深度学习(9)之 easyOCR使用详解-程序员宅基地
技术标签: python 计算机视觉 深度学习 人工智能 # 深度学习 OCR
easyOCR使用详解
- 本文在 OCR-easyocr初识 基础上进行修改
- EasyOCR 是一个python版的文字识别工具。目前支持80中语言的识别。其对应的 github 地址:EasyOCR
- 可以在网站版测试 demo 测试效果:https://www.jaided.ai/easyocr/
- 其在字符识别上的效果如下:

一、介绍
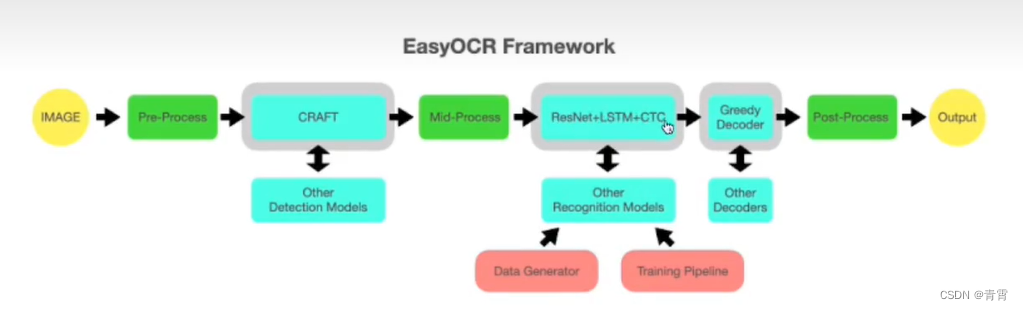
二、安装
- Install using pip
For the latest stable release:
pip install easyocr
For the latest development release:
pip install git+https://github.com/JaidedAI/EasyOCR.git
- 模型储存路径:
windows: C:\Users\username\.EasyOCR\linux:/root/.EasyOCR/
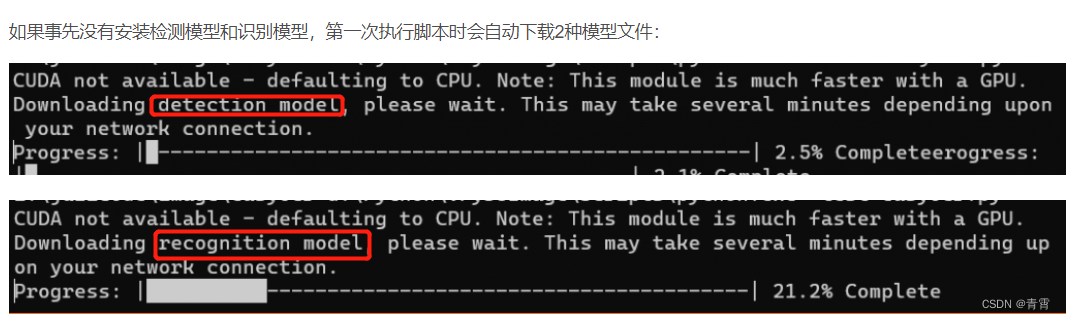

三、API文档
3.1、easyocr.Reader class:
-
lang_list (list) - 识别的语言代码列表,例如 ['ch_sim','en']
-
gpu (bool, string, default = True) - 启用 GPU
-
model_storage_directory (string, default = None) - 模型数据目录的路径。如果未指定,将从环境变量 EASYOCR_MODULE_PATH(首选)、MODULE_PATH(如果已定义)或 ~/.EasyOCR/ 定义的目录中读取模型。
-
download_enabled (bool, default = True) - 如果 EasyOCR 无法找到模型文件,则启用下载;
-
user_network_directory (bool, default = None) - 用户模型存储的路径。如果未指定,将从 MODULE_PATH + '/user_network' (~/.EasyOCR/user_network) 读取模型;
-
recog_network (string, default = 'standard') - 用户模型、模块和配置文件的名称;
-
detector (bool, default = True) - 将检测模型加载到内存中
-
recognizer (bool, default = True) - 将识别模型加载到内存中
-
lang_char - 显示当前模型中的所有可用字符
3.2、reader.readtext()
-
image (string, numpy array, byte) - 输入图像;
-
decoder (string, default = 'greedy')- 选项有 'greedy'、'beamsearch' 和 'wordbeamsearch';
-
beamWidth (int, default = 5) - 当解码器 = 'beamsearch' 或 'wordbeamsearch' 时要保留多少光束;
-
batch_size (int, default = 1) - batch_size>1 将使 EasyOCR 更快但使用更多内存;
-
worker (int, default = 0) - 数据加载器中使用的编号线程;
-
allowlist (string) - 强制 EasyOCR 只识别字符的子集。对特定问题有用(例如车牌等);
-
blocklist (string) - 字符的块子集。如果给定了允许列表,则此参数将被忽略。
-
detail (int, default = 1) - 将此设置为 0 以进行简单输出;
-
paragraph (bool, default = False) - 将结果合并到段落中;
-
min_size (int, default = 10) - 过滤文本框小于最小值(以像素为单位);
-
rotation_info (list, default = None) - 允许 EasyOCR 旋转每个文本框并返回具有最佳置信度分数的文本框。符合条件的值为 90、180 和 270。例如,对所有可能的文本方向尝试 [90, 180 ,270]。
-
contrast_ths (float, default = 0.1) - 对比度低于此值的文本框将被传入模型 2 次。首先是原始图像,其次是对比度调整为“adjust_contrast”值。结果将返回具有更高置信度的那个;
-
adjust_contrast (float, default = 0.5) - 低对比度文本框的目标对比度级别。
-
text_threshold (float, default = 0.7) - 文本置信度阈值
-
low_text (float, default = 0.4) - 文本下限分数
-
link_threshold (float, default = 0.4) - 链接置信度阈值
-
canvas_size (int, default = 2560) - 最大图像尺寸。大于此值的图像将被缩小。
-
mag_ratio (float, default = 1) - 图像放大率
-
slope_ths (float, default = 0.1) - 考虑合并的最大斜率 (delta y/delta x)。低值意味着不会合并平铺框。
-
ycenter_ths (float, default = 0.5) - y 方向的最大偏移。不应该合并不同级别的框。
-
height_ths (float, default = 0.5) - 盒子高度的最大差异。不应合并文本大小非常不同的框。
-
width_ths (float, default = 0.5) - 合并框的最大水平距离。
-
add_margin (float, default = 0.1) - 将边界框向所有方向扩展某个值。这对于具有复杂脚本的语言(例如泰语)很重要。
-
x_ths (float, default = 1.0) - 当段落=True 时合并文本框的最大水平距离。
-
y_ths (float, default = 0.5) - 当段落 = True 时合并文本框的最大垂直距离。
四、识别模型
 https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md
https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md4.1、训练识别模型
4.2、使用自定义的识别模型
五、使用
5.1、基本使用1
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True
5.2、基本使用2

代码实现如下:
import easyocr
reader = easyocr.Reader(
lang_list=['ch_sim', 'en'], # 需要导入的语言识别模型,可以传入多个语言模型,其中英语模型en可以与其他语言共同使用
gpu=False, # 默认为True
download_enabled=True # 默认为True,如果 EasyOCR 无法找到模型文件,则启用下载
)
result = reader.readtext('id_card.jpg', detail=1 ) # 图片可以传入图片路径、也可以传入图片链接。但推荐传入图片路径,会提高识别速度。包含中文会出错。设置detail=0可以简化输出结果,默认为1
print(result)
readtext 返回的列表中,每个元素都是一个元组,内含三个信息:位置、文字、置信度:
[
([[27, 37], [341, 37], [341, 79], [27, 79]], '姓 名 爱新觉罗 。玄烨', 0.6958897643232619),
([[29, 99], [157, 99], [157, 135], [29, 135]], '性 别 男', 0.914532774041559),
([[180, 95], [284, 95], [284, 131], [180, 131]], '民蔟满', 0.4622474180193509),
([[30, 152], [94, 152], [94, 182], [30, 182]], '出 生', 0.6015505790710449),
([[110, 152], [344, 152], [344, 184], [110, 184]], '1654 年54日', 0.42167866223467815),
([[29, 205], [421, 205], [421, 243], [29, 243]], '住 址 北京市东城区景山前街4号', 0.6362530289101117),
([[105, 251], [267, 251], [267, 287], [105, 287]], '紫禁城乾清宫', 0.8425745057905053),
([[32, 346], [200, 346], [200, 378], [32, 378]], '公民身份证号码', 0.22538012770296922),
([[218, 348], [566, 348], [566, 376], [218, 376]], '000003165405049842', 0.902066405195785)
]
detail=0,从而只返回文字内容:
['姓 名 爱新觉罗 。玄烨', '性 别 男', '民蔟满', '出 生', '1654 年54日', '住 址 北京市东城区景山前街4号', '紫禁城 乾清宫', '公民身份证号码', '000003165405049842']
5.3、基本使用3


智能推荐
DNS分离解析-程序员宅基地
文章浏览阅读114次。DNS分离解析包: bind #域名服务包, bind-chroot #提供虚拟根支持服务: named主配置文件: /etc/named.conf #设置本机负责解析的域名地址库文件: /var/named/ #主机名与IP地址的对应关系运行时的虚拟根环境:/var/named/chroot/ #牢笼政策分离解析概述(视图解析)当收到客户机的DNS查询..._dns分离解析匹配客户端来源的字段
第一章-第七题( 有人认为,“中文编程”, 是解决中国程序员编程效率一个秘密武器,请问它是一个 “银弹” 么? )--By 侯伟婷...-程序员宅基地
文章浏览阅读208次。 首先,“银弹”在百度百科中的解释是银色的子弹,我们更熟知的“银弹”一词,应该是在《人月神话》中提到的。银弹原本应该是指某种策略、技术或者技巧可以极大地提高程序员的生产力【1】。此题目中关于中文编程是否是一个“银弹”的讨论,我所持的是否定的态度,我不认为中文编程会是一项提高中国程序员编程效率的一个秘密武器,相反,我还认为他会比现在的英文编程来说降低工作效率,造成很大的工作上的困难。..._存在一种策略,技术技巧可以极大的提高程序员的生产力。
模拟用户操作 京东抢购 华为mate40 Pro、支付的js脚本_京东抢华为脚本-程序员宅基地
文章浏览阅读5.4k次,点赞2次,收藏29次。1 登录 https://item.jd.com/10024680695127.html2 打开开发者模式,插入如下代码,count=1nIntervId=0 stop=0 var goDate function start(){ if (stop==1){ clearInterval(nIntervId);//停止监控 return } if (Date.now() < goDate){ return _京东抢华为脚本
php eayswoole node axios crypto-js 实现大文件分片上传复盘_cryptojs 处理文件过大-程序员宅基地
文章浏览阅读740次。1)前端侧 :前端上传文件,根据分片大小,自动计算出整个文件的分片数量,以及分片二进制文件,以及整个文件的md5值,以及分片文件md5值,传与后端,后端处理完后,根据上传分片的进度以及后端返回状态,判断整个文件是否传输完毕,完毕后,前端展示完成进度。2)后端PHP侧:后端接收前端传过来的数据,包括文件名,文件md5,分片信息,然后将分片文件信息存储到redis 有序集合中,其中key为整个文件的md5 ,待所有分片文件都上传完后,根据顺序,然后将文件整合存储,然后完成整个文件分片上传逻辑。_cryptojs 处理文件过大
VScode 编译器配置IDE环境(C/C++/Go)_vscode 配置 在ide上编译运行-程序员宅基地
文章浏览阅读4.5k次,点赞4次,收藏29次。VScode 编译器配置IDE环境(C/C++/Go)摘要VS Code 下载安装下载安装简单使用WindowsLinuxIDE 环境配置C/C++C/C++ 编译器安装及配置简单使用 VS Code 终端进行编译和运行方式使用code runner插件:Go总结摘要对于 VS Code 的使用,我本人感觉这个编译器还是很好用的,而且目前能够支持在 Windows、Linux、MacOs 上流畅运行,并且官方已经提供了 X86、ARM等主流架构版本,还很容易通过安装插件就能过实现基于 SSH 的远程代_vscode 配置 在ide上编译运行
oracle use_ntl详细解释_oracle中use_nl提示-程序员宅基地
文章浏览阅读1k次。1./*+ use_nl(t2,t) */提示走nest Loop,但是没有提示t2还是t为驱动表2./*+ ordered user_nl(t2,t) */提示走 Nest Loop,order提示的是from 后面的第一个表为驱动表.3./*+ leading(t2) use_nl(t) */直接提示t2为驱动表。结论:use_NL不能让优化器确定谁是驱动表谁是被驱动表。use_nl(t,t2)也没有指出哪个是驱动表,这时候我们就需要使用Ordered ,_oracle中use_nl提示
随便推点
arm 32linux,C语言实现文件pcm转换wav,提供代码实验用PCM音频文件_mp3 to wav c语言-程序员宅基地
文章浏览阅读199次,点赞2次,收藏3次。linux系统C语言音频文件pcm转换wav,提供实验用PCM音频文件_mp3 to wav c语言
JVM详解-栈&堆_jvm 堆栈-程序员宅基地
文章浏览阅读2.7k次,点赞3次,收藏15次。栈&堆栈栈结构JVM中的栈Java中的栈1、栈里面存放什么2、栈运行原理堆堆(Heap)新生区老年区永久区出现OOMVM options参数栈栈结构栈是一种数据结构。程序=数据结构+算法栈:先进后出,后进先出队列:先进先出(FIFO)Q:为什么main()方法先执行后结束A:先进栈,最后出JVM中的栈Oracle关于栈和栈帧提供了如下描述:每个JVM线程拥有一个私有的 Java虚拟机栈,创建线程的同时栈也被创建。一个JVM栈由许多帧组成,称之为"栈帧"。JVM中的栈和C等常见语言_jvm 堆栈
5、Nacos 、Sentinel、Seata下载与安装_sentinel下载安装-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏10次。1、官网:https://nacos.io/zh-cn/index.html2、 下载3、解压安装双击startup.cmdjava.io.IOException: java.lang.IllegalArgumentException: db.num is null如果出现以上错误,需要指令启动:单机模式启动 window版本 startup.cmd -m standalone4、访问登录http://localhost:8848/nacos/index.html#/._sentinel下载安装
linux ssh远程登录退出,ssh登陆小技巧-用SSH 退出符切换 SSH 会话-程序员宅基地
文章浏览阅读1.7k次。用SSH 退出符切换 SSH 会话这个技巧非常实用。尤其是远程登陆到一台主机A,然后从A 登陆到B,如果希望在A 上做一些操作,还得再开一个终端,很是麻烦。当你使用ssh从本机登录到远程主机时,你可能希望切换到本地做一些操作,然后再重新回到远程主机。这个时候,你不需要中断 ssh连接,只需要按照如下步骤操作即可:当你已经登录到了远程主机时,你可能想要回到本地主机进行一些操作,然后又继续回到远程主机..._linux中ssh远程登录后如何回到原来主机
[渝粤教育] 四川农业大学 计算机网络 参考 资料_调制的信号是单一频率的载波信号吗-程序员宅基地
文章浏览阅读796次。教育-计算机网络-章节资料考试资料-四川农业大学【】随堂测验1、【单选题】以下哪一项不属于物联网的实现基础A、可穿戴设备B、RFIDC、APPD、蓝牙参考资料【 】2、【单选题】以下哪一项不是解决网络安全问题的因素A、 安全技术B、法律法规C、道德自律D、多种应用参考资料【 】电路交换随堂测验1、【单选题】以下哪一项不是电路交换的特征A、按需建立点对点信道B、数据无需携带地址信息C、点对点信道独占经过的物理链路带宽D、两两终端之间可以同时通信参考资料_调制的信号是单一频率的载波信号吗
吃透这几道MQ消息队列面试题,秒杀面试官..._mq面试题吊打面试官-程序员宅基地
文章浏览阅读450次。几种常见的MQ面试题相关视频参考(来自动力节点):https://www.bilibili.com/video/BV1Ap4y1D7tU相关资料下载:http://www.bjpowernode.com/?csdn为什么使用消息队列?其实就是问问你消息队列都有哪些使用场景,然后你项目里具体是什么场景,说说你在这个场景里用消息队列是什么?面试官问你这个问题,期望的一个回答是说,你们公司有个什么业务场景,这个业务场景有个什么技术挑战,如果不用 MQ 可能会很麻烦,但是你现在用了 MQ 之后带_mq面试题吊打面试官