Spring Boot 整合 Elastricsearch + LogStash + Kibana-程序员宅基地
技术标签: java elasticsearch linux hadoop 分布式
以下文章来源方志朋的博客,回复”666“获面试宝典
为什么要用ELK
ELK实际上是三个工具,Elastricsearch + LogStash + Kibana,通过ELK,用来收集日志还有进行日志分析,最后通过可视化UI进行展示。一开始业务量比较小的时候,通过简单的SLF4J+Logger在服务器打印日志,通过grep进行简单查询,但是随着业务量增加,数据量也会不断增加,所以使用ELK可以进行大数量的日志收集和分析
简单画了一下架构图
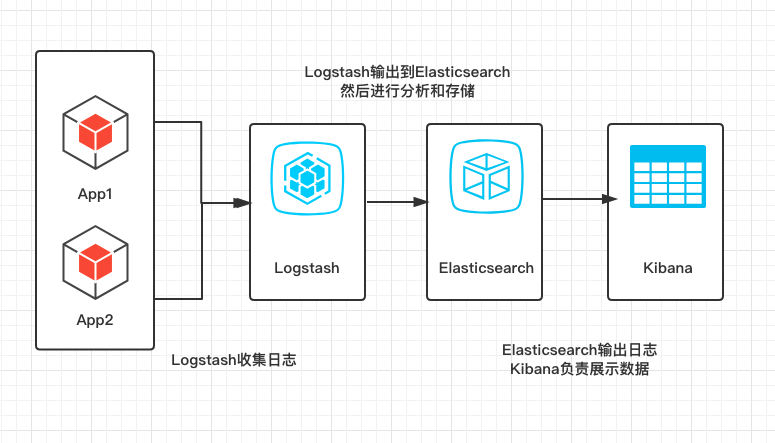
在环境配置中,主要介绍Mac和linux配置,windows系统大致相同,当然,前提是大家都安装了JDK1.8及以上版本~
[root@VM_234_23_centos ~]# java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)注意
高版本的ELK同样需要高版本的JDK支持,本文配置的ELK版本是6.0+,所以需要的JDK版本不小于1.8
ElasticSearch
Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
Mac安装和运行
安装:brew install elasticsearch
运行:elasticsearchlinux: 从Elasticsearch官方地址下载(也可以下载完,通过ftp之类的工具传上去),gz文件的话通过tar进行解压缩,然后进入bin目录下运行软件
[root@VM_234_23_centos app]# curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz
[root@VM_234_23_centos app]# tar -zxvf elasticsearch-6.2.4.tar.gz
[root@VM_234_23_centos app]# cd elasticsearch-6.2.4
[root@VM_234_23_centos elasticsearch-6.2.4]# ./bin/elasticsearch注意
在Linux机器上,运行elasticsearch需要一个新的用户组,文章最后有Elastic在linux安装的踩坑记录
Logstash
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(我们的存储库当然是 Elasticsearch。)-官方卖萌
「1. 软件安装」
Mac安装:
brew install logstashlinux安装:
[root@VM_234_23_centos app]# curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-6.3.2.tar.gz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 137M 100 137M 0 0 5849k 0 0:00:24 0:00:24 --:--:-- 6597k
[root@VM_234_23_centos app]# tar -zxvf logstash-6.3.2.tar.gz「2. 修改配置文件」
vim /etc/logstash.conf「conf文件,指定要使用的插件,和配置对应的elasticsearch的hosts」
input { stdin { } }
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}「3. 运行」
bin/logstash -f logstash.conf「4. 访问http://localhost:9600/」
{
"host": "=-=",
"version": "6.2.4",
"http_address": "127.0.0.1:9600",
"id": "5b47e81f-bdf8-48fc-9537-400107a13bd2",
"name": "=-=",
"build_date": "2018-04-12T22:29:17Z",
"build_sha": "a425a422e03087ac34ad6949f7c95ec6d27faf14",
"build_snapshot": false
}「在elasticsearch日志中,也能看到logstash正常加入的日志」
[2018-08-16T14:08:36,436][INFO ][o.e.c.m.MetaDataIndexTemplateService] [f2s1SD8] adding template [logstash] for index patterns [logstash-*]「看到这种返回值,表示已经成功安装和启动」
踩坑
在运行的那一步,有可能遇到内存分配错误
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c5330000, 986513408, 0) failed; error=’Cannot allocate memory’ (errno=12)这个错误很明显就是内存不足,由于个人购买的是腾讯云1G内存的服务器(如果是壕,请随意购买更高的配置=-=),已经运行了elasticsearch,导致logstash分配不到足够的内存,所以最后要修改一下jvm配置。
[root@VM_234_23_centos logstash-6.3.2]# cd config/
[root@VM_234_23_centos config]# ll
total 28
-rw-r--r-- 1 root root 1846 Jul 20 14:19 jvm.options
-rw-r--r-- 1 root root 4466 Jul 20 14:19 log4j2.properties
-rw-r--r-- 1 root root 8097 Jul 20 14:19 logstash.yml
-rw-r--r-- 1 root root 3244 Jul 20 14:19 pipelines.yml
-rw-r--r-- 1 root root 1696 Jul 20 14:19 startup.options
[root@VM_234_23_centos config]# vim jvm.options「将-Xms1g -Xmx1g修改为」
-Xms256m
-Xmx256m「然后就能正常启动了~~」
Kibana
「1. 软件安装」
Kibana 让您能够可视化 Elasticsearch 中的数据并操作 Elastic Stack,因此您可以在这里解开任何疑问:例如,为何会在凌晨 2:00 被传呼,雨水会对季度数据造成怎样的影响。(而且展示的图标十分酷炫)
Mac安装
brew install kibanalinux安装,官方下载地址:
https://www.elastic.co/downloads/kibana
[root@VM_234_23_centos app]# curl -L -O https://artifacts.elastic.co/downloads/kibana/kibana-6.3.2-linux-x86_64.tar.gz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 195M 0 271k 0 0 19235 0 2:57:54 0:00:14 2:57:40 26393「在这一步,有可能下载速度奇慢,所以我本地下载好之后,通过rz命令传输到服务器」
[root@VM_234_23_centos app]# rz
rz waiting to receive.
Starting zmodem transfer. Press Ctrl+C to cancel.
Transferring kibana-6.3.2-linux-x86_64.tar.gz...
100% 200519 KB 751 KB/sec 00:04:27 0 Errors
[root@VM_234_23_centos app]# tar -zxvf kibana-6.3.2-linux-x86_64.tar.gz「2. 修改配置」
修改 config/kibana.yml 配置文件,设置 elasticsearch.url 指向 Elasticsearch 实例。
如果跟我一样使用默认的配置,可以不需要修改该文件
「3. 启动」
[root@VM_234_23_centos kibana]# ./bin/kibana「4. 访问 http://localhost:5601/app/kibana#/home?_g=()」
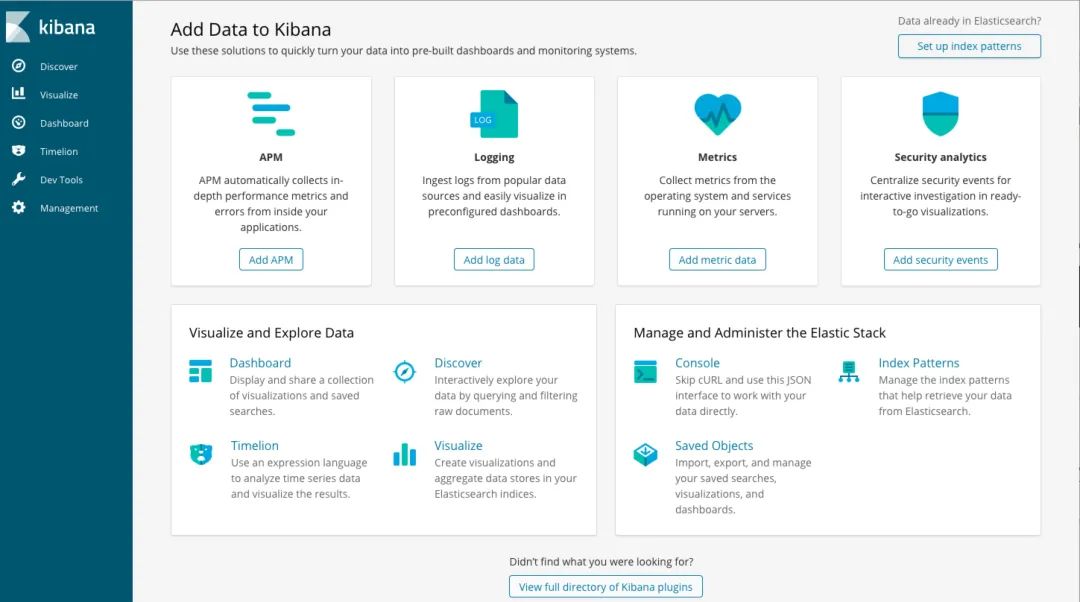
「界面显示了这么多功能,下面通过整合SLF4J+LogBack」
整合Spring+Logstash
「1. 修改logstash.conf后,重新启动logstash」
input {
# stdin { }
tcp {
# host:port就是上面appender中的 destination,
# 这里其实把logstash作为服务,开启9250端口接收logback发出的消息
host => "127.0.0.1" port => 9250 mode => "server" tags => ["tags"] codec => json_lines
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}「2. 在Java应用中引用依赖」
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.2</version>
</dependency>「3. 在Logback.xml中配置日志输出」
<!--日志导出的到 Logstash-->
<appender name="stash"
class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>localhost:9250</destination>
<!-- encoder必须配置,有多种可选 -->
<encoder charset="UTF-8"
class="net.logstash.logback.encoder.LogstashEncoder" >
<!-- "appname":"ye_test" 的作用是指定创建索引的名字时用,并且在生成的文档中会多了这个字段 -->
<customFields>{"appname":"ye_test"}</customFields>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="stash"/>
</root>「由于我在第一步骤中,没有指定对应的index,所以在服务启动的时候,日志采集器Logstash帮我自动创建了logstash-timestamp的index」
「4. 在kibana中添加index索引」
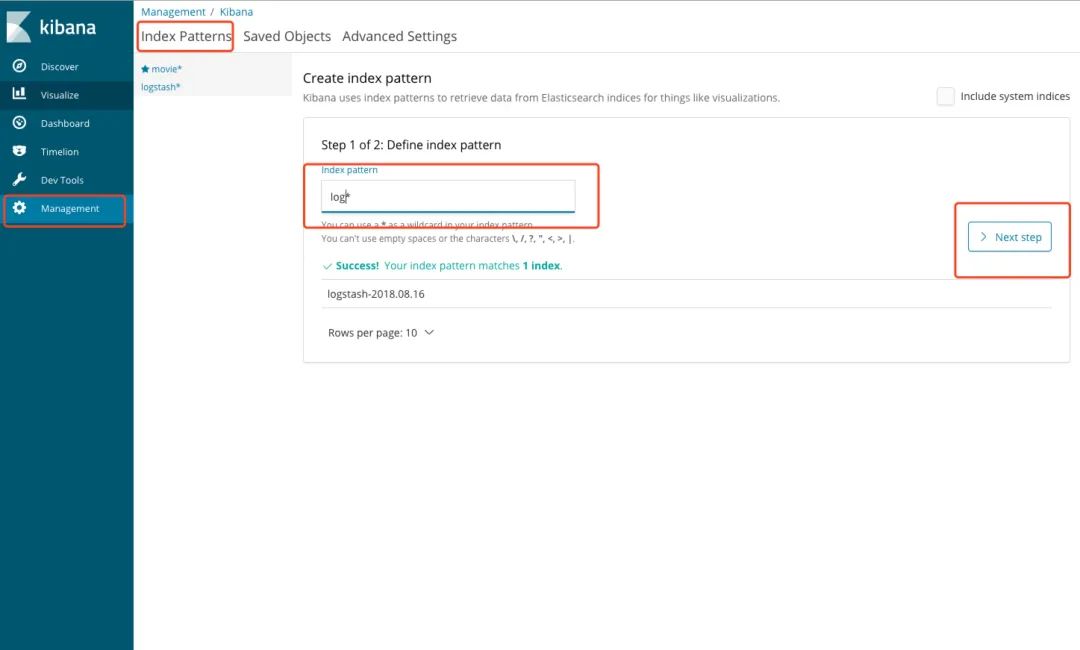
「5. 在左边discover中查看索引信息」
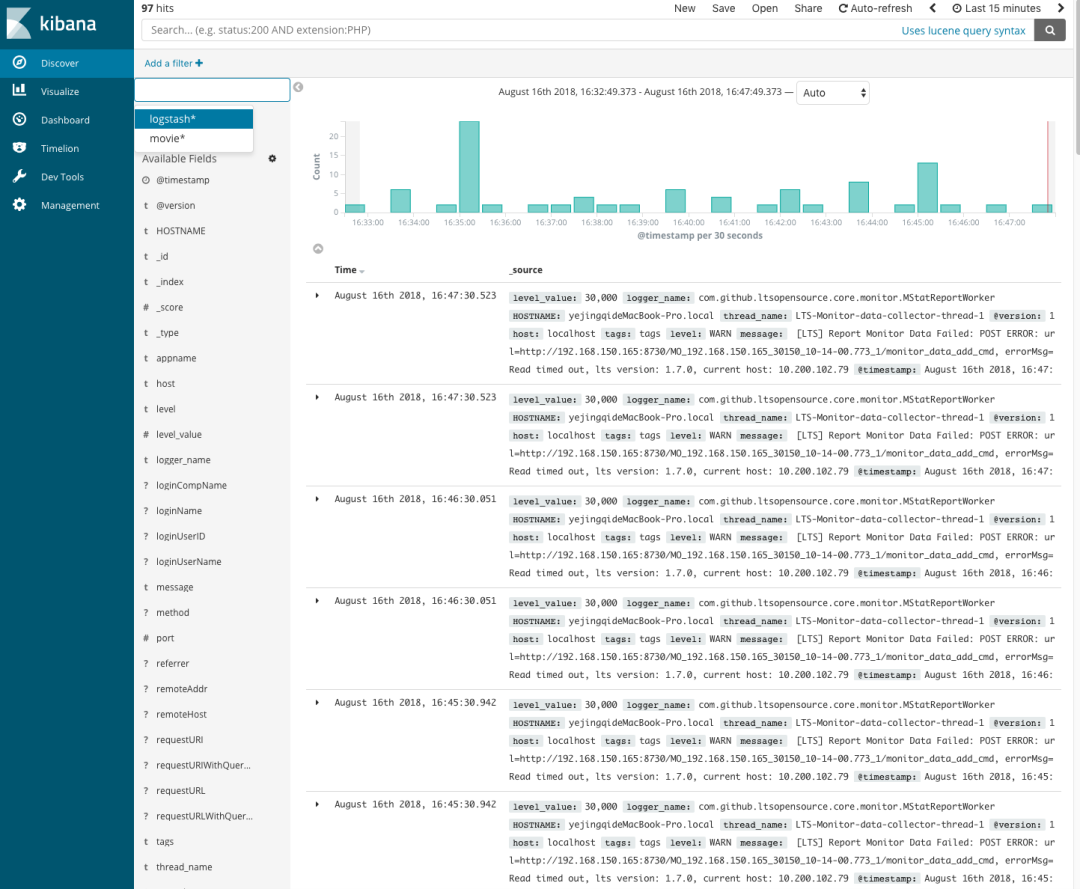
「6. 添加可视化图表Visualize」 「还有更多功能还在探索中,首先环境搭起来才会用动力继续去学习~」
「还有更多功能还在探索中,首先环境搭起来才会用动力继续去学习~」
踩坑记录
启动报错
uncaught exception in thread [main] org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
原因:不能使用Root权限登录
解决方案:切换用户
[root@VM_234_23_centos ~]# groupadd es
[root@VM_234_23_centos ~]# useradd es -g es -p es
[root@VM_234_23_centos ~]# chown es:es /home/app/elasticsearch/
# 切换用户,记得su - ,这样才能获得环境变量
[root@VM_234_23_centos ~]# sudo su - esException in thread “main” java.nio.file.AccessDeniedException:
错误原因:使用非 root用户启动ES,而该用户的文件权限不足而被拒绝执行。
解决方法:chown -R 用户名:用户名 文件(目录)名
例如:chown -R abc:abc searchengine
再启动ES就正常了
elasticsearch启动后报Killed
[2018-07-13T10:19:44,775][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [aggs-matrix-stats]
[2018-07-13T10:19:44,779][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [analysis-common]
[2018-07-13T10:19:44,780][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [ingest-common]
[2018-07-13T10:19:44,780][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [lang-expression]
[2018-07-13T10:19:44,780][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [lang-mustache]
[2018-07-13T10:19:44,780][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [lang-painless]
[2018-07-13T10:19:44,780][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [mapper-extras]
[2018-07-13T10:19:44,780][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [parent-join]
[2018-07-13T10:19:44,780][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [percolator]
[2018-07-13T10:19:44,780][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [rank-eval]
[2018-07-13T10:19:44,781][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [reindex]
[2018-07-13T10:19:44,781][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [repository-url]
[2018-07-13T10:19:44,781][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [transport-netty4]
[2018-07-13T10:19:44,781][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [tribe]
[2018-07-13T10:19:44,781][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [x-pack-core]
[2018-07-13T10:19:44,781][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [x-pack-deprecation]
[2018-07-13T10:19:44,781][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [x-pack-graph]
[2018-07-13T10:19:44,781][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [x-pack-logstash]
[2018-07-13T10:19:44,782][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [x-pack-ml]
[2018-07-13T10:19:44,782][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [x-pack-monitoring]
[2018-07-13T10:19:44,782][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [x-pack-rollup]
[2018-07-13T10:19:44,782][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [x-pack-security]
[2018-07-13T10:19:44,782][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [x-pack-sql]
[2018-07-13T10:19:44,782][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [x-pack-upgrade]
[2018-07-13T10:19:44,782][INFO ][o.e.p.PluginsService ] [f2s1SD8] loaded module [x-pack-watcher]
[2018-07-13T10:19:44,783][INFO ][o.e.p.PluginsService ] [f2s1SD8] no plugins loaded
Killed修改config目录下的jvm.options,将堆的大小设置小一点
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms512m
-Xmx512m虚拟内存不足
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[2018-07-13T14:02:06,749][DEBUG][o.e.a.ActionModule ] Using REST wrapper from plugin org.elasticsearch.xpack.security.Security
[2018-07-13T14:02:07,249][INFO ][o.e.d.DiscoveryModule ] [f2s1SD8] using discovery type [zen]
[2018-07-13T14:02:09,173][INFO ][o.e.n.Node ] [f2s1SD8] initialized
[2018-07-13T14:02:09,174][INFO ][o.e.n.Node ] [f2s1SD8] starting ...
[2018-07-13T14:02:09,539][INFO ][o.e.t.TransportService ] [f2s1SD8] publish_address {10.105.234.23:9300}, bound_addresses {0.0.0.0:9300}
[2018-07-13T14:02:09,575][INFO ][o.e.b.BootstrapChecks ] [f2s1SD8] bound or publishing to a non-loopback address, enforcing bootstrap checks
ERROR: [1] bootstrap checks failed
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[2018-07-13T14:02:09,621][INFO ][o.e.n.Node ] [f2s1SD8] stopping ...
[2018-07-13T14:02:09,726][INFO ][o.e.n.Node ] [f2s1SD8] stopped
[2018-07-13T14:02:09,726][INFO ][o.e.n.Node ] [f2s1SD8] closing ...
[2018-07-13T14:02:09,744][INFO ][o.e.n.Node ] [f2s1SD8] closed需要修改虚拟内存的大小(在root权限下)
[root@VM_234_23_centos elasticsearch]# vim /etc/sysctl.conf
# 插入下列代码后保存退出
vm.max_map_count=655360
[root@VM_234_23_centos elasticsearch]# sysctl -p
# 最后重启elastricsearch热门内容:5种分布式事务最终一致性解决方案,一次性说清了!
拜访了这位小哥的GitHub后,我失眠了!
我们已经不用AOP做操作日志了!
强烈不建议你用 a.equals(b) 判断对象相等!
最近面试BAT,整理一份面试资料《Java面试BAT通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。
明天见(。・ω・。)ノ♡
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范