”spark“ 的搜索结果
spark
标签: JupyterNotebook
适用于Python的课程笔记本和适用于大数据的Spark 课程幻灯片:Python和大数据的火花 Spark DataFrames Spark DataFrames部分介绍 Spark DataFrame基础 Spark DataFrame操作 分组和汇总功能 缺失数据 日期和时间戳 ...
Hive 是将 SQL 转为 MapReduce。SparkSQL 可以理解成是将 SQL 解析成:“RDD + 优化” 再执行在学习Spark SQL前,需要了解数据分类。

sparkcore sparksql sparkstreaming structedstreming
搭建spark集群。
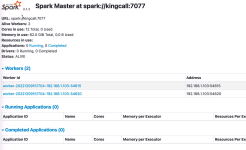
按回车键提交Spark作业后,观察Spark集群管理界面,其中“Running Applications”列表表示当前Spark集群正在计算的作业,执行几秒后,刷新界面,在Completed Applications表单下,可以看到当前应用执行完毕,返回...
目录一、Spark概述(1)概述(2)Spark整体架构(3)Spark特性(4)Spark与MR(5)Spark Streaming与Storm(6)Spark SQL与Hive二、Spark基本原理(1)Spark Core(2)Spark SQL(3)Spark Streaming(4)Spark基本...
部署Spark集群大体上分为两种模式:单机模式与集群模式大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。
从 Hive/Spark SQL 等最原始、最普及的 SQL 查询引擎,到 Kylin/ClickHouse 等 OLAP 引擎,再到流式的 Flink SQL/Kafka SQL,大数据的各条技术栈,都在或多或少地往 SQL 方向靠拢。缺乏对 SQL 的支持会让自身的技术...
解压文件包进入Spark安装目录的/bin目录,使用SparkPi计算Pi的值如果执行时输出非常多的运行日志信息,输出结果找不到,就使用grep命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出...
Spark On YARN模式的搭建比较简单,仅需要在YARN集群上的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。2)Spark中引入的RDD是分布在多个计算节点上的只读对象集合,这些集合是弹性的...
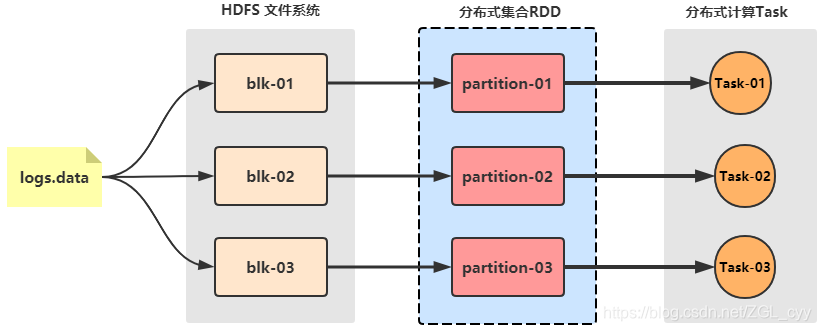
park为了解决以往分布式计算框架存在的一些问题(重复计算、资源共享、系统组合),提出了一个分布式数据集的抽象数据模型:RDD(Resilient Distributed Datasets)弹性分布式数据集。
Spark系列之Spark启动与基础使用
进入 /opt/software/ 查看是否导入scala、spark包(刚开始就导入包了,这里直接查看)然后进行文件的托拽到(/opt/software)目录下,也可以复制哦(可以两个包一起导入)(2)进入 /opt/software/ 查看是否导入...
cogroup:对多个(2~4)RDD 中的 KV 元素,每个 RDD 中相同 key 中的元素分别聚合成一个集合。与 reduceByKey 不同的是:reduceByKey 针对一个 RDD 中相同的 key 进行合并。而cogroup 针对多个 RDD 中相同的 key 的...
首先来聊聊什么是Spark?为什么现在那么多人都用Spark? Spark简介: Spark是一种通用的大数据计算框架,是基于**RDD(弹性分布式数据集)**的一种计算模型。那到底是什么呢?可能很多人还不是太理解,通俗讲就是可以...

进入解压后的Spark安装目录的/conf目录下,复制spark-env.sh.template文件并重命名为spark-env.sh。通过命令“jps”查看进程,如果既有Master进程又有Worker进程,那么说明Spark集群启动成功。进入Spark安装目录的/...
星火模型的langchain实现。测试已通过,希望有所帮助。实现如下: 自行跳转。

准备至少2台虚拟机,装好linux系统,我装的是Ubuntu20.04。
伪分布式安装参考:[root@cxy opt]# tar -zxf spark-3.2.1-bin-hadoop2.7.tgz -C /usr/local/[root@cxy opt]# cd /usr/local/spark-3.2.1-bin-hadoop2.7/conf/
在IDEA中运行spark程序


Hive On Spark 概述、安装配置、计算引擎更换、应用、异常解决
推荐文章
- centos7初始化mysql 5.7.9(源码安装)-程序员宅基地
- undefined reference to `cvHaarDetectObjects'()(人脸检测)_cvhaardetectobjects未定义-程序员宅基地
- 如何将参数传递给批处理文件?_批处理 传递参数-程序员宅基地
- C++的一些小总结 类 静态成员变量/函数 this指针_c++ class 静态指针函数-程序员宅基地
- springboot小区物业管理系统7ffeo[独有源码]如何选择高质量的计算机毕业设计_小区物业管理系统er图-程序员宅基地
- mac-gradle的安装和配置,掌握这些知识点再也不怕面试通不过_mac gradle配置-程序员宅基地
- 2032:【例4.18】分解质因数(信奥一本通)-程序员宅基地
- html怎么设置默认状态,网页中如何设置默认图片?方式介绍-程序员宅基地
- milp的matlab的案例代码_matlab30个案例分析案例5代码-程序员宅基地
- html实现/ 简约好看、美观大方的个人导航页源码/开源个人主页html源码_个人导航html-程序员宅基地