一文解析linux spinlock/rwlock/seqlock原理(基于ARM64)-程序员宅基地
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 概述
吹起并发机制研究的进攻号角了!
作为第一篇文章,应该提纲挈领的介绍下并发。什么是并发,并发就是:你有两个儿子,同时抢一个玩具玩,你一巴掌打在你大儿子手上,小儿子拿到了玩具。并发是指多个执行流访问同一个资源,并发引起竞态。
来张图吧:
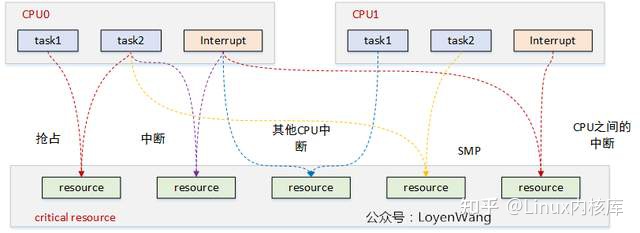
图中每一种颜色代表一种竞态情况,主要归结为三类:
- 进程与进程之间:单核上的抢占,多核上的SMP;
- 进程与中断之间:中断又包含了上半部与下半部,中断总是能打断进程的执行流;
- 中断与中断之间:外设的中断可以路由到不同的CPU上,它们之间也可能带来竞态;
目前内核中提供了很多机制来处理并发问题,spinlock就是其中一种。
spinlock,就是大家熟知的自旋锁,它的特点是自旋锁保护的区域不允许睡眠,可以用在中断上下文中。自旋锁获取不到时,CPU会忙等待,并循环测试等待条件。自旋锁一般用于保护很短的临界区。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
2. spinlock原理分析
2.1spin_lock/spin_unlock
先看一下函数调用流程:

- spin_lock操作中,关闭了抢占,也就是其他进程无法再来抢占当前进程了;
- spin_lock函数中,关键逻辑需要依赖于体系结构的实现,也就是arch_spin_lock函数;
- spin_unlock函数中,关键逻辑需要依赖于体系结构的实现,也就是arch_spin_unlock函数;
直接看ARM64中这个arch_spin_lock/arch_spin_unlock函数的实现吧:
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned int tmp;
arch_spinlock_t lockval, newval;
asm volatile(
/* Atomically increment the next ticket. */
ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" prfm pstl1strm, %3\n"
"1: ldaxr %w0, %3\n"
" add %w1, %w0, %w5\n"
" stxr %w2, %w1, %3\n"
" cbnz %w2, 1b\n",
/* LSE atomics */
" mov %w2, %w5\n"
" ldadda %w2, %w0, %3\n"
__nops(3)
)
/* Did we get the lock? */
" eor %w1, %w0, %w0, ror #16\n"
" cbz %w1, 3f\n"
/*
* No: spin on the owner. Send a local event to avoid missing an
* unlock before the exclusive load.
*/
" sevl\n"
"2: wfe\n"
" ldaxrh %w2, %4\n"
" eor %w1, %w2, %w0, lsr #16\n"
" cbnz %w1, 2b\n"
/* We got the lock. Critical section starts here. */
"3:"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp), "+Q" (*lock)
: "Q" (lock->owner), "I" (1 << TICKET_SHIFT)
: "memory");
}
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
unsigned long tmp;
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" ldrh %w1, %0\n"
" add %w1, %w1, #1\n"
" stlrh %w1, %0",
/* LSE atomics */
" mov %w1, #1\n"
" staddlh %w1, %0\n"
__nops(1))
: "=Q" (lock->owner), "=&r" (tmp)
:
: "memory");
}spinlock的核心思想是基于tickets的机制:
每个锁的数据结构arch_spinlock_t中维护两个字段:next和owner,只有当next和owner相等时才能获取锁;
每个进程在获取锁的时候,next值会增加,当进程在释放锁的时候owner值会增加;
如果有多个进程在争抢锁的时候,看起来就像是一个排队系统,FIFO ticket spinlock;
上边的代码中,核心逻辑在于asm volatile()内联汇编中,有点迷糊吗?把核心逻辑翻译成C语言,类似于下边:

- asm volatile内联汇编中,有很多独占的操作指令,只有基于指令的独占操作,才能保证软件上的互斥,简单介绍如下:
- ldaxr:Load-Acquire Exclusive Register derives an address from a base register value, loads a 32-bit word or 64-bit doubleword from memory, and writes it to a register,从内存地址中读取值到寄存器中,独占访问;
- stxr:Store Exclusive Register stores a 32-bit or a 64-bit doubleword from a register to memory if the PE has exclusive access to the memory address,将寄存器中的值写入到内存中,并需要返回是否独占访问成功;
- eor:Bitwise Exclusive OR,执行独占的按位或操作;
- ldadda:Atomic add on word or doubleword in memory atomically loads a 32-bit word or 64-bit doubleword from memory, adds the value held in a register to it, and stores the result back to memory,原子的将内存中的数据进行加值处理,并将结果写回到内存中;
- 此外,还需要提醒一点的是,在arch_spin_lock中,当自旋等待时,会执行WFE指令,这条指令会让CPU处于低功耗的状态,其他CPU可以通过SEV指令来唤醒当前CPU。
如果说了这么多,你还是没有明白,那就再来一张图吧:

2.2spin_lock_irq/spin_lock_bh
自旋锁还有另外两种形式,那就是在持有锁的时候,不仅仅关掉抢占,还会把本地的中断关掉,或者把下半部关掉(本质上是把软中断关掉)。这种锁用来保护临界资源既会被进程访问,也会被中断访问的情况。
看一下调用流程图:

- 可以看到这两个函数中,实际锁的机制实现跟spin_lock是一样的;
- 额外提一句,spin_lock_irq还有一种变种形式spin_lock_irqsave,该函数会将当前处理器的硬件中断状态保存下来;
__local_bh_disable_ip是怎么实现的呢,貌似也没有看到关抢占?有必要前情回顾一下了,如果看过之前的文章的朋友,应该见过下边这张图片:

- thread_info->preempt_count值就维护了各种状态,针对该值的加减操作,就可以进行状态的控制;
3. rwlock读写锁
- 读写锁是自旋锁的一种变种,分为读锁和写锁,有以下特点:
- 可以多个读者同时进入临界区;
- 读者与写者互斥;
- 写者与写者互斥;
先看流程分析图:

看一下arch_read_lock/arch_read_unlock/arch_write_lock/arch_write_unlock源代码:
static inline void arch_read_lock(arch_rwlock_t *rw)
{
unsigned int tmp, tmp2;
asm volatile(
" sevl\n"
ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
"1: wfe\n"
"2: ldaxr %w0, %2\n"
" add %w0, %w0, #1\n"
" tbnz %w0, #31, 1b\n"
" stxr %w1, %w0, %2\n"
" cbnz %w1, 2b\n"
__nops(1),
/* LSE atomics */
"1: wfe\n"
"2: ldxr %w0, %2\n"
" adds %w1, %w0, #1\n"
" tbnz %w1, #31, 1b\n"
" casa %w0, %w1, %2\n"
" sbc %w0, %w1, %w0\n"
" cbnz %w0, 2b")
: "=&r" (tmp), "=&r" (tmp2), "+Q" (rw->lock)
:
: "cc", "memory");
}
static inline void arch_read_unlock(arch_rwlock_t *rw)
{
unsigned int tmp, tmp2;
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
"1: ldxr %w0, %2\n"
" sub %w0, %w0, #1\n"
" stlxr %w1, %w0, %2\n"
" cbnz %w1, 1b",
/* LSE atomics */
" movn %w0, #0\n"
" staddl %w0, %2\n"
__nops(2))
: "=&r" (tmp), "=&r" (tmp2), "+Q" (rw->lock)
:
: "memory");
}
static inline void arch_write_lock(arch_rwlock_t *rw)
{
unsigned int tmp;
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" sevl\n"
"1: wfe\n"
"2: ldaxr %w0, %1\n"
" cbnz %w0, 1b\n"
" stxr %w0, %w2, %1\n"
" cbnz %w0, 2b\n"
__nops(1),
/* LSE atomics */
"1: mov %w0, wzr\n"
"2: casa %w0, %w2, %1\n"
" cbz %w0, 3f\n"
" ldxr %w0, %1\n"
" cbz %w0, 2b\n"
" wfe\n"
" b 1b\n"
"3:")
: "=&r" (tmp), "+Q" (rw->lock)
: "r" (0x80000000)
: "memory");
}
static inline void arch_write_unlock(arch_rwlock_t *rw)
{
asm volatile(ARM64_LSE_ATOMIC_INSN(
" stlr wzr, %0",
" swpl wzr, wzr, %0")
: "=Q" (rw->lock) :: "memory");
}知道你们不爱看汇编代码,那么翻译成C语言的伪代码看看吧:

- 读写锁数据结构arch_rwlock_t中只维护了一个字段:volatile unsigned int lock,其中bit[31]用于写锁的标记,bit[30:0]用于读锁的统计;
- 读者在获取读锁的时候,高位bit[31]如果为1,表明正有写者在访问临界区,这时候会进入自旋的状态,如果没有写者访问,那么直接去自加rw->lock的值,从逻辑中可以看出,是支持多个读者同时访问的;
- 读者在释放锁的时候,直接将rw->lock自减1即可;
- 写者在获取锁的时候,判断rw->lock的值是否为0,这个条件显得更为苛刻,也就是只要有其他读者或者写者访问,那么都将进入自旋,没错,它确实很霸道,只能自己一个人持有;
- 写者在释放锁的时候,很简单,直接将rw->lock值清零即可;
- 缺点:由于读者的判断条件很苛刻,假设出现了接二连三的读者来访问临界区,那么rw->lock的值将一直不为0,也就是会把写者活活的气死,噢,是活活的饿死。
读写锁当然也有类似于自旋锁的关中断、关底半部的形式:read_lock_irq/read_lock_bh/write_lock_irq/write_lock_bh,原理都类似,不再赘述了。
4. seqlock顺序锁
- 顺序锁也区分读锁与写锁,它的优点是读者不会把写者给饿死。
来看一下流程图:

- 顺序锁的读锁有三种形式:
- 无加锁访问,读者在读临界区之前,先读取序列号,退出临界区操作后再读取序列号进行比较,如果发现不相等,说明被写者更新内容了,需要重新再读取临界区,所以这种情况下可能给读者带来的开销会大一些;
- 加锁访问,实际是spin_lock/spin_unlock,仅仅是接口包装了一下而已,因此对读和写都是互斥的;
- 在形式1和形式2中动态选择,如果有写者在写临界区,读者化身为自旋锁,没有写者在写临界区,则化身为顺序无锁访问;
- 顺序锁的写锁,只有一种形式,本质上是用自旋锁来保护临界区,然后再把序号值自加处理;
- 顺序锁也有一些局限的地方,比如采用读者的形式1的话,临界区中存在地址(指针)操作,如果写者把地址进行了修改,那就可能造成访问错误了;
- 说明一下流程图中的smp_rmb/smp_wmb,这两个函数是内存屏障操作,作用是告诉编译器内存中的值已经改变,之前对内存的缓存(缓存到寄存器)都需要抛弃,屏障之后的内存操作需要重新从内存load,而不能使用之前寄存器缓存的值,内存屏障就像是代码中一道不可逾越的屏障,屏障之前的load/store指令不能跑到屏障的后边,同理,后边的也不能跑到前边;
- 顺序锁也同样存在关中断和关下半部的形式,原理基本都是一致的,不再啰嗦了。
最近在项目中,遇到了RCU Stall的问题,下一个topic就先来看看RCU吧,其他的并发机制都会在路上,Just keep growing and fuck everthing else,收工!

智能推荐
通用存储过程分页(top max模式)版本(性能相对之前的not in版本极大提高) _top 搭配not in 性能-程序员宅基地
文章浏览阅读1.3k次。 --/*-----存储过程 分页处理 孙伟 2005-03-28创建 -------*/--/*----- 对数据进行了2分处理使查询前半部分数据与查询后半部分数据性能相同 -------*/--/*-----存储过程 分页处理 孙伟 2005-04-21修改 添加Distinct查询功能-------*/--/*-----存储过程 分页处理 孙伟 2005-05-18修改 多字段排序规则问题-_top 搭配not in 性能
vue新玩法VueUse-工具库@vueuse/core-程序员宅基地
文章浏览阅读1.5w次,点赞3次,收藏10次。VueUse官方链接一、什么是VueUseVueUse不是Vue.use !!!它是一个基于 Composition API 的实用函数集合,下面是具体的一些用法二、如何引入import { 具体方法 } from ‘@vueuse/core’三、下面来看看一些具体的用法1、useMouse:监听当前鼠标坐标的一个方法,他会实时的获取鼠标的当前的位置2、usePreferredDark:判断用户是否喜欢深色的方法,他会实时的判断用户是否喜欢深色的主题3、useLocalStorage:数据_vueuse/core
统计学5大基本概念,建议收藏!(文末送书)-程序员宅基地
文章浏览阅读736次。转自:爱数据LoveD大家好,我是小z,也可以叫我阿粥~今天给大家分享一波统计学重要概念,顺便前排提示文末送书~从高的角度来看,统计学是一种利用数学理论来进行数据分析的技术。象柱状图这种基本的可视化形式,会给你更加全面的信息。但是,通过统计学我们可以以更富有信息驱动力和针对性的方式对数据进行操作。所涉及的数学理论帮助我们形成数据的具体结论,而不仅仅是猜测。利用统计学,我们可以更深入、更细致地观察数..._统计学五大基本原理
Java多线程4:synchronized的使用场景和原理简介_synchronized常见使用场景 threadsyntest.new myrunnable3-程序员宅基地
文章浏览阅读2.4k次,点赞3次,收藏9次。一、synchronized使用1.1 synchronized介绍在多线程并发编程中synchronized一直是元老级角色,很多人都会称呼它为重量级锁。但是,随着Java SE 1.6对synchronized进行了各种优化之后,有些情况下它就并不那么重了。synchronized可以修饰普通方法,静态方法和代码块。当synchronize..._synchronized常见使用场景 threadsyntest.new myrunnable3
Windows python用impyla连接远程Hive数据库_python impyla demo-程序员宅基地
文章浏览阅读260次。安装下述包:thirftpythirft-saslthirftpure-sasl(卸载sasl,若要用pyhive,sasl轮子安装路径Link)impyla# -*- coding:UTF-8 -*-from impala.dbapi import connect#下述host只是个demo,需填入真实ipconn = connect(host='11.22.33.44', port=21050, auth_mechanism='PLAIN',user='yourusername',pa_python impyla demo
php 编译 pdo_mysql_Linux正确编译pdo_mysql扩展-程序员宅基地
文章浏览阅读280次。错误编译pdo_mysqlphp扩展的操作流程,以及解决错误并成功完成编译pdo_mysql新编译的PHP环境运行项目时报错PHP Fatal error: Undefined class constant 'MYSQL_ATTR_INIT_COMMAND'原因是没有加载pdo_mysql扩展错误配置pdo_mysql及编译cd ext/pdo_mysqlphpize./configure --w..._/usr/local/php7.4.24/ext/pdo_mysql/php_pdo_mysql_int.h:29:11: fatal error: m
随便推点
python语言程序设计实践教程陈东上海交通大学答案_《软件开发训练营:ASP.NET开发一站式学习难点》杨云著【摘要 书评 在线阅读】-苏宁易购图书...-程序员宅基地
文章浏览阅读2.7k次。商品参数作者:杨云著出版社:清华大学出版社出版时间:2013-8-1版次:1印次:1印刷时间:2013-8-1页数:434开本:16开装帧:平装ISBN:9787302318286版权提供:清华大学出版社编辑推荐《软件开发训练营·ASP.NET开发一站式学习:难点·案例·练习》特色:1.《软件开发训练营·ASP.NET开发一站式学习:难点·案例·练习》所讲内容既避开艰涩难懂的理论知识,又覆盖了编程..._python语言程序设计实践教程陈东课后习题答案解析
解决:Qt项目构建成功,但是运行异常退出。_qt安装后构建可以,运行就一直提示程序异常-程序员宅基地
文章浏览阅读2k次。构建:从debug换成release:就可以正常运行了_qt安装后构建可以,运行就一直提示程序异常
李宏毅2021机器学习笔记(一)_李宏毅2021机器学习笔记 百度-程序员宅基地
文章浏览阅读601次。什么是机器学习?简单来说就是让机器帮我们找一个函数,即一个映射。如声音—>文字的语音识别函数自变量可以是向量,矩阵(图像识别),序列输出是数值、图片等课程讲什么?一、监督学习,给定图片人工的告诉机器其类型,训练模型,让机器拥有 f(图片)—>类型 这一函数二、训练模型之前进行Pre-train,让机器学习如何辨别图片这一基本功,因为人工输入图片类型过于繁琐。只需传入大量图片资料即可自动训练。如把图片翻转、变色,询问机器是不是可以..._李宏毅2021机器学习笔记 百度
stdmap c++两个map合并成一个map ,c++多个map的合并_c++ map合并-程序员宅基地
文章浏览阅读1.7k次。两个map合并成一个map,用insert()函数就可以了,看代码:#include <map>#include <iostream>int main(){ std::map<int, int> v1 = {{1, 1}, {2, 1}, {3, 1}, {4, 1}, {5, 1}}; std::map<int, int> v2 = { {3, 2}, {4, 2}, {5, 2}, {6, 2}, {7_c++ map合并
CLion:使用CLion新建一个C语言项目_clion创建c语言项目-程序员宅基地
文章浏览阅读1.3w次,点赞12次,收藏85次。步骤1、2、3、我喜欢一个文件夹下存放多个项目,所以删掉生成的CMakeList.txt、main.c和cmake-build-debug文件。新建一个List目录,并在该目录下新建CMakeList.txt4、创建一个C文件进行测试5、创建好后,提示在List文件夹下的CMakeList.txt添加:include_directories(.)add_executable(List-List01 List01.c) //List是文件夹名称,List01.c是具体文件名称_clion创建c语言项目
鸟哥的 linux 的私房菜 基础学习篇,鸟哥的 Linux 私房菜 -- 基础学习篇-程序员宅基地
文章浏览阅读5k次。再次强调:底下的几篇短文是学习 Linux 的基础文件,这些文件是基础中的基础,如果您能将其中的文件都看完,并且消化过,那么未来在管理 Linux 主机以及架设网站方面,就能够达到『事半功倍』的成效,请不要忽略这部份了!否则,再怎么讨论都是枉然的啦! ^_^第一部份:Linux 的规划与安装Linux 本身虽然具有相当强大的功能,不过,如果不能理解 Linux 的工作能力,那么 Linux 能做的..._鸟哥linux基础篇