手写B+树-程序员宅基地
1.特点
https://blog.csdn.net/weixin_57128596/article/details/127030901?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167176442416800188598723%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=167176442416800188598723&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-2-127030901-null-null.blog_rank_default&utm_term=B%2B&spm=1018.2226.3001.4450
1.整体有序
2.一个节点下面多个元素
3.非叶子节点没有指向当前数据的指针,叶子节点有
4.节点下的元素是有序的
5.叶子节点包含上面的所有数据,叶子节点之间是一个链表,不需要返回根节点再搜索其他节点**(核心 )**
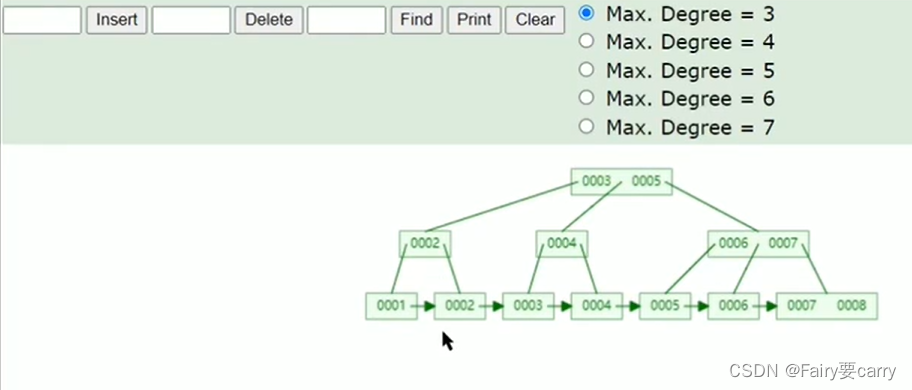
2. 抛出问题:为什么数据库插入数据会默认给你排好序
下图所示:插入了几条数据进入mysql,会根据主键进行排序,用主键效率会高一点,不然一下中间一下下面的,效率肯定受影响,自增往后面叠就行了
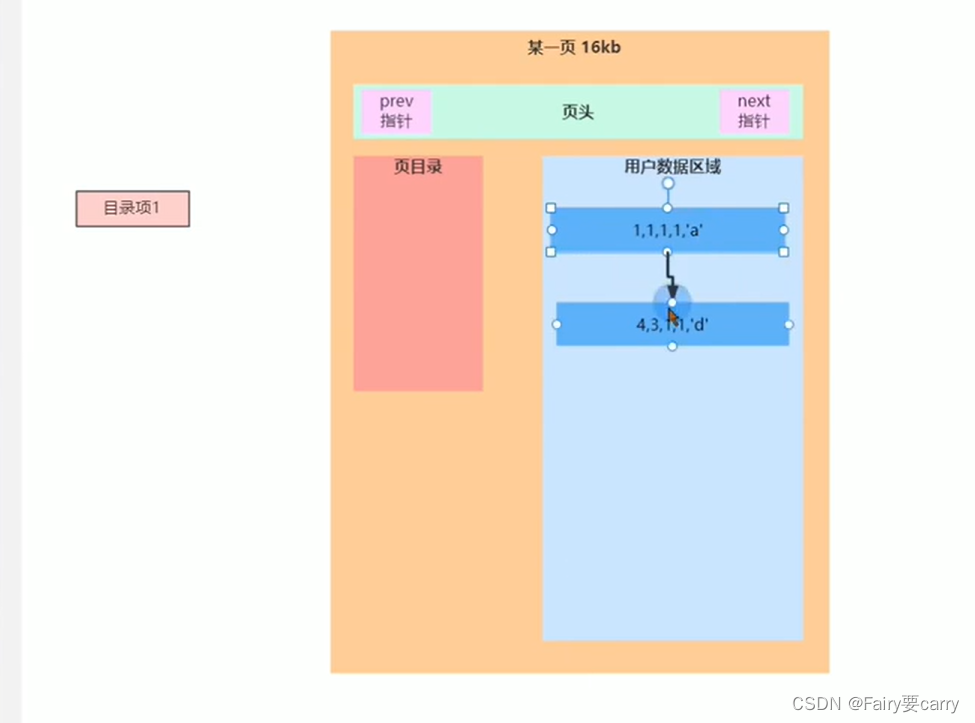
查询
在查询的时候,原先查询数据就像翻书一样一页一页翻,而我们这里你找到了就不会继续向下遍历了
更重要的是设置了目录:
会根据我们设置的主键确定目录,我们只需要判断有没有这个目录就能确定这个数据在不在这里面了,效率非常高,比如查询a=3,目录由主键确定1和4,那么a=3就会从主键为1的地方目录进行遍历寻找,如果遍历完没有就没有**(剩下了很多的遍历)**
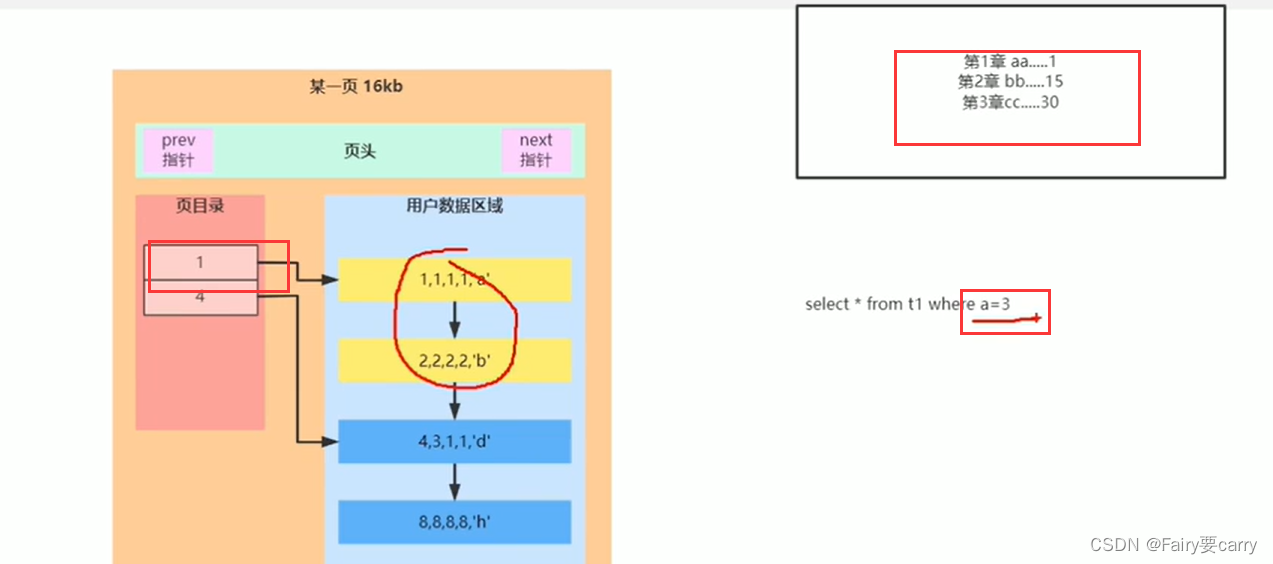
一页只要16kb满了怎么办
如果一页存储插入的数据有限,那么更多的数据就会到第二页上面
当我们进行搜寻的时候就会先遍历第一页,如果第一页没有再在第二页中搜寻——>(页数很多的情况搜索很难,比如数据在100页但是我还遍历了前99页的目录)
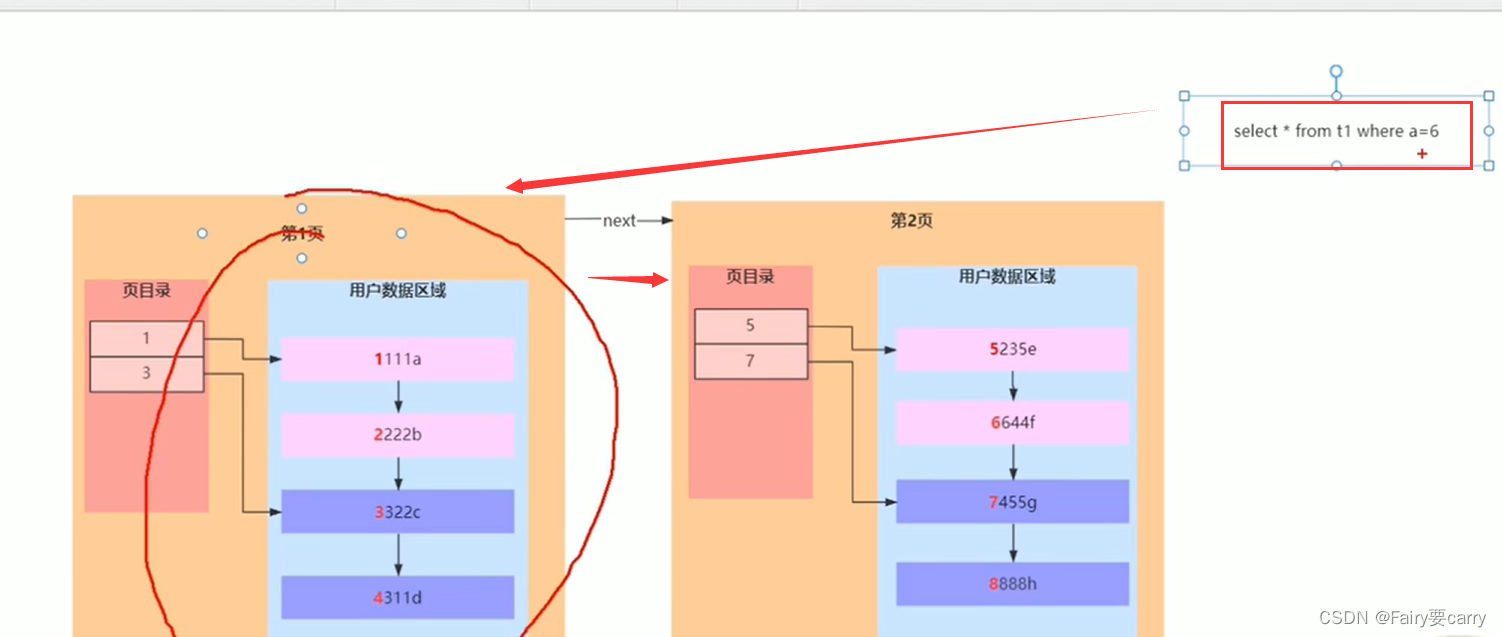
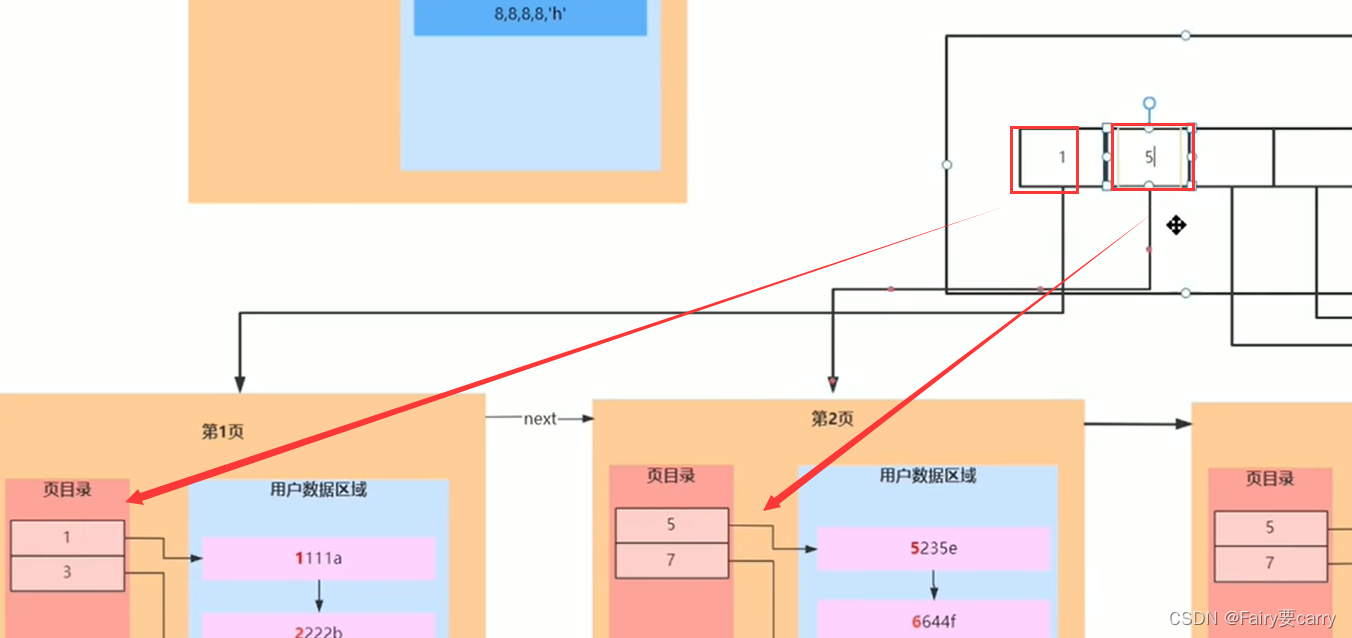
页目录优化
在创建一个目录,将每一页页目录中最小的主键放到这个目录里面,当我们进行搜索的时候可以先根据这个目录确定数据所在数据页,然后进而确定哪个位置
比如下面的你找主键id为3,就会根据主键值找到具体的数据页,然后再根据数据的页目录找到具体的用户数据
其实我们这个页目录就很像索引的建立
2.插入操作
1.插入的操作全部都在叶子结点上进行,且不能破坏关键字自小而大的顺序;
2.由于 B+树中各结点中存储的关键字的个数有明确的范围,做插入操作可能会出现结点中关键字个数超过阶数的情况,此时需要将该结点进行 “分裂”;
我们依旧以之前介绍查找操作时使用的图对插入操作进行说明,需要注意的是,B+树的阶数 M = 3 ,且 ⌈M/2⌉ = 2(取上限) 、⌊M/2⌋ = 1(取下限) :
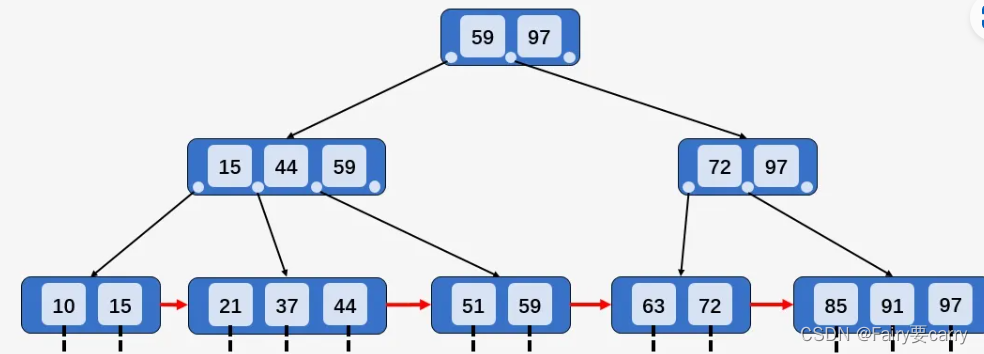
B+树中做插入关键字的操作,有以下 3 种情况:
1、 若被插入关键字所在的结点,其含有关键字数目小于阶数 M,则直接插入;
比如插入关键字 12 ,插入关键字所在的结点的 [10,15] 包含两个关键字,小于 M ,则直接插入关键字 12
2、 若被插入关键字所在的结点,其含有关键字数目等于阶数 M;
则需要将该结点分裂为两个结点,一个结点包含 ⌊M/2⌋ ,另一个结点包含 ⌈M/2⌉ 。同时,将⌈M/2⌉的关键字上移至其双亲结点。假设其双亲结点中包含的关键字个数小于 M,则插入操作完成。
插入关键字 95 ,插入关键字所在结点 [85、91、97] 包含 3 个关键字,等于阶数 M ,则将 [85、91、97] 分裂为两个结点 [85、91] 和结点 [97] , 关键字 95 插入到结点 [95、97] 中,并将关键字 91 上移至其双亲结点中,发现其双亲结点 [72、97] 中包含的关键字的个数 2 小于阶数 M ,插入操作完成
3、在第 2 情况中,如果上移操作导致其双亲结点中关键字个数大于 M,则应继续分裂其双亲结点。
插入关键字 40 ,按照第 2 种情况将结点分裂,并将关键字 37 上移到父结点,发现父结点 [15、37、44、59] 包含的关键字的个数大于 M ,所以将结点 [15、37、44、59] 分裂为两个结点 [15、37] 和结点 [44、59] ,并将关键字 37 上移到父结点中 [37、59、97] . 父结点包含关键字个数没有超过 M ,插入结束。
3.时间复杂度:
B+树插入删除时间复杂度为0(1)
搜索的时间复杂度为0(logn)
4.代码
package com.wyh.bootmath_java.Treap;
/**
* 实现B+树
*
* @param <T> 指定值类型
* @param <V> 使用泛型,指定索引类型,并且指定必须继承Comparable
*/
public class BPlusTree <T, V extends Comparable<V>>{
//B+树的阶
private Integer bTreeOrder;
//B+树的非叶子节点最小拥有的子节点数量(同时也是键的最小数量)
//private Integer minNUmber;
//B+树的非叶子节点最大拥有的节点数量(同时也是键的最大数量)
private Integer maxNumber;
private Node<T, V> root;
private LeafNode<T, V> left;
//无参构造方法,默认阶为3
public BPlusTree(){
this(3);
}
//有参构造方法,可以设定B+树的阶
public BPlusTree(Integer bTreeOrder){
this.bTreeOrder = bTreeOrder;
//this.minNUmber = (int) Math.ceil(1.0 * bTreeOrder / 2.0);
//因为插入节点过程中可能出现超过上限的情况,所以这里要加1
this.maxNumber = bTreeOrder + 1;
this.root = new LeafNode<T, V>();
this.left = null;
}
//查询
public T find(V key){
T t = this.root.find(key);
if(t == null){
System.out.println("不存在");
}
return t;
}
//插入
public void insert(T value, V key){
if(key == null)
return;
Node<T, V> t = this.root.insert(value, key);
if(t != null)
this.root = t;
this.left = (LeafNode<T, V>)this.root.refreshLeft();
// System.out.println("插入完成,当前根节点为:");
// for(int j = 0; j < this.root.number; j++) {
// System.out.print((V) this.root.keys[j] + " ");
// }
// System.out.println();
}
/**
* 节点父类,因为在B+树中,非叶子节点不用存储具体的数据,只需要把索引作为键就可以了
* 所以叶子节点和非叶子节点的类不太一样,但是又会公用一些方法,所以用Node类作为父类,
* 而且因为要互相调用一些公有方法,所以使用抽象类
*
* @param <T> 同BPlusTree
* @param <V>
*/
abstract class Node<T, V extends Comparable<V>>{
//父节点
protected Node<T, V> parent;
//子节点
protected Node<T, V>[] childs;
//键(子节点)数量
protected Integer number;
//键
protected Object keys[];
//构造方法
public Node(){
this.keys = new Object[maxNumber];
this.childs = new Node[maxNumber];
this.number = 0;
this.parent = null;
}
//查找
abstract T find(V key);
//插入
abstract Node<T, V> insert(T value, V key);
abstract LeafNode<T, V> refreshLeft();
}
/**
* 非叶节点类
* @param <T>
* @param <V>
*/
class BPlusNode <T, V extends Comparable<V>> extends Node<T, V>{
public BPlusNode() {
super();
}
/**
* 递归查找,这里只是为了确定值究竟在哪一块,真正的查找到叶子节点才会查
* @param key
* @return
*/
@Override
T find(V key) {
int i = 0;
while(i < this.number){
if(key.compareTo((V) this.keys[i]) <= 0)
break;
i++;
}
if(this.number == i)
return null;
return this.childs[i].find(key);
}
/**
* 递归插入,先把值插入到对应的叶子节点,最终讲调用叶子节点的插入类
* @param value
* @param key
*/
@Override
Node<T, V> insert(T value, V key) {
int i = 0;
while(i < this.number){
if(key.compareTo((V) this.keys[i]) < 0)
break;
i++;
}
if(key.compareTo((V) this.keys[this.number - 1]) >= 0) {
i--;
// if(this.childs[i].number + 1 <= bTreeOrder) {
// this.keys[this.number - 1] = key;
// }
}
// System.out.println("非叶子节点查找key: " + this.keys[i]);
return this.childs[i].insert(value, key);
}
@Override
LeafNode<T, V> refreshLeft() {
return this.childs[0].refreshLeft();
}
/**
* 当叶子节点插入成功完成分解时,递归地向父节点插入新的节点以保持平衡
* @param node1
* @param node2
* @param key
*/
Node<T, V> insertNode(Node<T, V> node1, Node<T, V> node2, V key){
// System.out.println("非叶子节点,插入key: " + node1.keys[node1.number - 1] + " " + node2.keys[node2.number - 1]);
V oldKey = null;
if(this.number > 0)
oldKey = (V) this.keys[this.number - 1];
//如果原有key为null,说明这个非节点是空的,直接放入两个节点即可
if(key == null || this.number <= 0){
// System.out.println("非叶子节点,插入key: " + node1.keys[node1.number - 1] + " " + node2.keys[node2.number - 1] + "直接插入");
this.keys[0] = node1.keys[node1.number - 1];
this.keys[1] = node2.keys[node2.number - 1];
this.childs[0] = node1;
this.childs[1] = node2;
this.number += 2;
return this;
}
//原有节点不为空,则应该先寻找原有节点的位置,然后将新的节点插入到原有节点中
int i = 0;
while(key.compareTo((V)this.keys[i]) != 0){
i++;
}
//左边节点的最大值可以直接插入,右边的要挪一挪再进行插入
this.keys[i] = node1.keys[node1.number - 1];
this.childs[i] = node1;
Object tempKeys[] = new Object[maxNumber];
Object tempChilds[] = new Node[maxNumber];
System.arraycopy(this.keys, 0, tempKeys, 0, i + 1);
System.arraycopy(this.childs, 0, tempChilds, 0, i + 1);
System.arraycopy(this.keys, i + 1, tempKeys, i + 2, this.number - i - 1);
System.arraycopy(this.childs, i + 1, tempChilds, i + 2, this.number - i - 1);
tempKeys[i + 1] = node2.keys[node2.number - 1];
tempChilds[i + 1] = node2;
this.number++;
//判断是否需要拆分
//如果不需要拆分,把数组复制回去,直接返回
if(this.number <= bTreeOrder){
System.arraycopy(tempKeys, 0, this.keys, 0, this.number);
System.arraycopy(tempChilds, 0, this.childs, 0, this.number);
// System.out.println("非叶子节点,插入key: " + node1.keys[node1.number - 1] + " " + node2.keys[node2.number - 1] + ", 不需要拆分");
return null;
}
// System.out.println("非叶子节点,插入key: " + node1.keys[node1.number - 1] + " " + node2.keys[node2.number - 1] + ",需要拆分");
//如果需要拆分,和拆叶子节点时类似,从中间拆开
Integer middle = this.number / 2;
//新建非叶子节点,作为拆分的右半部分
BPlusNode<T, V> tempNode = new BPlusNode<T, V>();
//非叶节点拆分后应该将其子节点的父节点指针更新为正确的指针
tempNode.number = this.number - middle;
tempNode.parent = this.parent;
//如果父节点为空,则新建一个非叶子节点作为父节点,并且让拆分成功的两个非叶子节点的指针指向父节点
if(this.parent == null) {
// System.out.println("非叶子节点,插入key: " + node1.keys[node1.number - 1] + " " + node2.keys[node2.number - 1] + ",新建父节点");
BPlusNode<T, V> tempBPlusNode = new BPlusNode<>();
tempNode.parent = tempBPlusNode;
this.parent = tempBPlusNode;
oldKey = null;
}
System.arraycopy(tempKeys, middle, tempNode.keys, 0, tempNode.number);
System.arraycopy(tempChilds, middle, tempNode.childs, 0, tempNode.number);
for(int j = 0; j < tempNode.number; j++){
tempNode.childs[j].parent = tempNode;
}
//让原有非叶子节点作为左边节点
this.number = middle;
this.keys = new Object[maxNumber];
this.childs = new Node[maxNumber];
System.arraycopy(tempKeys, 0, this.keys, 0, middle);
System.arraycopy(tempChilds, 0, this.childs, 0, middle);
//叶子节点拆分成功后,需要把新生成的节点插入父节点
BPlusNode<T, V> parentNode = (BPlusNode<T, V>)this.parent;
return parentNode.insertNode(this, tempNode, oldKey);
}
}
/**
* 叶节点类
* @param <T>
* @param <V>
*/
class LeafNode <T, V extends Comparable<V>> extends Node<T, V> {
protected Object values[];
protected LeafNode left;
protected LeafNode right;
public LeafNode(){
super();
this.values = new Object[maxNumber];
this.left = null;
this.right = null;
}
/**
* 进行查找,经典二分查找,不多加注释
* @param key
* @return
*/
@Override
T find(V key) {
if(this.number <=0)
return null;
// System.out.println("叶子节点查找");
Integer left = 0;
Integer right = this.number;
Integer middle = (left + right) / 2;
while(left < right){
V middleKey = (V) this.keys[middle];
if(key.compareTo(middleKey) == 0)
return (T) this.values[middle];
else if(key.compareTo(middleKey) < 0)
right = middle;
else
left = middle;
middle = (left + right) / 2;
}
return null;
}
/**
*
* @param value
* @param key
*/
@Override
Node<T, V> insert(T value, V key) {
// System.out.println("叶子节点,插入key: " + key);
//保存原始存在父节点的key值
V oldKey = null;
if(this.number > 0)
oldKey = (V) this.keys[this.number - 1];
//先插入数据
int i = 0;
while(i < this.number){
if(key.compareTo((V) this.keys[i]) < 0)
break;
i++;
}
//复制数组,完成添加
Object tempKeys[] = new Object[maxNumber];
Object tempValues[] = new Object[maxNumber];
System.arraycopy(this.keys, 0, tempKeys, 0, i);
System.arraycopy(this.values, 0, tempValues, 0, i);
System.arraycopy(this.keys, i, tempKeys, i + 1, this.number - i);
System.arraycopy(this.values, i, tempValues, i + 1, this.number - i);
tempKeys[i] = key;
tempValues[i] = value;
this.number++;
// System.out.println("插入完成,当前节点key为:");
// for(int j = 0; j < this.number; j++)
// System.out.print(tempKeys[j] + " ");
// System.out.println();
//判断是否需要拆分
//如果不需要拆分完成复制后直接返回
if(this.number <= bTreeOrder){
System.arraycopy(tempKeys, 0, this.keys, 0, this.number);
System.arraycopy(tempValues, 0, this.values, 0, this.number);
//有可能虽然没有节点分裂,但是实际上插入的值大于了原来的最大值,所以所有父节点的边界值都要进行更新
Node node = this;
while (node.parent != null){
V tempkey = (V)node.keys[node.number - 1];
if(tempkey.compareTo((V)node.parent.keys[node.parent.number - 1]) > 0){
node.parent.keys[node.parent.number - 1] = tempkey;
node = node.parent;
}
else {
break;
}
}
// System.out.println("叶子节点,插入key: " + key + ",不需要拆分");
return null;
}
// System.out.println("叶子节点,插入key: " + key + ",需要拆分");
//如果需要拆分,则从中间把节点拆分差不多的两部分
Integer middle = this.number / 2;
//新建叶子节点,作为拆分的右半部分
LeafNode<T, V> tempNode = new LeafNode<T, V>();
tempNode.number = this.number - middle;
tempNode.parent = this.parent;
//如果父节点为空,则新建一个非叶子节点作为父节点,并且让拆分成功的两个叶子节点的指针指向父节点
if(this.parent == null) {
// System.out.println("叶子节点,插入key: " + key + ",父节点为空 新建父节点");
BPlusNode<T, V> tempBPlusNode = new BPlusNode<>();
tempNode.parent = tempBPlusNode;
this.parent = tempBPlusNode;
oldKey = null;
}
System.arraycopy(tempKeys, middle, tempNode.keys, 0, tempNode.number);
System.arraycopy(tempValues, middle, tempNode.values, 0, tempNode.number);
//让原有叶子节点作为拆分的左半部分
this.number = middle;
this.keys = new Object[maxNumber];
this.values = new Object[maxNumber];
System.arraycopy(tempKeys, 0, this.keys, 0, middle);
System.arraycopy(tempValues, 0, this.values, 0, middle);
this.right = tempNode;
tempNode.left = this;
//叶子节点拆分成功后,需要把新生成的节点插入父节点
BPlusNode<T, V> parentNode = (BPlusNode<T, V>)this.parent;
return parentNode.insertNode(this, tempNode, oldKey);
}
@Override
LeafNode<T, V> refreshLeft() {
if(this.number <= 0)
return null;
return this;
}
}
}
智能推荐
linux网络配置后面加一条wheel,linux安全配置/etc/sudoers&wheel组-程序员宅基地
文章浏览阅读800次。/etc/sudoers 控制哪些用户能在哪些主机上以哪些用户的身份执行哪些命令。只有此文件权限为440时才能用户才能使用sudo命令,只有root用户才能使用visudo命令修改此文件。当然也可以先添加文件写权限,然后修改,再把文件权限改回来。此文件的一些配置规则定义别名:User_Alias UserName = user1,user2,kongoveHost_Alias HostName =..._%wheel all=(all) all
NO.15——使用Appium自动化测试爬取微信朋友圈数据_appium监测微信图片-程序员宅基地
文章浏览阅读9.7k次,点赞5次,收藏27次。 一、解析过程本人使用锤子手机做测试,型号是YQ601,首先打开开发者模式确保手机能与mac相连,打开Appium客户端,配置参数如图可以理解为Appuim继承自web端的selenium,同样可以执行一些自动化操作。Appium自带了一个XPATH选择器,给用户提供了选择结果,如图这个选择器给出的结果太繁琐,所以可以改成通过查找ID的方式来构造爬虫程序。但是这里要注意,估计微信提升了自己..._appium监测微信图片
Spring boot注入静态变量_springboot注入静态变量-程序员宅基地
文章浏览阅读498次。给静态变量赋值_springboot注入静态变量
WPF分页控件-程序员宅基地
文章浏览阅读154次。1.XML<UserControl x:Class="MahAppsMetro.Demo.Views.DataPager" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com..._mahapps控件库写分页控件
AndFix注意事项-程序员宅基地
文章浏览阅读64次。1、生成补丁,修改前后的apk包都必须签名。2、AndFix 不支持修改布局文件。3、文件的路径必须正确。4、AndFix 不支持添加匿名内部类(就是点击事件)。5、AndFix 不支持添加新的类。6、AndFix 支持连续打补丁(注意补丁的名字要求不一样)。转载于:https://www.cnblogs.com/Jackie-zhang/p/10162430.html..._阿里andfix增加内部类
qpushbutton添加menu时不显示三角下表_如何看待奶粉中添加的香精香料?不同人群这样说...-程序员宅基地
文章浏览阅读115次。婴幼儿配方奶粉是作为宝宝在无法母乳喂养时的无奈选择,也是除母乳以外最好的选择,宝妈在选择奶粉时也会格外认真,当看到奶粉中含有香精香料成分时,部分宝妈便不会购买,甚至认为此类成分是对宝宝身体有所危害的,所以坚决抵制购买,那么添加到奶粉中的香精香料到底怎么样,长期吃有没有坏处?我们来看看吧~不同人群,对香精香料有不同看法"宝妈们这样说:前段时间网上一位宝妈的评论吸引了笔者的注意:“我这奶粉买回家一开罐...
随便推点
数码管扫描显示verilog_如何开始Xilinx FPGA开发之旅 第二课 EGO1数码管与键盘-程序员宅基地
文章浏览阅读1.4k次。庚子年,我们的EGO1在疫情当中作为口袋实验平台成为了众多高校的复课利器。其中的成功案例更是得到了新华社网媒与CCTV教育频道的报道。借此东风,为了让更多的老师与学生熟悉了解Xilinx,更好的入门学习FPGA知识,我们的师资培训直播已开设EGO1专题直播,欢迎新老朋友跟踪关注。第二课---- EGO1数码管与键盘本周的直播我们将介绍EGO1的外设使用案例,介绍数码管扫描的原理和PS/2..._fpgaego1 键盘
python re库安装_python 库安装方法及常用库-程序员宅基地
文章浏览阅读3.6k次。python库安装方法:方法一:setpu.py1.下载库压缩包,解压,记录下路径:*:/**/……/2.运行cmd,切换到*:/**/……/目录下3.运行setup.py build4.然后输入python,进入python模块,验证是否安装成功方法二:1.Win + R 打开运行窗口,输入cmd回车2.找到pip安装路径——x:\Python xx\Scripts3. 在命令行中切换至该目录c..._rep库怎么安装
android listview fling,ListView优化: Fling(松开滑动) 过程中不加载数据-程序员宅基地
文章浏览阅读189次。1.Adapter增加滑动结束以后刷新方法//定义当前listview是否在滑动状态private boolean isScrolling = false;public void setScrolling(boolean scrolling) {this.isScrolling = scrolling;}public void refreshOnScrollEnd(AdapterView list..._android listview fling
微信公众号JSAPI自费支付总结_微信自动续费api-程序员宅基地
文章浏览阅读535次。文章目录前言一、准备操作1.公众号ID2.商户号3.商户号密钥4.域名、服务器二、步入正题1. 支付流程2. 初始化订单数据2.读入数据总结前言本编章主要是通过运行一个自费测试demo使其能够快速了解微信自费支付的实现流程,也是个人实现微信自费demo之后的记录、总结官方文档:https://pay.weixin.qq.com/wiki/doc/api/jsapi.php?chapter=9_1一、准备操作进行微信自费支付之前请先获得以下几项必要条件,公众号和商户号需要绑定名称_微信自动续费api
java byte 字节负数-程序员宅基地
文章浏览阅读2w次。由于通讯协议中长度使用byte字节来表示,但在java中长度超过127的时候会变成负数,所以需要保证得到的长度是正数byte b & 0xFFhttp://www.blogjava.net/orangelizq/archive/2008/07/20/216228.html在剖析该问题前请看如下代码public static String bytes2HexString(
Ubuntu18.04安装教程——超详细的图文教程_ubuntu系统18.04-程序员宅基地
文章浏览阅读10w+次,点赞112次,收藏974次。Ubuntu18.04镜像_ubuntu系统18.04