kafka原理及Docker环境部署-程序员宅基地
技术原理
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库 (计算机)。
Kafka是一个分布式的、高吞吐量、高可扩展性的消息系统。Kafka 基于发布/订阅模式,通过消息解耦,使生产者和消费者异步交互,无需彼此等待。Ckafka 具有数据压缩、同时支持离线和实时数据处理等优点,适用于日志压缩收集、监控数据聚合等场景。
关键名词:
- broker:kafka集群包含一个或者多个服务器,服务器就称作broker
- producer:负责发布消息到broker
- consumer:消费者,从broker获取消息
- topic:发布到kafka集群的消息类别。
- partition:每个topic划分为多个partition。
- group:每个partition分为多个group
架构示意图
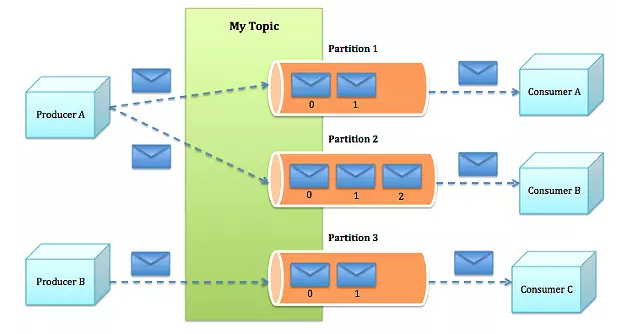
一个典型的Kafka集群中包含若干Producer(可以是web前端FET,或者是服务器日志等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干ConsumerGroup,以及一个Zookeeper集群。
Kafka通过Zookeeper管理Kafka集群配置:选举Kafka broker的leader,以及在Consumer Group发生变化时进行rebalance,因为consumer消费kafka topic的partition的offsite信息是存在Zookeeper的。
Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。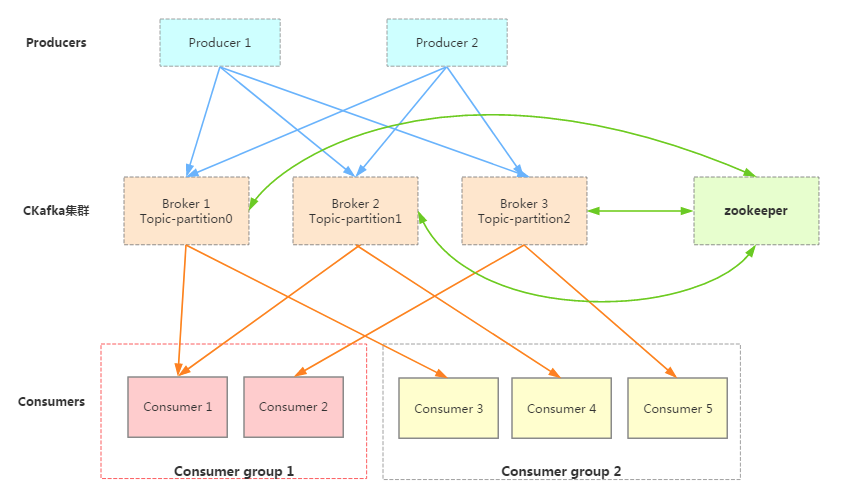
一个典型的Cloud Kafka集群如上所示。其中的生产者Producer可能是网页活动产生的消息、或是服务日志等信息。生产者通过push模式将消息发布到Cloud Kafka的Broker集群,消费者通过pull模式从broker中消费消息。消费者Consumer被划分为若干个Consumer Group,此外,集群通过Zookeeper管理集群配置,进行leader选举,故障容错等。
kafka特点:
- 它是一个处理流式数据的”发布-订阅“消息系统。
- 实时高效处理流式数据:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 将数据安全存储在分布式集群。
- 它是运行在集群上的。
- 它将流式记录存储在topics中。
- 每个record由key, value和timestamp组成。
Docker搭建
参考:https://github.com/wurstmeister/kafka-docker
docker-compose.yml如下:
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
volumes:
- ./data:/data
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 10.154.38.115
KAFKA_MESSAGE_MAX_BYTES: 2000000
KAFKA_CREATE_TOPICS: "Topic1:1:3,Topic2:1:1:compact"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- ./kafka-logs:/kafka
- /var/run/docker.sock:/var/run/docker.sock
kafka-manager:
image: sheepkiller/kafka-manager
ports:
- 9020:9000
environment:
ZK_HOSTS: zookeeper:2181
参数说明:
- KAFKA_ADVERTISED_HOST_NAME:Docker宿主机IP(如果你要配置多个brokers,就不能设置为 localhost 或 127.0.0.1)
- KAFKA_MESSAGE_MAX_BYTES:kafka(message.max.bytes) 会接收单个消息size的最大限制,默认值为1000000 , ≈1M
- KAFKA_CREATE_TOPICS:初始创建的topics,可以不设置
- 环境变量./kafka-logs为防止容器销毁时消息数据丢失。
- 容器kafka-manager为yahoo出可视化kafka WEB管理平台。
操作命令:
# 启动:
$ docker-compose up -d
# 增加更多Broker:
$ docker-compose scale kafka=3
# 合并:
$ docker-compose up --scale kafka=3
Kakfa使用
1,Kafka管理节点
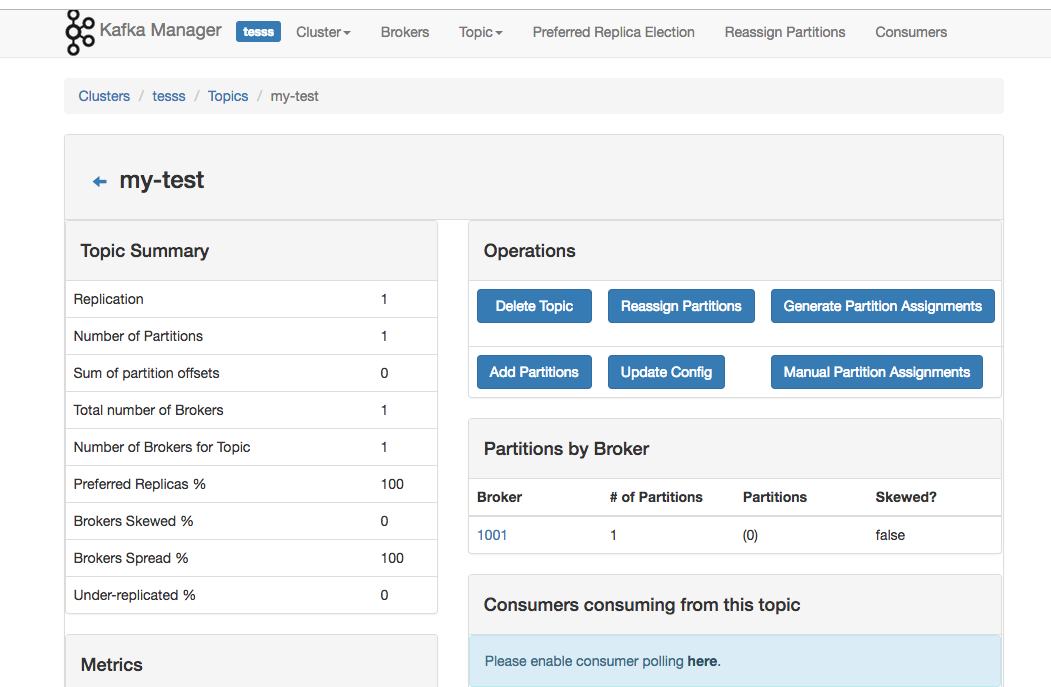
2,主题
environment:
KAFKA_CREATE_TOPICS: "Topic1:1:3,Topic2:1:1:compact"Topic1有1个Partition和3个replicas, Topic2有2个Partition,1个replica和cleanup.policy为compact。
Topic 1 will have 1 partition and 3 replicas, Topic 2 will have 1 partition, 1 replica and a cleanup.policy set to compact.
3,读写验证
读写验证的方法有很多,这里我们用kafka容器自带的工具来验证,首先进入到kafka容器的交互模式:
docker exec -it kafka_kafka_1 /bin/bash创建一个主题:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.31.84:2181 --replication-factor 1 --partitions 1 --topic my-test查看刚创建的主题:
/opt/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.31.84:2181
发送消息:
/opt/kafka/bin/kafka-console-producer.sh --broker-list 192.168.31.84:9092 --topic my-test
This is a message
This is another message读取消息:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.31.84:9092 --topic my-test --from-beginning使用场景
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
参考:
1,https://www.jianshu.com/p/bfeceb3548ad
2,https://www.jianshu.com/p/7f089cdff29a
3,https://www.cnblogs.com/iforever/p/9130983.html
4,利用flume+kafka+storm+mysql构建大数据实时系统
5,Kafka系列(四)Kafka消费者:从Kafka中读取数据
6,基于Docker搭建分布式消息队列Kafka
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线