它主要涉及:分析规划和获取运动信息的处理、步态的模式识别和分析以及步态的转换过程,以及脑电图和关节位置、足部压力等不同模式的数据作为机器学习模型的输入,以提高步态规划的及时性、准确性和安全性。...
”Multimodal“ 的搜索结果
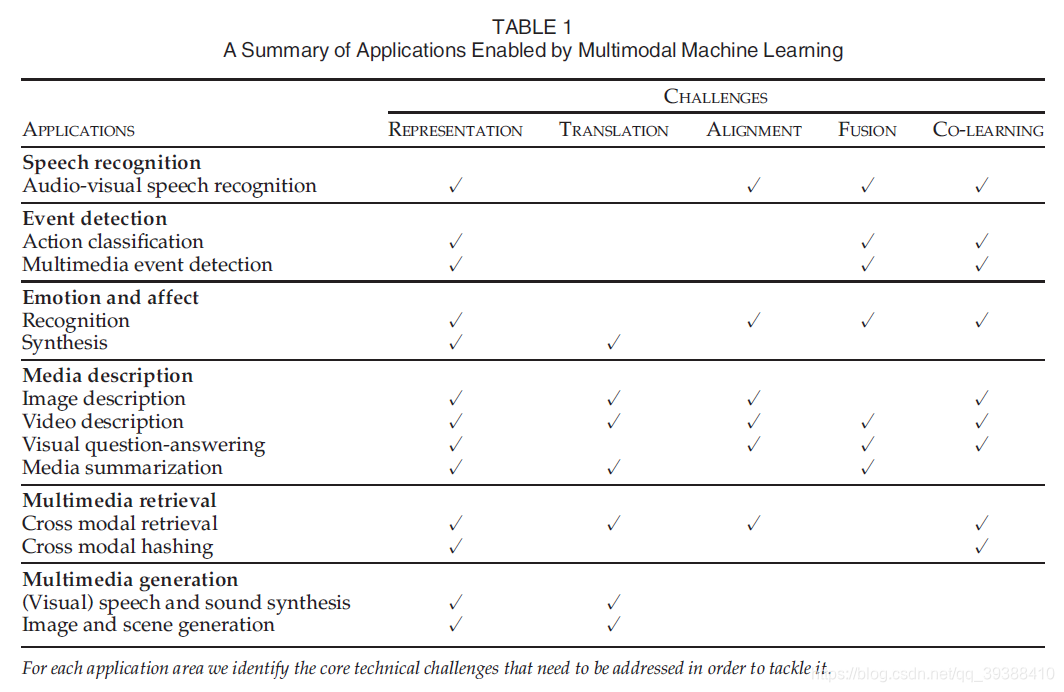
文章目录Multimodalmotivationproblem研究方向多模态表示学习 Multimodal Representation模态转化 Translation对齐 Alignment多模态融合 Multimodal Fusion\多源信息融合(Multi-source Information Fusion)\多...
【多模态大模型综述】 使用 gpt3.5 精细翻译,完美融合图片等内容 由微软7位华人研究员撰写,足足119页 它从目前已经完善的和还处于最前沿的两类多模态大模型研究方向出发,全面总结了五个具体研究主题: ...
cd multimodal/dataset ./download_data.sh 跑步训练 python mini_main.py --config configs/training_default.yaml 机器人数据集 动作数据集{50,4} contact数据集{50,50} \ depth_data数据集{50,128,128,1} ...
解决在实际医疗图像分析中多模态MRI脑肿瘤分割遇到的模态缺失问题
社交媒体平台是多模态信息交换的中心,包括文本、图像和视频,这使得机器很难理解与在线空间中的互动相关的信息或情绪。多模态大型语言模型(MLLMs)已成为应对这些挑战的一种很有前途的解决方案,但难以准确解释...
AI综述专栏 在科学研究中,从方法论上来讲,都应先见森林,再见树木。当前,人工智能科技迅猛发展,万木争荣,更应系统梳理脉络。为此,我们特别精选国内外优秀的综述论文,开辟“综述”专栏,敬请关注。...
Multimodal videoclassificationwithstacked contractiveautoencoders
【人工智能 | 多模态】几种常见的多模态任务
The Multimodal Emotion Recognition Challenge(MEC) is a part of the 2016 Chinese Conference on Pattern Recognition (CCPR).The goal of this competition is to compare multimedia processing and machine ...
由于每个单模态变换器的总变换器层数(Limg和Ltxt)现在不同,两个模态的单模态基础特征现在需要不同的层进行提取,而融合保留的剩余层数量保持不变。结论:我们提出了一种新型的模块化多模态融合框架,展现了高度的...
尽管LLM取得了成功,但由于可用的训练数据太少,它们往往难以在低资源语言上表现良好。这种简化在开源模型中尤其普遍。在这项工作中,我们探索训练LLaMA-2说阿姆哈拉语,阿姆哈拉语是一种全世界有5000多万人使用的...
Abstract—In this paper, we propose a multimodal search engine that combines visual and textual cues to retrieve items from a multimedia database aesthetically similar to the query. The goal of our ...
遵循我们的课程11-777 Multimodal Machine Learning ,2020秋季@ CMU。 关于文字游戏的NeurIPS 2020研讨会:当语言遇到游戏时。 ACL 2020多模态语言(过程)与语言和视觉研究进展研讨会。 ECCV 2020的多
文章指出现有的方法在将整个图像与相应方面对齐时存在局限性,因为图像的不同区域可能与同一句子中的不同方面相关,粗略的图像-方面对齐可能会引入视觉噪声。:开发了一个新颖的注意力模块,用于细粒度的图像-文本...
探索Awesome Foundation与Multimodal Models:构建未来智能的基石 项目地址:https://gitcode.com/SkalskiP/awesome-foundation-and-multimodal-models 该项目链接:...
title = "Integrating Multimodal Information in Large Pretrained Transformers", author = "Rahman, Wasifur and Hasan, Md Kamrul and Lee, Sangwu and Bagher Zadeh, AmirAli and Mao, Chengfeng and ...
具有区域的多模态大模型,除了整体图像理解之外,Groma 还擅长区域级任务,例如区域描述和视觉grounding。此类功能建立在本地化视觉标记化机制的基础上,其中图像输入被分解为感兴趣的区域,然后编码为区域标记。...
CMU-Multimodal SDK多模态数据库下载工具包的简单使用
多式联运代码和其他与 Multimodal 杂志主题相关的内容的 GitHub 区域结构体utilscripts/包括随机实用程序脚本(抓取文本、图像等)。 大多是相当骇人听闻的 bash; 没有用户界面/标志/花哨的东西imageanalysis/用于...
(*均等贡献) 如果您发现我们的工作对您的研究有用,请引用我们的论文: @inproceedings{tsai2019MULT, title={Multimodal Transformer for Unaligned Multimodal Language Sequences}, author={Tsai, Yao-Hung ...
探索未来多模态研究:FacebookResearch的Multimodal项目 项目地址:https://gitcode.com/facebookresearch/multimodal 在当今的数字化时代,多模态数据(如图像、文本和音频)的处理已经成为人工智能领域的焦点。...
探秘Multimodal Maestro:AI时代的多模态模型训练利器 项目地址:https://gitcode.com/roboflow/multimodal-maestro 项目简介 在AI领域,多模态学习已经成为研究热点,它涉及到图像、文本、语音等多种数据类型的融合...
首篇跨模态Transformer
多模式协作框架(MCOF)项目旨在为多模式交互开发新的协作框架,以减少“数字鸿沟”。
multimodal_fusion_project
基于多模递归神经网络的音频-视频语音识别,冯为江,管乃洋,关于人机交互接口的一些研究表明视觉信息可以提升语音识别准确率,尤其是在嘈杂环境中。由于深度学习在语音识别和图像识别方面均��
数据融合matlab代码使用深度和惯性传感器的深度多级多模式(M2)融合进行人体动作识别的数据集和代码(最新发表在IEEE传感器杂志上) 从链接下载数据集: ImageFolders_KinectV2Dataset文件夹具有与Kinect ...
该项目使用Python实现了多模式中间件协议。 它可用于连接同一台计算机或网络中的多模式组件。 多模式集线器和浏览器组件可用于管理组件网络。
推荐文章
- 如何用c语言写驱动程序,c – 如何启动自编写的驱动程序-程序员宅基地
- 常用的会话跟踪技术有哪些?_web开发中会话跟踪的方法有哪些-程序员宅基地
- php 判断二进制文件,PHP二进制判断文件类型-程序员宅基地
- 【Linux】Ubuntu20.04配置静态固定IP地址_ubuntu20.04配置静态ip-程序员宅基地
- Flutter 优秀实例项目_flutter项目案例-程序员宅基地
- 易语言 设置屏幕刷新率 源码_iQOO Z1智能手机屏幕测评报告 「Soomal」-程序员宅基地
- sql学习笔记(一)_show create table-程序员宅基地
- LAVA-M数据集的使用-程序员宅基地
- 静态HTML网页模板源码——仿男装女装购物商城(40页功能齐全)_html静态商城源代码-程序员宅基地
- GEE入门篇|图像分类(一):监督分类_gee分类-程序员宅基地