【笔记】SemGCN-程序员宅基地
一. 论文总结
1.1 核心贡献
- 提出了一种改进的图卷积操作,称为语义图卷积(SemGConv),它源自cnn。其关键思想是学习图中暗示的边的信道权值,然后将它们与核矩阵结合起来。这大大提高了图卷积的能力。
- 其次,我们引入了SemGCN,其中SemGConv层与非局部[65]层交叉。该体系结构捕获节点之间的本地和全局关系。
- 第三,我们提出了一个端到端学习框架,以表明SemGCN还可以合并外部信息,如图像内容,以进一步提高3D人体姿态回归的性能。
1.2 语义图卷积(SemGConv)
1.2.1 ResGCN
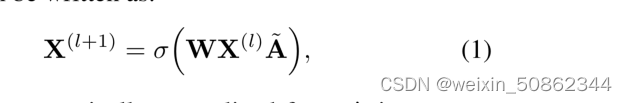
∈
和
∈
分别是节点i在第l个卷积之前和之后的表示。
- 可学习参数矩阵W∈
- 其中
是在常规GCNs中对A进行对称归一化。A∈
是G的邻接矩阵,对于节点j∈N (i)有
= 1,
= 1
两个明显的缺点:
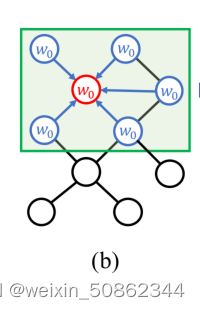
- 首先,为了使图卷积在具有任意拓扑结构的节点上工作,所有边共享学习的核矩阵W。结果,相邻节点的关系或图中的内部结构,不能很好地利用。
- 其次,之前的工作只收集每个节点的第一个序列上的(应该是最近邻的意思)邻居的特征。因为接受野被固定为1,这也是存在不足的。
1.2.2 SemGConv
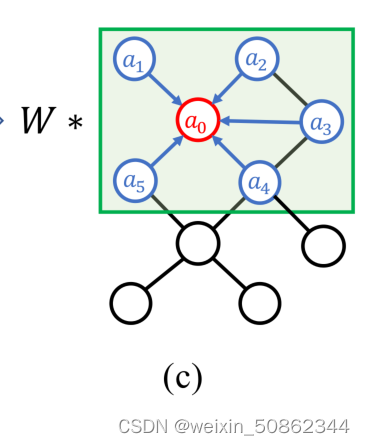
在传统的图卷积中添加了一个可学习的权重矩阵M∈(按我的理解就是上图中的
)。然后转化为:
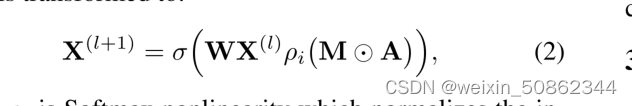
- 其中
是Softmax非线性,它在节点
的所有选择上归一化输入矩阵;
- ⊙是一个元素级运算,如果
- A作为一个掩码,它迫使图中的节点i,我们只计算其相邻节点j∈N (i)的权值。
学习每一个通道的加权权重,将公式进一步扩展:
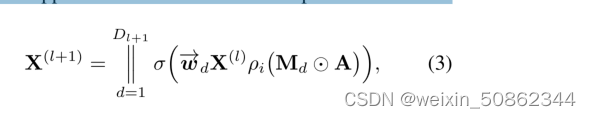
- 其中 || 表示对所有层的输入进行拼接,
是变换矩阵w的第d行。
1.3 网络架构
整体结构
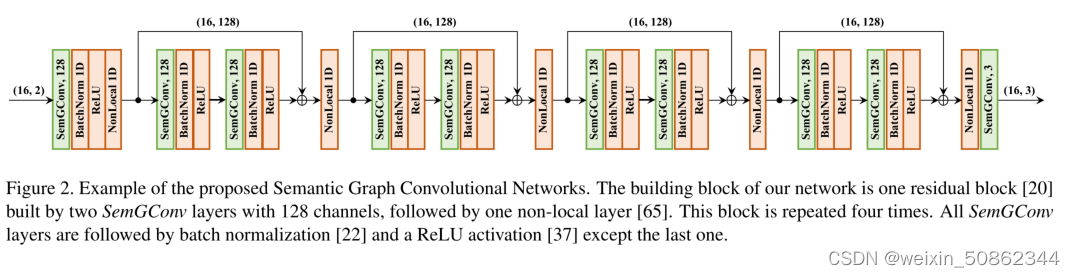
SemGCN网络架构是通过SemGConv和 Non-Local层交错以捕获节点的局部和全局语义关系
Non-Local来自2018年cvpr论文Non-local Neural Networks
(翻译和解析后面会更新)
1.3.1 基本结构
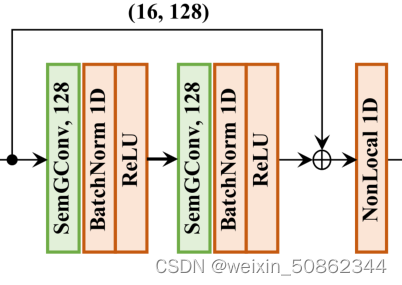
在这项工作中,所有块中的SemGCN具有相同的结构,由两个具有128通道的SemGConv层构建的一个残差块[20]组成,然后再跟随一个非本地层。
二.代码实现
2.1 生成 邻接矩阵
adj = adj_mx_from_skeleton(dataset.skeleton())#建立对称邻接矩阵以human36M为例:
dataset.skeleton()返回的就是
h36m_skeleton = Skeleton(parents=[-1,
0, 1, 2, 3, 4,
0, 6, 7, 8, 9,
0, 11, 12, 13, 14, 12,
16, 17, 18, 19, 20, 19, 22, 12, 24, 25, 26, 27, 28, 27, 30],
joints_left=[6, 7, 8, 9, 10, 16, 17, 18, 19, 20, 21, 22, 23],
joints_right=[1, 2, 3, 4, 5, 24, 25, 26, 27, 28, 29, 30, 31])具体来看一下adj_mx_from_skeleton这个生成邻接矩阵的函数:
from __future__ import absolute_import
import torch
import numpy as np
import scipy.sparse as sp
def normalize(mx):
"""Row-normalize sparse matrix"""
rowsum = np.array(mx.sum(1))
r_inv = np.power(rowsum, -1).flatten()
r_inv[np.isinf(r_inv)] = 0.
r_mat_inv = sp.diags(r_inv)
mx = r_mat_inv.dot(mx)
return mx
def sparse_mx_to_torch_sparse_tensor(sparse_mx):
"""将scipy稀疏矩阵转换为torch稀疏张量。Convert a scipy sparse matrix to a torch sparse tensor."""
sparse_mx = sparse_mx.tocoo().astype(np.float32)
indices = torch.from_numpy(np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))
values = torch.from_numpy(sparse_mx.data)
shape = torch.Size(sparse_mx.shape)
return torch.sparse.FloatTensor(indices, values, shape)
def adj_mx_from_edges(num_pts, edges, sparse=True):
edges = np.array(edges, dtype=np.int32)
data, i, j = np.ones(edges.shape[0]), edges[:, 0], edges[:, 1]
adj_mx = sp.coo_matrix((data, (i, j)), shape=(num_pts, num_pts), dtype=np.float32)
#sp.coo_matrix() 的作用是生成矩阵
#sp.coo_matrix((data, (row, col)), shape=(4, 4))用指定数据生成矩阵
# 建立对称邻接矩阵 build symmetric adjacency matrix
adj_mx = adj_mx + adj_mx.T.multiply(adj_mx.T > adj_mx) - adj_mx.multiply(adj_mx.T > adj_mx)
adj_mx = normalize(adj_mx + sp.eye(adj_mx.shape[0]))
if sparse:
adj_mx = sparse_mx_to_torch_sparse_tensor(adj_mx)
else:
adj_mx = torch.tensor(adj_mx.todense(), dtype=torch.float)
return adj_mx
def adj_mx_from_skeleton(skeleton):
num_joints = skeleton.num_joints()
edges = list(filter(lambda x: x[1] >= 0, zip(list(range(0, num_joints)), skeleton.parents())))
#盆骨父节点为-1
return adj_mx_from_edges(num_joints, edges, sparse=False)
2.2 SemGCN
2.2.1 SemGraphConv
class SemGraphConv(nn.Module):
"""
Semantic graph convolution layer
"""
def __init__(self, in_features, out_features, adj, bias=True):
super(SemGraphConv, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.W = nn.Parameter(torch.zeros(size=(2, in_features, out_features), dtype=torch.float))
#作为nn.Module中的可训练参数使用,与torch.Tensor的区别就是nn.Parameter会自动被认为是module的可训练参数
nn.init.xavier_uniform_(self.W.data, gain=1.414)
self.adj = adj#邻接矩阵
self.m = (self.adj > 0)
self.e = nn.Parameter(torch.zeros(1, len(self.m.nonzero()), dtype=torch.float))
nn.init.constant_(self.e.data, 1)
if bias:
self.bias = nn.Parameter(torch.zeros(out_features, dtype=torch.float))
stdv = 1. / math.sqrt(self.W.size(2))
self.bias.data.uniform_(-stdv, stdv)
else:
self.register_parameter('bias', None)
def forward(self, input):
h0 = torch.matmul(input, self.W[0])
h1 = torch.matmul(input, self.W[1])
adj = -9e15 * torch.ones_like(self.adj).to(input.device)
adj[self.m] = self.e
adj = F.softmax(adj, dim=1)
M = torch.eye(adj.size(0), dtype=torch.float).to(input.device)
output = torch.matmul(adj * M, h0) + torch.matmul(adj * (1 - M), h1)
if self.bias is not None:
return output + self.bias.view(1, 1, -1)
else:
return output
def __repr__(self):
return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')'
2.2.2 GraphNonLocal
from __future__ import absolute_import, division
import torch
from torch import nn
class _NonLocalBlock(nn.Module):
def __init__(self, in_channels, inter_channels=None, dimension=3, sub_sample=1, bn_layer=True):
super(_NonLocalBlock, self).__init__()
assert dimension in [1, 2, 3]
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
assert self.inter_channels > 0
if dimension == 3:
conv_nd = nn.Conv3d
max_pool = nn.MaxPool3d
bn = nn.BatchNorm3d
elif dimension == 2:
conv_nd = nn.Conv2d
max_pool = nn.MaxPool2d
bn = nn.BatchNorm2d
elif dimension == 1:
conv_nd = nn.Conv1d
max_pool = nn.MaxPool1d
bn = nn.BatchNorm1d
else:
raise Exception('Error feature dimension.')
self.g = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
self.theta = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
self.phi = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
self.concat_project = nn.Sequential(
nn.Conv2d(self.inter_channels * 2, 1, 1, 1, 0, bias=False),
nn.ReLU()
)
nn.init.kaiming_normal_(self.concat_project[0].weight)
nn.init.kaiming_normal_(self.g.weight)
nn.init.constant_(self.g.bias, 0)
nn.init.kaiming_normal_(self.theta.weight)
nn.init.constant_(self.theta.bias, 0)
nn.init.kaiming_normal_(self.phi.weight)
nn.init.constant_(self.phi.bias, 0)
if bn_layer:
self.W = nn.Sequential(
conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0),
bn(self.in_channels)
)
nn.init.kaiming_normal_(self.W[0].weight)
nn.init.constant_(self.W[0].bias, 0)
nn.init.constant_(self.W[1].weight, 0)
nn.init.constant_(self.W[1].bias, 0)
else:
self.W = conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0)
nn.init.constant_(self.W.weight, 0)
nn.init.constant_(self.W.bias, 0)
if sub_sample > 1:
self.g = nn.Sequential(self.g, max_pool(kernel_size=sub_sample))
self.phi = nn.Sequential(self.phi, max_pool(kernel_size=sub_sample))
def forward(self, x):
batch_size = x.size(0) # x: (b, c, t, h, w)
g_x = self.g(x).view(batch_size, self.inter_channels, -1)
g_x = g_x.permute(0, 2, 1)
# (b, c, N, 1)
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1, 1)
# (b, c, 1, N)
phi_x = self.phi(x).view(batch_size, self.inter_channels, 1, -1)
h = theta_x.size(2)
w = phi_x.size(3)
theta_x = theta_x.expand(-1, -1, -1, w)
phi_x = phi_x.expand(-1, -1, h, -1)
concat_feature = torch.cat([theta_x, phi_x], dim=1)
f = self.concat_project(concat_feature)
b, _, h, w = f.size()
f = f.view(b, h, w)
N = f.size(-1)
f_div_C = f / N
y = torch.matmul(f_div_C, g_x)
y = y.permute(0, 2, 1).contiguous()
y = y.view(batch_size, self.inter_channels, *x.size()[2:])
W_y = self.W(y)
z = W_y + x
return z
class GraphNonLocal(_NonLocalBlock):
def __init__(self, in_channels, inter_channels=None, sub_sample=1, bn_layer=True):
super(GraphNonLocal, self).__init__(in_channels, inter_channels=inter_channels, dimension=1,
sub_sample=sub_sample, bn_layer=bn_layer)
2.2.3 ResGraphConv
表示的是如下这个部分:
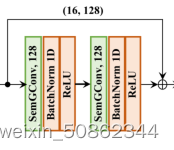
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf