Hadoop 自定义序列化编程_1.package tem_com; 2.import java.io.ioexception; 3-程序员宅基地
package com.cakin.hadoop.mr;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class UserWritable implements WritableComparable<UserWritable> {
private Integer id;
private Integer income;
private Integer expenses;
private Integer sum;
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeInt(id);
out.writeInt(income);
out.writeInt(expenses);
out.writeInt(sum);
}
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.id=in.readInt();
this.income=in.readInt();
this.expenses=in.readInt();
this.sum=in.readInt();
}
public Integer getId() {
return id;
}
public UserWritable setId(Integer id) {
this.id = id;
return this;
}
public Integer getIncome() {
return income;
}
public UserWritable setIncome(Integer income) {
this.income = income;
return this;
}
public Integer getExpenses() {
return expenses;
}
public UserWritable setExpenses(Integer expenses) {
this.expenses = expenses;
return this;
}
public Integer getSum() {
return sum;
}
public UserWritable setSum(Integer sum) {
this.sum = sum;
return this;
}
public int compareTo(UserWritable o) {
// TODO Auto-generated method stub
return this.id>o.getId()?1:-1;
}
@Override
public String toString() {
return id + "\t"+income+"\t"+expenses+"\t"+sum;
}
}package com.cakin.hadoop.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
/*
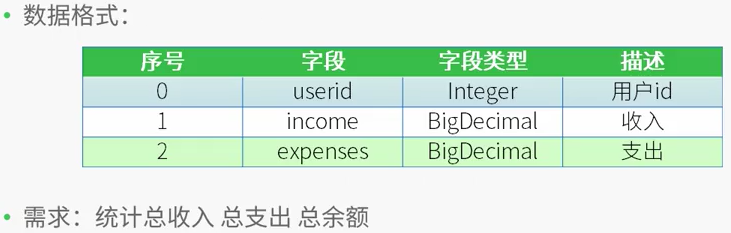
* 测试数据
* 用户id 收入 支出
* 1 1000 0
* 2 500 300
* 1 2000 1000
* 2 500 200
*
* 需求:
* 用户id 总收入 总支出 总的余额
* 1 3000 1000 2000
* 2 1000 500 500
* */
public class CountMapReduce {
public static class CountMapper extends Mapper<LongWritable,Text,IntWritable,UserWritable>
{
private UserWritable userWritable =new UserWritable();
private IntWritable id =new IntWritable();
@Override
protected void map(LongWritable key,Text value,
Mapper<LongWritable,Text,IntWritable,UserWritable>.Context context) throws IOException, InterruptedException{
String line = value.toString();
String[] words = line.split("\t");
if(words.length ==3)
{
userWritable.setId(Integer.parseInt(words[0]))
.setIncome(Integer.parseInt(words[1]))
.setExpenses(Integer.parseInt(words[2]))
.setSum(Integer.parseInt(words[1])-Integer.parseInt(words[2]));
id.set(Integer.parseInt(words[0]));
}
context.write(id, userWritable);
}
}
public static class CountReducer extends Reducer<IntWritable,UserWritable,UserWritable,NullWritable>
{
/*
* 输入数据
* <1,{[1,1000,0,1000],[1,2000,1000,1000]}>
* <2,[2,500,300,200],[2,500,200,300]>
*
* */
private UserWritable userWritable = new UserWritable();
private NullWritable n = NullWritable.get();
protected void reduce(IntWritable key,Iterable<UserWritable> values,
Reducer<IntWritable,UserWritable,UserWritable,NullWritable>.Context context) throws IOException, InterruptedException{
Integer income=0;
Integer expenses = 0;
Integer sum =0;
for(UserWritable u:values)
{
income += u.getIncome();
expenses+=u.getExpenses();
}
sum = income - expenses;
userWritable.setId(key.get())
.setIncome(income)
.setExpenses(expenses)
.setSum(sum);
context.write(userWritable, n);
}
}
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
Configuration conf=new Configuration();
/*
* 集群中节点都有配置文件
conf.set("mapreduce.framework.name.", "yarn");
conf.set("yarn.resourcemanager.hostname", "mini1");
*/
Job job=Job.getInstance(conf,"countMR");
//jar包在哪里,现在在客户端,传递参数
//任意运行,类加载器知道这个类的路径,就可以知道jar包所在的本地路径
job.setJarByClass(CountMapReduce.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(CountMapper.class);
job.setReducerClass(CountReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(UserWritable.class);
//指定最终输出的数据kv类型
job.setOutputKeyClass(UserWritable.class);
job.setOutputKeyClass(NullWritable.class);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中配置的相关参数及job所用的java类在的jar包,提交给yarn去运行
//提交之后,此时客户端代码就执行完毕,退出
//job.submit();
//等集群返回结果在退出
boolean res=job.waitForCompletion(true);
System.exit(res?0:1);
//类似于shell中的$?
}
}[root@centos hadoop-2.7.4]# bin/hdfs dfs -cat /input/data
1 1000 0
2 500 300
1 2000 1000
2 500 200[root@centos hadoop-2.7.4]# bin/yarn jar /root/jar/mapreduce.jar /input/data /output3
17/12/20 21:24:45 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/12/20 21:24:46 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
17/12/20 21:24:47 INFO input.FileInputFormat: Total input paths to process : 1
17/12/20 21:24:47 INFO mapreduce.JobSubmitter: number of splits:1
17/12/20 21:24:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513775596077_0001
17/12/20 21:24:49 INFO impl.YarnClientImpl: Submitted application application_1513775596077_0001
17/12/20 21:24:49 INFO mapreduce.Job: The url to track the job: http://centos:8088/proxy/application_1513775596077_0001/
17/12/20 21:24:49 INFO mapreduce.Job: Running job: job_1513775596077_0001
17/12/20 21:25:13 INFO mapreduce.Job: Job job_1513775596077_0001 running in uber mode : false
17/12/20 21:25:13 INFO mapreduce.Job: map 0% reduce 0%
17/12/20 21:25:38 INFO mapreduce.Job: map 100% reduce 0%
17/12/20 21:25:54 INFO mapreduce.Job: map 100% reduce 100%
17/12/20 21:25:56 INFO mapreduce.Job: Job job_1513775596077_0001 completed successfully
17/12/20 21:25:57 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=94
FILE: Number of bytes written=241391
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=135
HDFS: Number of bytes written=32
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=23672
Total time spent by all reduces in occupied slots (ms)=11815
Total time spent by all map tasks (ms)=23672
Total time spent by all reduce tasks (ms)=11815
Total vcore-milliseconds taken by all map tasks=23672
Total vcore-milliseconds taken by all reduce tasks=11815
Total megabyte-milliseconds taken by all map tasks=24240128
Total megabyte-milliseconds taken by all reduce tasks=12098560
Map-Reduce Framework
Map input records=4
Map output records=4
Map output bytes=80
Map output materialized bytes=94
Input split bytes=94
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=94
Reduce input records=4
Reduce output records=2
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=157
CPU time spent (ms)=1090
Physical memory (bytes) snapshot=275660800
Virtual memory (bytes) snapshot=4160692224
Total committed heap usage (bytes)=139264000
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=41
File Output Format Counters
Bytes Written=32[root@centos hadoop-2.7.4]# bin/hdfs dfs -cat /output3/part-r-00000
1 3000 1000 2000
2 1000 500 500智能推荐
vacode模块使用报错的问题_indesssss.html:1 access to script at 'file:///i:/v-程序员宅基地
文章浏览阅读651次。在vscode中是用模块化的时候会出现报错,提示如下Access to script at ‘file:///F:/%E5%AD%A6%E4%B9%A0/%E7%BA%BF%E4%B8%8BJS/test/js./modul.js’ from origin ‘null’ has been blocked by CORS policy: Cross origin requests are only supported for protocol schemes: http, data, chrome, ch_indesssss.html:1 access to script at 'file:///i:/vscode/cheshi/tesss.js' fro
华三SDN产业链分析-程序员宅基地
文章浏览阅读218次。为什么80%的码农都做不了架构师?>>> ..._h3c virtual converged framework切片
手把手教你开发第一个HarmonyOS (鸿蒙)移动应用_鸿蒙移动应用开发-程序员宅基地
文章浏览阅读1.9w次,点赞44次,收藏268次。AndroidIOSHarmonyOS (鸿蒙)文档概览-HarmonyOS应用开发官网2.1.1 系统的定位搭载该操作系统的设备在系统层⾯融为⼀体、形成超级终端,让设备的硬件能⼒可以弹性 扩展,实现设备之间 硬件互助,资源共享。对消费者⽽⾔,HarmonyOS能够将⽣活场景中的各类终端进⾏能⼒整合,实现不同终端 设备之间的快速连接、能⼒互助、资源共享,匹配合适的设备、提供流畅的全场景体验。⾯向开发者,实现⼀次开发,多端部署。_鸿蒙移动应用开发
AndroidStudio无代码高亮解决办法_android studio 高亮-程序员宅基地
文章浏览阅读2.8k次。AndroidStudio 升级到 4.2.2 版本后,没有代码高亮了,很蛋疼。解决办法是:点开上方的 File,先勾选 Power Save Mode 再取消就可以了。_android studio 高亮
swift4.0 valueForUndefinedKey:]: this class is not key value coding-compliant for the key unity.'_forundefinedkey swift4-程序员宅基地
文章浏览阅读1k次。使用swift4.0整合Unity出现[ valueForUndefinedKey:]: this class is not key value coding-compliant for the key unity.'在对应属性前加@objc 即可。或者调回swift3.2版本_forundefinedkey swift4
Spring Security2的COOKIE的保存时间设置_springsecurity 设置cookie失效时间-程序员宅基地
文章浏览阅读1.3k次。http auto-config="true" access-denied-page="/common/403.htm"> intercept-url pattern="/login.**" access="IS_AUTHENTICATED_ANONYMOUSLY"/> form-login login-page="/login.jsp" defau_springsecurity 设置cookie失效时间
随便推点
Kotlin相关面试题_kotlin面试题-程序员宅基地
文章浏览阅读1.9w次,点赞26次,收藏185次。目录一.请简述下什么是kotlin?它有什么特性?二.Kotlin 中注解 @JvmOverloads 的作用?三.Kotlin中的MutableList与List有什么区别?四.kotlin实现单例的几种方式?五. kotlin中关键字data的理解?相对于普通的类有哪些特点?六.什么是委托属性?简单说一下应用场景?七.kotlin中with、run、apply、let函数的区别?一般用于什么场景?八.kotlin中Unit的应用以及和Java中void的区别?九.Ko_kotlin面试题
HEVC英文缩写及部分概念整理(1)--博主整理_反量化 英文缩写-程序员宅基地
文章浏览阅读2.8k次。有这个想法一方面是确实很多时候会记不得一些缩写是什么意思。另外也是受 http://blog.csdn.net/lin453701006/article/details/52797415这篇博客的启发,本文主要用于自己记忆 内容主要整理自http://blog.sina.com.cn/s/blog_520811730101hmj9.html http://blog.csdn.net/feix_反量化 英文缩写
超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门-程序员宅基地
文章浏览阅读7.3k次,点赞6次,收藏36次。超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门
python怎么输出logistic回归系数_python - Logistic回归scikit学习系数与统计模型的系数 - SO中文参考 - www.soinside.com...-程序员宅基地
文章浏览阅读1.2k次。您的代码存在一些问题。首先,您在此处显示的两个模型是not等效的:尽管您将scikit-learn LogisticRegression设置为fit_intercept=True(这是默认设置),但您并没有这样做statsmodels一;来自statsmodels docs:默认情况下不包括拦截器,用户应添加。参见statsmodels.tools.add_constant。另一个问题是,尽管您处..._sm fit(method
VS2017、VS2019配置SFML_vsllfqm-程序员宅基地
文章浏览阅读518次。一、sfml官网下载32位的版本 一样的设置,64位的版本我没有成功,用不了。二、三、四以下这些内容拷贝过去:sfml-graphics-d.libsfml-window-d.libsfml-system-d.libsfml-audio-d.lib..._vsllfqm
vc——类似与beyondcompare工具的文本比较算法源代码_byoned compare 字符串比较算法-程序员宅基地
文章浏览阅读2.7k次。由于工作需要,要做一个类似bc2的文本比较工具,用红色字体标明不同的地方,研究了半天,自己写了一个简易版的。文本比较的规则是1.先比较文本的行数,2.再比较对应行的字符串的长度3.再比较每一个字符串是否相同。具体代码如下:其中m_basestr和m_mergestr里面存放是待比较的字符串int basecount=m_basestr.GetLength(); int mergec_byoned compare 字符串比较算法