深度学习 第1讲:深度学习简介和感知机原理与实现_python 单层感知机 深度学习-程序员宅基地
而对于阅读深度学习系列文章的广大数据爱好者而言,小编希望大家能有一些机器学习基础,而且小编不会去刻意用很多通俗的语言去描述数学和计算机科学相关的术语和概念,当然小编也会尽力把主要的知识点说的够敞亮,希望大家理解。那么闲话少说,我们正式开启深度学习的学习之旅~
1
机器学习与深度学习
要是说到深度学习,恐怕不得不先提一下机器学习,解释好二者之间的关系。相信大家心中应该有自己对于机器学习概念的理解。小编这里就一句话简单概括一下:机器学习就是从历史数据中探索和训练出数据的普遍规律,将其归纳为相应的数学模型,并对未知的数据进行预测的过程。至于在这个过程中我们碰到的各种各样的问题,比如数据质量、模型评价标准、训练优化方法、过拟合等一系列关乎机器学习模型生死的问题,小编就不展开来说了,自己去补机器学习知识哈。
在机器学习中,我们有很多很多已经相当成熟了的模型和算法。(这里厘一下模型和算法的概念,小编认为,通常我们所说的像SVM之类的所谓机器学习十大算法其实不应该称之为算法,更应该称其为模型,机器学习的算法应该是在给定模型和训练策略的情况下采取的优化算法,比如梯度下降、牛顿法之类。当然,一般情况下将模型和算法混合称呼也不碍事,毕竟模型中本身就包含着计算规则的意思。)在这很多种机器学习模型中,有一种很厉害的模型,那就是人工神经网络。这种模型从早期的感知机发展而来,对任何函数都有较好的拟合性,但自上个世纪90年代一直到2012年深度学习集中爆发前夕,神经网络受制于计算资源的限制和较差的可解释性,一直处于发展的低谷阶段。之后大数据兴起,计算资源也迅速跟上,加之2012年ImageNet竞赛冠军采用的AlexNet卷积神经网络一举将图片预测的 top5 错误率降至16.4%,震惊了当时的学界和业界。从此之后,原本处于研究边缘状态的神经网络又迅速热了起来,深度学习也逐渐占据了计算机视觉的主导地位。
扯了这么多,无非就是想让大家知道,以神经网络为核心的深度学习理论是机器学习的一个领域分支,所以深度学习其本质上也必须是遵循一些机器学习的基本要义和法则的。传统的机器学习中,我们需要训练的是结构化的数值数据,比如说预测销售量、预测某人是否按时还款等等。但在深度学习中,我们的训练输入就不大是常规的数据了,它可能是一张图像、一段语言、一段对话语料或是一段视频。深度学习要做的就是我丢一张猫的图片到神经网络里,它的输出是猫或者cat这样的标签,丢进去一段语音,它输出的是你好这样的文本。所以机器学习/深度学习的核心任务就是找(训练)一个模型,它能够将我们的输入转化为正确的输出。

(图片来自台湾大学李宏毅教授的deep learning tutorial ppt)
2
感知机与神经网络
就像上面那幅图展示的一样,深度学习看起来就像是一个黑箱子,给定输入之后就出来预测结果,中间的细节很难搞清楚。在实际生产环境下,调用像 tensorflow 这样优秀的深度学习计算框架能够帮助我们快速搭建起一个深度学习项目,但在学习深度学习的过程中,小编并不建议大家一开始就上手各种深度学习框架,希望大家能和小编一道,在把基本的原理搞明白之后利用 python 或者 R 自己手动去编写模型和实现算法细节。
所以,为了学习各种结构的神经网络,我们需要从头开始。感知机作为神经网络和支持向量机的理论基础,相信任何有机器学习基础的同学都清楚其模型细节。简单而言,感知机就是一个旨在建立一个线性超平面对线性可分的数据集进行分类的线性模型。其基本结构如下所示:
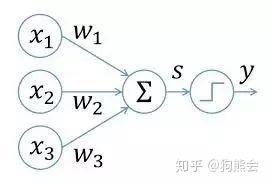
上图从左到右为感知机模型的计算执行方向,模型接受了X1、X2、X3三个输入,将输入与权值参数W进行加权求和并经过 sigmoid 函数进行激活,将激活结果作为 y 进行输出。这便是感知机执行前向计算的基本过程。这样就行了吗?当然不行。按照李航老师的统计学习三要素来打分,刚刚我们只解释了模型,对策略和算法并未解释。当我们执行完前向计算得到输出之后,模型需要根据你的输出和实际的输出按照损失函数计算当前损失,计算损失函数关于权值和偏置的梯度,然后根据梯度下降法更新权值和偏置。经过不断的迭代调整权值和偏置使得损失最小,这便是完整的单层感知机的训练过程。
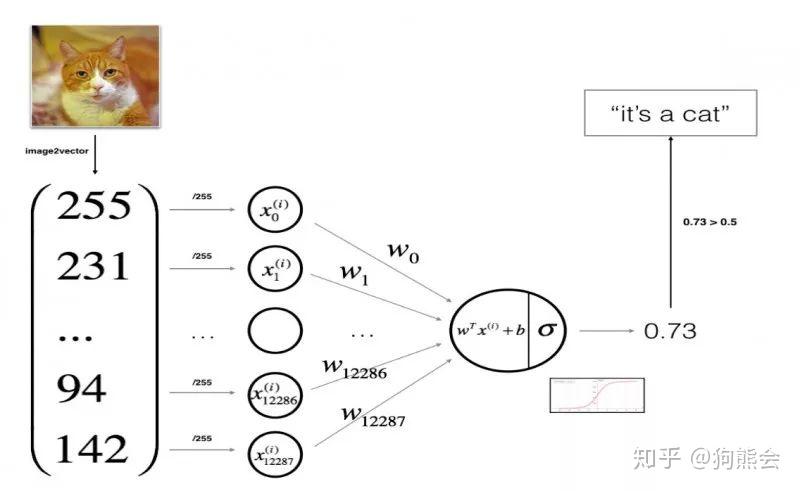
输入为图像的感知机计算过程(图片来自吴恩达老师deeplearningai作业截图)
上述的单层感知机包含两层神经元,即输入与输出神经元,可以非常容易的实现逻辑与、或和非等线性可分情形,但终归而言,这样的一层感知机的学习能力是非常有限的,对于像异或这样的非线性情形,单层感知机就搞不定了。其学习过程会呈现一定程度的振荡,权值参数 w 难以稳定下来,最终不能求得合适的解。
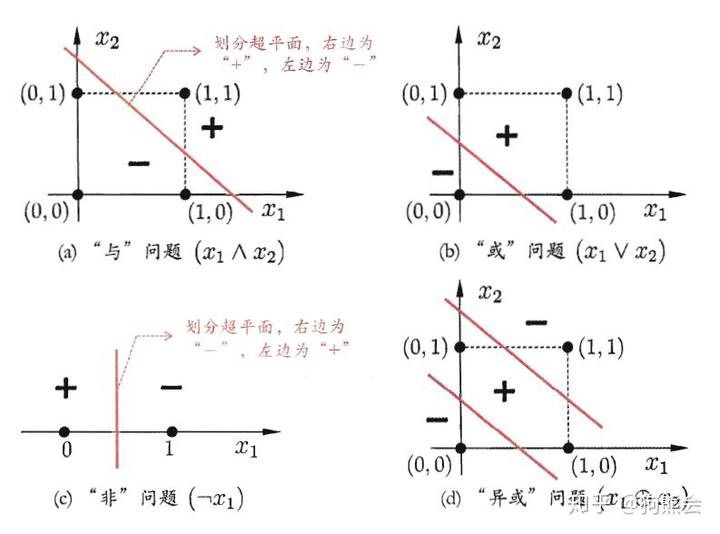
单层感知机难以解决异或问题(截图于周志华老师的《机器学习》)
对于非线性可分的情况,在感知机基础上一般有了两个解决方向,一个就是著名的支持向量机模型,旨在通过核函数映射来处理非线性的情况,这里我们不多谈,读者朋友们可以去回顾复习机器学习中有关的内容,而另一种就是神经网络模型。这里的神经网络模型也叫多层感知机(MLP: Muti-Layer Perception),与单层的感知机在结构上的区别主要在于 MLP 多了若干隐藏层,这使得神经网络对非线性的情况拟合能力大大增强。
一个单隐层的人工神经网络的结构如下图所示:
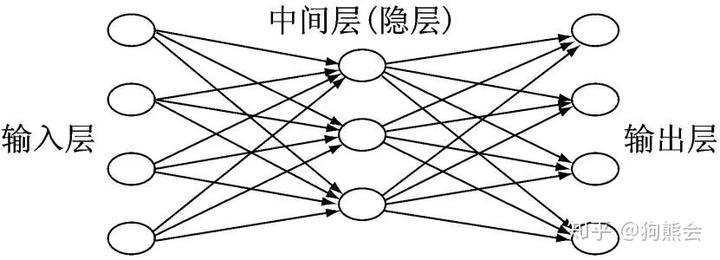
可以看到相较于两层神经元的单层感知机,多层感知机中间多了一个隐藏层,称为隐藏层的含义在于神经网络的训练过程中我们只能观察到输入和输出层的数据,对于中间的隐藏层我们是看不见的,因而在深度神经网络(DNN)中,对于中间看不见又难以进行解释的隐藏层又有个黑箱子的称呼。
含隐藏层的神经网络是如何训练的呢?跟感知机一样,神经网络的训练依然是包含前向计算和反向传播两个主要过程。当然,单层感知机没有反向传播的概念,通常是直接建立损失函数对权值和偏置参数的梯度优化。前向计算过程这里不再细述,就是权值偏置与输入的线性加权和激活操作,在隐藏层上有个嵌套的过程。这里我们重点讲一下反向传播算法(Error BackPropagation,因而也叫误差逆传播),作为神经网络的训练算法,反向传播算法可谓是目前最成功的神经网络学习算法了。我们通常说的 BP 神经网络也就是指应用反向传播算法进行训练的神经网络模型。
那反向传播算法究竟是怎样个工作机制呢?前方高能,需要大家自己补习微积分知识。因为小编实在是没有不借助公式把反向传播讲清楚的能力。假设以一个两层(即单隐层)网络为例,也就是上图中的网络结构,小编带大家详细推导一下反向传播的基本过程。
我们假设输入层为 X ,输入层与隐藏层之间的权值和偏置分别为 W1 和 b1,线性加权计算结果为 Z1 = W1*X + b1,采用 sigmoid 激活函数,隐藏层是激活输出为 a1 = σ(Z1)。而隐藏层到输出层的权值和偏置分别为 W2 和 b2,线性加权计算结果为 Z2 = W2*a1+ b2,激活输出为 a2 = σ(Z2)。所以这个两层网络的前向计算过程为 X-Z1-a1-Z2-a2。
所以反向传播的直观理解就是将上述前向计算过程反过来,但必须是梯度计算的方向反过来,假设我们这里采用交叉熵损失函数:
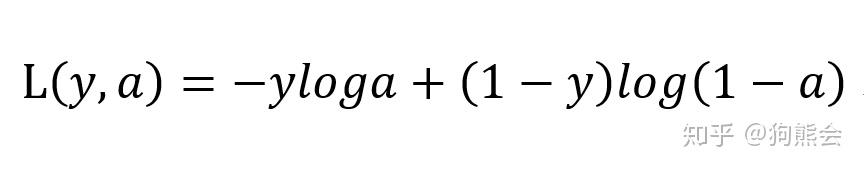
反向传播是基于梯度下降策略的,主要是以目标参数的负梯度方向对参数进行更新,所以基于损失函数对前向计算过程中各个变量进行梯度计算就是非常必要的了。将前向计算过程反过来,那基于损失函数的梯度计算顺序就是 da2-dZ2-dW2-db2-da1-dZ1-dW1-db1。一大堆微分符号!聪明如你应该可以看到我们马上要进行一波链式求导操作。我们从输出 a2 开始进行反向推导。输出层激活输出为 a2,那首先计算损失函数L(y, a) 关于 a2 的微分 da2,影响输出 a2 的是谁呢?由前向传播可知 a2 是由 Z2 经激活函数激活计算而来的,所以计算损失函数关于 Z2 的导数 dZ2 必须经由 a2 进行复合函数求导,即微积分上常说的链式求导法则。然后继续往前推,影响 Z2 的又是哪些变量呢?由前向计算 Z2 = W2*a1+ b2 可知影响 Z2 的有 W2、a1 和 b2,继续按照链式求导法则进行求导即可。最终以交叉熵损失函数为代表的两层神经网络的反向传播向量化求导计算公式如下所示:

在有了梯度计算结果之后,我们便可根据权值更新公式对权值和偏置参数进行更新了,具体计算公式如下,其中 η 为学习率,是个超参数,需要我们在训练时手动指定,当然也可以对其进行调参取得最优超参数。
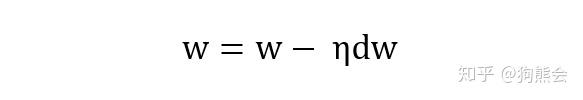
以上便是 BP 神经网络模型和算法的基本工作流程,简单而言就是前向计算得到输出,反向传播调整参数,最后以得到损失最小时的参数为最优学习参数。神经网络的基本总结流程如下图所示:

训练一个 BP 神经网络并非难事,我们有足够优秀的深度学习计算框架通过几行代码就可以搭建起一个全连接网络。但是为了学习和掌握神经网络的基本思维范式和锻炼实际的编码能力,希望大家能够利用 python 或者 R 在不调用任何算法包的情况下根据算法原理手动实现一遍神经网络模型。最后以一个神经网络可视化的动图给大家动态的展示一下神经网络的训练过程:
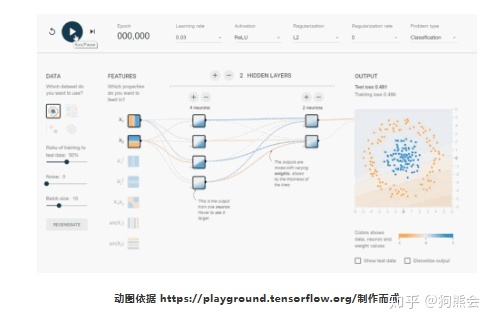
第一讲的内容到这里就结束了,在深度学习第一讲中,我们了解了深度学习和机器学习的基本关系和发展历程,对神经网络的理论基础有了更深层次的学习和掌握。咱们下期见!
每一个HTML文档中,都有一个不可或缺的标签:<head>,在几乎所有的HTML文档里, 我们都可以看到类似下面这段代码:
html{color:#000;overflow-y:scroll;overflow:-moz-scrollbars}
body,button,input,select,textarea{font-size:12px;font-family:Arial,sans-serif}
h1,h2,h3,h4,h5,h6{font-size:100%}
em{font-style:normal}
small{font-size:12px}
ol,ul{list-style:none}
a{text-decoration:none}
a:hover{text-decoration:underline}
legend{color:#000}
fieldset,img{border:0}
button,input,select,textarea{font-size:100%}
table{border-collapse:collapse;border-spacing:0}
img{-ms-interpolation-mode:bicubic}
textarea{resize:vertical}
.left{float:left}
.right{float:right}
.overflow{overflow:hidden}
.hide{display:none}
.block{display:block}
.inline{display:inline}
.error{color:red;font-size:12px}
button,label{cursor:pointer}
.clearfix:after{content:'\20';display:block;height:0;clear:both}
.clearfix{zoom:1}
.clear{clear:both;height:0;line-height:0;font-size:0;visibility:hidden;overflow:hidden}
.wordwrap{word-break:break-all;word-wrap:break-word}
.s-yahei{font-family:arial,'Microsoft Yahei','微软雅黑'}
pre.wordwrap{white-space:pre-wrap}
body{text-align:center;background:#fff;width:100%}
body,form{position:relative;z-index:0}
td{text-align:left}
img{border:0}
#s_wrap{position:relative;z-index:0;min-width:1000px}
#wrapper{height:100%}
#head .s-ps-islite{_padding-bottom:370px}
#head_wrapper.s-ps-islite{padding-bottom:370px}#head_wrapper.s-ps-islite #s_lm_wrap{bottom:298px;background:0 0!important;filter:none!important}#head_wrapper.s-ps-islite .s_form{position:relative;z-index:1}#head_wrapper.s-ps-islite .fm{position:absolute;bottom:0}#head_wrapper.s-ps-islite .s-p-top{position:absolute;bottom:40px;width:100%;height:181px}#head_wrapper.s-ps-islite #s_lg_img,#head_wrapper.s-ps-islite#s_lg_img_aging,#head_wrapper.s-ps-islite #s_lg_img_new{position:static;margin:33px auto 0 auto}.s_lm_hide{display:none!important}#head_wrapper.s-down #s_lm_wrap{display:none}.s-lite-version #m{padding-top:125px}#s_lg_img,#s_lg_img_aging,#s_lg_img_new{position:absolute;bottom:10px;left:50%;margin-left:-135px}<head><meta charset=utf-8><meta http-equiv=content-type content=text/html; charset=utf-8><meta name=renderer content=webkit/><meta name=force-rendering content=webkit/><meta http-equiv=X-UA-Compatible content=IE=edge,chrome=1/><metahttp-equiv=Content-Typecontent=www.czjy.cn;charset=gb2312><meta name=viewport content=width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no></head>.s-ps-sug table{width:100%;background:#fff;cursor:default}.s-ps-sug td{color:#000;font:14px arial;height:25px;line-height:25px;padding:0 8px}.s-ps-sug td b{color:#000}.s-ps-sug .mo{background:#ebebeb;cursor:pointer}.s-ps-sug .ml{background:#fff}.s-ps-sug td.sug_storage{color:#7a77c8}.s-ps-sug td.sug_storage b{color:#7a77c8}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .mo .sug_del{display:block}
.s-ps-sug .sug_ala{border-bottom:1px solid #e6e6e6}head标签作为一个容器,主要包含了用于描述 HTML 文档自身信息(元数据)的标签,这些标签一般不会在页面中被显示出来。
智能推荐
Codeforces Round #530 (Div. 1) 1098A Sum in the tree_cf1098a sum in the tree-程序员宅基地
文章浏览阅读2.4k次。A. Sum in the treeMitya has a rooted tree with nn vertices indexed from 11 to nn, where the root has index 11. Each vertex vv initially had an integer number av≥0av≥0 written on it. For every vertex ..._cf1098a sum in the tree
C++——std::String-程序员宅基地
文章浏览阅读2.1k次。link写在前面这一篇博客系统学习一下C++中String类的相关函数。这个类在之前做题的时候就经常遇到,其实说白了,它也就是一个vector < char >。但是,它又有一些独特的函数,可以在做题的时候简化代码,提高效率。所以在这一篇博客,就根据CPlusPlus官网中< string >中的内容做一个整理。自己整理之外,还有一些优秀的整理资料可供参考:std::string用法总结。string类与头文件包含string即为字符串。string是C++标准库的一个重要_std::string
python中的class Solution(object):的含义与类继承与类、对象概念的详解-程序员宅基地
文章浏览阅读9.1k次,点赞26次,收藏86次。python中的class Solution(object):的含义与类继承与类、对象概念的详解_class solution
读《疯狂的程序员》后感-程序员宅基地
文章浏览阅读1k次。读《疯狂的程序员》后感 花了几天功夫,把《疯狂的程序员》这本书看完了,这本书,是我无意间在校图书馆看到的,出版日期是2008年的,到现在为止已经过去好几年了,作者绝影。是在csdn上连载的博客,不过不知道作者在csdn上的名字是什么,自己搜索找,竟然没找到,很遗憾。书中讲述的是作者从大学时期到工作,再到创业7年时间的精力,说实话,作者的语文功底非常不错,能够生动的刻画
可后悔贪心 -- 解题报告_e. buy low sell high-程序员宅基地
文章浏览阅读244次。感觉普通贪心是每一个维度都是平等的,没有优先级。而可后悔贪心是存在某个维度是不可变的,不能直接用排序或者堆进行维护,常常需要经过某种处理,通过挖掘出题目中关于不可变维度的特殊性质,使其可以用排序或者堆等数据结构进行贪心。可后悔贪心常用堆(priority_queue)进行维护。_e. buy low sell high
AMCL源码解析-程序员宅基地
文章浏览阅读6.5k次,点赞14次,收藏93次。AMCL是ros导航中的一个定位功能包。其实现了机器人在2D平面中基于概率方法的定位系统。该方法使用粒子滤波器来针对已知地图跟踪机器人的位姿。MCL与AMCL的区别它们最重要的区别应该是重采用过程。AMCL在采样过程中仍然会随机的增加小数量的粒子。这一步骤正式为了解决MCL不能处理的重定位问题。当粒子逐渐聚集,其它地方的粒子将慢慢消失。对于MCL来说,如果此时将机器人搬动到另一个地方。此时原来..._amcl源码
随便推点
ACM模式输入输出攻略 | C++篇-程序员宅基地
文章浏览阅读1.4w次,点赞97次,收藏328次。本文内容干货非常非常多,从笔试面试环境的要点,到C++输入输出的具体函数,再到几乎覆盖全部情况的ACM模式写法,最后也给出了链表和二叉树的定义和输入输出。_acm模式
uni-app实现Android分享到微信朋友圈和微信好友_uniapp实现app微信分享好友和朋友圈需要到微信开放平台申请吗-程序员宅基地
文章浏览阅读2.6k次。最近使用uniapp开发app,使用开发环境中使用微信分享功能时可以正常分享到微信好友或者朋友圈,但是发布后提示,经过百度后发现需要在微信开放平台申请。附上步骤在项目中打开manifest.json,点击App模块权限配置,给Share(分享)打勾,给这个App加一个分享权限。点击App SDK配置,进去找到分享,填写appid那么问题来了,appid从哪弄呢?前往微信开放平台https://open.weixin.qq.com/注册,登录创建移动应用按要_uniapp实现app微信分享好友和朋友圈需要到微信开放平台申请吗
使用docker安装部署oracle12.2_docker 官方oracle 12.2安装包-程序员宅基地
文章浏览阅读9.6k次,点赞2次,收藏6次。1. 步骤在Mac上安装docker使用oracle的dockerfile,构建image在docker中运行oracle实例启动,停止oracle docker容器连接数据库 2. 在Mac上安装docker到docker store下载docker-for-mac。我们需要适当调整一下cpu内存分配,如4核CPU,16G内存。 点击reveal in f..._docker 官方oracle 12.2安装包
Javascript 笔记三-程序员宅基地
文章浏览阅读50次。1. 检测变量是否是非数字的方法是? isNaN(变量) 结果:非数字为true。数字为false if嵌套2. switch语法格式? 注意点 switch(表达式){ case 常量表达式: 语句体; break; case 常量表达式: 语句体; break; 。。。 default: ...
Ionic4—UI组件之表单&双向数据绑定_ionic 动态绑定数据-程序员宅基地
文章浏览阅读974次。目录一、概述二、代码示例三、效果图一、概述二、代码示例Angular中ngModel指令实现双向数据绑定,ngFor实现遍历。组件的属性使用动态数据作为参数时,属性名用中括号包裹。单行文本框<ion-list> <ion-item> <ion-label>用户名:</ion-label>..._ionic 动态绑定数据
PyQt5之QDrag拖放按钮小部件学习_pyqt qdrag-程序员宅基地
文章浏览阅读1.1k次。在下面的示例中,我们将演示如何拖放按钮小部件。from PyQt5.Qt import QPushButton, QWidget, QApplicationfrom PyQt5.QtCore import Qt, QMimeDatafrom PyQt5.QtGui import QDragimport sys#按钮类class Button(QPushButton): d..._pyqt qdrag