无
”python网络爬虫第三方库“ 的搜索结果
Python语言的应用场景可谓是十分全面,比如后端开发、网络爬虫、人工智能、数据分析,之所以应用场景这么广泛,其原因在于丰富的第三方库,那么适用于网络爬虫的第三方库有哪些呢?
用 python编写的爬虫项目集合
我相信很多人跟我都有相同的经历:想在网上找点资源,却因为种种原因而得不到。不要急,看完这篇文章,我想你应该知道该怎么做了。...本文我将给大家分享目前做爬虫所涉及的 Python 库,总会一款是你的最爱。
几乎覆盖信息技术所有领域,下面简单介绍下数据分析与可视化、网络爬虫、自动化、WEB开发、机器学习常用的一些第三方库。有了这些库,我们就不可以不用造轮子了。 一、数据分析和可视化 这对于一些大公司来说,...
Python语言的应用场景可谓是十分全面,比如后端开发、网络爬虫、人工智能、数据分析,之所以应用场景这么广泛,其原因在于丰富的第三方库,那么适用于网络爬虫的第三方库有哪些呢?RoboBrowser:一个简单的、极具...
本书共8章,涵盖的内容有Python语言的基本语法、Python常用IDE的使用、Python第三方模块的导入使用、Python爬虫常用模块、Scrapy爬虫、Beautiful Soup爬虫、Mechanize模拟浏览器和Selenium模拟浏览器。本书所有源...

下面简单介绍下网络爬虫、自动化、数据分析与可视化、WEB开发、机器学习和其他常用的一些第三方库,如果有你感兴趣的库,不妨去试试它的功能吧。1、网络爬虫•requests-对HTTP协议进行高度封装,支持非常丰富的链接...
Python语言的应用场景可谓是十分全面,比如后端开发、网络爬虫、人工智能、数据分析,之所以应用场景这么广泛,其原因在于丰富的第三方库,那么适用于网络爬虫的第三方库有哪些呢?
python对于爬虫的编写已经是相当的友好了,不过除了利用requests库或者scrapy框架之外,有一些库还需要我们知道,以便于我们更熟练、便捷的完成目标数据的爬取,接下来我就总结一下我认为在爬虫中常用的几个库。...
测验9: Python计算生态纵览 (第9周)单项选择题1、以下选项不是Python数据可视化方向第三方库...2、以下选项不是Python网络爬虫方向第三方库的是:A、Python-GooseB、ScrapyC、RequestsD、pyspider正确答案 APython-G...
Python网络爬虫
标签: python
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入...
Python3安装第三方爬虫库BeautifulSoup4,供大家参考,具体内容如下 在做Python3爬虫练习时,从网上找到了一段代码如下: ...回到之前的程序中,会发现IntelJ已经检测到第三方库BS4的安装,已自更新项
python爬虫库安装
python实现网络爬虫使用了第三方库beautifulsoup来解析网页文件,并且实现了cookie登录特定网站访问.zip
python对于爬虫的编写已经是相当的友好了,不过除了利用requests库或者scrapy框架之外,有一些库还需要我们知道,以便于我们更熟练、便捷的完成目标数据的爬取,接下来我就总结一下我认为在爬虫中常用的几个库。...
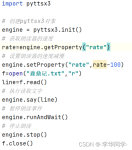
原博文2018-10-23 09:31 −这个列表包含与网页抓取和数据处理的Python库 网络 通用 urllib -网络库(stdlib)。 requests -网络库。 grab – 网络库(基于pycurl)。 pycurl – 网络库(绑定libcurl)。 urllib3 – ...
Python安装第三方库的4种方法1、使用pip大多数库都可以通过pip安装,安装方法为,在命令行窗口输入:pip install libNamelibName — 为库名某些库通过pip安装不了,可能是因为没有打包上传到pypi中,可以下载安装包...

Python第三方库matplotlib(2D绘图库)入门与进阶 Python第三方库wordcloud(词云)快速入门与进阶 Python第三方库jieba(中文分词)入门与进阶(官方文档)) Python第三方库SnowNLP(Simplified Chinese Text ...
Python第三方库安装——使用vscode、pycharm安装Python第三方库

python爬虫常用第三方库 这个列表包含与网页抓取和数据处理的Python库 网络 通用 urllib-网络库(stdlib)。 requests-网络库。 grab– 网络库(基于pycurl)。 pycurl– 网络库(绑定libcurl)。 urllib3...
在使用Python的过程中,势必会涉及到许多第三方库。但是怎么下载这些第三方库呢? 这里以如何手动安装为主。 方法一: 在命令提示符中输入: pip install + 需要安装的库名,即可下载安装。 这是一个比较官方的...
安装第三方模块及使用

python爬虫资源抓取--urllib/requests/requests-html、正则表达式、数据解析-Beautiful Soup/lxml/selectolax、自动化爬虫--selenium、爬虫框架--Scrapy/pyspider、模拟登录与验证码识别、autoscraper
网络站点爬取爬取网络站点的库Scrapy – 一个快速高级的屏幕爬取及网页采集框架。cola – 一个分布式爬虫...MechanicalSoup – 用于自动和网络站点交互的 Python 库。portia – Scrapy 可视化爬取。pyspider – 一...
推荐文章
- 网络编程socket accept函数的理解_当在函数 'main' 中调用 'open_socket_accept'时.line: 8. con-程序员宅基地
- C#对象销毁_c# 销毁对象及其所有引用-程序员宅基地
- 笔记-中项/高项学习期间的错题笔记1_大型设备可靠性测试可否拆解为几个部分进行测试-程序员宅基地
- html 保存成word (富文本编辑器导出内容成word)_wangeditor导出word-程序员宅基地
- 认识YOLOv5模型结构目录_yolo的框架在哪个文件-程序员宅基地
- jeecg-boot安装和使用(入门)_jeecgboot-程序员宅基地
- 转载:不是所有DDR3都可以用Fly by结构_ddr3 fly_by拓扑之应用实例-程序员宅基地
- pads铺铜不能开启drp_PADS中常见问题解决方案-程序员宅基地
- android oppo 权限,OPPO Reno可尝鲜Android Q:教程如下-程序员宅基地
- MYGUI/CEGUI中文输入的问题(3)-程序员宅基地