SHAP: 在我眼里,没有黑箱_python对shap的计算只能针对大数值吗-程序员宅基地
技术标签: 零基础入门数据挖掘 SHAP 竞赛学习笔记 特征选择 Feature import
1. 写在前面
很多高级的机器学习模型(xgboost, lgb, cat)和神经网络模型, 它们相对于普通线性模型在进行预测时往往有更好的精度,但是同时也失去了线性模型的可解释性, 所以这些模型也往往看作是黑箱模型, 在2017年,Lundberg和Lee的论文提出了SHAP值这一广泛适用的方法用来解释各种模型(分类以及回归), 使得前面的黑箱模型变得可解释了,这篇文章主要整理一下SHAP的使用, 这个在特征选择的时候特别好用。
这次整理, 主要是在xgboost和lgb等树模型上的使用方式, 并且用一个真实的数据集进行演示, 详细的内容参考SHAP的原地址:https://github.com/slundberg/shap
2. 简单回忆特征选择
一般在机器学习中, 我们想看哪些特征对目标变量有重要作用的时候, 常用的有下面几种方式:
-
求相关性
这个往往可以判别出某些特征和目标变量之间是否有线性相关关系, 从而去看某些特征的重要性程度, 一般我们喜欢保留线性相关关系大的一些特征。 -
包裹式
这个说白了, 就是直接把数据放到像xgboost和lgb这种模型中训练, 训练完了之后, 再用feature importance可视化每个特征的重要性, 从而看哪些特征对最终的模型影响较大, But, 这种方式无法判断特征与最终预测结果的关系是如何的, 即不知道怎么影响的,待会给出真实例子来演示。 -
permutation importance
这是在kaggle比赛中学习到的一种特征筛选的方式, 所以也借机整理一下, 这个方式还是很不错的, 这个思路就是用所有的特征训练模型, 然后再在验证集上得到验证误差, 然后遍历每一个特征, 随机打乱这个特征的值, 再计算验证误差, 用后面的验证误差和前面的验证误差进行对比, 就可以看出该特征对于减少误差的贡献程度, 也就能看出特征的重要性。这里整理一下这种方式(思路):# 首先我们先建立一个模型, 然后写一个训练模型的函数 lgb_params = { 'boosting_type': 'gbdt', # Standart boosting type 'objective': 'mae', # Standart loss for RMSE 'metric': ['mae'], # as we will use rmse as metric "proxy" 'subsample': 0.8, 'subsample_freq': 1, 'learning_rate': 0.05, # 0.5 is "fast enough" for us 'num_leaves': 2**7-1, # We will need model only for fast check 'min_data_in_leaf': 2**8-1, # So we want it to train faster even with drop in generalization 'feature_fraction': 0.8, 'n_estimators': 5000, # We don't want to limit training (you can change 5000 to any big enough number) 'early_stopping_rounds': 30, # We will stop training almost immediately (if it stops improving) 'seed': 2020, 'verbose': -1, } def make_fast_test(sel_data): train_ready = sel_data[sel_data['time'] < pd.to_datetime('2019-12-10')].drop(columns = ['time']) x_train = train_ready.drop(columns = ['TTI']) y_train = train_ready['TTI'] val_ready = sel_data[sel_data['time'] >= pd.to_datetime('2019-12-10')].drop(columns = ['time']) x_val = val_ready.drop(columns = ['TTI']) y_val = val_ready['TTI'] train_data = lgb.Dataset(x_train, label=y_train) val_data = lgb.Dataset(x_val, label=y_val) estimator = lgb.train(lgb_params, train_data, valid_sets=[train_data, val_data], verbose_eval=500) return estimator # 调用函数建立训练好的模型 test_model = make_fast_test(sel_data) # 做一个验证集 features_columns = sel_data.drop(columns='time').columns.tolist() features_columns.remove('TTI') val_ready = val_ready = sel_data[sel_data['time'] >= pd.to_datetime('2019-12-10')].drop(columns = ['time']) x_val = val_ready.drop(columns = ['TTI']) y_val = val_ready['TTI'] pre = test_model.predict(x_val) base_score = mean_absolute_error(pre, y_val) print('startscore: ', base_score) # 这里会得到模型在验证集上的分数 # 接下来就是尝试筛选特征,对于每个特征, # 把那一列的值进行随机打乱, 然后再用之前的模型进行预测, 得到验证误差 # 对比这俩误差的不同, 就会发现每个特征对于模型来说,是有利于模型表现好还是表现差 for col in features_columns: temp_df = x_val.copy() temp_df[col] = np.random.permutation(temp_df[col].values) pre = test_model.predict(temp_df) cur_score = mean_absolute_error(pre, y_val) print(col, np.round(cur_score-base_score, 4))这个方式,其实就能够既判断出特征的重要性, 也能判断出特征是怎么影响模型的。
而有了SHAP之后, 貌似是这一切变得更加简单。
下面通过一个真实的例子, 来看一下之前的Feature importance和SHAP的具体使用, 这里用的数据集是一个数据竞赛的数据集
3. Feature importance VS SHAP
3.1 Feature importance
在SHAP被广泛使用之前,我们通常用feature importance或者partial dependence plot来解释xgboost等机器学习模型。 feature importance是用来衡量数据集中每个特征的重要性。每个特征对于提升整个模型的预测能力的贡献程度就是特征的重要性。
下面根据这个案例来看看, 先导入包和数据, 然后训练xgb和lgb。
import xgboost as xgb
import lightgbm as lgb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('seaborn')
# 读取数据
data = pd.read_csv('data/train.csv', index_col=0)
# 获得球员的年龄
today = pd.to_datetime('2018-01-01')
data['birth_date'] = pd.to_datetime(data['birth_date'])
data['age'] = np.round((today-data['birth_date']).apply(lambda x:x.days) / 365., 1)
# 选择部分特征举例
# 特征依次为身高(厘米)、潜力、速度、射门、传球、带球、防守、体格、国际知名度、年龄
cols = ['height_cm', 'potential', 'pac', 'sho', 'pas', 'dri', 'def', 'phy',
'international_reputation', 'age']
model1 = xgb.XGBRegressor(max_depth=4, learning_rate=0.05, n_estimators=150)
model2 = lgb.LGBMRegressor()
model1.fit(data[cols], data['y'])
model2.fit(data[cols], data['y'])
下面我们可以画出每个特征的重要性程度:
# 获取feature importance
plt.figure(figsize=(20, 10))
plt.subplot(1, 2, 1)
plt.bar(range(len(cols)), model1.feature_importances_)
plt.xticks(range(len(cols)), cols, rotation=-45, fontsize=14)
plt.title('Xgb Feature importance', fontsize=14)
plt.subplot(1, 2, 2)
plt.bar(range(len(cols)), model2.feature_importances_)
plt.xticks(range(len(cols)), cols, rotation=-45, fontsize=14)
plt.title('Lgb Feature importance', fontsize=14)
plt.show()
结果如下:
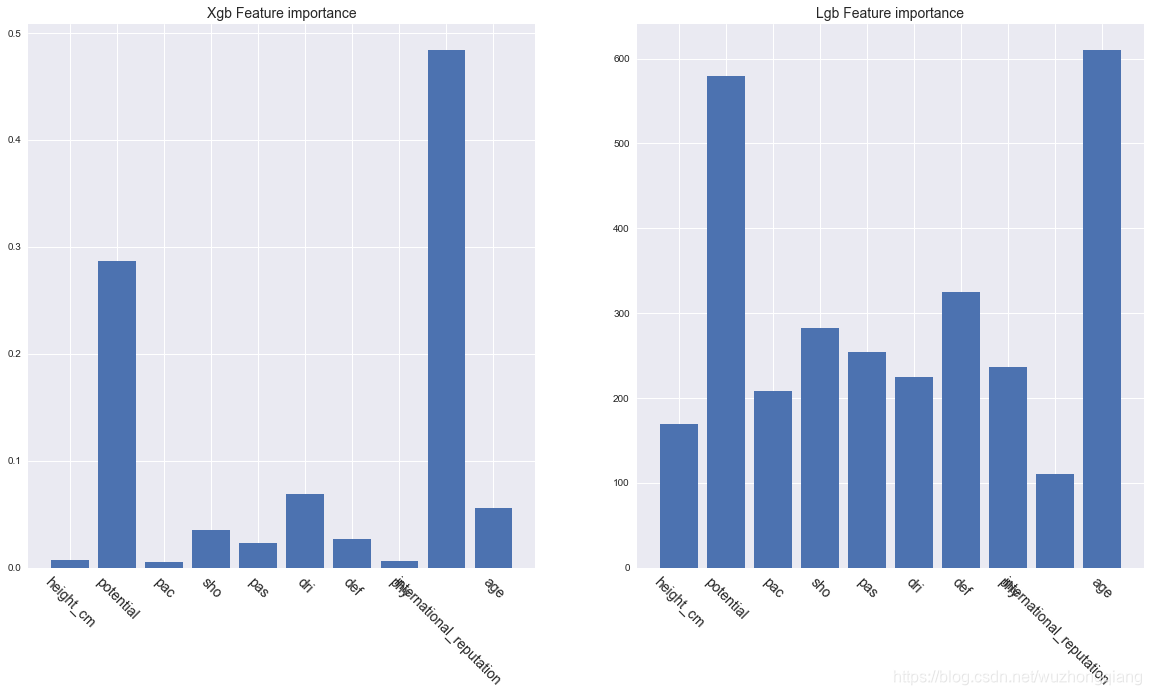
对于xgboost来说,我们可以看出国际知名度、潜力和年龄是影响球员身价最重要的三个因素。而LGB来说, 潜力和年龄很重要, 但是这些因素和身价是正相关、负相关还是其他更复杂的相关性,我们无法从上图得知。我们也无法解读每个特征对每个个体的预测值的影响。
3.2 SHAP value
SHAP的名称来源于SHapley Additive exPlanation。
Shapley value起源于合作博弈论。比如说甲乙丙丁四个工人一起打工,甲和乙完成了价值100元的工件,甲、乙、丙完成了价值120元的工件,乙、丙、丁完成了价值150元的工件,甲、丁完成了价值90元的工件,那么该如何公平、合理地分配这四个人的工钱呢?Shapley提出了一个合理的计算方法(有兴趣地可以查看原论文),我们称每个参与者分配到的数额为Shapley value。
SHAP是由Shapley value启发的可加性解释模型。对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。假设第 i i i个样本为 x i x_i xi, 第 i i i个样本的第 j j j个特征为 x i j x_{ij} xij, 模型对于第 i i i个样本的预测值为 y i y_i yi, 整个模型的基线(通常是所有样本目标变量的均值)为 y b a s e y_{base} ybase, 那么SHAP value服从以下等式。
y i = y b a s e + f ( x i 1 ) + f ( x i 2 ) + f ( x i 3 ) + . . . . + f ( x i k ) y_i = y_{base}+f(x_{i1})+f(x_{i2})+f(x_{i3})+....+f(x_{ik}) yi=ybase+f(xi1)+f(xi2)+f(xi3)+....+f(xik)
其中, f ( x i k ) f(x_{ik}) f(xik)为 x i k x_{ik} xik的SHAP值。 直观上看, f ( x i k ) f_(x_{ik}) f(xik)就是第 i i i个样本中第 k k k个特征对最终预测值 y i y_i yi的贡献值, 当 f ( x i k ) > 0 f_(x_{ik})>0 f(xik)>0, 说明该特征提升了预测值, 也是正向的作用, 反之, 说明该特征使得预测值降低, 有反作用。很明显可以看出,与前面的feature importance相比,SHAP value最大的优势是SHAP能对于反映出每一个样本中的特征的影响力,而且还表现出影响的正负性。
那么怎么用呢?
3.3 SHAP的python实现
Python中SHAP值的计算由shap这个package实现,可以通过pip install shap安装。
import shap
# 导入package, 就可以用shape获得一个解释器
explainer_xgb = shap.TreeExplainer(model1)
explainer_lgb = shap.TreeExplainer(model2)
# 获取训练集data各个样本各个特征的SHAP值
shape_values = explainer_lgb.shap_values(data[cols])
shape_values.shape # data中有10441个样本10个特征, 所以这里的SHAP值是每个样本每个特征的shap值
# 获得基线ybase
ybase_xgb = explainer_xgb.expected_value
ybase_lgb = explainer_lgb.expected_value
print(ybase_lgb, ybase_xgb) # 229.28876544209956 [229.1682549]
## 基线值等于训练集的目标变量的拟合值的均值
pred_xgb = model1.predict(data[cols])
pred_lgb = model2.predict(data[cols])
print(pred_lgb.mean(), pred_xgb.mean()) # 229.28876544209956 229.16826
3.3.1 单个样本的SHAP的值
可以随机检查某一个球员身价的预测值以及各个特征对其预测值的影响。
j = 30
player_explainer = pd.DataFrame()
player_explainer['feature'] = cols
player_explainer['feature_values'] = data[cols].iloc[j].values
player_explainer['shap_value'] = shape_values[j]
player_explainer
结果如下:

# 一个样本中各个特征SHAP的值的和加上基线值应该等于该样本的预测值
print(ybase_lgb+player_explainer['shap_value'].sum(), pred_lgb[j])
shap还提供了强大的数据可视化功能。
shap.initjs()
shap.force_plot(explainer_lgb.expected_value, shape_values[j], data[cols].iloc[j])
结果如下:

蓝色表示该特征的贡献是负数, 红色表示该特征的贡献是正数。
3.3.2 对特征的总体分析
除了能对单个样本的SHAP值进行可视化之外,还能对特征进行整体的可视化。
shap.summary_plot(shape_values, data[cols])
结果如下:

图中每一行代表一个特征,横坐标为SHAP值。一个点代表一个样本,颜色越红说明特征本身数值越大,颜色越蓝说明特征本身数值越小。
我们可以直观地看出潜力potential是一个很重要的特征,而且基本上是与身价成正相关的。年龄age也会明显影响身价,蓝色点主要集中在SHAP小于0的区域,可见年纪小会降低身价估值,另一方面如果年纪很大,也会降低估值,甚至降低得更明显,因为age这一行最左端的点基本上都是红色的。
我们也可以把一个特征对目标变量影响程度的绝对值的均值作为这个特征的重要性。因为SHAP和feature_importance的计算方法不同,所以我们这里也得到了与前面不同的重要性排序。
shap.summary_plot(shape_values, data[cols], plot_type='bar')
结果如下:

3.3.3 部分依赖图
SHAP也提供了部分依赖图的功能,与传统的部分依赖图不同的是,这里纵坐标不是目标变量y的数值而是SHAP值。
shap.dependence_plot('age', shape_values, data[cols], interaction_index=None, show=False)
结果如下:

年纪大概呈现出金字塔分布,也就是25到32岁这个年纪对球员的身价是拉抬作用,小于25以及大于32岁的球员身价则会被年纪所累。
3.3.4 对多个变量的交互进行分析
可以多个变量的交互作用进行分析。
shap_interaction_values = shap.TreeExplainer(model1).shap_interaction_values(data[cols])
shap.summary_plot(shap_interaction_values, data[cols], max_display=4)
结果如下:

3.3.5 两个变量交互下的变量对目标值的影响
shap.dependence_plot('potential', shape_values, data[cols], interaction_index='international_reputation', show=False)
结果如下:

4. 小总
小总一下, SHAP在特征选择里面挺常用的, 让很多模型变得有了可解释性。当然, 也不仅适用于机器学习模型, 同样也适用于深度学习的一些模型, 这个具体的可以看下面的GitHub链接。
参考:
智能推荐
874计算机科学基础综合,2018年四川大学874计算机科学专业基础综合之计算机操作系统考研仿真模拟五套题...-程序员宅基地
文章浏览阅读1.1k次。一、选择题1. 串行接口是指( )。A. 接口与系统总线之间串行传送,接口与I/0设备之间串行传送B. 接口与系统总线之间串行传送,接口与1/0设备之间并行传送C. 接口与系统总线之间并行传送,接口与I/0设备之间串行传送D. 接口与系统总线之间并行传送,接口与I/0设备之间并行传送【答案】C2. 最容易造成很多小碎片的可变分区分配算法是( )。A. 首次适应算法B. 最佳适应算法..._874 计算机科学专业基础综合题型
XShell连接失败:Could not connect to '192.168.191.128' (port 22): Connection failed._could not connect to '192.168.17.128' (port 22): c-程序员宅基地
文章浏览阅读9.7k次,点赞5次,收藏15次。连接xshell失败,报错如下图,怎么解决呢。1、通过ps -e|grep ssh命令判断是否安装ssh服务2、如果只有客户端安装了,服务器没有安装,则需要安装ssh服务器,命令:apt-get install openssh-server3、安装成功之后,启动ssh服务,命令:/etc/init.d/ssh start4、通过ps -e|grep ssh命令再次判断是否正确启动..._could not connect to '192.168.17.128' (port 22): connection failed.
杰理之KeyPage【篇】_杰理 空白芯片 烧入key文件-程序员宅基地
文章浏览阅读209次。00000000_杰理 空白芯片 烧入key文件
一文读懂ChatGPT,满足你对chatGPT的好奇心_引发对chatgpt兴趣的表述-程序员宅基地
文章浏览阅读475次。2023年初,“ChatGPT”一词在社交媒体上引起了热议,人们纷纷探讨它的本质和对社会的影响。就连央视新闻也对此进行了报道。作为新传专业的前沿人士,我们当然不能忽视这一热点。本文将全面解析ChatGPT,打开“技术黑箱”,探讨它对新闻与传播领域的影响。_引发对chatgpt兴趣的表述
中文字符频率统计python_用Python数据分析方法进行汉字声调频率统计分析-程序员宅基地
文章浏览阅读259次。用Python数据分析方法进行汉字声调频率统计分析木合塔尔·沙地克;布合力齐姑丽·瓦斯力【期刊名称】《电脑知识与技术》【年(卷),期】2017(013)035【摘要】该文首先用Python程序,自动获取基本汉字字符集中的所有汉字,然后用汉字拼音转换工具pypinyin把所有汉字转换成拼音,最后根据所有汉字的拼音声调,统计并可视化拼音声调的占比.【总页数】2页(13-14)【关键词】数据分析;数据可..._汉字声调频率统计
linux输出信息调试信息重定向-程序员宅基地
文章浏览阅读64次。最近在做一个android系统移植的项目,所使用的开发板com1是调试串口,就是说会有uboot和kernel的调试信息打印在com1上(ttySAC0)。因为后期要使用ttySAC0作为上层应用通信串口,所以要把所有的调试信息都给去掉。参考网上的几篇文章,自己做了如下修改,终于把调试信息重定向到ttySAC1上了,在这做下记录。参考文章有:http://blog.csdn.net/longt..._嵌入式rootfs 输出重定向到/dev/console
随便推点
uniapp 引入iconfont图标库彩色symbol教程_uniapp symbol图标-程序员宅基地
文章浏览阅读1.2k次,点赞4次,收藏12次。1,先去iconfont登录,然后选择图标加入购物车 2,点击又上角车车添加进入项目我的项目中就会出现选择的图标 3,点击下载至本地,然后解压文件夹,然后切换到uniapp打开终端运行注:要保证自己电脑有安装node(没有安装node可以去官网下载Node.js 中文网)npm i -g iconfont-tools(mac用户失败的话在前面加个sudo,password就是自己的开机密码吧)4,终端切换到上面解压的文件夹里面,运行iconfont-tools 这些可以默认也可以自己命名(我是自己命名的_uniapp symbol图标
C、C++ 对于char*和char[]的理解_c++ char*-程序员宅基地
文章浏览阅读1.2w次,点赞25次,收藏192次。char*和char[]都是指针,指向第一个字符所在的地址,但char*是常量的指针,char[]是指针的常量_c++ char*
Sublime Text2 使用教程-程序员宅基地
文章浏览阅读930次。代码编辑器或者文本编辑器,对于程序员来说,就像剑与战士一样,谁都想拥有一把可以随心驾驭且锋利无比的宝剑,而每一位程序员,同样会去追求最适合自己的强大、灵活的编辑器,相信你和我一样,都不会例外。我用过的编辑器不少,真不少~ 但却没有哪款让我特别心仪的,直到我遇到了 Sublime Text 2 !如果说“神器”是我能给予一款软件最高的评价,那么我很乐意为它封上这么一个称号。它小巧绿色且速度非
对10个整数进行按照从小到大的顺序排序用选择法和冒泡排序_对十个数进行大小排序java-程序员宅基地
文章浏览阅读4.1k次。一、选择法这是每一个数出来跟后面所有的进行比较。2.冒泡排序法,是两个相邻的进行对比。_对十个数进行大小排序java
物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)_网络调试助手连接阿里云连不上-程序员宅基地
文章浏览阅读2.9k次。物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)其实作者本意是使用4G模块来实现与阿里云物联网平台的连接过程,但是由于自己用的4G模块自身的限制,使得阿里云连接总是无法建立,已经联系客服返厂检修了,于是我在此使用网络调试助手来演示如何与阿里云物联网平台建立连接。一.准备工作1.MQTT协议说明文档(3.1.1版本)2.网络调试助手(可使用域名与服务器建立连接)PS:与阿里云建立连解释,最好使用域名来完成连接过程,而不是使用IP号。这里我跟阿里云的售后工程师咨询过,表示对应_网络调试助手连接阿里云连不上
<<<零基础C++速成>>>_无c语言基础c++期末速成-程序员宅基地
文章浏览阅读544次,点赞5次,收藏6次。运算符与表达式任何高级程序设计语言中,表达式都是最基本的组成部分,可以说C++中的大部分语句都是由表达式构成的。_无c语言基础c++期末速成