map和reduce是hadoop的核心功能,hadoop正是通过多个map和reduce的并行运行来实现任务的分布式并行计算,从这个观点来看,如果将map和reduce的数量设置为1,那么用户的任务就没有并行执行,但是map和reduce的数量也...
”map和reduce“ 的搜索结果
本人搭建了hadoop的开发环境,一个namenode, 两个datanode,写了一个wordcount的程序,能成功执行,那么问题来了,怎么查看map,和reduce的个数,又怎么人为的控制map个reduce的个数。
map()方法和reduce()方法的使用JS高阶函数map()reduce() ~~ JS高阶函数 在javascript中有很多处理数组的高阶函数,如map(),reduce(),sort(),filter()等,本文将介绍map/reduce的使用。 map() 举例:1.如果...
map map() 方法:原数组中的每个元素调用一个指定方法后,返回返回值组成的新数组。 arr.map(function) 例子: 有一个数组x=[1, 2, 3, 4, 5, 6, 7, 8, 9],求x^2 function pow(x){ //定义一个平方函数 ...
合理设置 Map 及 Reduce 数 1)通常情况下,作业会通过 input 的目录产生一个或者多个 map 任务。 主要的决定因素有:input 的文件总个数,input 的文件大小,集群设置的文件块大小。 2)是不是 map 数越多越...
主要介绍了Python lambda表达式filter、map、reduce函数用法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
转载http://my.oschina.net/Chanthon/blog/150500map和reduce是hadoop的核心功能,hadoop正是通过多个map和reduce的并行运行来实现任务的分布式并行计算,从这个观点来看,如果将map和reduce的数量设置为1,那么用户...
1. 控制hive任务中的map数和reduce数 map数量 1.多少map数量合适: 遵循两个原则: 使大数据量利用合适的map数;使单个map任务处理合适的数据量; 2.主要决定因素: hdfs block-- input的文件总个数,input的文件大小...
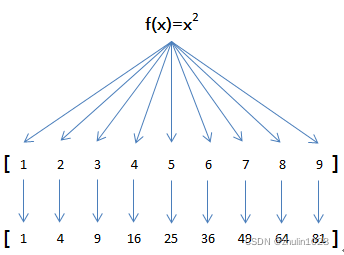
举例说明,比如我们有一个函数f(x)=x2,要把这个函数作用在一个数组[1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map实现如下:由于map()方法定义在JavaScript的Array中,我们调用Array的map()方法,传入我们自己的函数...
google三大核心技术之一,map reduce的论文
1.mapTask工作原理: 我们在写job任务时,指定一个FileInputFormat,设置一个路径,FileInputFormat类继承InputFormat(一个抽象接口),里面提供了一个抽象方法getSplits(),FileInputFormat中重写该方法的逻辑...
《Ranking and Semi-supervised Classification on Large Scale Graphs Using Map-Reduce》原文及译文
一、 控制hive任务中的map数: 1. 通常情况下,作业会通过input的目录产生一个或者多个map任务。 主要的决定因素有: input的文件总个数,input的文件大小,集群设置的文件块大小(目前为128M, 可在hive中...
map 首先我们来看看同步的map怎么写。 // 对数组所有元素乘2 [1,2,3].map(value => value * 2); // [2,4,6] 复制代码那如果map函数需要进行异步操作才能返回结果应该怎么写呢? [1, 2, 3].map(async value => ...
Mapper数据过大的话,会产生大量的小文件,过多的Mapper创建和初始化都会消耗大量的硬件资源 Mapper数太小,并发度过小,Job执行时间过长,无法充分利用分布式硬件资源 Mapper数量由什么决定?? (1)输入文件...
map-reduce-html 有用的Map Reduce功能集合,可深入了解HTML文档 程序和输出 字数 跑步 -- Using the provided shell script $ ./run.sh WordCount -- Running it on your own $ hadoop jar /usr/lib/hadoop-...
MapReduce运行时的mapTask和reduceTask 1 mapTask任务 1.1 mapTask & mapTask并行度 1.2 如何修改mapTask并行度 2 reduceTask任务 2.1 reduceTask & reduceTask并行度 2.2 如何设置reduceTask的并行度...
Python内建了map()和reduce()函数。 如果你读过Google的那篇大名鼎鼎的论文“MapReduce: Simplified Data Processing on Large Clusters”,你就能大概明白map/reduce的概念。 我们先看map。map()函数接收两个参数,...
文章目录一、如何调整任务map数量1、FileInputFormat的实现逻辑介绍1.1 getSplits方法实现2、CombineFileInputFormat的实现逻辑介绍2.1 ...5、map数量调整总结二、如何调整任务reduce数量三、关于map tas...
一、 实验环境 1个master节点, 16个slave节点: CPU:8GHZ ... 通过Hadoop自带的Terasort排序程序,测试不同的map task和reduce task数量,对Hadoop性能的影响。 实验数据由程序中的teragen程序生成,数据量为1
Python中有两个非常常见的内置函数:map()和reduce()函数。这两个函数都是应用于序列的处理函数,map()用于映射,reduce()用于归并。 本关目标就是让读者了解并掌握map()和reduce()函数的相关知识。 相关知识 map()...
根据输入文件估算Reduce的个数可能未必很准确,因为Reduce的输入是Map的输出,而Map的输出可能会比输入要小,所以最准确的数根据Map的输出估算Reduce的个数。比如有一个127M的文件,正常会用一个map去完成,但这个...
不要使用JavaScript内置的parseInt()函数,利用map和reduce操作实现一个string2int()函数: 练习:把一个字符串"13579"转换成13579,并且不使用parseInt和Number函数 ```javascrpt 'use strict'; function ...
目标就是每个map,reduce数据处理量要适当1.hive小文件很多,造成map个数很多,需要减少map个数 set mapred.max.split.size=100000000; set mapred.min.split.size.per.node=100000000; set mapred.min.split.size....
映射归约通用map-reduce执行器可以与火花执行器等横向执行器一起使用通用jar: gradle jar许可证:GPLv3
0、先说结论: 由于mapreduce中没有办法直接控制map数量,所以...控制map和reduce的参数 set mapred.max.split.size=256000000; -- 决定每个map处理的最大的文件大小,单位为B set mapred.min.split.size.per...
MapReduce在map和reduce阶段添加依赖包办法 通常在MapReduce编程过程,大部分都是使用Hadoop jar的方式运行MapReduce程序,但是在开发map或reduce阶段中会需要引入外部的包,Hadoop集群环境并没有这些依赖包。 ...
reduce为累计器,reduce虽然可以用来处理数据结构并进行数据结构的重组,但是规范来讲,一般不采取这样的做法,通常只是用reduce进行累计计算,返回一个对象或数值型的累积结果 map为迭代器,通常用于处理数据结构...
Python中有两个非常常见的内置函数:map()和reduce()函数。这两个函数都是应用于序列的处理函数,map()用于映射,reduce()用于归并。 本关目标就是让读者了解并掌握map()和reduce()函数的相关知识。 相关知识 map...
推荐文章
- Springboot——mybatis配置_springboot配置mybatis-程序员宅基地
- 计算机网络体系结构-程序员宅基地
- 韶音、南卡、Oladance开放式耳机值得买吗?多维度测评实力最强品牌-程序员宅基地
- bert简介_tensorflow 2.0+ 基于BERT的多标签文本分类-程序员宅基地
- jupyter notebook常用快捷键和语法_jupyter notebook怎么换行-程序员宅基地
- 教材编者,请多点儿“钻研”精神-程序员宅基地
- MySQL如何更改数据库名字_mysql update数据库名称-程序员宅基地
- windows上最好用的文件管理软件 Directory Opus_directory ops-程序员宅基地
- AWT图形界面设计编程——1.AWT容器_awt容器定义-程序员宅基地
- 一文看懂mybatis底层运行原理解析-程序员宅基地