Hive beeline和Spark SQL兼容Hive – 配置 Hive beeline 上面安装后直接输入hive是CLI的操作方式,在后面可能会被舍弃掉,换用beeline方式去连接,因为目前使用CLI的人比较多,所以还暂未舍弃 1.打开hiveserver2的...
”beeline兼容hive“ 的搜索结果
从Hive出生就一直存在,但随着Hive功能的增强、BUG的修复及版本升级,Hive-cli结构的局限性已经跟不上Hive的发展,如果强行更改又不能满足向下兼容,于是就出现了全新的beeline命令行结构
cli 是hive连接hivesever的命令行工具,从hive出生就一直存在,但随着hive功能的增强、bug的修复、版本升级,hive-cli结构的局限性跟不上hive的发展,如果强行更改就不能满足向下兼容,就出现了全新的beeline命令行...
使用beeline工具连接Hive
Beeline Shell可以工作在嵌入式模式和远程模式,在嵌入式模式中,它运行一个嵌入式的Hive(类似于Hive CLI),在远程模式中,通过Thrift连接到一个单独的HiveServer2进程,从Hive 0.14开始,当Beel...
hive beeline客户端方式采用JDBC方式借助于Hive Thrift服务访问Hive数据仓库。 HiveThrift(HiveServer)是Hive中的组件之一,设计目的是为了实现跨语言轻量级访问Hive数据仓库,有Hiveserver和 Hiveserver2两...
从hive出生就一直存在,但随着hive功能的增强、bug的修复、版本升级,hive-cli结构的局限性跟不上hive的发展,如果强行更改就不能满足向下兼容,就出现了全新的beeline命令行结构,即就是hive-cli能做的事beeline都...
本文为自己翻译的译文,原文地址:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+ClientsHive官方使用手册——新Hive CLI(Beeline CLI)这个页面描述了HiveServer2支持的不同客户端。其它的...

作为数据仓库的工具,hive提供了两种ETL运行方式,分别是通过Hive 命令行和beeline客户端; 命令行方式即通过hive进入命令模式后通过执行不同的HQL命令得到对应的结果;相当于胖客户端模式,即客户机中需要安装JRE...


Hive Hive基本介绍 产生原因 方便对文件及数据的元数据进行管理,提供统一的元数据管理方式; 提供更加简单的方式来访问大规模的数据集,使用SQL语言进行数据分析。 介绍 Hive在使用过程中,是使用SQL语句来进行...
首先,我们在下载官方的hive的发行版,很可能会出现发行版中预编译的hive与我们目标平台的其他组件出现不兼容,例如小编就会经常遇到hive在读取hbase的时候出现这样或者那样的问题,当然也有很多处理和解决的办法,...
文章目录环境介绍下载、安装、配置TEZ测试hive on tez参考网址 环境介绍 组件 版本 hadoop 2.6.5 hive 2.3.6 tez 0.8.5 tez对hadoop版本是有要求的。tez 0.8及以上需要hadoop 2.6及以上。tez 0.9及...


本文关键字:Hive、远程连接、MetaStore、JDBC、SparkSQL。在进行开发时,我们通常需要能够在代码中访问Hive进行查询,此时我们要做一些配置和修改。第一种方式是直接开启一个hiveserver2的Hive服务端,用来提供执行...

切换Tez执行引擎后,hive启动以及HQL执行的日志较多,可参考前面第11步,将日志打印级别设为WARN或者ERROR。Tez介绍:https://www.infoq.cn/article/apache-tez-saha-murthy。3、hive.cli.tez.session.async:是否...
阿里巴巴开发工程师罗宇侠、阿里巴巴开发工程师方盛凯,在 Flink Forward Asia 2022 流批一体专场的分享。
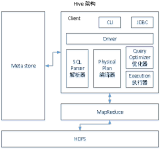
最近在研究hdfs,hive与ranger配合完成ACL访问控制,本文总结下遇到的问题。ranger-admin的安装部署与ranger的hdfs插件、hive插件的安装,官网有简单描述...




如何从命令提示符知道Hive和Hadoop版本?如何从命令提示符中找到我正在使用的Hive版本。 以下是详情 -我使用Putty连接到hive表并访问表中的记录。 所以我做的是 - 我打开Putty并在主机名中键入 - leo-ingesting.vip....

推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地