有Mysql数据库的情况下为什么要用Hive数据库?-程序员宅基地
有Mysql数据库的情况下为什么要用Hive?
最近接到公司的一个需求,要求使用Hive做数据查询。当时第一反应就是What?Hive是什么鬼?一脸懵逼状。(请原谅一个刚开始实习的Java实习生见识短浅)然后发现了hive的一些问题。下面简单介绍一下Hive。
网上对于hive与mysql的区别的文章也不是很多。so只能问问公司大牛们,看看他们是怎样理解的。
由于 Hive 采用了 SQL 的查询语言 HQL,因此很容易将 Hive 理解为数据库。其实 从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。
数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
一、Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能 够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
Hive是Facebook 2008年8月刚开源的一个数据仓库框架,其系统目标与 Pig 有相似之处,但它有一些Pig目前还不支持的机制,比如:更丰富的类型系统、更类似SQL的查询语言、Table/Partition元数据的持久化等。
Hive 可以看成是从SQL到Map-Reduce的 映射器
Hive的数据放在哪儿?
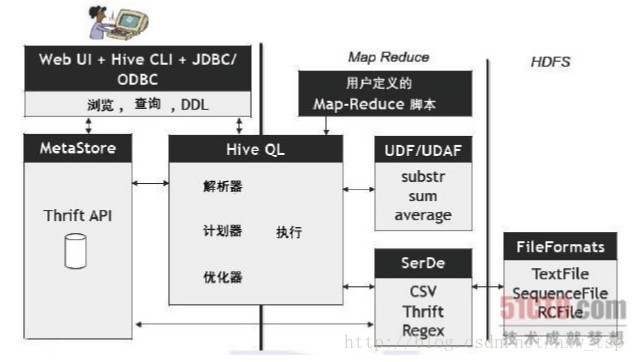
数据在HDFS的warehouse目录下,一个表对应一个子目录。
本地的/tmp目录存放日志和执行计划
hive的表分为两种,内表和外表。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
使用Mysql作为Hive metaStore的存储数据库
其中主要涉及到的表如下:
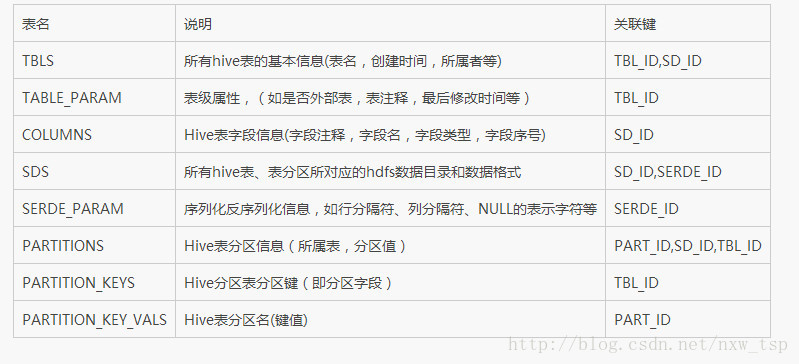
但是对于一个菜鸟来说,看完这些还是有点云里雾里。
下面来看他们的异同。
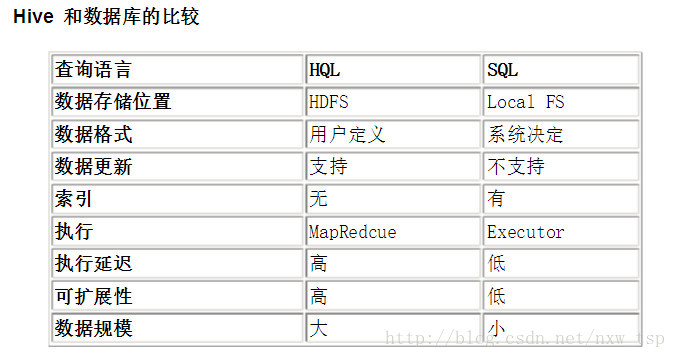
查询语言。由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
数据存储位置。Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库 则可以将数据保存在本地文件系统中。
数据格式。Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三 个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
数据更新。由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不 支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET 修改数据。
索引。之前已经说过,Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描, 因此也没有对数据中的某些 Key 建立索引。Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
执行。Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的(类似 select * from tbl 的查询不需要 MapReduce)。而数据库通常有自己的执行引擎。
执行延迟。之前提到,Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外 一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
可扩展性。由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是 一致的(世界上最大的 Hadoop 集群在 Yahoo!,2009年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的 数据;对应的,数据库可以支持的数据规模较小。
看了这些,我说为什么hive查询数据怎么这么慢呢。
最后再来一下数据库和数据仓储的区别。
> 数据库是面向事务的设计,数据仓库是面向主题设计的。 数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
> 数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。
> 数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个基本的元素是维表和事实表。(维是看问题的角度,比如时间,部门,维表放的就是这些东西的定义,事实表里放着要查询的数据,同时有维的ID)
以上文章部分内容来自与网络。
智能推荐
【幻化万千戏红尘】qianfengDay20-java基础学习:数据流、随机读取文件流RandomAccessFile-程序员宅基地
文章浏览阅读189次。课程回顾:流:转换流:字符和字节的转换对象流(Object):序列化,反序列化打印流(Print):打印各种数据类型的数据今日内容:数据流(Data):支持将基本数据类型写出,字节流,处理流1、DataOutputStream:数据输出字节流常用方法:writeXXX:写出基本数据类型的数据writeUTF:写
计算机通天之路第一季:计算机硬件基础_计算机天问之路-程序员宅基地
文章浏览阅读365次。时间:2017-1-6 20:32:07 今天学习了计算硬件基础,从零开始电脑内部主要包括的几个关键1. 电源电源是电脑的供电者,没有电源一切免谈。其质量好坏,决定了电脑各个部件的电压稳定程度,当你玩着玩着就没电了,或者电压不稳,死机了,蓝屏了,你是什么感受? 2. CPU系统的核心,又称中央处理器,相当于计算机的大脑,负责:算数运算,逻辑运算,数据传输。3. 内存全称:内部存储器。特点是:体积_计算机天问之路
Ubuntu安装MySQL时出现E: Unable to locate package mysql-server 的解决方法-程序员宅基地
文章浏览阅读2.3k次,点赞5次,收藏4次。在Ubuntu系统下,利用apt-get install安装MySQL时sudo apt-get install mysql-server出现如下问题:解决的办法:使用命令sudo apt-get update更新软件源sudo apt-get update然后再输入 sudo apt-get install mysql-server 就可以安装了sudo apt-get install mysql-server..._unable to locate package mysql-server
调用超时或找不到服务器,进入某个功能(如:基础档案、填制凭证等)提示:连接超时或数据服务器连接失败...-程序员宅基地
文章浏览阅读89次。用友软件增加明细科目时提示新增会计科目是,提示上级科目已经使用,新增科目将自动改为上级科目的设置已经使用的科目如何增加明细科目在软件操作过程中,经常会遇到对已经使用的科目,要求增加其明细科目的问题。科目已经使用,有两种情形:1、该科目没有期初余额或本期发生数,但在月末转账定义中使用。2、该科目已经有期初余额或本期发生数。下面分别就这两种情形的处理方法,分别进行介绍。情形1:该科目没有期初余额或本期..._调用超时应用集成平台连接异常
东北大学c语言编程及答案,东北大学c语言编程试题及其答案.doc-程序员宅基地
文章浏览阅读730次。东北大学C语言题库第一部分( 选择题 )1、构成C语言的基本单位是________。你的答案是:正确答案是:B过程函数语句命令2、设x为整型变量,不能正确表达数学关系:55<="">x>5&&x<10x==6||x==7||x==8||x==9!(x<=5)&&(x<10)3、在C语言中,逻辑运算符的优先级从高到低的排列顺序为__..._以下有关结构体类型描述正确的是 a.结构体类型的大小为其各成员所占内存的总和b.
c语言迪杰斯拉算法,麻烦改成迪杰特拉斯算法-程序员宅基地
文章浏览阅读61次。该楼层疑似违规已被系统折叠隐藏此楼查看此楼#includeusing namespace std;const int n=5; //n表示公园图中顶点个数const int e=7; //e表示公园图中路径bool visited[n+1];#define max 32767class graph{public:int arcs[n+1][n+1]; //领接矩阵int a[n+1][n+1];..._迪特拉斯算法代码
随便推点
Airtest从入门到放弃?不要急,这份免费的“超长”攻略请收好!_airtest官网-程序员宅基地
文章浏览阅读1.4k次,点赞5次,收藏12次。此文章来源于项目官方公众号:“AirtestProject”版权声明:允许转载,但转载必须保留原链接;请勿用作商业或者非法用途前言不知道你有没有遇到这种情况?在刚接触我们的Airtest项目的时候,总是兴致满满、斗志昂扬;但使用一段时间后,却总是被“找不到图片”、“连不上设备”、“录制的脚本不能运行”这些问题劝退。不要着急,今天我们特意跟同学们分享下当年入坑Airtest的经验;希望看完今天这篇攻略,可以让你在入门Airtest的时候少走一些弯路!1.设备连接篇1)连接Android设备A._airtest官网
【Android】adb+shell - 实现滑动、等待、返回自动化_adb shell 滑动-程序员宅基地
文章浏览阅读2.8k次。adb 模拟手机操作,获取 微信读书 时长 -> 虚荣心漫番刷广告_adb shell 滑动
uipath和python哪个好_UiPath从入门到精通视频教程-程序员宅基地
文章浏览阅读251次。匠厂出品,必属精品 Uipath中文社区qq交流群:465630324uipath中文交流社区:https://uipathbbs.comRPA之家qq群:465620839第一课--UiPath的安装与激活第二课--UiPath设计器介绍第三课--UiPath变量介绍第四课--UiPath条件判断第五课--UiPath循环第六课--UiPath整合流程控制语句第七课--UiPath邮件发送之..._uipath和python哪个好
Doolittle分解法(LU分解法)的Python实现_杜立特尔三角分解法python-程序员宅基地
文章浏览阅读7.2k次,点赞8次,收藏17次。在解一般的非奇异矩阵线性方程组的时候,或者在迭代改善算法中,需要使用LU分解法。对于一个一般的非奇异矩阵A=(a11, a12,…,a1n,a21,…ann),可分解为一个下三角矩阵L和一个上三角矩阵U。其中L的主对角线元素都是1.希望得到一个M,最后在需要的时候将M拆分为L和UM=[[u11 u12 u13 ...... u1n l21 u22 u23 ...... u2n ..._杜立特尔三角分解法python
python关键词统计_Python3 利用openpyxl 以及jieba 对帖子进行关键词抽取 ——对抽取的关键词进行词频统计...-程序员宅基地
文章浏览阅读384次。Python3 利用openpyxl 以及jieba 对帖子进行关键词抽取 ——对抽取的关键词进行词频统计20180413学习笔记一、工作前天在对帖子的关键词抽取存储后,发现一个问题。我似乎将每个关键词都存到分离的cell中,这样在最后统计总词频的时候,比较不好处理。于是,上回的那种样式:是不行的,应该把它们放到同一列(行)中,组装成一个list或tuple再进行词频统计。1.读取输出文件“t1..._openpyxl如何关键字出现计数
python在数据分析方面的应用、下列说法正确_智慧树知到大数据分析的python基础答案...-程序员宅基地
文章浏览阅读1.8k次。智慧树知到大数据分析的python基础答案在派生类中可以通过 “ 基类名 . 方法名 ()” 的方式来调用基类中的方法 .下面代码的执行结果是 : ( ) a = 10.99 print( complex(a))numpy 中求最大值方法是: ( )下面代码的输出结果是 : ( ) vlist = list( range(5)) print( vlist)计算numpy中元素个数的方法是: ( ..._关于python在数据分析方面的应用,以下说法正确的是哪些选项