论文阅读【自然语言处理-预训练模型】XML:Crosslingual language model pretraining_跨语言预训练模型由 clm 与 mlm 或 mlm 与 tlm 结合的模型组成-程序员宅基地
技术标签: 论文阅读 语言模型 xml 人工智能 自然语言处理
Crosslingual language model pretraining
【论文链接】:https://arxiv.org/abs/1901.07291
【代码链接】:https://github.com/facebookresearch/XLM
【来源】:由 Guillaume Lample 和 Alexis Conneau 等人于2019年提出的,他们是 Facebook AI Research (FAIR) 的研究员。
XLM模型代表了一种强大而灵活的方法,用于训练神经网络模型来理解和生成多语言的自然语言文本,并有可能在多语言环境中实现更有效和高效的自然语言处理。
XLM:多语⾔预训练起点
随着BERT、GPT预训练语⾔模型的兴起,这些⽅法也被⾃然⽽然的⽤在了多语⾔预训练任务上。通过在 BERT、GPT等成熟的NLP模型结构上同时学习多个语⾔的语料,并设计多语⾔对⻬任务,实现了 Multilingual预训练语⾔模型,应⽤到下游各种语⾔的任务中。
Facebook在Crosslingual language model pretraining(NIPS 2019)⼀⽂中提出XLM预训练多语⾔模型,整体思路基于BERT,并提出了针对多语⾔预训练的3个优化任务。后续很多多语⾔预训练⼯作都建⽴在XLM的基础上,我们来详细看看XLM的整体训练过程。
-
⾸先,需要构造⼀个多语⾔的vocabulary list。XLM让所有语⾔共⽤同⼀个词表,**利⽤Byte Pair Encoding (BPE)的⽅法从所有语⾔中采样⽂本构造词典。为了提升low-resource语⾔采样⽐例,缓解预训练模型偏向high-resource语⾔,在采样过程中会对各个语⾔采样⽐例做⼀定的矫正。**通过多种语⾔共⽤⼀个BPE词表的⽅法,便于不同语⾔的token embedding在隐空间对⻬,也能提取到不同语⾔共⽤的token。
-
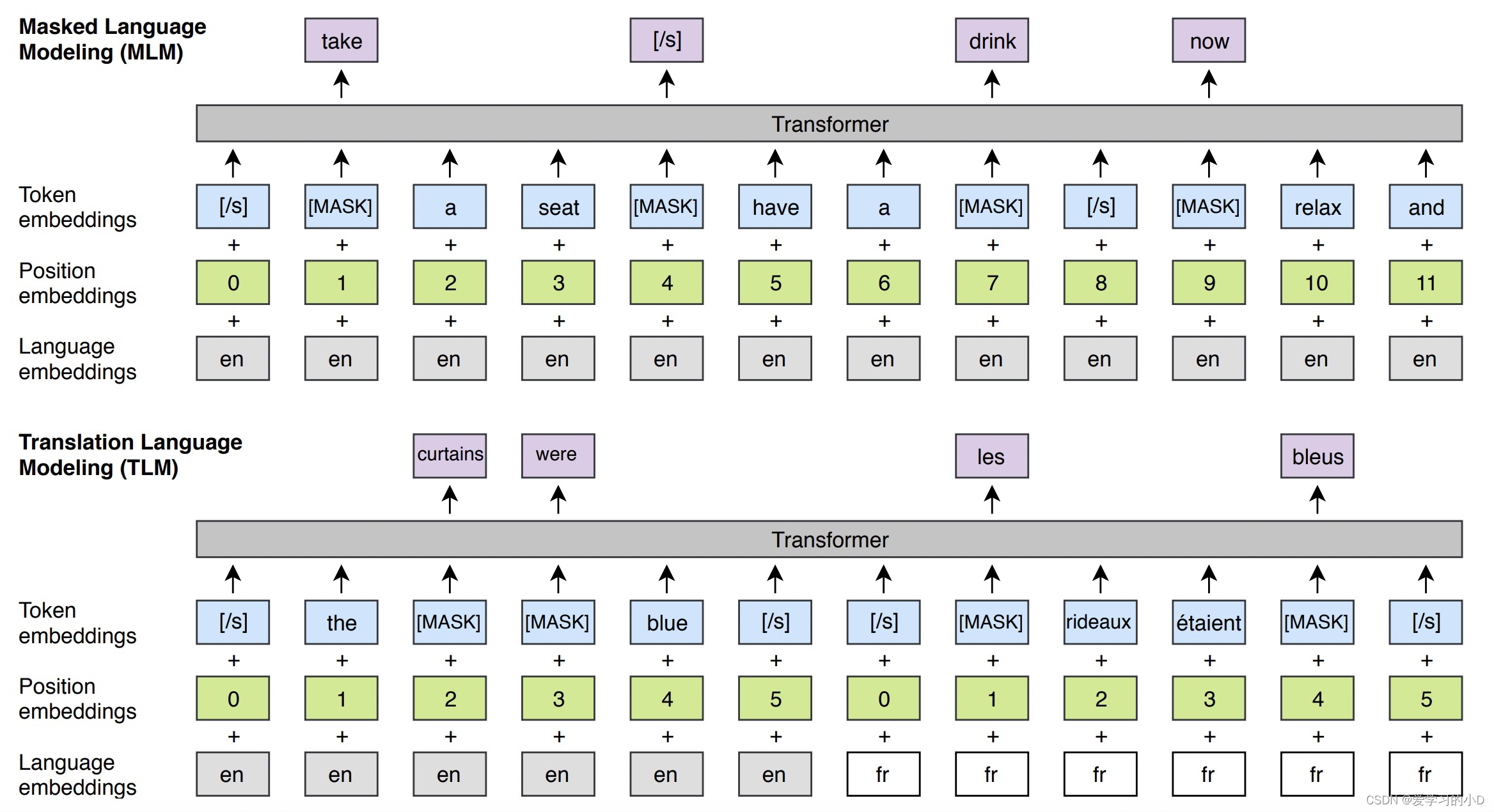
模型预训练主要包括两个任务,分别是MLM和TLM。
- 其中MLM和BERT中采⽤的⽅式类似,mask部分token进⾏预测。
- TLM是Translation Language Model,这个任务为了引⼊多语⾔的对⻬关系,将两种语⾔的⽂本拼接到⼀起采⽤mask token的⽅式预测。这样在预测过程中,既可以根据本语⾔的信息预测,
也可以根据另⼀种语⾔的信息预测。此外,XLM引⼊了language embedding,⽤来标明每个位置上的token属于哪个语⾔。XLM的两个预训练任务如下图所示。
1.论文解析
跨语言语言模型预训练(XLM)是一种自然语言处理技术,即在大量的多语言文本数据上预训练神经网络模型,以提高其理解和生成多语言的能力。XLM是在2019年Facebook AI的一篇研究论文中首次提出的。
XLM方法建立在语言建模预训练的成功基础上,预训练涉及训练神经网络,以预测一个句子中的下一个单词,给定的是以前的单词。XLM背后的想法是将这种方法扩展到多种语言,使用一个可以针对特定语言进行微调的共享模型。
为了预训练XLM模型,使用了大量的多语言文本数据。该模型被训练来预测一个句子中的下一个词,给定一个支持的语言中的前一个词的序列。XLM模型结合使用各种技术,如屏蔽语言建模、翻译语言建模和语言ID预测,以提高其理解和生成多语言文本的能力。
一旦XLM模型经过预训练,它就可以针对特定的语言任务进行微调,如机器翻译、命名实体识别和情感分析。微调包括在较少的特定任务数据上训练XLM模型,以使其适应特定语言或任务的细微差别。
XLM已被证明在提高语言模型的跨语言性能方面非常有效,并已被用于各种自然语言处理任务,包括机器翻译、跨语言文本分类和零点跨语言转移。
(1)主要贡献
跨语言模型预训练(XLM)对自然语言处理(NLP)领域做出了多项重大贡献:
-
改进了跨语言转移学习: XLM改善了语言模型在跨语言迁移学习任务中的表现。通过对多语言文本数据进行预训练,XLM可以学习理解和生成跨语言的语言,从而更好地从一种语言转移学习到另一种语言。
-
对低资源语言有更好的支持: XLM还提高了语言模型支持低资源语言的能力。通过对大量的多语言文本数据进行预训练,XLM可以学习以一种对不同语言的数据可用性变化更加稳健的方式来表示语言。
-
启用零距离的跨语言转移: XLM已经实现了零次跨语言转换,这意味着一个模型可以在一种语言上进行训练,然后用于另一种语言的预测,而无需任何额外的训练数据。这有可能大大减少支持多语言应用所需的数据量。
启用零点跨语言转换意味着语言模型可以在没有明确训练的语言中进行预测,而无需任何额外的训练数据。这是通过在大量的多语言文本数据上对模型进行预训练来实现的,这使它能够学会理解和生成多语言的语言。
例如,如果一个语言模型是在英语文本数据上训练的,然后被用来生成西班牙语文本,它可以不需要在西班牙语数据上做任何额外的训练。该模型可以利用其学到的语言表征来理解和生成新语言的文本,即使它在训练期间没有接触过这种语言。
实现零距离跨语言转换对多语言应用有重大意义,因为它减少了对每种语言的单独训练数据和模型的需求。这可以大大降低多语言NLP系统的计算成本和数据要求,并可以使其更容易在训练数据稀缺或不可用的语言中部署模型。
-
多语言机器翻译方面的进展: XLM也推动了多语言机器翻译的发展,因为它可以使用一个单一的模型在多种语言之间进行翻译。这有可能降低多语言翻译系统的计算成本和数据要求。
总的来说,XLM为开发更有效和高效的跨语言NLP方法做出了贡献,对改善跨语言的语言理解和生成具有意义。
(2)论文的思想是什么?
- 跨语言语言模型预训练(XLM)论文提出了一种训练神经网络模型的方法,以理解和生成跨多种语言的自然语言文本。XLM方法是基于转化器架构,它使用自我注意机制来捕捉自然语言文本中的长距离依赖关系。
- XLM的主要思想是学习一种可应用于多种语言的共享语言表征,使一个模型能够更有效地将知识从一种语言转移到另一种语言。
(3)论文的方法是什么?
-
XLM方法涉及到在大量的多语言文本数据上预训练一个神经网络模型,使用的任务组合包括遮蔽语言建模、翻译语言建模和语言ID预测。在预训练过程中,该模型学习预测一个句子中的下一个词,而这个词是来自支持的语言之一的前一个词的序列。
-
XLM方法旨在学习一种适用于多种语言的语言共享表示。为了实现这一目标,该模型同时在多种语言的文本数据上进行训练,并对模型的参数进行优化,以使损失函数最小化,该损失函数反映了该模型在序列中预测下一个单词的能力如何。
-
一旦XLM模型在多语言文本数据上进行了预训练,它就可以在特定的任务上进行微调,如情感分析或机器翻译。在微调过程中,该模型在特定的任务数据上进行训练,以进一步完善在预训练期间学到的语言共享表示。
-
XLM方法还包括对转换器结构的一些修改,以提高其对多语言文本数据的性能。例如,XLM使用跨语言关注机制,使模型能够关注不同语言的单词和短语。
总的来说,XLM论文提出了一种训练神经网络模型以理解和生成多语言文本的综合方法,推动了多语言自然语言处理领域的先进水平。
(4)methodology是什么?
跨语言模型预训练(XLM)论文的方法可以概括为以下几点:
-
数据收集和准备: XLM的作者从各种来源收集了大量的多语言文本数据,包括维基百科、新闻文章和网页。然后,他们对数据进行了预处理,以去除噪音,对文本进行标记,并将其分割成句子。
-
模型架构: XLM模型是基于transformer架构,它使用自我注意机制来捕捉自然语言文本中的长距离依赖关系。XLM模型包括对transformer架构的一些修改,以提高其对多语言文本数据的性能,如跨语言的关注机制。
-
预训练: XLM模型在多语言文本数据上进行预训练,使用的任务组合包括屏蔽语言建模、翻译语言建模和语言ID预测。在预训练过程中,该模型学习预测一个句子中的下一个单词,这些单词来自支持的语言之一的前一个序列。预训练过程旨在学习一种适用于多种语言的共享语言表示。
-
微调: 一旦XLM模型在多语言文本数据上进行了预训练,它就可以在特定的任务上进行微调,例如情感分析或机器翻译。在微调过程中,该模型在特定的任务数据上进行训练,以进一步完善在预训练期间学到的语言共享表征。
-
评估: XLM的作者在几个基准数据集上评估了该模型的性能,包括跨语言的自然语言推理和跨语言的句子检索。他们还通过训练一个模型在多种语言之间进行翻译,证明了XLM在机器翻译方面的有效性。
总的来说,XLM论文的方法代表了一种训练神经网络模型以理解和生成多语言自然语言文本的综合方法,它推动了多语言自然语言处理的最新进展。
(5)创新点
跨语言语言模型预训练(XLM)论文提出了对转换器架构的若干创新修改,以提高其对多语言文本数据的性能。该论文的一些主要创新和贡献包括:
- 跨语言的关注机制: XLM模型包括跨语言关注机制,使其能够关注不同语言的单词和短语,从而促进跨语言共享语言结构的学习。
- 跨语言的共享词汇: XLM模型在所有支持的语言中使用一个共享词汇,这使它能够处理代码转换和其他形式的语言混合。这种方法有可能提高该模型处理多语言文本数据的能力,并促进跨语言的迁移学习。
- 对多个任务进行预训练: XLM模型在大量的多语言文本数据上进行预训练,使用的任务组合包括屏蔽语言建模、翻译语言建模和语言ID预测。这种多任务预训练方法使该模型能够学习到一种更稳健和可概括的语言表征,适用于多种语言。
- 零起点的跨语言转移: XLM模型在一系列跨语言自然语言处理任务中表现出最先进的性能,包括机器翻译、跨语言文档分类和命名实体识别。这一性能是在没有任何特定任务微调的情况下实现的,这证明了XLM模型在实现零距离跨语言转移方面的有效性。
总的来说,XLM论文对转换器的结构提出了几个创新的修改,并引入了一个强大的预训练方法,以便在多语言环境中实现有效和高效的自然语言处理。
(6)应用
跨语言语言模型预训练(XLM)论文在多语言环境的自然语言处理(NLP)中有着广泛的潜在应用。XLM模型的一些关键应用包括:
- 跨语言文件分类: XLM模型可以用来对用不同语言编写的文件进行分类,而不需要特定语言的训练数据或模型。这在文件以多种语言书写的情况下特别有用,例如在跨国公司或国际组织。
- 机器翻译: XLM模型可以在机器翻译任务中进行微调,以实现语言之间的跨语言翻译。该模型在一些机器翻译基准上表现出最先进的性能,包括WMT’16英德翻译任务和WMT’16英罗尼亚翻译任务。
- 命名实体识别: XLM模型可用于跨语言的命名实体识别,这涉及到识别和分类实体,如用多种语言编写的文本中的人、组织和地点。
- 多语言聊天机器人和虚拟助理: XLM模型可用于开发聊天机器人和虚拟助手,它们可以理解和生成多种语言的自然语言文本,而不需要特定语言的训练数据或模型。
总的来说,XLM模型有可能在多语言环境中实现更有效和高效的自然语言处理,并可应用于涉及多语言文本数据的广泛的NLP任务。
(7)局限性
虽然跨语言模型预训练(XLM)论文为多语言自然语言处理提出了一个强大的方法,但该模型有几个局限性,应予以考虑:
- 语言的覆盖面有限: 虽然XLM模型支持广泛的语言,但与世界上的语言总数相比,其覆盖范围仍然有限。这可能会限制它在一些涉及不常用语言的应用中的效用。
- 预训练和微调要求: XLM模型需要在大量的多语言文本数据上进行大量的预训练,以及在特定任务数据上进行微调。这在计算上是很昂贵和耗时的,而且可能需要使用大规模的计算资源。
- 特定任务的限制: XLM模型可能无法针对某些特定任务的应用进行优化,例如那些涉及特定领域语言或专门词汇的应用。在这种情况下,特定任务的模型可能更有效。
- 缺少可解释性: XLM模型是一个复杂的神经网络,很难解释,这使得理解模型如何做出决定以及调试错误或问题变得很有挑战性。
总的来说,虽然XLM模型是一种强大的多语言自然语言处理方法,但在将其应用于特定任务或应用时,应考虑到其局限性。
XLM与Bert的区别
XLM(跨语言语言模型)和BERT(来自变换器的双向编码器表示法)模型都是强大的自然语言处理模型,但它们之间有一些关键的区别:
- 多语言与单语言:XLM和BERT的主要区别之一是XLM是一个多语言模型,而BERT是一个单语言模型。XLM同时在多种语言上进行训练,而BERT则在单一语言上进行训练,通常是英语。
- 跨语言转移学习: XLM的设计是为了促进跨语言迁移学习,也就是说,它可以学习多种语言的文本表征,并利用这些知识来提高这些语言的特定任务的性能。另一方面,BERT通常在单一语言的特定任务上进行微调,其性能可能不能很好地推广到其他语言。
- 不同的预训练目标: XLM和BERT使用的预训练目标也不同。XLM使用遮蔽语言建模和翻译语言建模的组合,而BERT使用遮蔽语言建模和下句预测。
- 模型架构: 虽然XLM和BERT都是基于Transformer架构,但它们的具体模型架构有一些区别。例如,XLM包括一个特定语言的嵌入层以区分不同的语言,而BERT则没有。
总的来说,XLM是专门为多语言自然语言处理任务而设计的,而BERT更常用于英语的单语言任务。然而,这两种模型都在广泛的NLP任务中表现出令人印象深刻的性能。
如何实现多语言训练的
- XLM(跨语言语言模型预训练)通过使用两个预训练目标的组合来实现多语言训练:屏蔽语言模型(MLM)和翻译语言模型(TLM)。
- 在MLM中,模型被训练为根据周围的语境来预测一个句子中的随机屏蔽标记。XLM通过在一个训练批次中掩盖不同语言的标记,将这一目标扩展到多种语言。
- 在TLM中,模型被训练成在给定的语言中预测下一个句子,而当前的句子是另一种语言。这个目标被用来鼓励模型学习跨语言的表征,这些表征可用于语言间的迁移学习。
- 为了使模型能够处理多种语言,XLM在输入标记嵌入中加入了语言嵌入,这使得模型能够区分不同的语言。此外,XLM在所有语言中使用一个共享的Transformer架构,这样可以有效地共享参数并提高跨语言的性能。
- XLM是在一个大规模的多语言语料库上训练的,其中包括来自不同语言的平行数据以及单语数据。这使得该模型能够学习语言内和语言间的单词和短语之间的关系,这使得它能够在广泛的多语言任务中表现良好。
XLM的输入输出是什么
XLM(跨语言模型预训练)的输入和输出取决于它被用于的具体任务。
-
在预训练阶段,XLM的输入是一串来自一种或多种语言的标记。每个标记被表示为一个学习的嵌入向量,其中包括一个语言嵌入以表示该标记的语言。该序列通过一个多层转化器架构,该架构在所有语言中都是共享的,并用于预测该序列中的屏蔽标记(MLM目标)和下一句话(TLM目标)。
-
在微调阶段,XLM的输入取决于具体的下游任务。例如,在多语言情感分类任务中,输入可能是一个或多个语言的文本序列,而输出可能是一个二进制情感标签。微调阶段通常包括在预训练的XLM模型上添加额外的特定任务层,并对特定任务的所有参数进行微调。
总的来说,XLM模型是为处理多语言输入和输出而设计的,它的结构为学习跨语言表征而优化,可用于不同语言的广泛下游任务。
2. 代码实现举例
这段代码使用transformers库加载XLM模型和标记器,对英语和法语的样本输入序列进行标记,将序列填充到相同的长度,并通过XLM模型进行前向传递,得到最终的隐藏状态和集合输出。输出的形状被打印出来,以供验证。请注意,这只是一个例子,XLM模型可以用于标记化和编码之外的各种下游任务。
import torch
from transformers import XLMModel, XLMTokenizer
# Define the XLM model architecture and tokenizer
model = XLMModel.from_pretrained('xlm-mlm-en-2048')
tokenizer = XLMTokenizer.from_pretrained('xlm-mlm-en-2048')
# Define a sample input sequence in English and French
input_text = ["Hello, world!", "Bonjour, le monde!"]
# Tokenize the input sequence into subwords
input_ids = [tokenizer.encode(text) for text in input_text]
# Pad the input sequences to the same length
max_length = max(len(ids) for ids in input_ids)
input_ids = [ids + [0]*(max_length - len(ids)) for ids in input_ids]
# Convert the input sequences to PyTorch tensors
input_ids = torch.tensor(input_ids)
# Forward pass through the XLM model
outputs = model(input_ids)
# Get the final hidden states and pooled output
hidden_states = outputs.last_hidden_state
pooled_output = outputs.pooler_output
# Print the output shape
print(hidden_states.shape) # (2, max_length, 2048)
print(pooled_output.shape) # (2, 2048)
Tensorflow实现
这段代码使用transformers库加载XLM模型和标记器,对英语和法语的样本输入序列进行标记,将序列填充到相同的长度,并通过XLM模型进行前向传递,得到最终的隐藏状态和集合输出。输出的形状被打印出来,以供验证。请注意,这只是一个例子,XLM模型可以用于标记化和编码之外的各种下游任务。
import tensorflow as tf
from transformers import TFXLMModel, XLMTokenizer
# Define the XLM model architecture and tokenizer
model = TFXLMModel.from_pretrained('xlm-mlm-en-2048')
tokenizer = XLMTokenizer.from_pretrained('xlm-mlm-en-2048')
# Define a sample input sequence in English and French
input_text = ["Hello, world!", "Bonjour, le monde!"]
# Tokenize the input sequence into subwords
input_ids = [tokenizer.encode(text) for text in input_text]
# Pad the input sequences to the same length
max_length = max(len(ids) for ids in input_ids)
input_ids = [ids + [0]*(max_length - len(ids)) for ids in input_ids]
# Convert the input sequences to TensorFlow tensors
input_ids = tf.constant(input_ids)
# Forward pass through the XLM model
outputs = model(input_ids)
# Get the final hidden states and pooled output
hidden_states = outputs.last_hidden_state
pooled_output = outputs.pooler_output
# Print the output shape
print(hidden_states.shape) # (2, max_length, 2048)
print(pooled_output.shape) # (2, 2048)
3.论文翻译
摘要
最近的研究证明了生成式预训练对英语自然语言理解的有效性。在这项工作中,我们将这种方法扩展到多种语言,并展示了跨语言预训练的有效性。我们提出了两种学习跨语言语言模型 (XLM) 的方法:一种是仅依赖单语言数据的无监督方法,另一种是利用具有新的跨语言语言模型目标的并行数据的监督方法。我们在跨语言分类、无监督和监督机器翻译方面获得了最先进的结果。在 XNLI 上,我们的方法以 4.9% 的准确率绝对增益推动了最先进的技术水平。在无监督机器翻译中,我们在 WMT'16 德语-英语上获得了 34.3 BLEU,将之前的技术水平提高了超过 9 BLEU。在有监督的机器翻译上,我们在 WMT'16 罗马尼亚语-英语上获得了 38.5 BLEU 的最新技术水平,比之前的最佳方法高出 4 个以上的 BLEU。我们的代码和预训练模型将公开发布。
1 简介
-
句子编码器的生成预训练(Radford 等人,2018 年;Howard 和 Ruder,2018 年;Devlin 等人,2018 年)已经在众多自然语言理解基准上取得了很大的进步(Wang 等人,2018 年)。在这种情况下,Transformer (Vaswani et al., 2017) 语言模型是在大型无监督文本语料库上学习的,然后在自然语言理解 (NLU) 任务上进行微调,例如分类 (Socher et al., 2013) 或自然语言推理(Bowman 等人,2015 年;Williams 等人,2017 年)。尽管人们对学习通用句子表示的兴趣激增,但该领域的研究基本上是单一语言的,并且主要集中在英语基准上(Conneau 和 Kiela,2018 年;Wang 等人,2018 年)。学习和评估多种语言的跨语言句子表示的最新进展(Conneau 等人,2018b)旨在减轻以英语为中心的偏见,并建议可以构建通用的跨语言编码器,将任何句子编码成共享嵌入空间。
-
在这项工作中,我们展示了跨语言语言模型预训练在多个跨语言理解 (XLU) 基准上的有效性。准确地说,我们做出了以下贡献:
- 我们引入了一种新的无监督方法,使用跨语言语言建模来学习跨语言表示,并研究了两个单语言预训练目标。
- 我们引入了一种新的监督学习目标,可以在并行数据可用时改进跨语言预训练。
- 我们在跨语言分类、无监督机器翻译和有监督机器翻译方面的表现明显优于之前的技术水平。
- 我们表明跨语言语言模型可以显着改善低资源语言的困惑度。 5. 我们将公开我们的代码和预训练模型。
2 相关工作
-
我们的工作建立在 Radford 等人的基础之上。 (2018);霍华德和罗德 (2018);德夫林等人。 (2018) 研究预训练 Transformer 编码器的语言建模。他们的方法使 GLUE 基准测试的几个分类任务有了显着改进(Wang 等人,2018 年)。拉马钱德兰等人。 (2016) 表明,语言建模预训练还可以显着改进机器翻译任务,即使对于存在大量并行数据的高资源语言对(例如英语-德语)也是如此。在我们开展工作的同时,BERT 存储库 1 上展示了使用跨语言语言建模方法进行跨语言分类的结果。我们将这些结果与第 5 节中的方法进行比较。
-
文本表示的对齐分布有着悠久的传统,从词嵌入对齐和 Mikolov 等人的工作开始。 (2013a) 利用小型词典来对齐来自不同语言的单词表示。一系列后续研究表明,跨语言表示可用于提高单语表示的质量(Faruqui 和 Dyer,2014),正交变换足以对齐这些词分布(Xing 等人,2015),并且所有这些技术都可以应用于任意数量的语言(Ammar 等人,2016 年)。按照这一工作路线,跨语言监督的需求进一步减少(Smith 等人,2017 年),直到它被完全删除(Conneau 等人,2018a)。在这项工作中,我们通过对齐句子的分布并减少对并行数据的需求,使这些想法更进一步。在对齐来自多种语言的句子表示方面有大量工作。
-
通过使用平行数据,Hermann 和 Blunsom (2014);康诺等。 (2018b); Eriguchi 等人。 (2018) 调查了零样本跨语言句子分类。但最近最成功的跨语言编码器方法可能是 Johnson 等人的方法。 (2017) 用于多语言机器翻译。他们表明,通过使用单个共享的 LSTM 编码器和解码器,单个序列到序列模型可用于为许多语言对执行机器翻译。他们的多语言模型在低资源语言对上的表现优于现有技术,并启用了 1 https://github.com/google-research/bert 零样本翻译。按照这种方法,Artetxe 和 Schwenk(2018 年)表明生成的编码器可用于生成跨语言句子嵌入。他们的方法利用了超过 2 亿个平行句子。他们通过在固定句子表示之上学习分类器,在 XNLI 跨语言分类基准(Conneau 等人,2018b)上获得了最新的技术水平。虽然这些方法需要大量并行数据,但最近在无监督机器翻译方面的工作表明,句子表示可以以完全无监督的方式对齐(Lample 等人,2018a;Artetxe 等人,2018)。例如,Lample 等人。 (2018b) 在不使用平行句的情况下,在 WMT'16 德语-英语上获得了 25.2 BLEU。与这项工作类似,我们表明我们可以以完全无监督的方式对齐句子的分布,并且我们的跨语言模型可用于广泛的自然语言理解任务,包括机器翻译。
-
与我们最相似的工作可能是 Wada 和 Iwata (2018) 的工作,作者在其中使用来自不同语言的句子训练 LSTM(Hochreiter 和 Schmidhuber,1997)语言模型。它们共享 LSTM 参数,但使用不同的查找表来表示每种语言中的单词。他们专注于对齐单词表示,并表明他们的方法在单词翻译任务上效果很好。
3 跨语言语言模型
在本节中,我们介绍了我们在整个工作中考虑的三个语言建模目标。其中两个只需要单语数据(无监督),而第三个需要平行句子(有监督)。我们考虑 N 种语言。除非另有说明,我们假设我们有 N 个单语语料库 {Ci}i=1…N ,我们用 ni 表示 Ci 中的句子数。
3.1 共享子词词汇
- 在我们所有的实验中,我们使用通过字节对编码(BPE)创建的相同共享词汇来处理所有语言(Sennrich 等人,2015)。如 Lample 等人所示。 (2018a),这大大提高了跨语言的嵌入空间对齐,这些语言共享相同的字母表或锚标记,例如数字 (Smith et al., 2017) 或专有名词。我们在从单语语料库中随机抽取的句子串联上学习 BPE 拆分。句子根据概率为 { q i } i = 1... N \{q_i\}_{i=1...N} { qi}i=1...N 的多项式分布进行采样,其中:
q i = p i α ∑ j = 1 N p j α w i t h p i = n i ∑ k = 1 N n k q_i = \frac{p_i^\alpha}{\sum_{j=1}^Np_j^\alpha} \ \ with \ \ \\ p_i = \frac{n_i}{\sum_{k=1}^Nn_k} qi=∑j=1Npjαpiα with pi=∑k=1Nnkni
我们认为α=0.5。用这种分布进行抽样,增加了与低资源语言相关的标记的数量,缓解了对高资源语言的偏见。特别是,这可以防止低资源语言的词在字符层面上被分割。
3.2 因果语言建模 (CLM)
- 我们的因果语言建模 (CLM) 任务由一个 Transformer 语言模型组成,该模型经过训练可以对给定句子中先前单词的单词概率建模 P ( w t ∣ w 1 , . . . , w t − 1 , θ ) P(w_t |w_1, . . ., w_{t−1}, θ) P(wt∣w1,...,wt−1,θ)。虽然循环神经网络在语言建模基准测试中获得了最先进的性能(Mikolov 等人,2010 年;Jozefowicz 等人,2016 年),但 Transformer 模型也非常具有竞争力(Dai 等人,2019 年)。
- 在 LSTM 语言模型的情况下,通过时间反向传播 (Werbos, 1990) (BPTT) 是通过为 LSTM 提供前一次迭代的最后隐藏状态来执行的。在 Transformers 的情况下,之前的隐藏状态可以传递给当前批次(Al-Rfou 等人,2018 年),为批次中的第一个单词提供上下文。然而,这种技术并不能扩展到跨语言设置,所以为了简单起见,我们只保留每批中的第一个单词而没有上下文。
3.3 掩码语言建模(MLM)
- 我们还考虑了 Devlin 等人的掩码语言建模(MLM)目标。 (2018),也称为完形填空任务 (Taylor, 1953)。继 Devlin 等人之后。 (2018),我们从文本流中随机抽取 15% 的 BPE 标记,80% 的时间用 [MASK] 标记替换它们,10% 的时间用随机标记替换它们,我们保持它们不变 10%时间。我们的方法与 Devlin 等人的 MLM 之间的差异。 (2018) 包括使用任意数量的句子的文本流(截断为 256 个标记)而不是成对的句子。为了解决稀有和频繁标记(例如标点符号或停用词)之间的不平衡,我们还使用类似于 Mikolov 等人的方法对频繁输出进行二次采样。 (2013b):文本流中的标记根据多项式分布进行采样,其权重与其反转频率的平方根成正比。我们的 MLM 目标如图 1 所示。
3.4 翻译语言建模 (TLM)
- CLM 和 MLM 目标都是无监督的,只需要单语数据。但是,这些目标不能用于在可用时利用并行数据。我们引入了一种新的翻译语言建模 (TLM) 目标来改进跨语言预训练。我们的 TLM 目标是 MLM 的扩展,我们不考虑单语文本流,而是连接平行句子,如图 1 所示。我们随机屏蔽源句子和目标句子中的单词。为了预测英语句子中隐藏的单词,该模型可以关注周围的英语单词或法语翻译,从而鼓励模型对齐英语和法语表示。特别是,如果英语语境不足以推断出被屏蔽的英语单词,该模型可以利用法语语境。为了便于对齐,我们还重置了目标句子的位置。
3.5 跨语言语言模型
- 在这项工作中,我们考虑使用 CLM、MLM 或与 TLM 结合使用的 MLM 进行跨语言语言模型预训练。对于 CLM 和 MLM 目标,我们使用由 256 个标记组成的 64 个连续句子流来训练模型。在每次迭代中,一个批次由来自相同语言的句子组成,这些句子从上面的分布 { q i } i = 1... N \{q_i\}_{i=1...N} { qi}i=1...N 中采样,其中 α = 0.7。当 TLM 与 MLM 结合使用时,我们在这两个目标之间交替,并使用类似的方法对语言对进行采样。
4 跨语言语言模型预训练
在本节中,我们将解释如何使用跨语言语言模型来获得:
- 更好地初始化零样本跨语言分类的句子编码器
- 更好地初始化有监督和无监督的神经机器翻译系统
- 低资源语言的语言模型
- 无监督的跨语言词嵌入
4.1 跨语言分类
- 我们预训练的 XLM 模型提供通用的跨语言文本表示。类似于英语分类任务的单语言语言模型微调(Radford 等人,2018 年;Devlin 等人,2018 年),我们在跨语言分类基准上微调 XLM。我们使用跨语言自然语言推理 (XNLI) 数据集来评估我们的方法。准确地说,我们在预训练的 Transformer 的第一个隐藏状态之上添加了一个线性分类器,并在英语 NLI 训练数据集上微调了所有参数。然后我们评估我们的模型在 15 种 XNLI 语言中做出正确 NLI 预测的能力。在 Conneau 等人之后。 (2018b),我们还包括了训练集和测试集的机器翻译基线。我们在表 1 中报告了我们的结果。
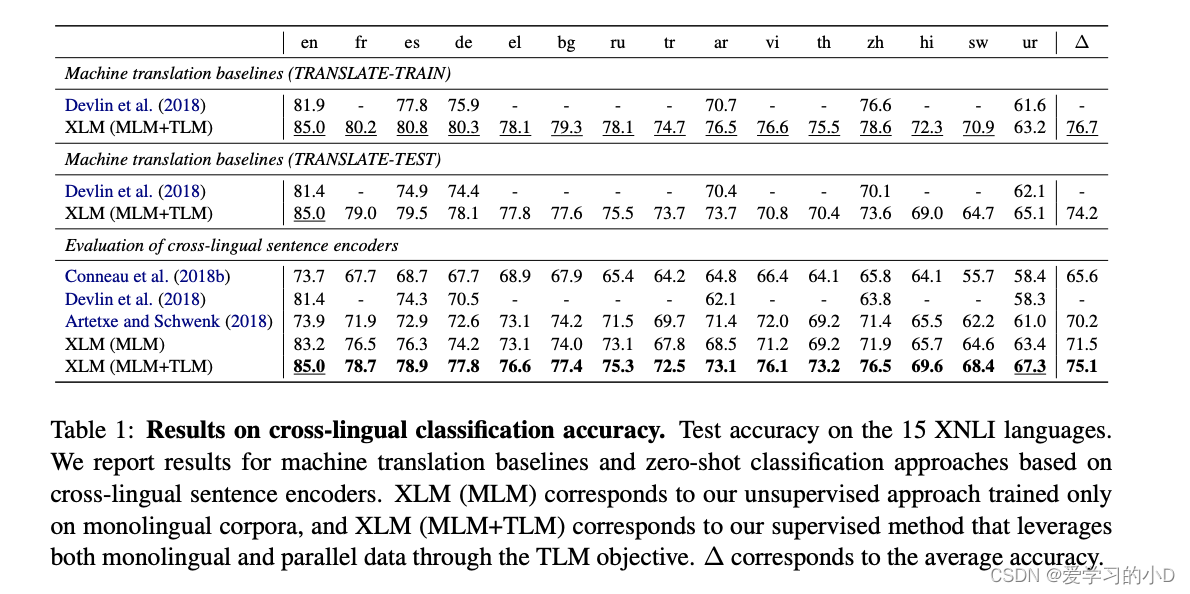
表 1:跨语言分类准确性的结果。测试 15 种 XNLI 语言的准确性。我们报告了基于跨语言句子编码器的机器翻译基线和零样本分类方法的结果。 XLM (MLM) 对应于我们仅在单语语料库上训练的无监督方法,而 XLM (MLM+TLM) 对应于我们通过 TLM 目标利用单语和并行数据的监督方法。 ∆ 对应于平均准确度。
4.2 无监督机器翻译
- 预训练是无监督神经机器翻译 (UNMT) 的关键组成部分(Lample 等人,2018a;Artetxe 等人,2018)。 Lample 等人。 (2018b) 表明,用于初始化查找表的预训练跨语言词嵌入的质量对无监督机器翻译模型的性能有重大影响。我们建议通过使用跨语言语言模型对整个编码器和解码器进行预训练来将这一想法更进一步,以引导 UNMT 的迭代过程。我们探索各种初始化方案并评估它们对几个标准机器翻译基准的影响,包括 WMT'14 英语-法语、WMT'16 英语-德语和 WMT'16 英语罗马尼亚语。结果如表 2 所示。
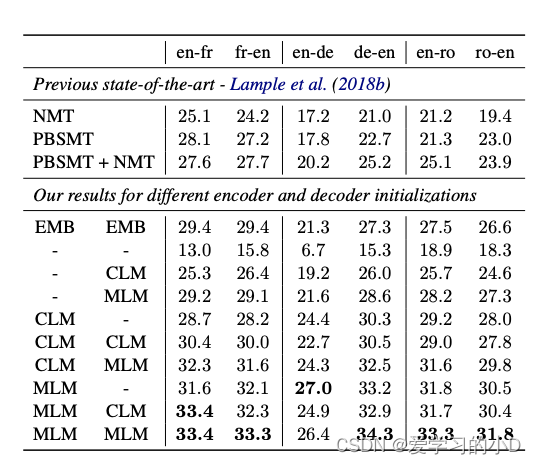
表2: 无监督MT的结果。在WMT’14英语-法语、WMT’16德语-英语和WMT’16罗马尼亚语中的BLEU分数。德语-英语和WMT’16罗马尼亚语英语。对于我们的结果,前两栏 表示用于预训练编码器和解码器的模型。和解码器。"-"表示该模型是 随机初始化的。EMB对应的是 EMB对应于用跨语言的查找表进行预训练。嵌入,CLM和MLM对应于 预训练的模型是根据CLM或 MLM目标进行预训练。
4.3 监督机器翻译
- 我们还研究了跨语言语言建模预训练对监督机器翻译的影响,并扩展了 Ramachandran 等人的方法。 (2016 年)到多语言 NMT(Johnson 等人,2017 年)。我们评估了 CLM 和 MLM 预训练对 WMT'16 罗马尼亚-英语的影响,并在表 3 中给出了结果。
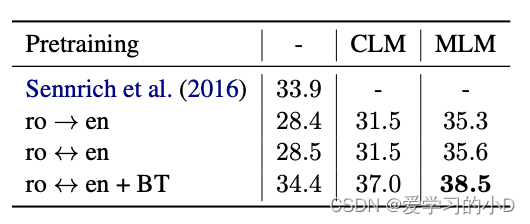
表3: 有监督的MT的结果。BLEU分数 在WMT’16的罗马尼亚语-英语上。以前的 Sennrich等人(2016)的最先进的方法是同时使用反译和集合模型。逆向翻译和一个集合模型。对应于在两个方向上训练的模型。
4.4 低资源语言建模
- 对于低资源语言,利用类似但资源更高的数据通常是有益的语言,尤其是当它们共享很大一部分词汇时。例如,维基百科上有大约 10 万个尼泊尔语句子,而印地语大约是其 6 倍。这两种语言在 100k 子词单元的共享 BPE 词汇表中也有超过 80% 的标记是相同的。我们在表 4 中提供了尼泊尔语言模型与以尼泊尔语训练但用印地语和英语数据的不同组合丰富的跨语言语言模型之间的困惑度比较。
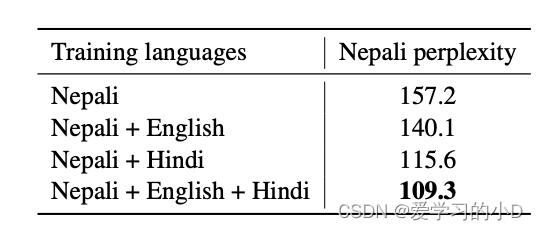
表4:语言建模的结果。当使用来自类似语言(印地语)或遥远语言(英语)的额外数据时,尼泊尔语的困惑程度。
4.5 无监督跨语言词嵌入
- Conneau 等人。 (2018a) 展示了如何通过将单语词嵌入空间与对抗训练 (MUSE) 对齐来执行无监督词翻译。 Lample 等人。 (2018a) 表明,使用两种语言之间的共享词汇,然后应用 fastText (Bojanowski et al., 2017) 连接他们的单语语料库,也直接为共享词汇的语言提供高质量的跨语言词嵌入 (Concat)通用字母表。在这项工作中,我们也使用共享词汇表,但我们的词嵌入是通过跨语言语言模型 (XLM) 的查找表获得的。在第 5 节中,我们在三个不同的指标上比较了这三种方法:余弦相似度、L2 距离和跨语言单词相似度
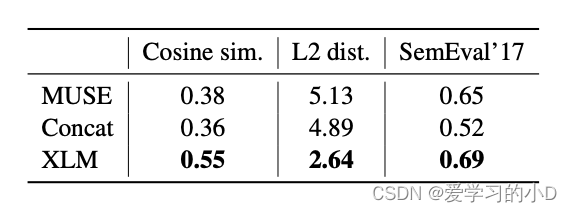
表5:无监督跨语言词嵌入源词和其译文之间的余弦相似度和二级距离。在SemEval’17跨语言词汇的皮尔逊相关度 Camacho-Collados等人(2017)的相似性任务。
5 实验和结果
在本节中,我们通过经验证明了跨语言语言模型预训练对几个基准的强烈影响,并将我们的方法与当前的技术水平进行了比较。
5.1 训练细节
- 在所有实验中,我们使用具有 1024 个隐藏单元、8 个头、GELU 激活(Hendrycks 和 Gimpel,2016)、0.1 的丢失率和学习位置嵌入的 Transformer 架构。我们使用 Adam 优化器(Kingma 和 Ba,2014 年)、线性预热(Vaswani 等人,2017 年)和从 10−4 到 5.10−4 的学习率来训练我们的模型。
- 对于 CLM 和 MLM 目标,我们使用 256 个令牌的流和大小为 64 的小批量。与 Devlin 等人不同。 (2018),小批量中的序列可以包含两个以上的连续句子,如第 3.2 节所述。对于 TLM 目标,我们对 4000 个由长度相似的句子组成的标记进行了小批量采样。我们使用语言的平均困惑度作为训练的停止标准。对于机器翻译,我们只使用 6 层,我们创建了 2000 个标记的小批量。
- 在对 XNLI 进行微调时,我们使用大小为 8 或 16 的小批量,并将句子长度限制为 256 个单词。我们使用 80k BPE 拆分和 95k 的词汇表,并在 XNLI 语言的维基百科上训练一个 12 层模型。我们使用 5.10−4 到 2.10−4 之间的值对 Adam 优化器的学习率进行采样,并使用 20000 个随机样本的小评估时期。我们使用 transformer 最后一层的第一个隐藏状态作为随机初始化的最终线性分类器的输入,并对所有参数进行微调。在我们的实验中,在最后一层使用最大池化或均值池化并不比使用第一个隐藏状态更好。
- 我们在 PyTorch 中实现了所有模型(Paszke 等人,2017 年),并在 64 个 Volta GPU 上训练它们用于语言建模任务,并在 8 个 GPU 上训练它们用于 MT 任务。我们使用 float16 操作来加速训练并减少模型的内存使用。
5.2 数据预处理
- 我们使用 WikiExtractor2 从维基百科转储中提取原始句子,并将它们用作 CLM 和 MLM 目标的单语数据。对于 TLM 目标,我们仅使用涉及英语的并行数据,类似于 Conneau 等人。 (2018b)。准确地说,我们对法语、西班牙语、俄语、阿拉伯语和汉语使用 MultiUN(Ziemski 等人,2016 年),对印地语使用 IIT 孟买语料库(Anoop 等人,2018 年)。我们从 OPUS 3 网站 Tiedemann (2012) 中提取了以下语料库:德语、希腊语和保加利亚语的 EUbookshop 语料库,土耳其语、越南语和泰语的 OpenSubtitles 2018,乌尔都语和斯瓦希里语的 Tanzil 以及斯瓦希里语的 GlobalVoices。对于中文、日文和泰文,我们使用 Chang 等人的分词器。 (2008),分别是 Kytea4 分词器和 PyThaiNLP5 分词器。对于所有其他语言,我们使用 Moses (Koehn et al., 2007) 提供的分词器,必要时回退到默认的英语分词器。我们使用 fastBPE6 来学习 BPE 代码并将单词拆分为子单词单元。 BPE 代码是根据第 3.1 节中介绍的方法从所有语言中采样的句子串联学习的。
5.3 结果与分析
在本节中,我们展示了跨语言语言模型预训练的有效性。我们的方法在跨语言分类、无监督和有监督的机器翻译方面明显优于以前的技术水平。
Cross-lingual classification跨语言分类
- 在表 1 中,我们评估了两种类型的预训练跨语言编码器:一种无监督的跨语言语言模型,仅在单语语料库上使用 MLM 目标;以及一个有监督的跨语言语言模型,它使用额外的并行数据结合了 MLM 和 TLM 损失。在 Conneau 等人之后。 (2018b),我们包括两个机器翻译基线:TRANSLATETRAIN,其中英语 MultiNLI 训练集被机器翻译成每种 XNLI 语言,以及 TRANSLATE-TEST,其中 XNLI 的每个开发和测试集都被翻译成英语。我们报告了 Conneau 等人的 XNLI 基线。 (2018b),Devlin 等人的多语言 BERT 方法。 (2018) 以及 Artetxe 和 Schwenk (2018) 的近期作品。
- 我们完全无监督的 MLM 方法在零样本跨语言分类方面开创了最先进的技术,并且明显优于使用 2.23 亿个平行句子的 Artetxe 和 Schwenk(2018)的监督方法。准确地说,MLM 平均获得了 71.5% 的准确率 (Δ),而他们获得了 70.2% 的准确率。通过 TLM 目标 (MLM+TLM) 利用并行数据,我们的性能显着提高了 3.6%,进一步将现有技术水平提高到 75.1%。在斯瓦希里语和乌尔都语低资源语言上,我们的表现分别比之前的技术水平高出 6.2% 和 6.3%。除了 MLM 之外,使用 TLM 还可以将英语准确率从 83.2% 提高到 85%,优于 Artetxe 和 Schwenk (2018) 以及 Devlin 等人。 (2018) 的准确率分别为 11.1% 和 3.6%。
- 当对每种 XNLI 语言 (TRANSLATE-TRAIN) 的训练集进行微调时,我们的监督模型比我们的零样本方法高出 1.6%,达到了 76.7% 平均准确率的绝对最新水平。这个结果特别证明了我们方法的一致性,并表明 XLM 可以在任何具有强大性能的语言上进行微调。与多语言 BERT(Devlin 等人,2018 年)类似,我们观察到 TRANSLATE-TRAIN 的平均准确度比 TRANSLATE-TEST 高 2.5%,此外,我们的零样本方法比 TRANSLATE-TEST 高 0.9%。
Unsupervised machine translation无监督机器翻译
-
对于无监督机器翻译任务,我们考虑 3 种语言对:英语-法语、英语-德语和英语-罗马尼亚语。我们的设置与 Lample 等人的设置相同。 (2018b),除了初始化步骤,我们使用跨语言语言建模来预训练完整模型,而不是仅使用查找表。
-
对于编码器和解码器,我们考虑不同的可能初始化:CLM 预训练、MLM 预训练或随机初始化,这会产生 9 种不同的设置。然后我们跟随 Lample 等人。 (2018b) 并使用去噪自动编码损失和在线反向翻译损失来训练模型。结果报告在表 2 中。我们将我们的方法与 Lample 等人的方法进行了比较。 (2018b)。对于每个语言对,我们观察到比以前的技术水平有显着改进。我们重新实现了 Lample 等人的 NMT 方法。 (2018b) (EMB),并获得了比他们论文中报道的更好的结果。我们预计这是由于我们的多 GPU 实现使用了明显更大的批次。在德语-英语中,我们最好的模型比以前的无监督方法高出 9.1 BLEU,如果我们只考虑神经无监督方法,则高出 13.3 BLEU。与仅对查找表 (EMB) 进行预训练相比,使用 MLM 对编码器和解码器进行预训练可使德语英语的 BLEU 持续显着提高多达 7 个。我们还观察到,MLM 目标预训练始终优于 CLM,英语法语从 30.4 升至 33.4 BLEU,罗马尼亚英语从 28.0 升至 31.8。这些结果与 Devlin 等人的结果一致。 (2018) 与 CLM 相比,在针对 MLM 目标进行训练时观察到 NLU 任务具有更好的泛化能力。我们还观察到编码器是预训练最重要的元素:与同时对编码器和解码器进行预训练相比,仅对解码器进行预训练会导致性能显着下降,而仅对编码器进行预训练对最终结果的影响很小BLEU 分数。
Supervised machine translation监督机器翻译
- 在表 3 中,我们报告了罗马尼亚语-英语 WMT'16 在不同监督训练配置下的表现:单向(ro→en)、双向(roen,在 en→ro 和 en→ro 上训练的多 NMT 模型ro→en) 和双向反向翻译 (roen + BT)。具有反向翻译的模型使用与用于预训练的语言模型相同的单语数据进行训练。与在无监督设置中一样,我们观察到预训练显着提高了每个配置的 BLEU 分数,并且使用 MLM 目标进行预训练会带来最佳性能。此外,虽然具有反向翻译的模型可以访问与预训练模型相同数量的单语数据,但它们在评估集上的泛化能力不佳。我们用反向翻译训练的双向模型获得最佳性能并达到 38.5 BLEU,优于 Sennrich 等人之前的 SOTA。 (2016)(基于反向翻译和集成模型)超过 4 个 BLEU。
Low-resource language model低资源语言模型
- 在表 4 中,我们调查了跨语言语言建模对改善尼泊尔语言模型的困惑度的影响。为此,我们在维基百科上训练尼泊尔语言模型,以及来自英语或印地语的额外数据。虽然尼泊尔语和英语是遥远的语言,但尼泊尔语和印地语很相似,因为它们共享相同的天城体文字,并且有共同的梵语祖先。使用英语数据时,我们将尼泊尔语言模型的困惑度降低了 17.1 点,从仅使用尼泊尔语的语言模型的 157.2 降低到使用英语时的 140.1。使用来自印地语的额外数据,我们得到了更大的困惑减少 41.6。最后,通过利用英语和印地语的数据,我们将尼泊尔语的困惑度进一步降低至 109.3。跨语言语言建模带来的困惑度的增加可以部分用跨语言共享的 n-gram 锚点来解释,例如在维基百科文章中。因此,跨语言语言模型可以通过这些锚点转移由印地语或英语单语语料库提供的额外上下文,以改进尼泊尔语模型。
Unsupervised cross-lingual word embeddings无监督跨语言词嵌入
- MUSE、Concat 和 XLM (MLM) 方法提供了具有不同属性的无监督跨语言词嵌入空间。在表 5 中,我们使用相同的词汇表研究了这三种方法,并计算了 MUSE 词典中单词翻译对之间的余弦相似度和 L2 距离。我们还通过 Camacho-Collados 等人的 SemEval'17 跨语言单词相似性任务评估余弦相似性度量的质量。 (2017)。我们观察到 XLM 在跨语言单词相似性方面优于 MUSE 和 Concat,达到 0.69 的 Pearson 相关性。有趣的是,XLM 跨语言词嵌入空间中的词翻译对也比 MUSE 或 Concat 更接近。具体来说,MUSE 的余弦相似度和 L2 距离分别为 0.38 和 5.13,而 XLM 的相同指标分别为 0.55 和 2.64。请注意,XLM 嵌入具有与句子编码器一起训练的特殊性,这可能会加强这种紧密性,而 MUSE 和 Concat 则基于 fastText 词嵌入。
6 结论
- 在这项工作中,我们首次展示了跨语言语言模型 (XLM) 预训练的强大影响。我们研究了两个只需要单语语料库的无监督训练目标:因果语言建模 (CLM) 和掩码语言建模 (MLM)。我们展示了 CLM 和 MLM 方法都提供了强大的跨语言功能,可用于预训练模型。在无监督机器翻译中,我们证明了 MLM 预训练非常有效。我们在 WMT'16 GermanEnglish 上达到了 34.3 BLEU 的新水平,比之前的最佳方法高出 9 个 BLEU。同样,我们在有监督的机器翻译上获得了很大的改进。我们在 WMT'16 罗马尼亚语-英语上达到了 38.5 BLEU 的最新技术水平,这相当于提高了超过 4 个 BLEU 点。我们还证明了跨语言语言模型可用于改善尼泊尔语言模型的困惑度,并且它提供了无监督的跨语言词嵌入。在不使用单个平行句的情况下,在 XNLI 跨语言分类基准上微调的跨语言语言模型已经比之前的监督技术水平平均准确率高出 1.3%。我们工作的一个关键贡献是翻译语言建模 (TLM) 目标,它通过利用并行数据改进跨语言语言模型预训练。 TLM 通过使用成批的平行句子而不是连续的句子自然地扩展了 BERT MLM 方法。除了 MLM 之外,我们通过使用 TLM 获得了显着的收益,并且我们表明这种监督方法在 XNLI 上的平均准确度超过了以前的技术水平 4.9%。我们的代码和预训练模型将公开发布。
智能推荐
微服务 tars php,腾讯tars微服务安装笔记-程序员宅基地
文章浏览阅读118次。tarsphp 文档地址https://www.bookstack.cn/read/TarsPHP/ 谢谢大佬的整理安装需要组件例如,在Centos下,执行:yum install glibc-develyum install gccyum install gcc-c++yum install lrzszyum install -y git下载tarsphp 架构包下载TarsFramework源..._windows tarsphp安装
浪潮信息HANA一体机创SAP BWH最佳成绩,算力助商业智能更快更准-程序员宅基地
文章浏览阅读948次,点赞24次,收藏26次。近日,SAP官方发布最新BWH Benchmark基准测试结果,浪潮信息NF8480G7四路HANA一体机以每小时执行17044次查询的成绩,刷新该测试最高纪录,为全球金融、高端制造、零售、能源等行业用户的商业智能分析,提供高效、领先的算力平台,从容应对快速多变的商业环境。
ESP32 开发笔记(三)源码示例 8_DHT11_RMT 使用RMT实现读取DHT11温湿度传感器_基于vscode的esp32开发,读取dht11传感器数据到led显示屏上-程序员宅基地
文章浏览阅读1.1w次,点赞5次,收藏22次。开发板购买链接https://item.taobao.com/item.htm?spm=a2oq0.12575281.0.0.50111deb2Ij1As&ft=t&id=626366733674开发板简介开发环境搭建 windows源码示例: 0_Hello Bug (ESP_LOGX与printf) 工程模板/打印调试输出 1_LED LED亮灭控制 ..._基于vscode的esp32开发,读取dht11传感器数据到led显示屏上
icpc网络赛第二场 J-A Game about Increasing Sequences-程序员宅基地
文章浏览阅读623次。简单题,但是不会_a game about increasing sequences
9.学习74HC595以及8x8点阵流水灯_stc8g 驱动74hc595-程序员宅基地
文章浏览阅读2.3k次。OE非:输出使能,本实验接地使用。记得接地!单片机手动接地!J24模块!RCLK:储存寄存器时钟输入SRCLR非:复位,本单片机默认接VCC,不用管。SRCLK:移位寄存器时钟输入SER:串行输入QA-QH:8位并行输出QH非:串行输出 本实验595的工作:SRCLK每接到一个上升沿,就把SER的值储存起来;当存够8位后,给RCLK一个上升沿,储存起来的数就被放到QA-QH,第一个存进来的数放到QH(高位的数放高位)。(自己的理解,不知对错)列由P0控..._stc8g 驱动74hc595
Python Flask框架学习31:orm操作及序列化/更规范的文件格式_get_db_uri-程序员宅基地
文章浏览阅读492次。文件树如下:首先是utils包:functions.py配置代码如下:from flask_sqlalchemy import SQLAlchemyfrom flask_debugtoolbar import DebugToolbarExtensionfrom flask_restful import Apifrom flask_marshmallow import Marshmallowdb = SQLAlchemy()debugtoolbar = DebugToolb_get_db_uri
随便推点
mysql5.6主从库安装与配置_mysql的主从库部署-程序员宅基地
文章浏览阅读4.3k次。mysql5.6主从库安装与配置关闭防火墙//临时关闭systemctl stop firewalld//禁止开机启动systemctl disable firewalldmysql5.6安装保证可以联通外网。安装wgetyum install wget检查系统是否安装其他版本的mysql数据yum list installed | grep mysqlyum ..._mysql的主从库部署
Lua学习-运算符_lua &&-程序员宅基地
文章浏览阅读655次。运算符分为:1.算术运算符2.条件运算符3.逻辑运算符4.位运算符5.三元运算符在Lua中不支持位运算符和三位运算符,但是可以间接实现三元运算符1.算术运算符(+、-、*、/、%、^(幂运算符))注意:Lua中没有++,–,+=,-=,*=,/=,%=2.条件运算符(and ,or,not) 注意:Lua中的条件运算符就这三个,没有&&,||,!=3.逻辑运算符(> ,<, =, >=, <=, ==,~=) 注意:Lua中的不等于是"~="pri_lua &&
基于图像的三维模型重建——相机模型与对极几何-程序员宅基地
文章浏览阅读1.7k次。点击上方“3D视觉工坊”,选择“星标”干货第一时间送达作者:梦寐mayshinehttps://zhuanlan.zhihu.com/p/129681081本文转载自知乎,作者已授权,未..._图像 3d模型 csdn
2021年美赛解题思路汇总Final!!!_2021年美赛b题思路-程序员宅基地
文章浏览阅读1.2w次,点赞9次,收藏54次。首先:A题是连续型问题,是“数值分析”领域的内容,需要熟练掌握偏微分方程以及精通将连续性方程离散化求解的编程能力。这时,队伍里最好是有一个纯数学基础好的(偏微分方程、复变函数、信号与系统等等),还需要有两个擅长连续型问题编程的同学,两个人都比较擅长编程这一点很重要,既可以防止一个人编程的话,思路可能有所偏颇,又可以使得两个人在相互碰撞中产生新的灵感。B题的话可能是离散型问题,对于B题在编程上,一定需要比较熟悉计算机的“算法与数据结构”这类离散型编程问题的同学。C题属于大数据类问题,几乎都是关于数_2021年美赛b题思路
IP地址网站划分详解_网址划分-程序员宅基地
文章浏览阅读780次。LAN IP地址网站划分详解IP和子网掩码我们都知道,IP是由四段数字组成,在此,我们先来了解一下3类常用的IPA类IP段 0.0.0.0 到127.255.255.255B类IP段 128.0.0.0到191.255.255.255C类IP段 192.0.0.0到223.255.255.255 XP默认分配的子网掩码每段只有255或0 A类的默认子网_网址划分
【重识 HTML + CSS】知识点目录-程序员宅基地
文章浏览阅读637次,点赞29次,收藏14次。javascript是前端必要掌握的真正算得上是编程语言的语言,学会灵活运用javascript,将对以后学习工作有非常大的帮助。掌握它最重要的首先是学习好基础知识,而后通过不断的实战来提升我们的编程技巧和逻辑思维。这一块学习是持续的,直到我们真正掌握它并且能够灵活运用它。如果最开始学习一两遍之后,发现暂时没有提升的空间,我们可以暂时放一放。继续下面的学习,javascript贯穿我们前端工作中,在之后的学习实现里也会遇到和锻炼到。真正学习起来并不难理解,关键是灵活运用。