大数据集群迁移整理_hadoop数据迁移-程序员宅基地
技术标签: 程序人生
大数据技术之集群数据迁移
一、Hadoop集群数据迁移
1. 迁移之前需要考虑的问题
-
迁移总数据量有多少? -
新老集群之间的带宽有多少?能否全部用完?为了减少对线上其他业务的影响最多可使用多少带宽? -
如何限制迁移过程中使用的带宽? -
迁移过程中,哪些文件可能发生删除,新增数据的情况?新数据和旧数据怎么处理?哪些目录可能会发生新增文件的情况? -
迁移后的数据一致性校验怎么做? -
迁移后的HDFS文件权限如何跟老集群保持一致?
2. 迁移方案
1、迁移数据量评估
通过hdfs dfs -du -h / 命令查看各目录总数据量。按业务划分,统计各业务数据总量。
2、制定迁移节奏
由于数据量大,带宽有限,HDFS中的文件每天随业务不断变化,所以在文件变化之前全部迁移完成是不现实的。建议按业务、分目录、分批迁移。
3、迁移工具选择
使用Hadoop自带数据迁移工具Distcp,只需要简单的命令即可完成数据迁移。
# hadoop distcp hdfs://nn1:8020/data hdfs://nn2:8020/
4、迁移时间评估
由于老集群每天仍然在使用,为了减小对线上业务的影响,尽量选择老集群低负载运行的时间段来进行数据迁移
5、对新老集群之间的网络进行硬件改造
咨询运维同学,新老集群之间的最大传输带宽是多少,如果带宽跑满的话会不会影响线上其他业务。能否对新老集群之间的网络进行硬件改造,例如通过新老集群之间搭网线的方式来提升网络传输的带宽并消除对其他线上业务的影响。
6、数据迁移状况评估
在完成上面所有准备之后,先尝试进行小数据量的迁移,可以先进行100G的数据迁移、500G的数据迁移、1T的数据迁移,以评估数据迁移速率并收集迁移过程中遇到的问题。
3. 迁移工具Distcp
工具使用很简单,只需要执行简单的命令即可开始数据迁移,可选参数如下: hadoop distcp 源HDFS文件路径 目标HDFS文件路径 同版本集群拷贝(或者协议兼容版本之间的拷贝)使用HDFS协议
hadoop distcp hdfs://src-name-node:3333/user/src/dir hdfs://dst-namenode:4444/user/dst/dir
不同版本集群拷贝(比如1.x到2.x)使用hxp协议或者webhdfs协议,都是使用hdfs的HTTP端口
hadoop distcp hftp://src-name-node:80/user/src/dir hftp://dst-namenode:80/user/dst/dir
hadoop distcp webhdfs://src-name-node:80/user/src/dir webhdfs://dst-namenode:80/user/dst/dir
-
1、Distcp的原理
Distcp的本质是一个MapReduce任务,只有Map阶段,没有Reduce阶段,具备分布式执行的特性。在Map任务中从老集群读取数据,然后写入新集群,以此来完成数据迁移。
-
2、迁移期间新老两个集群的资源消耗是怎样的?
Distcp是一个MapReduce任务,如果在新集群上执行就向新集群的Yarn申请资源,老集群只有数据读取和网络传输的消耗。
-
3、如何提高数据迁移速度?
Distcp提供了 -m 参数来设置map任务的最大数量(默认20),以提高并发性。注意这里要结合最大网络传输速率来设置。
-
4、带宽如何限制?
Distcp提供了 -bandwidth 参数来控制单个Map任务的最大带宽,单位是MB。
-
5、迁移之后的数据一致性怎么校验?
Distcp负责进行CRC校验,可以通过-skipcrccheck参数来跳过校验来提供性能。
-
6、迁移之后的文件权限是怎样的?
Distcp提供了 -p 参数来在新集群里保留状态(rbugpcaxt)(复制,块大小,用户,组,权限,校验和类型,ACL,XATTR,时间戳)。如果没有指定 -p 参数,权限是执行MapReduce任务的用户权限,迁移完成以后需要手动执行chown命令变更。
-
7、迁移的过程中老集群目录新增了文件,删除了文件怎么办?
把握好迁移节奏,尽量避免这些情况的出现。Distcp在任务启动的时候就会将需要copy的文件列表从源HDFS读取出来。如果迁移期间新增了文件,新增的文件会被漏掉。删除文件会导致改文件copy失败,可以通过 -i参数忽略失败。
-
8、迁移中遇到文件已存在的情况怎么办?
Distcp提供了-overwrite 参数来覆盖已存在的文件。
-
9、迁移了一半,任务失败了怎么办?
删除掉新集群中的脏数据,重新执行迁移命令。不加-overwrite参数,来跳过已存在的文件。
-
10、遇到需要对一个文件增量同步怎么办?
Distcp提供-append参数将源HDFS文件的数据新增进去而不是覆盖它。
二、迁移步骤演示
1)准备两套集群,我这使用apache集群和CDH集群。  2)启动集群
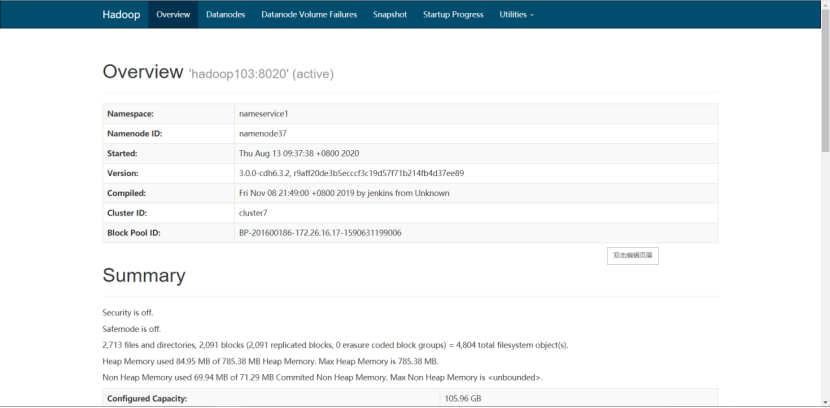
2)启动集群 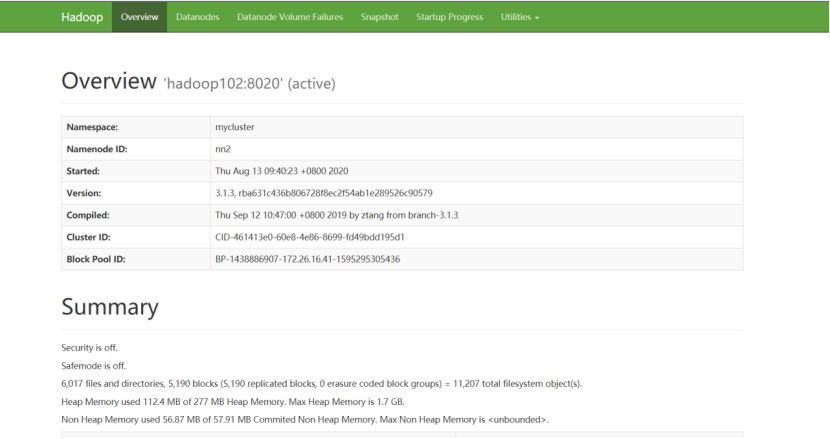
 3)启动完毕后,将apache集群中,hive库里dwd,dws,ads三个库的数据迁移到CDH集群
3)启动完毕后,将apache集群中,hive库里dwd,dws,ads三个库的数据迁移到CDH集群 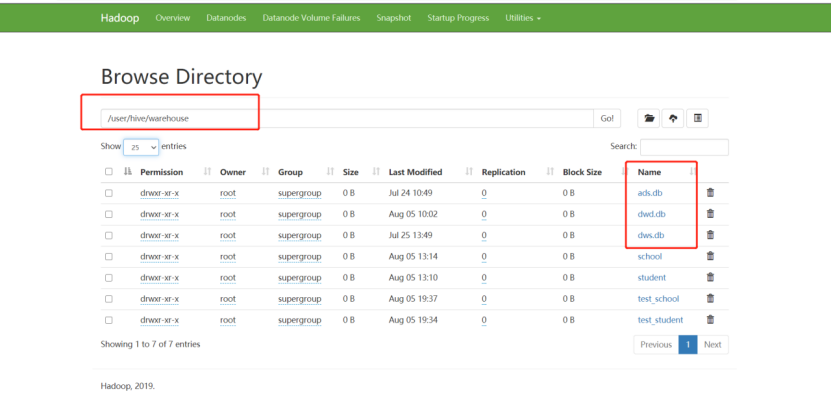
 4)在apache集群里hosts加上CDH Namenode对应域名并分发给各机器
4)在apache集群里hosts加上CDH Namenode对应域名并分发给各机器
[root@hadoop101 ~]# vim /etc/hosts
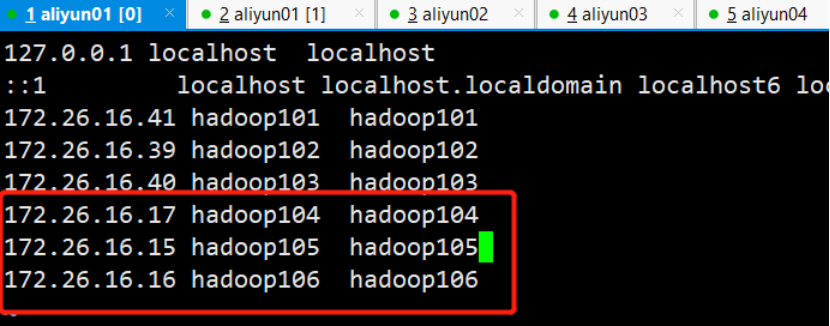
[root@hadoop101 ~]# scp /etc/hosts hadoop102:/etc/ [root@hadoop101 ~]# scp /etc/hosts hadoop103:/etc/
5)因为集群都是HA模式,所以需要在apache集群上配置CDH集群,让distcp能识别出CDH的nameservice
[root@hadoop101 hadoop]# vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
<!--配置nameservice-->
<property>
<name>dfs.nameservices</name>
<value>mycluster,nameservice1</value>
</property>
<!--指定本地服务-->
<property>
<name>dfs.internal.nameservices</name>
<value>mycluster</value>
</property>
<!--配置多NamenNode-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop101:8020</value>
</property>
<property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop102:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop103:8020</value>
</property>
<!--配置nameservice1的namenode服务-->
<property>
<name>dfs.ha.namenodes.nameservice1</name>
<value>namenode30,namenode37</value>
</property>
<property>
<name>dfs.namenode.rpc-address.nameservice1.namenode30</name>
<value>hadoop104:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.nameservice1.namenode37</name>
<value>hadoop106:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.nameservice1.namenode30</name>
<value>hadoop104:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.nameservice1.namenode37</name>
<value>hadoop106:9870</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.nameservice1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--为NamneNode设置HTTP服务监听-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop101:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop102:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hadoop103:9870</value>
</property>
<!--配置HDFS客户端联系Active NameNode节点的Java类-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
6)修改CDH hosts
[root@hadoop101 ~]# vim /etc/hosts
7)进行分发 这里的hadoop104,hadoop105,hadoop106分别对应apache的hadoop101,hadoop102,hadoop103
[root@hadoop101 ~]# scp /etc/hosts hadoop102:/etc/
[root@hadoop101 ~]# scp /etc/hosts hadoop103:/etc/
8)同样修改CDH集群配置,在所有hdfs-site.xml文件里修改配置
<property>
<name>dfs.nameservices</name>
<value>mycluster,nameservice1</value>
</property>
<property>
<name>dfs.internal.nameservices</name>
<value>nameservice1</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop104:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop105:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop106:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop104:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop105:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hadoop106:9870</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
9)最后注意:
重点由于Apahce集群和CDH集群3台集群都是hadoop101,hadoop102,hadoop103所以要关闭域名访问,使用IP访问 CDH把钩去了
10)apache设置为false
11)再使用hadoop distcp命令进行迁移
-Dmapred.job.queue.name指定队列,默认是default队列。上面配置集群都配了的话,那么在CDH和apache集群下都可以执行这个命令
[root@hadoop101 hadoop]# hadoop distcp -Dmapred.job.queue.name=hive webhdfs://mycluster:9070/user/hive/warehouse/dwd.db/ hdfs://nameservice1/user/hive/warehouse
12)会启动一个MR任务,正在迁移
13)查看cdh 9870 http地址
14)数据已经成功迁移。数据迁移成功之后,接下来迁移hive表结构,编写shell脚本
[root@hadoop101 module]# vim exportHive.sh
#!/bin/bash
hive -e "use dwd;show tables">tables.txt
cat tables.txt |while read eachline
do
hive -e "use dwd;show create table $eachline">>tablesDDL.txt
echo ";" >> tablesDDL.txt
done
15)执行脚本后将tablesDDL.txt文件分发到CDH集群下
[root@hadoop101 module]# scp tablesDDL.txt hadoop104:/opt/module/
16)然后CDH下导入此表结构,先进到CDH的hive里创建dwd库
[root@hadoop101 module]# hive
hive> create database dwd;
17)创建数据库后,边界tablesDDL.txt在最上方加上use dwd;
18)并且将createtab_stmt都替换成空格
[root@hadoop101 module]# sed -i s"#createtab_stmt# #g" tablesDDL.txt
19)最后执行hive -f命令将表结构导入
[root@hadoop101 module]# hive -f tablesDDL.txt
20)最后将表的分区重新刷新下,只有刷新分区才能把数据读出来,编写脚本
[root@hadoop101 module]# vim msckPartition.sh
#!/bin/bash
hive -e "use dwd;show tables">tables.txt
cat tables.txt |while read eachline
do
hive -e "use dwd;MSCK REPAIR TABLE $eachline"
done
[root@hadoop101 module]# chmod +777 msckPartition.sh
[root@hadoop101 module]# ./msckPartition.sh
21)刷完分区后,查询表数据 
有赞大数据离线集群迁移实战
一、背景
有赞是一家商家服务公司,向商家提供强大的基于社交网络的,全渠道经营的 SaaS 系统和一体化新零售解决方案。随着近年来社交电商的火爆,有赞大数据集群一直处于快速增长的状态。在 2019 年下半年,原有云厂商的机房已经不能满足未来几年的持续扩容的需要,同时考虑到提升机器扩容的效率(减少等待机器到位的时间)以及支持弹性伸缩容的能力,我们决定将大数据离线 Hadoop 集群整体迁移到其他云厂商。
在迁移前我们的离线集群规模已经达到 200+ 物理机器,每天 40000+ 调度任务,本次迁移的目标如下:
-
将 Hadoop 上的数据从原有机房在有限时间内全量迁移到新的机房 -
如果全量迁移数据期间有新增或者更新的数据,需要识别出来并增量迁移 -
对迁移前后的数据,要能对比验证一致性(不能出现数据缺失、脏数据等情况) -
迁移期间(可能持续几个月),保证上层运行任务的成功和结果数据的正确
有赞大数据离线平台技术架构
上文说了 Hadoop 集群迁移的背景和目的,我们回过头来再看下目前有赞大数据离线平台整体的技术架构,如图1.1所示,从低往上看依次包括: 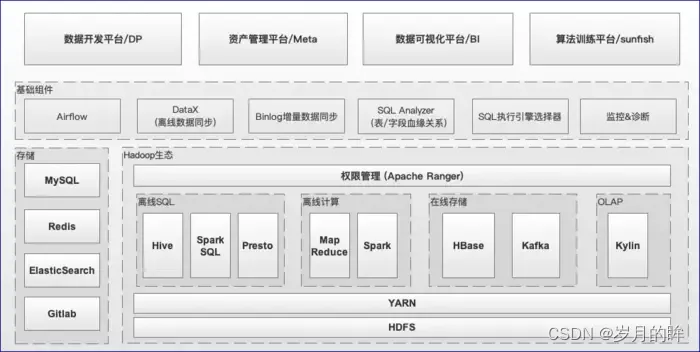 图1.1 有赞大数据离线平台的技术架构
图1.1 有赞大数据离线平台的技术架构
-
Hadoop 生态相关基础设施,包括 HDFS、YARN、Spark、Hive、Presto、HBase、Kafka、Kylin等 -
基础组件,包括 Airflow (调度)、DataX (离线数据同步)、基于binlog的增量数据同步、SQL解析 -
执行引擎选择服务、监控&诊断等 -
平台层面,包括: 数据开发平台(下文简称DP)、资产管理平台、数据可视化平台、算法训练平台等 本次迁移会涉及到从底层基础设施到上层平台各个层面的工作。
二、方案调研
在开始迁移之前,我们调研了业界在迁移 Hadoop 集群时,常用的几种方案:
2.1 单集群
两个机房公用一个 Hadoop 集群(同一个Active NameNode,DataNode节点进行双机房部署),具体来讲有两种实现方式:
-
(记为方案A) 新机房DataNode节点逐步扩容,老机房DataNode节点逐步缩容,缩容之后通过 HDFS 原生工具 Balancer 实现 HDFS Block 副本的动态均衡,最后将Active NameNode切换到新机房部署,完成迁移。这种方式最为简单,但是存在跨机房拉取 Shuffle 数据、HDFS 文件读取等导致的专线带宽耗尽的风险,如图2.1所示 -
(记为方案B) 方案 A 由于两个机房之间有大量的网络传输,实际跨机房专线带宽较少情况下一般不会采纳,另外一种带宽更加友好的方案是: -
通过Hadoop 的 Rack Awareness 来实现 HDFS Block N副本双机房按比例分布(通过调整 HDFS 数据块副本放置策略,比如常用3副本,两个机房比例为1:2) -
通过工具(需要自研)来保证 HDFS Block 副本按比例在两个机房间的分布(思路是:通过 NameNode 拉取 FSImage,读取每个 HDFS Block 副本的机房分布情况,然后在预定限速下,实现副本的均衡) 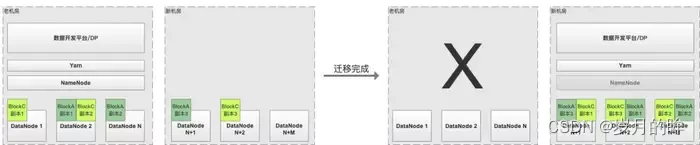
图2.1 单集群迁移方案 优点:
对用户透明,基本无需业务方投入
数据一致性好
相比多集群,机器成本比较低
缺点:
需要比较大的跨机房专线带宽,保证每天增量数据的同步和 Shuffle 数据拉取的需要
需要改造基础组件(Hadoop/Spark)来支持本机房优先读写、在限速下实现跨机房副本按比例分布等
最后在完成迁移之前,需要集中进行 Namenode、ResourceManager 等切换,有变更风险
2.2 多集群
在新机房搭建一套新的 Hadoop 集群,第一次将全量 HDFS 数据通过 Distcp 拷贝到新集群,之后保证增量的数据拷贝直至两边的数据完全一致,完成切换并把老的集群下线,如图2.2所示。
这种场景也有两种不同的实施方式:
-
(记为方案C) 两边 HDFS 数据完全一致后,一键全部切换(比如通过在DP上配置改成指向新集群),优点是用户基本无感知,缺点也比较明显,一键迁移的风险极大(怎么保证两边完全一致、怎么快速识别&快速回滚) -
(记为方案D) 按照DP上的任务血缘关系,分层(比如按照数据仓库分层依次迁移 ODS / DW / DM 层数据)、分不同业务线迁移,优点是风险较低(分治)且可控,缺点是用户感知较为明显 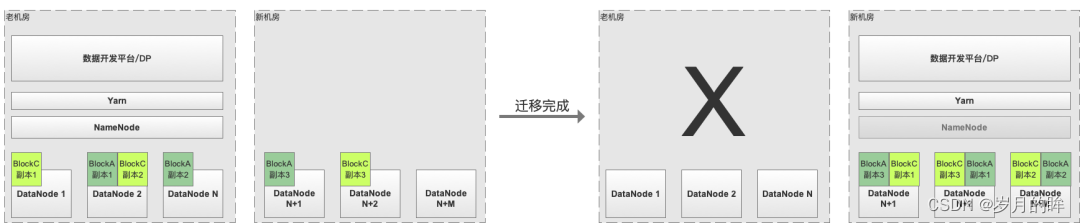 优点:
优点:
跨机房专线带宽要求不高(第一次全量同步期间不跑任务,后续增量数据同步,两边双跑任务不存在跨机房 Shuffle 问题)
风险可控,可以分阶段(ODS / DW / DM)依次迁移,每个阶段可以验证数据一致性后再开始下一阶段的迁移
不需要改造基础组件(Hadoop/Spark)
缺点:
对用户不透明,需要业务方配合
在平台层需要提供工具,来实现低成本迁移、数据一致性校验等
2.3 方案评估
从用户感知透明度来考虑,我们肯定会优先考虑单集群方案,因为单集群在迁移过程中,能做到基本对用户无感知的状态,但是考虑到如下几个方面的因素,我们最终还是选择了多集群方案:
-
(主因)跨机房的专线带宽大小不足。上述单集群的方案 A 在 Shuffle 过程中需要大量的带宽使用;方案 B 虽然带宽更加可控些,但副本跨机房复制还是需要不少带宽,同时前期的基础设施改造成本较大 -
(次因)平台上的任务类型众多,之前也没系统性梳理过,透明的一键迁移可能会产生稳定性问题,同时较难做回滚操作 因此我们通过评估,最终采用了方案 D。
三、实施过程
在方案确定后,我们便开始了有条不紊的迁移工作,整体的流程如图3.1所示 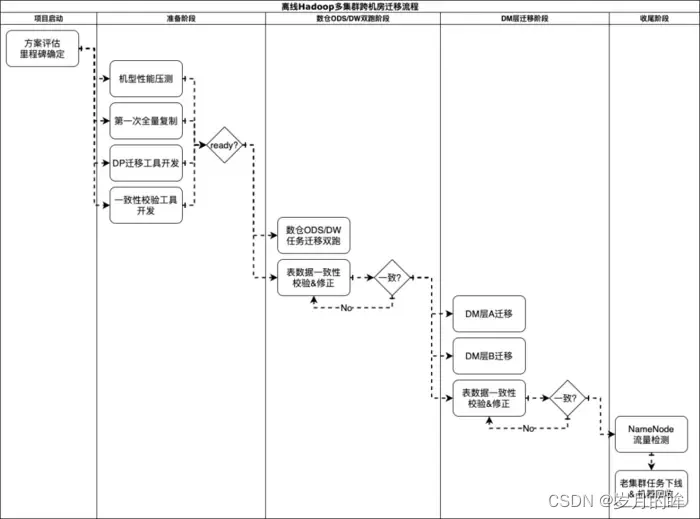 图3.1 离线Hadoop多集群跨机房迁移流程图
图3.1 离线Hadoop多集群跨机房迁移流程图
上述迁移流程中,核心要解决几个问题:
-
第一次全量Hadoop数据复制到新集群,如何保证过程的可控(有限时间内完成、限速、数据一致、识别更新数据)?(工具保证) -
离线任务的迁移,如何做到较低的迁移成本,且保障迁移期间任务代码、数据完全一致?(平台保证) -
完全迁移的条件怎么确定?如何降低整体的风险?(重要考虑点)
3.1 Hadoop 全量数据复制
首先我们在新机房搭建了一套 Hadoop 集群,在进行了性能压测和容量评估后,使用DistCp工具在老集群资源相对空闲的时间段做了 HDFS 数据的全量复制,此次复制 HDFS 数据时新集群只开启了单副本,整个全量同步持续了两周。基于 DistCp 本身的特性(带宽限制:-bandwidth / 基于修改时间和大小的比较和更新:-update)较好的满足全量数据复制以及后续的增量更新的需求。
3.2 离线任务的迁移
目前有赞所有的大数据离线任务都是通过 DP 平台来开发和调度的,由于底层采用了两套 Hadoop 集群的方案,所以迁移的核心工作变成了怎么把 DP 平台上任务迁移到新集群。
3.2.1 DP 平台介绍
有赞的 DP 平台是提供用户大数据离线开发所需的环境、工具以及数据的一站式平台(更详细的介绍请参考另一篇博客),目前支持的任务主要包括:
离线导入任务( MySQL 全量/增量导入到 Hive)
基于binlog的增量导入 (数据流:binlog -> Canal -> NSQ -> Flume -> HDFS -> Hive)
导出任务(Hive -> MySQL、Hive -> ElasticSearch、Hive -> HBase 等)
Hive SQL、Spark SQL 任务
Spark Jar、MapReduce 任务
其他:比如脚本任务
本次由于采用多集群跨机房迁移方案(两个 Hadoop 集群),因此需要在新旧两个机房搭建两套 DP 平台,同时由于迁移周期比较长(几个月)且用户迁移的时间节奏不一样,因此会出现部分任务先迁完,部分任务还在双跑,还有一些任务没开始迁移的情况。
3.2.2 DP 任务状态一致性保证
在新旧两套 DP 平台都允许用户创建和更新任务的前提下,如何保证两边任务状态一致呢(任务状态不限于MySQL的数据、Gitlab的调度文件等,因此不能简单使用MySQL自带的主从复制功能)?我们采取的方案是通过事件机制来实现任务操作时间的重放,展开来讲:
-
用户在老 DP 产生的操作(包括新建/更新任务配置、任务测试/发布/暂停等),通过事件总线产生事件消息发送到 Kafka,新系统通过订阅 Kafka 消息来实现事件的回放,如图 3.2 所示。 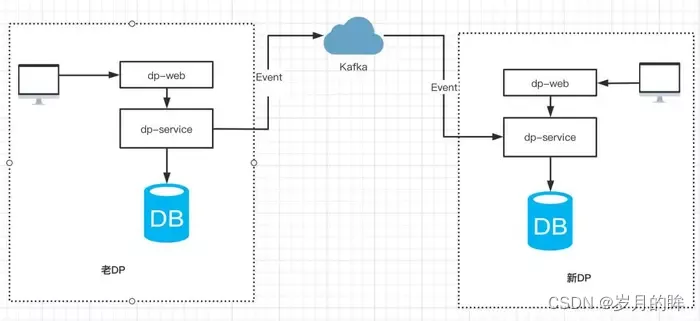 图3.2 通过事件机制,来保证两个平台之间的任务状态一致
图3.2 通过事件机制,来保证两个平台之间的任务状态一致
3.2.3 DP 任务迁移状态机设计
DP 底层的改造对用户来说是透明的,最终暴露给用户的仅是一个迁移界面,每个工作流的迁移动作由用户来触发。工作流的迁移分为两个阶段:双跑和全部迁移,状态流转如图 3.3 所示 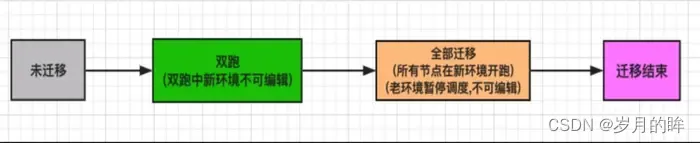 图 3.3 工作流迁移状态流转
图 3.3 工作流迁移状态流转
双跑
工作流的初始状态为未迁移,然后用户点击迁移按钮,会弹出迁移界面,如图 3.4 所示,用户可以指定工作流的任意子任务的运行方式,主要选项如下:
两边都跑:任务在新老环境都进行调度
老环境跑:任务只在老环境进行调度
新环境跑:任务只在新环境进行调度
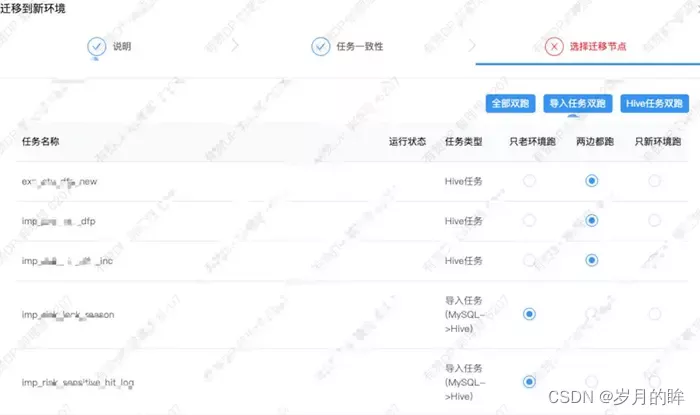 图 3.4 工作流点击迁移时,弹框提示选择子任务需要运行的方式
图 3.4 工作流点击迁移时,弹框提示选择子任务需要运行的方式
不同类型的子任务建议的运行方式如下:
导入任务 (MySQL -> Hive):通常是双跑,也就是两个集群在调度期间都会从业务方的 MySQL 拉取数据(由于拉取的是 Slave 库,且全量拉取的一般是数据量不太大的表)
Hive、SparkSQL 任务:通常也是双跑,双跑时新老集群都会进行计算。
MapReduce、Spark Jar 任务:需要业务方自行判断:任务的输出是否是幂等的、代码中是否配置了指向老集群的地址信息等
导出任务:一般而言无法双跑,如果两个环境的任务同时向同一个 MySQL表(或者 同一个ElasticSearch 索引)写入/更新数据,容易造成数据不一致,建议在验证了上游 Hive 表数据在两个集群一致性后进行切换(只在新环境跑)。
同时处于用户容易误操作导致问题的考虑,DP 平台在用户设置任务运行方式后,进行必要的规则校验:
如果任务状态是双跑,则任务依赖的上游必须处于双跑的状态,否则进行报错。
如果任务是第一次双跑,会使用 Distcp 将其产出的 Hive 表同步到新集群,基于 Distcp 本身的特性,实际上只同步了在第一次同步之后的增量/修改数据。
如果工作流要全部迁移(老环境不跑了),则工作流的下游必须已经全部迁移完。
双跑期间的数据流向如下图 3.5 所示: 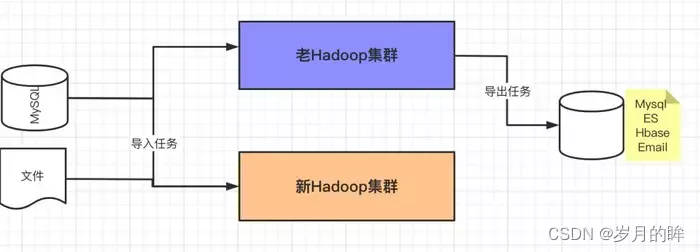
迁移过程中工作流操作的限制规则
由于某个工作流迁移的持续时间可能会比较长(比如DW层任务需要等到所有DM层任务全部迁移完),因此我们既要保证在迁移期间工作流可以继续开发,同时也要做好预防误操作的限制,具体规则如下:
-
迁移中的工作流在老环境可以进行修改和发布的,新环境则禁止 -
工作流在老环境修改发布后,会将修改的元数据同步到新环境,同时对新环境中的工作流进行发布。 -
工作流全部迁移,需要所有的下游已经完成全部迁移
3.3 有序推动业务方迁移
工具都已经开发好了,接下来就是推动 DP 上的业务方进行迁移,DP 上任务数量大、种类多、依赖复杂,推动业务方需要一定的策略和顺序。有赞的数据仓库设计是有一定规范的,所以我们可以按照任务依赖的上下游关系进行推动:
-
导入任务( MySQL 全量/增量导入 Hive) 一般属于数据仓库的 ODS 层,可以进行全量双跑。 -
数仓中间层任务主要是 Hive / Spark SQL 任务,也可以全量双跑,在验证了新老集群的 Hive 表一致性后,开始推动数仓业务方进行迁移。 -
数仓业务方的任务一般是 Hive / Spark SQL 任务和导出任务,先将自己的 Hive 任务双跑,验证数据一致性没有问题后,用户可以选择对工作流进行全部迁移,此操作将整个工作流在新环境开始调度,老环境暂停调度。 -
数仓业务方的工作流全部迁移完成后,将导入任务和数仓中间层任务统一在老环境暂停调度。 -
其他任务主要是 MapReduce、Spark Jar、脚本任务,需要责任人自行评估。
3.4 过程保障
工具已经开发好,迁移计划也已经确定,是不是可以让业务进行迁移了呢?慢着,我们还少了一个很重要的环节,如何保证迁移的稳定呢?在迁移期间一旦出现 bug 那必将是一个很严重的故障。因此如何保证迁移的稳定性也是需要着重考虑的,经过仔细思考我们发现问题可以分为三类,迁移工具的稳定,数据一致性和快速回滚。
迁移工具稳定
新 DP 的元数据同步不及时或出现 Bug,导致新老环境元数据不一致,最终跑出来的数据必定天差地别。
应对措施:通过离线任务比对两套 DP 中的元数据,如果出现不一致,及时报警。
工作流在老 DP 修改发布后,新 DP 工作流没发布成功,导致两边调度的 airflow 脚本不一致。
应对措施:通过离线任务来比对 airflow 的脚本,如果出现不一致,及时报警。
全部迁移后老环境 DP 没有暂定调度,导致导出任务生成脏数据。
应对措施:定时检测全部迁移的工作流是否暂停调度。
用户设置的运行状态和实际 airflow 脚本的运行状态不一致,比如用户期望新环境空跑,但由于程序 bug 导致新环境没有空跑。
应对措施:通过离线任务来比对 airflow 的脚本运行状态和数据库设置的状态。
Hive 表数据一致性
Hive 表数据一致性指的是,双跑任务产出的 Hive 表数据,如何检查数据一致性以及识别出来不一致的数据的内容,具体方案如下(如图3.6所示):
双跑的任务在每次调度运行完成后,我们会上报 <任务T、产出的表A> 信息,用于数据质量校验(DQC),等两个集群产出的表A都准备好了,就触发数据一致性对比
根据 <表名、表唯一键K> 参数提交一个 MapReduce Job,由于我们的 Hive 表格式都是以 Orc格式存储,提交的 MapReduce Job 在 MapTask 中会读取表的任意一个 Orc 文件并得到 Orc Struct 信息,根据用户指定的表唯一键,来作为 Shuffle Key,这样新老表的同一条记录就会在同一个 ReduceTask 中处理,计算得到数据是否相同,如果不同则打印出差异的数据
表数据比对不一致的结果会发送给表的负责人,及时发现和定位问题
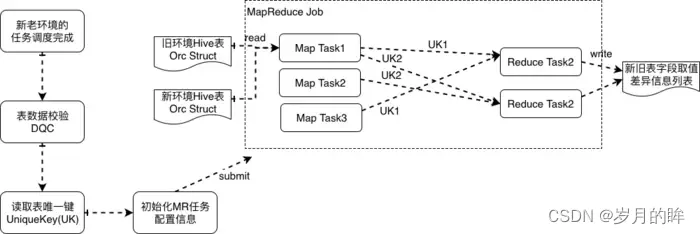
图 3.6 Hive表新老集群数据一致性校验方案
四、迁移过程中的问题总结
使用 DistCp 同步 HDFS 数据时漏配参数(-p),导致 HDFS 文件 owner 信息不一致。
使用 DistCp 同步 HDFS 数据时覆盖了 HBase 的 clusterId,导致 Hbase 两个集群之间同步数据时发生问题。
在迁移开始后,新集群的 Hive 表通过 export import 表结构来创建,再使用 DistCp 同步表的数据。导致 Hive meta 信息丢失了 totalSize 属性,造成了 Spark SQL 由于读取不到文件大小信息无法做 broadcast join,解决方案是在 DistCp 同步表数据之后,执行 Hive 命令 ANALYZE TABLE TABLE_NAME COMPUTE STATISTICS 来生成表相关属性。
迁移期间由于在夜间启动了大量的 MapReduce 任务,进行 Hive 表数据比对,占用太多离线集群的计算资源,导致任务出现了延迟,最后将数据比对任务放在资源相对空闲的时间段。
工作流之间存在循环依赖,导致双跑-全部迁移的流程走不下去,所以数仓建设的规范很重要,解决方案就是要么让用户对任务重新组织,来重构工作流的依赖关系,要么两个工作流双跑后,一起全部迁移。
迁移期间在部分下游已经全部迁移的情况下,上游出现了问题需要重刷所有下游,由于只操作了老 DP,导致新环境没有重刷,使迁移到新环境的下游任务受到了影响。
MapReduce 和 Spark Jar 类型的任务无法通过代码来检测生成的上下游依赖关系,导致这类任务只能由用户自己来判断,存在一定的风险,后续会要求用户对这类任务也配上依赖的 Hive 表和产出的 Hive 表。
五、总结与展望
本次的大数据离线集群跨机房迁移工作,时间跨度近6个月(包括4个月的准备工作和2个月的迁移),涉及PB+的数据量和4万日均调度任务。虽然整个过程比较复杂(体现在涉及的组件众多、任务种类和实现复杂、时间跨度长和参与人员众多),但通过前期的充分调研和探讨、中期的良好迁移工具设计、后期的可控推进和问题修复,我们做到了整体比较平稳的推进和落地。同时针对迁移过程中遇到的问题,在后续的类似工作中我们可以做的更好:
-
做好平台的治理,比如代码不能对当前环境配置有耦合 -
完善迁移工具,尽量让上层用户无感知 -
单 Hadoop 集群方案的能力储备,主要解决跨机房带宽的受控使用
六、元数据迁移工具hive-tools
hive-tools 项目介绍
Github地址:https://github.com/NetEase/hive-tools
在网易集团内部有大大小小几百套 hive 集群,为了满足网易猛犸大数据平台的元数据统一管理的需求,我们需要将多个分别独立的 hive 集群的元数据信息进行合并,但是不需要移动 HDFS 中的数据文件,比如可以将 hive2、hive3、hive4 的元数据全部合并到 hive1 的元数据 Mysql 中,然后就可以在 hive1 中处理 hive2、hive3、hive4 中的数据。
我们首先想到的是 hive 中有自带的 EXPORT 命令,可以把指定库表的数据和元数据导出到本地或者 HDFS 目录中,再通过 IMPORT 命令将元数据和数据文件导入新的 hive 仓库中,但是存在以下问题不符合我们的场景
我们不需要重现导入数据;
我们的每个 hive 中的表的数量多达上十万,分区数量几千万,无法指定 IMPORT 命令中的分区名;
经过测试 IMPORT 命令执行效率也很低,在偶发性导入失败后,无法回滚已经导入的部分元数据,只能手工在 hive 中执行 drop table 操作,但是我们线上的 hive 配置是开启了删除表同时删除数据,这是无法接受的;
于是我们便考虑自己开发一个 hive 元数据迁移合并工具,满足我们的以下需求:
可以将一个 hive 集群中的元数据全部迁移到目标 hive 集群中,不移动数据;
在迁移失败的情况下,可以回退到元数据导入之前的状态;
可以停止源 hive 服务,但不能停止目标 hive 的服务下,进行元数据迁移;
迁移过程控制在十分钟之内,以减少对迁移方的业务影响;
元数据合并的难点
hive 的元数据信息(metastore)一般是通过 Mysql 数据库进行存储的,在 hive-1.2.1 版本中元数据信息有 54 张表进行了存储,比如存储了数据库名称的表 DBS、存储表名称的表 TBLS 、分区信息的 PARTITIONS 等等。
元数据表依赖关系非常复杂  元数据信息的这 54 张表通过 ID 号形成的很强的主外健依赖关系,例如
元数据信息的这 54 张表通过 ID 号形成的很强的主外健依赖关系,例如
-
DBS 表中的 DB_ID 字段被 20 多张表作为外健进行了引用; -
TBLS 表中的 TBL_ID 字段被 20 多张表作为外健进行了引用; -
TBLS 表中的 DB_ID 字段是 DBS 表的外健、SD_ID 字段是 SDS 表的外健; -
PARTITIONS 表中的 TBL_ID 字段是 TBLS 表的外健、SD_ID 字段是 SDS 表的外健; -
DATABASE_PARAMS 表中的 DB_ID 字段是 DBS 表的外健;
这样的嵌套让表与表之间的关系表现为 [DBS]=>[TBLS]=>[PARTITIONS]=>[PARTITION_KEY_VALS],像这样具有 5 层以上嵌套关系的有4-5 套,这为元数据合并带来了如下问题。
源 hive 中的所有表的主键 ID 必须修改,否则会和目标 hive2 中的主键 ID 冲突,导致失败;
源 hive 中所有表的主键 ID 修改后,但必须依然保持源 hive1 中自身的主外健依赖关系,也就是说所有的关联表的主外健 ID 都必须进行完全一致性的修改,比如 DBS 中的 ID 从 1 变成 100,那么 TBLS、PARTITIONS 等所有子表中的 DB_ID 也需要需要从 1 变成 100;
按照表的依赖关系,我们必须首先导入主表,再导入子表,再导入子子表 …,否则也无法正确导入;
修改元数据的主外健 ID
我们使用了一个巧妙的方法来解决 ID 修改的问题:
从目标 hive 中查询出所有表的最大 ID 号,将每个表的 ID 号加上源 hive 中所有对应表的 ID 号码,形成导入后新生成出的 ID 号,公式是:新表ID = 源表ID + 目标表 ID,因为所有的表都使用了相同的逻辑,通过这个方法我们的程序就不需要维护父子表之间主外健的 ID 号。
唯一可能会存在问题的是,在线导入过程中,目标 hive 新创建了 DB,导致 DB_ID 冲突的问题,为此,我们在每次导入 hive 增加一个跳号,公式变为:新表ID = 源表ID + 目标表 ID + 跳号值(100)
数据库操作
我们使用了 mybatis 进行了源和目标这 2 个 Mysql 的数据库操作,从源 Mysql 中按照上面的逻辑关系取出元数据修改主外健的 ID 号再插入到目标 Mysql 数据库中。
由于 mybatis 进行数据库操作的时候,需要通过表的 bean 对象进行操作,54 张表全部手工敲出来又累又容易出错,应该想办法偷懒,于是我们使用了 druid 解析 hive 的建表语句,再通过 codemodel 自动生成出了对应每个表的 54 个 JAVA 类对象。参见代码:com.netease.hivetools.apps.SchemaToMetaBean
元数据迁移操作步骤
1:备份元数据迁移前的目标和源数据库
2:将源数据库的元数据导入到临时数据库 exchange_db 中,需要一个临时数据库是因为源数据库的 hive 集群仍然在提供在线服务,元数据表的 ID 流水号仍然在变化,hive-tools 工具只支持目的数据库是在线状态;
3:通过临时数据库 exchange_db 能够删除多余 hive db 的目的,还能够通过固定的数据库名称,规范整个元数据迁移操作流程,减低因为手工修改执行命令参数导致出错的概率
4:在 hive-tools.properties 文件中配置源和目的数据库的 JDBC 配置项
# exchange_db
exchange_db.jdbc.driverClassName=com.mysql.jdbc.Driver
exchange_db.jdbc.url=jdbc:mysql://10.172.121.126:3306/hivecluster1?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
exchange_db.jdbc.username=src_hive
exchange_db.jdbc.password=abcdefg
# dest_hive
dest_hive.jdbc.driverClassName=com.mysql.jdbc.Driver
dest_hive.jdbc.url=jdbc:mysql://10.172.121.126:3306/hivecluster1?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
dest_hive.jdbc.username=dest_hive
dest_hive.jdbc.password=abcdefg
5:执行元数据迁移命令
export SOURCE_NAME=exchange_db
export DEST_NAME=dest_hive
/home/hadoop/java-current/jre/bin/java -cp "./hive-tools-current.jar" com.netease.hivetools.apps.MetaDataMerge --s=$SOURCE_NAME --d=$DEST_NAME
6:hive-tools 会在迁移元数据之前首先检查源和目的元数据库中重名的 hive db,终止元数据迁移操作并给出提示
7:执行删除重名数据库命令
# 修改脚本中的 DEL_DB(多个库之间用逗号分割,default必须删除)参数和 DEL_TBL(为空则删除所有表)
export SOURCE=exchange_db
export DEL_DB=default,nisp_nhids,real,azkaban_autotest_db
export DEL_TBL=
~/java-current/jre/bin/java -cp "./hive-tools-current.jar" com.netease.hivetools.apps.DelMetaData --s=$SOURCE --d=$DEL_DB --t=$DEL_TBL
8:再次执行执行元数据迁移命令
9:检查元数据迁移命令窗口日志或文件日志,如果发现元数据合并出错,通过对目的数据库进行执行删除指定 hive db 的命令,将迁移过去的元数据进行删除,如果没有错误,通过 hive 客户端检查目的数据库中是否能够正常使用新迁移过来的元数据
10:严格按照我们的元数据迁移流程已经在网易集团内部通过 hive-tools 已经成功迁移合并了大量的 hive 元数据库,几乎没有出现过问题
代码技巧——数据迁移方案【建议收藏】
开发工作中,可能会遇到如"大表拆分"、"跨库数据迁移"等场景,本文介绍互联网常见架构下的数据迁移方案及实现;
1. 数据迁移的业务场景
以下是需要数据迁移的场景业务场景;
1.1 大表拆分
由于历史原因,为了业务快速迭代,设计之初未考虑用户的规模,对于如用户权益、用户订单的数据,仅做了单表存储; 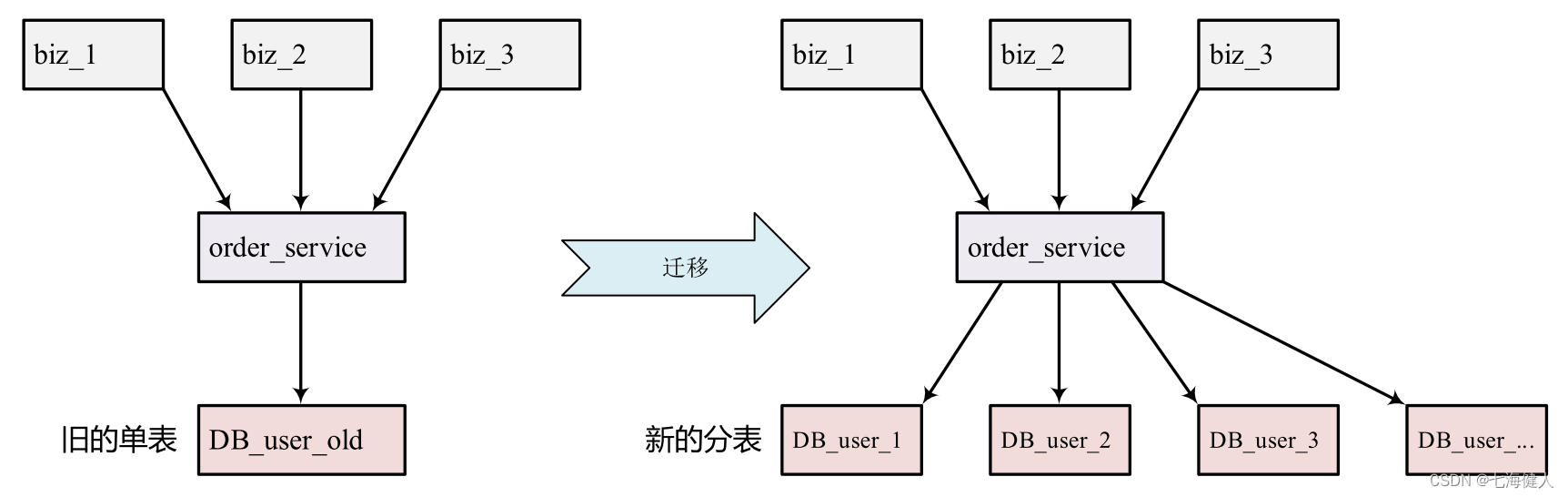 随着业务规模快速增长,单表数据膨胀,读写压力变大,可能出现单条慢SQL拖垮整个表的风险,以至于使整个业务不可用的情况,因此,需要将存储大量数据的单表拆分为多表(分库分表);
随着业务规模快速增长,单表数据膨胀,读写压力变大,可能出现单条慢SQL拖垮整个表的风险,以至于使整个业务不可用的情况,因此,需要将存储大量数据的单表拆分为多表(分库分表);
1.2 数据迁移
业务发展之初,业务模块小,多个业务都放在同一个数据库中;随着业务规模的增长,当初聚合的多个业务模块要做业务交割,交由不同的团队维护和迭代,各个业务都有自己的库表; 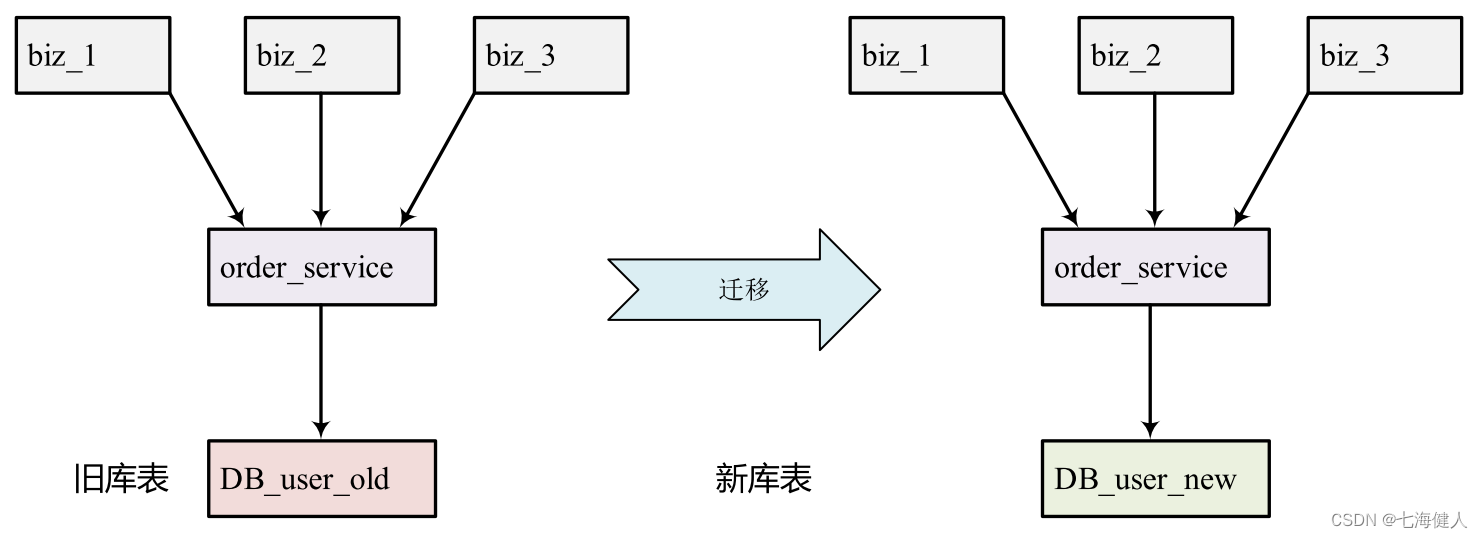 为了防止不同业务之间,可能由于其他业务异常拖累整个数据库,要做业务存储的物理隔离,因此需要将旧库表的数据迁移到新的库表;
为了防止不同业务之间,可能由于其他业务异常拖累整个数据库,要做业务存储的物理隔离,因此需要将旧库表的数据迁移到新的库表;
1.3 数据同步
举个例子,用户的支付订单的数据都保存在支付中台,由于历史原因,当前业务方的部分业务订单未做存储; 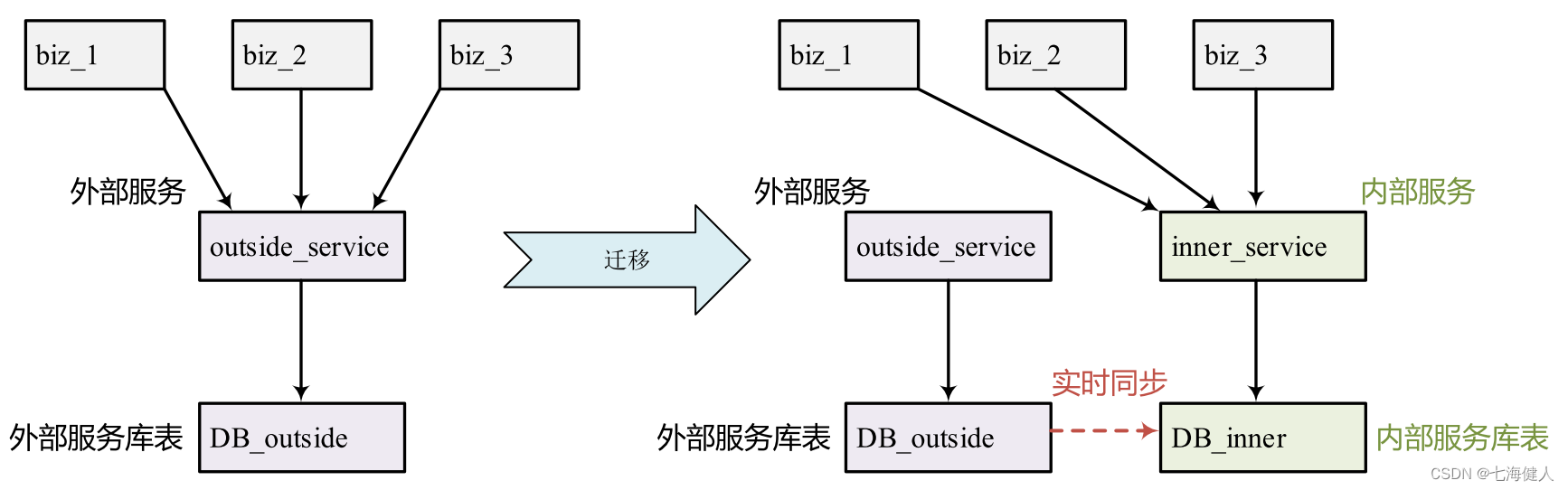 现在要做一个支付管控版本(如未成年人防沉迷专项),需要依赖订单中台来协助实现功能,而跨部门的需求对接周期长成本高;因此需要 [拉取并实时同步支付中台的订单数据] ,当前业务得到这部分数据后,就可以自行实现上述的跟订单相关的功能,从而将交易管控能力(实名制/防沉迷、商品限购)收敛在当前业务团队,提升需求版本迭代效率,减少跨部门的开发、测试之间的沟通、合作、资源等待问题,达到更快速响应业务需求目的;
现在要做一个支付管控版本(如未成年人防沉迷专项),需要依赖订单中台来协助实现功能,而跨部门的需求对接周期长成本高;因此需要 [拉取并实时同步支付中台的订单数据] ,当前业务得到这部分数据后,就可以自行实现上述的跟订单相关的功能,从而将交易管控能力(实名制/防沉迷、商品限购)收敛在当前业务团队,提升需求版本迭代效率,减少跨部门的开发、测试之间的沟通、合作、资源等待问题,达到更快速响应业务需求目的;
2. 方案选择
2.1 有损迁移
有损方案指的是停机变更方案,因为需要一段时间停止服务,因此对于业务是有损的;可以按照如下步骤执行: 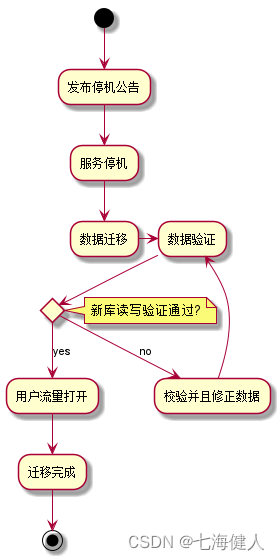 (1)研发同事通过观察历史的用户流量监控,选择流量较小的时间段执行变更来尽可能减小业务影响,如凌晨4点开始运维;运营同事前一天在网站或者 APP挂个公告,说次日4点到早上6点进行系统升级,无法访问;
(1)研发同事通过观察历史的用户流量监控,选择流量较小的时间段执行变更来尽可能减小业务影响,如凌晨4点开始运维;运营同事前一天在网站或者 APP挂个公告,说次日4点到早上6点进行系统升级,无法访问;
(2)接着到凌晨4点停机,系统停掉,关闭用户流量入口,此时老数据库表不再有变更产生,属于临时静态数据;然后通过提前得写好的一个数据导出导入工具,将老数据库表的数据按序读出来,写到分库分表里面去;当然,为了提升数据导出速度,可以使用多线程分段读写数据,甚至可以联系DBA直接物理复制数据库表,然后再执行rename;
(3)数据导出之后,通过修改系统的数据库连接配置,重启服务,连到新的分库分表上去;模拟用户请求验证一下对数据的读写,这时发现如预期一样,这时打开用户流量,再观察一段时间,确认无误后,伸个懒腰回家调休;
说到停机迁移这种方案,可能有些同学觉得很low,但是实际上目前存在相当一部分迁移方案都是使用凌晨停机迁移的方式(例如有时候会看到停机维护公告),因为这种方式成本低简单粗暴、无需考虑新老库数据临界情况不一致的问题、整个迁移周期非常短不存在灰度放量与多次修改代码发布的情况,缺点就是短暂业务有损,需要DBA、研发值班;
2.2 平滑迁移
平滑迁移也叫无损迁移,服务在迁移过程中不需要停机,最多只需要短暂的重启时间,对于业务几乎没有任何影响的;双写方案,就是平滑迁移方案,简单来说,就是修改线上代码,之在前所有写老库(增删改操作)的地方,都加上对新库的增删改,这就是所谓的双写;
然后系统部署之后,由于我们只处理了某个时间节点之后的增量数据,新库数据整体数据差太远,用之前说的数据导出导入工具,跑起来读老库数据写新库,写的时候要根据类似gmt_modified字段判断这条数据最后修改的时间,除非是读出来的数据在新库里没有,或者是比新库的数据新才会写,简单来说,就是不允许用老数据覆盖新数据,新库的数据总是最新的;
导完一轮之后,有可能数据还是存在不一致,保险起见,通过定时任务做多轮新老库的数据校验,比对新老库每个表的每条数据,接着如果有不一样的,按照以最新数据为准的原则,重新从老库读数据再次写新库,直到两个库的数据追平,完全一致为止;
接着当数据完全一致了,切换为仅读写新库的代码,重新部署服务,重新部署后,数据的读写全部都落在新库中;求稳起见,这一阶段往往建议通过灰度策略,把用户的流量(仅读写新库)慢慢的切换到新库里,注意灰度的用户放量只能逐渐加大,不能回滚,因为灰度命中的用户数据都落在了新库,而老库没有;最终放量100%,迁移完成; 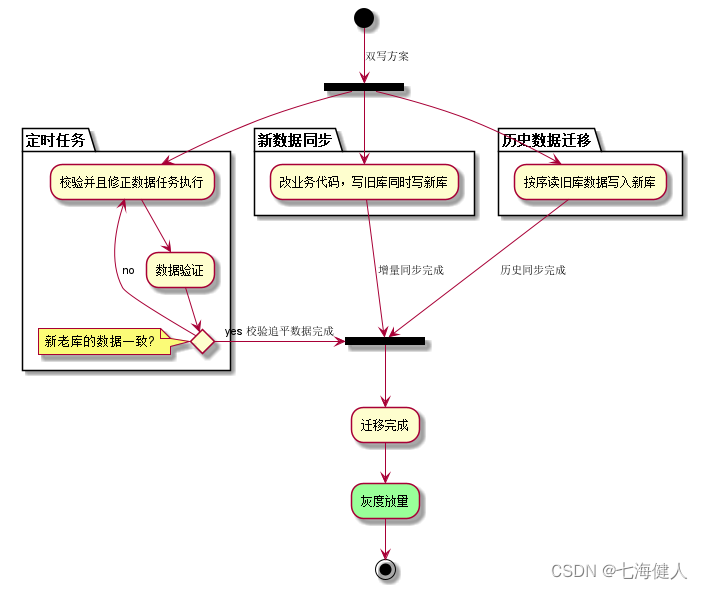 相对有损迁移方案,这种平滑迁移方案无需长达几个小时的停机时间,对业务的影响几乎没有,所以现在基本做数据迁移都会偏向这种方案;
相对有损迁移方案,这种平滑迁移方案无需长达几个小时的停机时间,对业务的影响几乎没有,所以现在基本做数据迁移都会偏向这种方案;
2.3 增量迁移
这种迁移方案一般应用于特殊的业务数据,这类业务数据的历史数据价值不大具备有效期属性,如用户的优惠券数据;例如有这样的一个业务场景:用户优惠券表由于历史原因未做分库分表,目前数据增长过快,查询、写入性能变差;该业务属于部门核心业务,每天都有大量的用户流量和数据写入;为了保证业务的可用性需要对优惠券大表做拆分;
针对以上业务场景,考虑用户优惠券本身的特性(存在有效期),采取以下方案:灰度期间,用户优惠券新增数据全部保存至新表中,旧表的历史数据不迁移仅更新,共存阶段同时查询新库和旧库数据做数据聚合,运行N个月后(旧库数据已全部业务失效)用户请求的读写全部切到新库中,旧库直接作为归档; 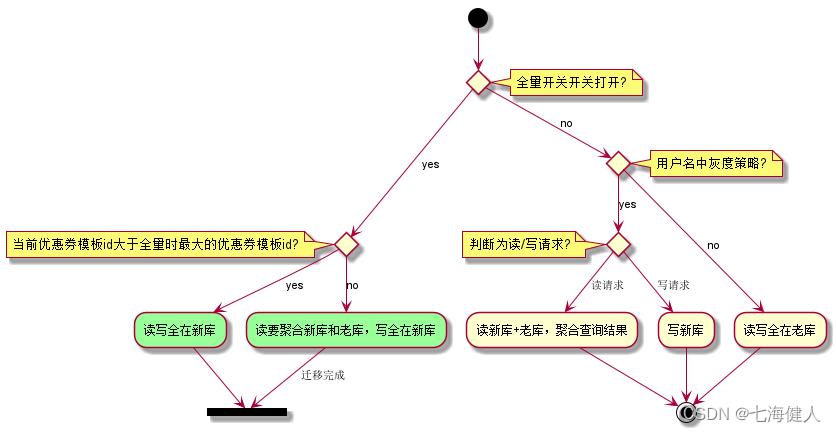 该方案的特点就是历史数据天然的无需迁移,方案逐渐放量、无需考虑回滚,适用于解决大表拆分问题;
该方案的特点就是历史数据天然的无需迁移,方案逐渐放量、无需考虑回滚,适用于解决大表拆分问题;
3. 平滑迁移方案的实现细节
双写方案,总的来说就5个步骤:
1. 双写,增量数据同步;
2. 历史数据同步;
3. 定时任务校验数据一致性并修复;
4. 灰度放量,异常时可回滚;
5. 功能全量,完成平滑迁移;
3.1 双写的实现方式
首先,配置新库和老库两个数据源Datasource,来分别执行对老库和新库的读写;对于写操作的实现,有两种方式:
(1)修改业务代码,在写老库的地方,加上一句对新库的写操作;这种方法将写新库与原业务操作耦合到了一起,修改代码的位置可能非常多,业务代码会改的很混乱,并且当老库写成功,新库写失败时,需要考虑如何补偿,至少不能影响老库已经成功的业务逻辑,这种方法不推荐;
(2)因为业务请求只在数据迁移完成后才切换,所以并不要求老库与新库的写操作同步执行;因此可以考虑使用消息中间件解耦,如记录“对旧库上的数据修改”的日志持久化并丢入消息队列,然后按序消费队列里面的所有消息;
(3)借助公司大数据团队提供的binlog解析采集工具,如基于开源的canal binlog parser模块二次开发的binlog接入工具,通过MySQL主从复制协议去业务db捕获增量变更数据(模拟MySQL slave,通过socket连接去拉取和解析数据,对于MySQL的性能损耗很小,按照MySQL官方的说法,损耗为1%),解析成json格式,写入kafka,最终由业务消费数据,按照自己需求写入hive,hbase,es等等异构数据源中;),作为业务方只需要消费数据库增量变更的Kafka消息即可;
3.2 边双写边迁移历史数据
对旧库上的数据修改的同时,在新库上进行相同的修改操作,这就是所谓的“双写”,主要修改操作包括:
(1)旧库与新库的同时insert;
(2)旧库与新库的同时delete;
(3)旧库与新库的同时update;
由于新库中此时是没有历史数据的,所以双写旧库与新库中的affect rows可能不一样,不过这完全不影响业务功能,因为此时还未切库,依然是旧库提供业务服务;
新库写操作的数据变更原则为:
1. 对于单条数据的重复变更,以最新的数据为准,不能用旧数据替换了比它更新的数据;
2. 双写时,只有当老库执行写操作成功,才会对新库执行操作;
3. 新库执行写操作失败不能影响旧库的写操作成功的结果;
接着,执行历史数据迁移定时任务,由于迁移数据的过程中,旧库新库双写操作在同时进行,怎么保证数据迁移完成之后数据就基本一致了呢? 可以参考下面的图来做一个说明; 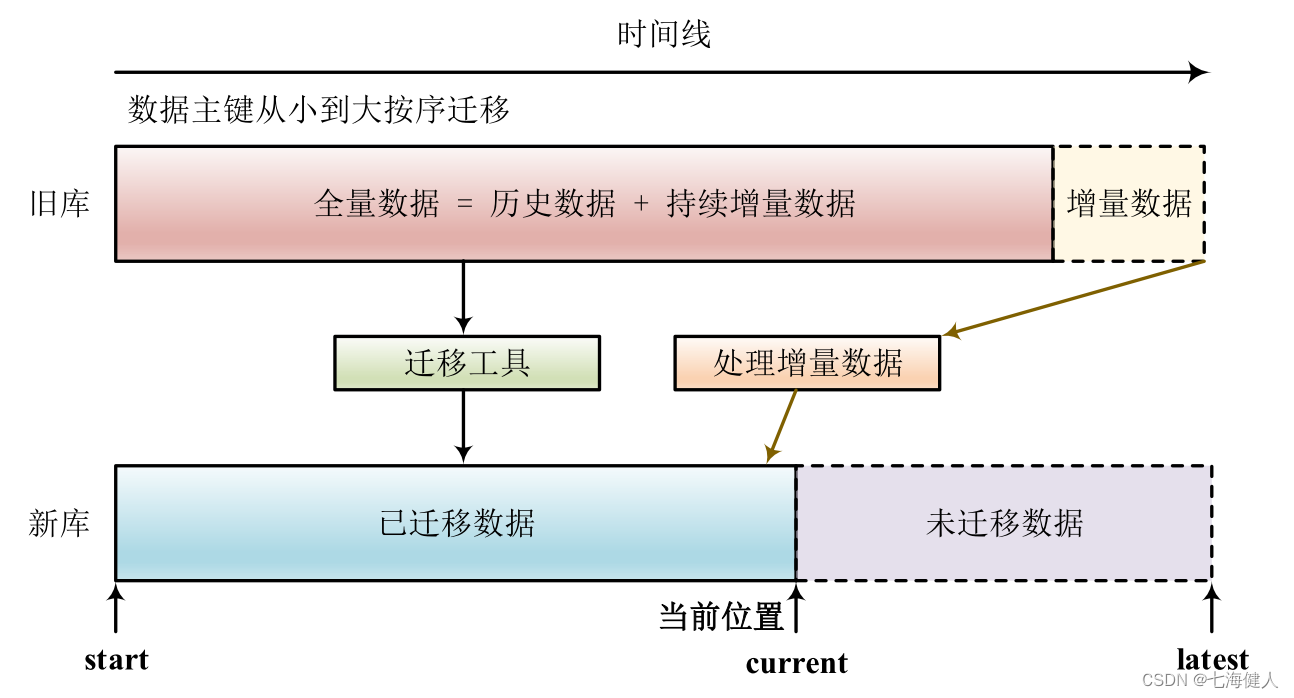 上方是旧库中的数据,数据量还在随时间线持续写入;下方是新库中的数据,边通过迁移工具同步历史数据,边处理旧库中新发生的增量数据(这里的增量数据指的是双写时,新库的写操作导致的数据变更,不仅限于insert操作);
上方是旧库中的数据,数据量还在随时间线持续写入;下方是新库中的数据,边通过迁移工具同步历史数据,边处理旧库中新发生的增量数据(这里的增量数据指的是双写时,新库的写操作导致的数据变更,不仅限于insert操作);
下面针对数据迁移过程中,由于双写同时产生的修改操作,讨论下该如何处理:
1. 旧库执行insert操作后
新库执行insert操作,操作一定能成功(因为新库的数据是旧库的子集,旧库既然可以插入成功,那么新库也可以插入成功),此时旧库新库都插入了数据,数据一致性没有被破坏;
2. 旧库执行delete操作后
根据删除的数据所处的区间,分为两种情况:
-
情况(1):假设这delete的数据属于[start, current]范围,即已经写入了新库,则旧库新库都删除了该条数据,数据一致性没有被破坏; -
情况(2):假设这delete的数据属于[current, latest]范围,即还未写入新库,则旧库中删除操作的affect rows(影响的行数)为1,新库中删除操作的affect rows为0;
但是数据迁移工具在后续数据迁移中,因为这条"未来的"数据已经从旧库删除,因此并不会将这条旧库中被删除的数据迁移到新库中,所以数据一致性仍没有被破坏;
3. 旧库执行update操作后
根据更新的数据所处的区间,分为两种情况:
-
情况(1):假设这update的数据属于[start, current]范围,即已经写入了新库,则旧库新库都更新了该条数据,数据一致性没有被破坏; -
情况(2):假设这update的数据属于[current, latest]范围,即还未写入新库,此时新库将这条update操作改为insert操作即可;数据迁移工具在后续数据迁移这条数据时,由于这条数据的更新时间与新库中已插入的这条记录的更新时间相同(同一条数据),因此不会执行迁移替换,所以数据一致性仍没有被破坏;
也可以这么理解,可以认为update操作是一个delete加一个insert操作的复合操作,结合上面对于inser和delete的分析,所以数据仍然是一致的;
特殊情况:
-
1.数据迁移工具刚好从旧库中将某一条数据X取出,准备执行迁移插入新库; -
2.在X插入到新库中之前,旧库发生了写操作(delete),旧库删除了这条数据,affect rows为1,新库由于此时还没有这条数据,affect rows为0; -
3.双写完成后,数据迁移工具再将X插入到新库中;导致新库比旧库多出一条"本应被删除的"数据X,导致数据不一致;
因此,为了保证数据的一致性,切库之前,新库和老库的数据校验是必要的!
在数据迁移完成之后,需要写一个数据校验和修复的数据校验的定时任务,将旧库和新库中的数据进行比对,完全一致则符合预期;如果出现某种极端情况下导致的老库新库数据不一致情况,则以旧库中的(最新的)数据为准;
这个定时任务跟数据迁移写法类似,只不过前者是遍历查旧库写新库,后者是遍历查旧库,然后用旧库结果去查新库,做数据对比与修正;整个过程依然是旧库对线上提供服务,因此没有任何操作风险;
数据校验和修复的定时任务可以执行的久一点,一段时间后都没有出现旧库与新库数据存在不一致的告警时,可以开始逐渐灰度了,即将命中灰度策略的用户请求全部走读写新库,放量可以慢点,直到所有用户请求都路由到新库为止,则数据迁移完成;
4. 实际工作中使用的方案
我在工作期间,设计过1.1大表拆分和1.3数据同步这两种业务场景的技术方案;这里介绍下在做数据同步时我用到的方案,仅供参考;
-
背景:组内做了一个针对部门业务的订单小中台,负责对接公司的支付系统(下单、回调、重试),目的是减少部门各个业务模块对接公司支付中台的成本,屏蔽如订单重试补偿的逻辑;此外,将部门内业务订单数据收拢,方便做整个部门业务的支付管控; -
任务:对于已经自主对接公司支付中台的部门内业务,需要把这些业务存储的业务订单数据迁移到订单小中台;数据跨库,且新库的表结构与旧库不同;
方案:
(1)binlog采集工具:公司大数据团队做了一款基于canal binlog parser模块二次开发的binlog接入工具,它通过MySQL主从复制协议去业务db捕获增量变更数据(模拟MySQL slave,通过socket连接去拉取和解析数据,对于MySQL的性能损耗很小,按照MySQL官方的说法,损耗为1%),解析成json格式,写入kafka,最终由业务消费数据,按照自己需求写入hive,hbase,es等等异构数据源中;
(2)工具接入步骤: 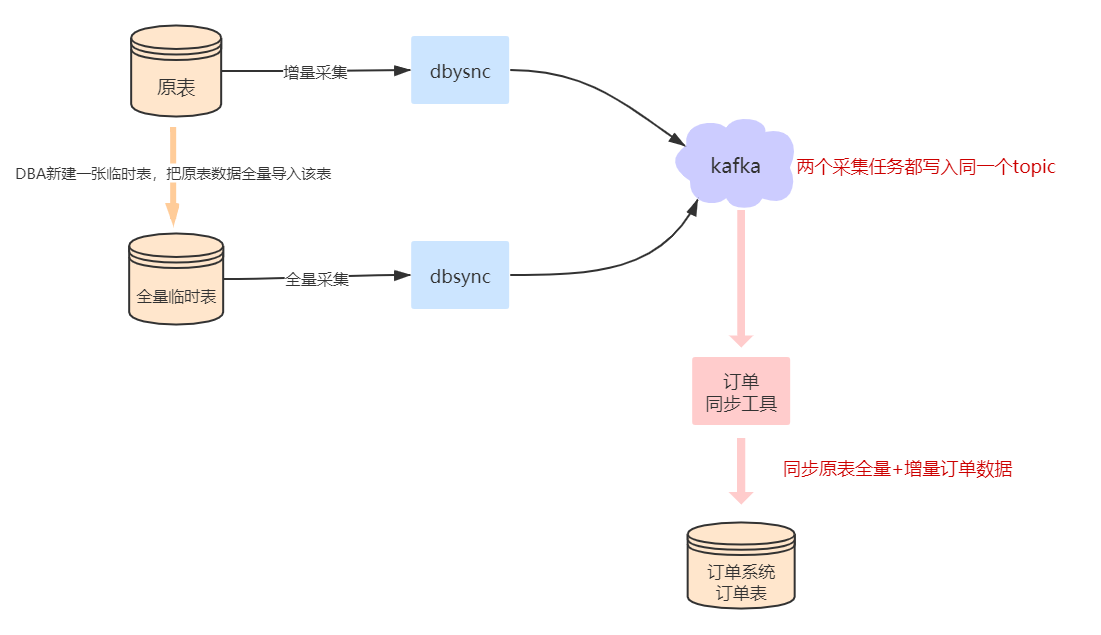
-
-
业务方需要为被采集binlog日志的数据库,申请一个离线从库,并开启这个从库的binlog开关、开启row full 模式、开启gtid,获取当前的GTID信息或者点位文件信息;也就是说只采集位点之后的binlog,对于位点之前的biglog,可以新建一张表并用同样方式监听其binlog,然后将位点前的旧库数据按序写入;
-
-
-
配置采集任务,分别采集旧库位点前后的binlog,binlog event会被处理成方便解析的数据丢入kafka broker集群;并且,会对每条binlog event分配一个全集唯一的版本号,并且保证后面产生的binlog的版本号比前面的大,从而为业务方提供了一种数据顺序性;
-
-
-
业务方只需要写一个消费kafka消息的listener即可;需要注意的是消息可能是乱序的(位点前后的binlog一起消费);
-
数据同步的消息处理逻辑如下: 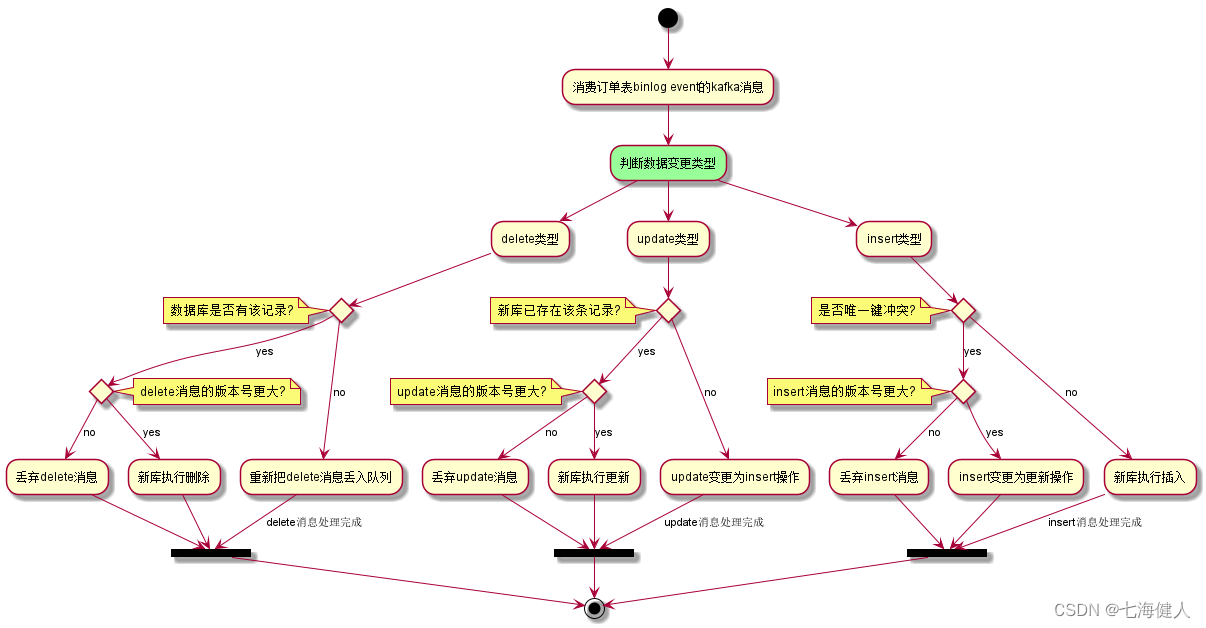 历史数据迁移完成后,还是需要一个定时任务来处理新库和老库不一样的数据;
历史数据迁移完成后,还是需要一个定时任务来处理新库和老库不一样的数据;
本文由 mdnice 多平台发布
智能推荐
基于DBN神经网络的语音分类识别_dbn说话人识别-程序员宅基地
文章浏览阅读453次。详细介绍DBN的原理,然后MATLAB编程实现DBN对语音的识别,论文附有代码_dbn说话人识别
你离入行车载,就差这份Android车载操作系统开发指北-程序员宅基地
文章浏览阅读156次。路变窄了,咱就换条路目前互联网行业的就业形势不太理想,“开猿节流”时有发生,而且频率一年比一年高。对于Android开发来说,市场的,明显可以感知到企业招聘门槛的提高,面临这种情况大部分都会选择一个正处于时代风口的领域继续发展。而车载开发无疑是具有这个潜力的领域,要知道随着国家的多年扶持以及车载的不断革新,车载领域走向风口的同时也催生了大量的车载岗位对车载开发相关的人才需求急剧增加。如今有一定车载开发经验的工程师月薪拿20k不是问题,掌握车载基础知识也能够轻松过万。
了解Android架构组件后,构建APP超简单!系列教学-程序员宅基地
文章浏览阅读45次。����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
关于BP神经网络正则化(人工控制参数干扰训练)_bp算法 正则化-程序员宅基地
文章浏览阅读1.3k次,点赞4次,收藏18次。正则化BP神经网络,控制神经网络参数,帮助减少过拟合,提高模型的准确性和鲁棒性。_bp算法 正则化
C语言 | 指针详解_pc指针-程序员宅基地
文章浏览阅读2.8k次,点赞11次,收藏52次。什么是指针?1. 指针是内存中一个最小单元的编号,也就是地址2.平常口语中的指针通常是指针变量前面我们讲过,地址就是一个编号,那么这个编号怎么来的呢?实际上,在32位的机器上,有32根地址线,每根地址线由高低电频表示1和0,而由这32根地址线可以表示2^32个编号,每个编号就是我们所说的地址了,可按照下图理解每个地址都能找到对应的一块空间,每块空间大小都是1字节,我们也可以将地址编号理解成为我们生活中酒店的门牌号,而每个门牌号都对应一个房间,每个地址也有对应的一块内存空间。_pc指针
Altium designer 原理图转换为pcb时出现的 unknown pin 和 failed to add class member_ad转pcb提示未知引脚-程序员宅基地
文章浏览阅读4.3k次,点赞14次,收藏31次。网上有很多方法,大部分都是让直接新建一个pcb文件,这显然太不现实了。 上述错误可以看出,unknown pin 的错误是在add pin to net的时候发生的 failed to add class member 的错误实在add to component class member发生的 要想根本解决这个问题,要了解net和class的作用。 首先net的作用是..._ad转pcb提示未知引脚
随便推点
springBoot整合ElasticSearch_spring-boot-dependencies elasticsearch-程序员宅基地
文章浏览阅读173次。目录SpringBoot整合ElasticSearch1、导入依赖2、编写测试类1)测试保存数据2)测试获取数据其他1. kibana控制台命令SpringBoot整合ElasticSearch1、导入依赖这里的版本要和所按照的ELK版本匹配。<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level_spring-boot-dependencies elasticsearch
神奇的贝叶斯定理(一)_贝叶斯 红球-程序员宅基地
文章浏览阅读918次。贝叶斯定理看起来是如此的简单,但却有着神奇的功效,这非常符合国人治病求医的思维模式---偏方治百病,但贝叶斯不是偏方,它虽然小,却很美 P(B|A)=P(A|B)P(B)/P(A) 上面就是贝叶斯定理,理解起来非常容易 P(B|A) : 已知A发生,求B发生的概率 P(A|B) : 已知B发生时,A发生的概率 P(B) _贝叶斯 红球
ChatGLM + LoRA 进行finetune_chatglm rola killed-程序员宅基地
文章浏览阅读1.6k次。ChatGLM + LoRA 进行finetune_chatglm rola killed
使用vs2015编译、部署ssd-caffe(weiliu89版,CPU模式)-程序员宅基地
文章浏览阅读381次。使用vs2015编译、部署ssd-caffe(weiliu89版,CPU模式) 前因项目所需,须训练一个快速模型以实现目标物体的实时检测。历经多次实践,发现MobileNetSSD网络符合要求,故在本人工作PC上部署weiliu89版本的ssd-caffe以期用之训练项目要求之模型。当时思之甚简,网络上相关文章多矣,此事应不成问题。..._vs2015 模板参数与声明不兼容
hbuilderx适配Android11,小米11在HBuilderX中真机联调问题-程序员宅基地
文章浏览阅读2.9k次。(1) 问题:为检测到手机或模拟器解决:手机开启usb调试(2) 安装HBuilder基座App失败10:33:50.398 正在编译中...10:34:09.363 DONE Build complete. Watching for changes...10:34:09.364 项目 'jack-edge-app' 编译成功。10:34:09.969 正在建立手机连接...10:34:09...._error: unable to open file: /sdcard/android_base.apk
Android开发之ADB命令使用技巧_adb iockbrowsor-程序员宅基地
文章浏览阅读2.1k次。学习Android的小伙伴们一定都听过ADB吧,如果没有听过也没有关系,下面我将介绍ADB及一些ADB命令的使用技巧.ADB的全称是Android Debug Bridge,直接翻译过来就是Android调试桥,它就像一个纽带,可以让我们在电脑上操作手机,我们可以在电脑上对其发送一些指令来调试它._adb iockbrowsor