python用scrapy框架爬取双色球数据_怎样抓取开奖号码-程序员宅基地
1、今天刷到朋友圈,看到一个数据,决定自己也要来跟随下潮流(靠天吃饭)

去百度了下,决定要爬的网站是https://caipiao.ip138.com/shuangseqiu/
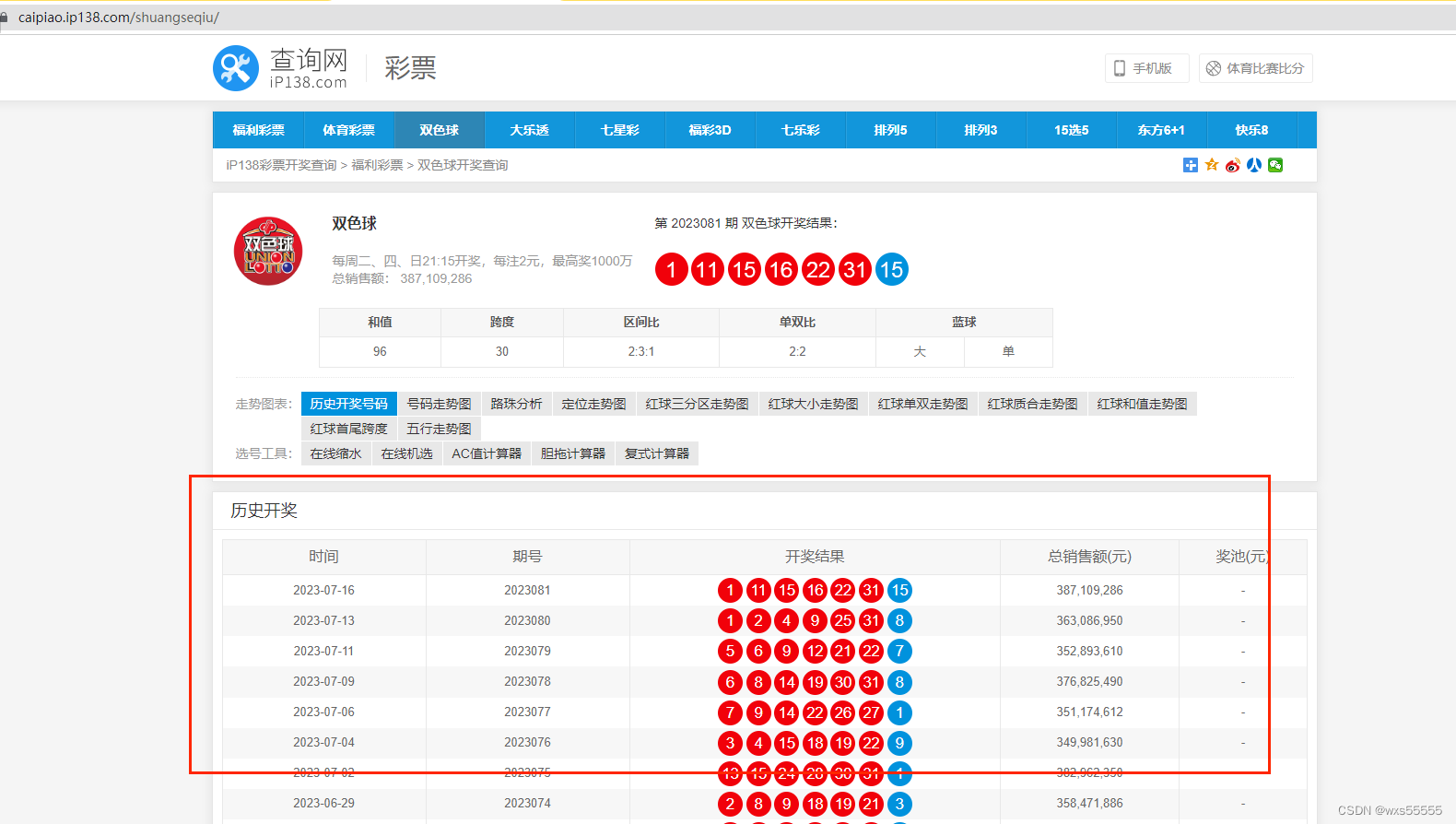
分析:根据图片设计数据库便于爬取保存数据,时间,6个红球,一个蓝球字段
DROP TABLE IF EXISTS `shuangseqiu`;
CREATE TABLE `shuangseqiu` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`openDate` date NOT NULL COMMENT '日期',
`red1` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球1',
`red2` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球2',
`red3` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球3',
`red4` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球4',
`red5` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球5',
`red6` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球6',
`blue` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '蓝球',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 342 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;2、安装python,去官网下载一个windows版本的,一直下一步就行了
3、安装完后打开cmd,输入pip install scrapy安装scrapy框架
4、框架安装完后,输入 scrapy startproject caipiao新增彩票项目
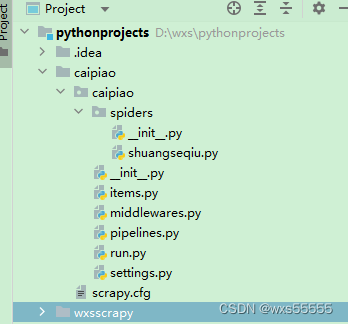
5、进入到spider目录,输入 scrapy genspider shuangseqiu "https://caipiao.ip138.com/shuangseqiu/"新增双色球爬虫,最终生成项目结构如下
6、在items.py里面定义爬取存储的字段
import scrapy
class ShuangseqiuItem(scrapy.Item):
# define the fields for your item here like:
openDate = scrapy.Field()
red1 = scrapy.Field()
red2 = scrapy.Field()
red3 = scrapy.Field()
red4 = scrapy.Field()
red5 = scrapy.Field()
red6 = scrapy.Field()
blue = scrapy.Field()
7、在pipelines.py里面写好保存数据库的逻辑,并在settings.py文件新增配置,数据库连接配置在settings.py文件里面新增下面配置就行
settings.py配置如下
ITEM_PIPELINES = {
"caipiao.pipelines.ShuangseqiuscrapyPipeline": 300,
}
MYSQL_HOST = '192.168.XXX.XXX'
MYSQL_DBNAME = '数据库名'
MYSQL_USER = '用户'
MYSQL_PASSWD = '密码'pipelines.py文件内容如下
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import pymysql
from caipiao import settings
class ShuangseqiuscrapyPipeline:
def __init__(self):
# 连接数据库
self.connect = pymysql.connect(
host=settings.MYSQL_HOST,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8',
use_unicode=True)
# 通过cursor执行增删查改
self.cursor = self.connect.cursor();
def process_item(self, item, spider):
try:
# 先删除数据
self.cursor.execute(
"""delete from shuangseqiu where openDate=%s""",
(item['openDate']
))
# 插入数据
self.cursor.execute(
"""insert into shuangseqiu(openDate,red1,red2,red3,red4,red5,red6,blue)
value (%s,%s, %s, %s,%s, %s,%s, %s)""",
(item['openDate'],
item['red1'],
item['red2'],
item['red3'],
item['red4'],
item['red5'],
item['red6'],
item['blue']
))
# 提交sql语句
self.connect.commit()
except Exception as error:
# 出现错误时打印错误日志
print(error)
return item
8、在spiders/shuangseqiu.py下面写爬取逻辑,不知道怎么获取xpath结构的可以在网站右击节点获取copy---->copy full xpath
import scrapy
from caipiao.items import ShuangseqiuItem
class ShuangseqiuSpider(scrapy.Spider):
name = "shuangseqiu"
allowed_domains = ["caipiao.ip138.com"]
start_urls = ["https://caipiao.ip138.com/shuangseqiu/"]
def parse(self, response):
print(response.text)
#获取历史开奖列表
shuangseqiuList = response.xpath("//div[@class='module mod-panel']//div[@class='panel']//tbody/tr")
for li in shuangseqiuList:
item = ShuangseqiuItem()
#获取开奖时间
item["openDate"] = li.xpath('td[1]/span/text()')[0].extract()
#获取中奖号码
balls=li.xpath('td[3]/span/text()');
item["red1"] = balls[0].extract()
item["red2"] = balls[1].extract()
item["red3"] = balls[2].extract()
item["red4"] = balls[3].extract()
item["red5"] = balls[4].extract()
item["red6"] = balls[5].extract()
item["blue"] = balls[6].extract()
print(item)
yield item
9、新增run.py文件,用来在idea里面跑cmd脚本用来爬数据
from scrapy import cmdline
name = 'shuangseqiu'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())
10、执行run.py,发现报错
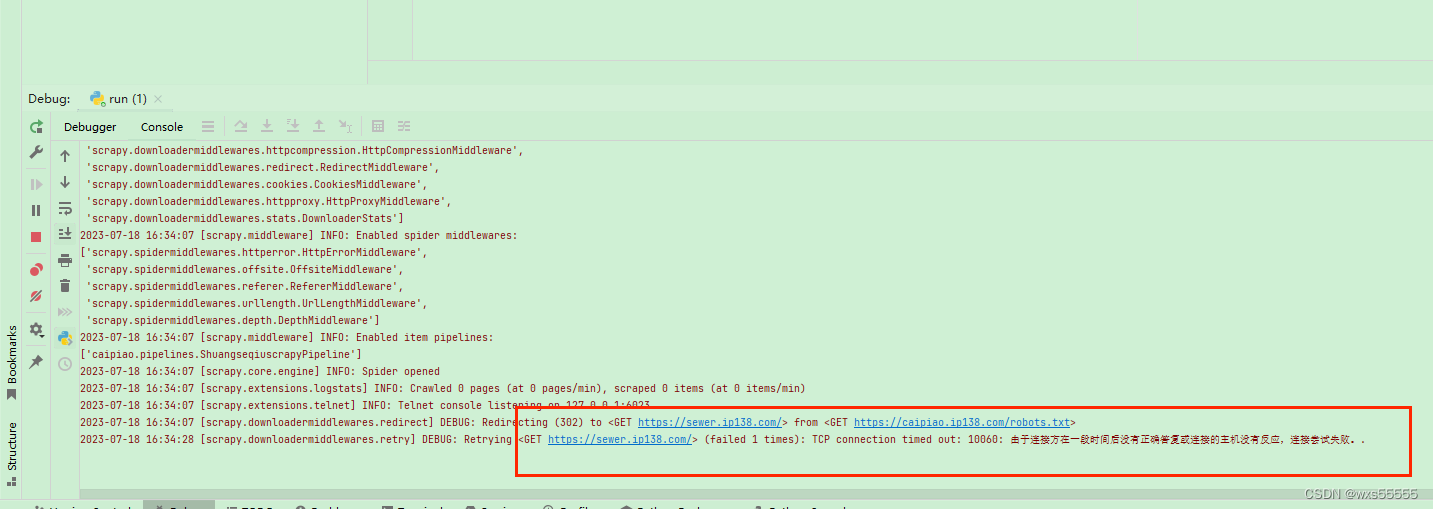
11、百度了一下,通过修改settings.py如下配置,在执行run.py,发现成功了
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
ROBOTSTXT_OBEY = False
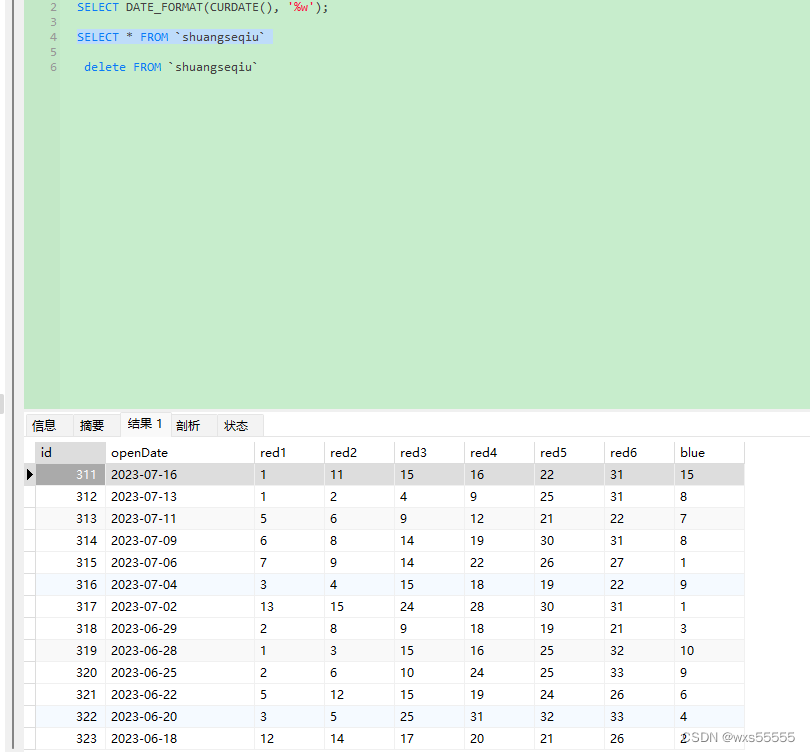
 12.数据库查询表,发现数据成功获取
12.数据库查询表,发现数据成功获取
13、拿数据去分析,离中大奖不远了![]()
![]() ~~~~,下面是几个简单的数据分析sql
~~~~,下面是几个简单的数据分析sql
-- 统计每个位置的球出现最多次数的号码
SELECT red1,count(red1) FROM `shuangseqiu` group by red1 order by count(red1) desc;
SELECT red2,count(red2) FROM `shuangseqiu` group by red2 order by count(red2) desc;
SELECT red3,count(red3) FROM `shuangseqiu` group by red3 order by count(red3) desc;
SELECT red4,count(red4) FROM `shuangseqiu` group by red4 order by count(red4) desc;
SELECT red5,count(red5) FROM `shuangseqiu` group by red5 order by count(red5) desc;
SELECT red6,count(red6) FROM `shuangseqiu` group by red6 order by count(red6) desc;
SELECT blue,count(blue) FROM `shuangseqiu` group by blue order by count(blue) desc;
-- 统计每周几出现次数最多次的号码 0-6为周日到周六
SELECT DATE_FORMAT(openDate, '%w'),red1,count(red1) FROM `shuangseqiu` group by red1,DATE_FORMAT(openDate, '%w') order by DATE_FORMAT(openDate, '%w') asc,count(red1) desc;14 、完事了~~~~~~
智能推荐
Django使用 haystack+whoosh实现搜索功能,并返回json数据_django填加whoosh backend-程序员宅基地
文章浏览阅读228次。【代码】Django使用 haystack+whoosh实现搜索功能,并返回json数据。_django填加whoosh backend
nginx反向代理-程序员宅基地
文章浏览阅读341次。环境是政务微信放请求71代理服务器,71代理服务器请求项目所在的14服务器。1.服务器的映射 server { listen 8080; server_name 10.99.89.71; #charset koi8-r; #access_log logs/host.access.log main; rewrite ^(.*)$ https://${server_name}$1 permanent;
[FPGA入门笔记](十四):IIC总线控制原理与Verilog实现_fpga作为iic的从机-程序员宅基地
文章浏览阅读2.1k次,点赞8次,收藏39次。简介今天购买了AXLINX AX7020的开发板,从今天开始每一个例程都要做文档记录,为自己加油。本实验,基于ALINX AX7020开发板,芯片为xc7z020clg400-2。开发板输入时钟为50MHz。参考文章本文主要参考了以下两篇文章,并在其基础上加以改进和完善,加入了作者自己的理解。博客一:【IIC协议原理以及主机、从机Verilog实现】博客二:【接口时序】6、IIC总线的原理与Verilog实现一、IIC协议介绍IIC(Inter-Integrated Circuit)总线是一_fpga作为iic的从机
web缓存—Squid代理服务-程序员宅基地
文章浏览阅读1k次。web缓存 squid代理 ACL控制访问 方向代理 _squid代理
Golang Cron 定时任务分析-程序员宅基地
文章浏览阅读1w次,点赞2次,收藏4次。1、cron 表达式的基本格式 用过 linux 的应该对 cron 有所了解。linux 中可以通过 crontab -e 来配置定时任务。不过,linux 中的 cron 只能精确到分钟。而我们这里要讨论的 Go 实现的 cron 可以精确到秒,除了这点比较大的区别外,cron 表达式的基本语法是类似的。(如果使用过 Java 中的 Quartz,对 cron 表达式应该比较了解,而且它和这里
C语言实操篇——QQ消息轰炸-程序员宅基地
文章浏览阅读1.1k次,点赞29次,收藏26次。Window.h库里有很多好玩的函数,下面让我们使用这个库中的函数并且尝试实现消息轰炸,这里以QQ为例(轰炸条数任意,轰炸内容可以是某段文字也可以是某个表情包哦)~FindWindowA是WIndow.h库中的一个函数,用于查找窗口句柄,处理的是ANSI编码字符串(如果你需要处理Unicode编码字符串,可以使用FindWindowW函数)。这行代码的释义是连接一个名为“111”的窗口;在 C 语言中, SendMessageA 函数是一个用于向窗口发送消息的函数,它是 Windows API 的一部分;
随便推点
C/C++坦克大战项目-程序员宅基地
文章浏览阅读4.8k次,点赞10次,收藏48次。本次坦克大战项目已实现的功能背景音效,动画界面,各级菜单选项,暂停游戏,重新开始,储存与读取游戏进度。单人,双人(闯关模式) (自定义游戏),双人联机模式每辆坦克独立的HP,MP,移动速度,攻击CD,自动回HP,MP,3种不同的炮弹攻击针对BOSS的自动寻找玩家并攻击。使用A星算法。各种类型食物:无敌,攻击翻倍,全屏秒杀,无限子弹,全场冰冻。各种类型敌人:4种按等级区分的普通敌人,1种...
北京54或国家80或CGCS2000转WGS84坐标系的程序实现方法_cgcs2000转换到wgs84 c# 代码-程序员宅基地
文章浏览阅读3.9k次,点赞10次,收藏17次。介绍在工程测量中,经常使用的坐标系如北京54坐标系、国家80(也叫西安80)坐标系、CGCS2000坐标系。而在终端设备或定位平台中,一般使用WGS84坐标系。这样的情况下,就需要一种北京54、国家80、CGCS2000转WGS84坐标系的通用程序方法。而我们使用的就是布尔莎七参数法来进行的程序转换。通过使用C++程序,从而得到平台需要的wgs84坐标。布尔莎七参数标准的七参数转换方法,使用X、Y、Z平移,X、Y、Z旋转,K尺度,这七个参数,在已知三个以上点的情况下,来计算七参数模型。具体七参数计_cgcs2000转换到wgs84 c# 代码
山东大学软件学院增强现实2020年期末考试试题回忆_增强现实算法基础 秦学英 答案-程序员宅基地
文章浏览阅读1.5k次,点赞6次,收藏32次。山东大学软件学院增强现实2020年期末考试试题回忆一、选择题(8题,每题5分,共40分)基本上都是认知性题目,只需要对课上的东西看过一眼就一眼(大部分题只要知道增强现实是什么),就可以做了。增强现实的三要素。张正友定标是怎么实现的。二、论述与证明题 (4题,每题15分,共60分)1、给出了ppt上一个光学穿透式头盔显式器的图,问:(1)根据下图描述光学穿透式头盔显式器的原理。(2)它的核心部件(技术)是什么?(3)它的优缺点是什么?2、 homographic单应性矩阵 H,两平面上的_增强现实算法基础 秦学英 答案
为Hexo添加Valine评论系统_hexo valine-程序员宅基地
文章浏览阅读1.1k次。更多文章见个人博客Valine 诞生于2017年8月7日,是一款基于LeanCloud的快速、简洁且高效的无后端评论系统。获取APP ID和APP key前往LeanCloud注册或登录,进入首页创建应用创建好后,点击刚刚创建的应用,点击设置-应用Keys,就能看到APP ID和key了启用ValineNext主题已经内置Valine评论系统,只需要修改主题配置文件启用即可# Valine# For more information: https://valine.js.org,_hexo valine
Spring依赖注入(DI)的三种实现方式_di的两种注入方式,怎么实现?-程序员宅基地
文章浏览阅读1.1w次。Spring依赖注入(DI)的三种方式,分别为:1. 接口注入2. Setter方法注入3. 构造方法注入 下面介绍一下这三种依赖注入在Spring中是怎么样实现的。 首先我们需要以下几个类:接口 Logic.java接口实现类 LogicImpl.java一个处理类 LoginAction.java还有一个测试类 TestMain.java _di的两种注入方式,怎么实现?
span标签、strong/b 标签_span b标签-程序员宅基地
文章浏览阅读2.9k次。span 标签: <span> 标签被用来组合文档中的行内元素。 注:span 没有固定的格式表现。当对它应用样式时,它才会产生视觉上的变化 <p><span>span标签:</span>... ... ...</p> 运行如下:span 没有固定的格式表现。当对它应用样式时,它才会产生视觉上的变化..._span b标签