Kafka是一种消息队列,主要用来处理大量数据状态下的消息队列,一般用来做日志的处理。既然是消息队列,那么Kafka也就拥有消息队列的相应的特性了
”kafk“ 的搜索结果
Kafka3.1部署、应用(Topic主题数据生产与消费)
附件是Linux系统中安装Kafka的教程,包含具体的操作步骤, 文件绿色安全,仅供学习交流使用,欢迎大家下载学习交流!
安装3.1 建立文件夹3.2 将压缩包放置到该文件夹下(可以使用xftp)3.3 修改配置文件3.4 启动3.4.1 启动zookeeper3.4.2 启动kafka4.测试4.1 创建topic4.2 创建生产者4.3 创建消费者5.JAVA连接kafka5.1 pom.xml5.2 ...
Kafka是Apache下的一个子项目,是一个高性能跨语言分布式发布/订阅消息队列系统,图展示了Kafka的相关术语以及之间的关系 上图一个topic配置了3个partition。Partition1有两个offset:0和1。Partition2有4个offs.....

kafka
kafka-map工具
标签: kafka
kafka-map是一个连接kafka的页面工具
kafka stream使用详解
继上一次教大家手把手安装kafka后,今天我们直接来到入门实操教程,也就是使用SpringBoot该怎么对接和使用kafka。当然,在一开始我们也会比较细致的介绍一下kafka本身。那么话不多说,马上开始今天的学习吧
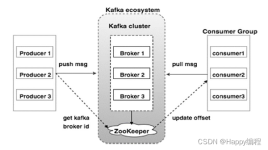
经过上述的讲解,我们不难知道Kafka的应用场景非常广泛,你可以只把他当MQ组件,也可以使用它进行日志传输或流处理。它的特点也非常鲜明,就是强大的吞吐量、扩展性和可靠性。当然它与传统MQ组件对比,它在复杂场景...
Kafka是将partition的数据写在磁盘的(消息日志),不过Kafka只允许追加写入(顺序访问),避免缓慢的随机 I/O 操作。 Kafka也不是partition一有数据就立马将数据写到磁盘上,它会先缓存一部分,等到足够多数据量或等待...
这里我们的配置是选择的是KRaft,因为Kafka官方已经计划在Kafak中移除Zookeeper。对于UI配置项没什么特别要说的,这里只是提一下,注意这里的docker-compose.yml中environment的写法,和上面的Kafka镜像中...
Apache Kafka是一个开源消息系统、一个开源分布式流平台,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目...
在本篇技术博文中,我们详细地教你如何安装kafka,还有它的可视化工具,中间也列举了一些异常以及它的处理方式,真正做到了手把手教学。那么安装教学就告一段落。在后面的学习中,我们将讲解他们的使用及运行原理,...
(一)、Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 (二)、Kafka 本质上是⼀个消息队列。与...
场景:在Spring Boot微服务集成Kafka客户端kafka-clients-3.0.0操作Kafka。使用kafka-clients的原生KafkaProducer操作Kafka生产者Producer。使用kafka-clients的原生KafkaConsumer操作Kafka的消费者Consumer。
kafka常用命令

记录:461 场景:在Spring Boot微服务集成spring-kafka-2.8.2操作Kafka集群。使用KafkaTemplate操作Kafka集群的生产者Producer。使用@KafkaListener操作Kafka集群的消费者Consumer。
早期,要监控Kafka集群我们可以使用Kafka Monitor以及Kafka Manager,但随着监控的功能要求、性能要求的提高,这些工具已经无法满足。Kafka Eagle是一款结合了目前大数据Kafka监控工具的特点,重新研发的一块开源...
场景:在Spring Boot微服务集成Kafka客户端spring-kafka-2.8.2操作Kafka。使用Spring封装的KafkaTemplate操作Kafka生产者Producer。使用Spring封装的@KafkaListener操作Kafka的消费者Consumer。

Prometheus监控kafka的三种方式:JMX监控kafka、kafka_exporter监控kafka、Kminion监控kafka。
实现序列化与反序列化,主要是以字节流的形式读取和写入数据,然后实现kafka的序列化与反序列化的方法,最后在生产者或消费者中设置key、value的序列化与反序列化的类。本分五部分,即简单的写数据到kafka、从topic...
推荐文章
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地
- Python 攻克移动开发失败!_beeware-程序员宅基地
- Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
- 元素三大等待-程序员宅基地
- Java软件工程师职位分析_java岗位分析-程序员宅基地
- Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
- 标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地