进-程序员宅基地
- 软件体系结构_采用结构化技术开发的软件是否具有体系结构?-程序员宅基地