Hadoop安装与配置详细教程_安装hadoop安装详细步骤-程序员宅基地
【确保服务器集群安装和配置已经完成!】
前言
请根据读者的自身情况,进行相应随机应变。
我的三台CentOS7服务器:
主机:master(192.168.56.110)
从机:slave0(192.168.56.111)
从机:slave1(192.168.56.112)
每一个节点的安装与配置是相同的,在实际工作中,通常在master节点上完成安装和配置后,然后将安装目录复制到其他节点就可以,没有必要把所有节点都配置一遍,那样没有效率。
注意:所有操作都是root用户权限
下载Hadoop安装包
Hadoop官网:http://hadoop.apache.org/
我这里用的Hadoop版本下载地址:http://archive.apache.org/dist/hadoop/core/hadoop-2.7.5/
解压Hadoop安装包(只在master做)
确保network网络已经配置好,使用Xftp等类似工具进行上传,把hadoop-2.7.5.tar.gz上传到/opt/hadoop目录内。
上传完成后,在master主机上执行以下代码:
cd /opt/hadoop
进入/opt/hadoop目录后,执行解压缩命令:
tar -zxvf hadoop-2.7.5.tar.gz
回车后系统开始解压,屏幕会不断滚动解压过程,执行成功后,系统在hadoop目录自动创建hadoop-2.7.5子目录。
然后修改文件夹名称为“hadoop”,即hadoop安装目录,执行修改文件夹名称命令:
mv hadoop-2.7.5 hadoop
注意:也可用Xftp查看相应目录是否存在,确保正确完成。
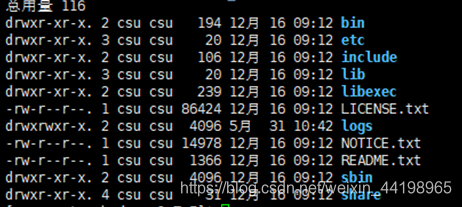
我们进入安装目录,查看一下安装文件,如果显示如图文件列表,说明压缩成功
配置env文件(只在master做)
请先看如下命令(并且记住它们,后续操作大量用到,并且不再赘述):
A. 进入编辑状态:insert
B. 删除:delete
C. 退出编辑状态:ctrl+[
D. 进入保存状态:ctrl+]
E. 保存并退出:" :wq " 注意先输入英文状态下冒号
F. 不保存退出:" :q! " 同上
大概执行顺序:A→B→C→D→E
配置jdk文件
执行命令:
vi /opt/hadoop/hadoop/etc/hadoop/hadoop-env.sh
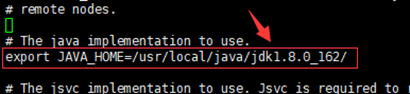
找到 “ export JAVA_HOME ” 这行,用来配置jdk路径
修改为:export JAVA_HOME=/usr/local/java/jdk1.8.0_162/
配置核心组件文件(只在master做)
Hadoop的核心组件文件是core-site.xml,位于/opt/hadoop/hadoop/etc/hadoop子目录下,用vi编辑core-site.xml文件,需要将下面的配置代码放在文件的<configuration>和</configuration>之间。
执行编辑core-site.xml文件的命令:
vi /opt/hadoop/hadoop/etc/hadoop/core-site.xml
需要在<configuration>和</configuration>之间加入的代码:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoopdata</value>
</property>
编辑完成后,退出并保存即可!
配置文件系统(只在master做)
Hadoop的文件系统配置文件是hdfs-site.xml,位于/opt/hadoop/hadoop/etc/hadoop子目录下,用vi编辑该文件,需要将以下代码放在文件的<configuration>和</configuration>之间。
执行编辑hdfs-site.xml文件的命令:
vi /opt/hadoop/hadoop/etc/hadoop/hdfs-site.xml
需要在<configuration>和</configuration>之间加入的代码:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
编辑完成后,退出保存即可!
配置 yarn-site.xml 文件(只在master做)
Yarn的站点配置文件是yarn-site.xml,位于/opt/hadoop/hadoop/etc/hadoop子目录下,依然用vi编辑该文件,将以下代码放在文件的<configuration>和</configuration>之间。
执行编辑yarn-site.xml文件的命令:
vi /opt/hadoop/hadoop/etc/hadoop/yarn-site.xml
需要在<configuration>和</configuration>之间加入的代码:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
配置MapReduce计算框架文件(只在master做)
在/opt/hadoop/hadoop/etc/hadoop子目录下,系统已经有一个mapred-site.xml.template文件,我们需要将其复制并改名,位置不变。
执行复制和改名操作命令:
cp /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml
然后用vi编辑mapred-site.xml文件,需要将下面的代码填充到文件的<configuration>和</configuration>之间。
执行命令:
vi /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml
需要在<configuration>和</configuration>之间加入的代码:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
编辑完毕,保存退出即可!
配置master的slaves文件(只在master做)
slaves文件给出了Hadoop集群的slave节点列表,该文件十分的重要,因为启动Hadoop的时候,系统总是根据当前slaves文件中的slave节点名称列表启动集群,不在列表中的slave节点便不会被视为计算节点。
执行编辑slaves文件命令:
vi /opt/hadoop/hadoop/etc/hadoop/slaves
注意:用vi编辑slaves文件,应该根据读者您自己所搭建集群的实际情况进行编辑。
例如:我这里已经安装了slave0和slave1,并且计划将它们全部投入Hadoop集群运行。
所以应当加入以下代码:
slave0
slave1
注意:删除slaves文件中原来localhost那一行!
复制master上的Hadoop到slave节点(只在master做)
通过复制master节点上的hadoop,能够大大提高系统部署效率,假设我们有200台需要配置…笔者岂不白头
由于我这里有slave0和slave1,所以复制两次。
复制命令:
scp -r /opt/hadoop root@slave0:/opt
scp -r /opt/hadoop root@slave1:/opt
Hadoop集群的启动-配置操作系统环境变量(三个节点都做)
回到用户目录命令:
cd /opt/hadoop
然后用vi编辑.bash_profile文件,命令:
vi ~/.bash_profile
最后把以下代码追加到文件的尾部:
#HADOOP
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存退出后,执行命令:
source ~/.bash_profile
source ~/.bash_profile命令是使上述配置生效
提示:在slave0和slave1使用上述相同的配置方法,进行三个节点全部配置。
创建Hadoop数据目录(只在master做)
创建数据目录,命令是:
mkdir /opt/hadoop/hadoopdata
通过Xftp可查看该hadoopdata
格式化文件系统(只在master做)
执行格式化文件系统命令:
hadoop namenode -format
启动和关闭Hadoop集群(只在master做)
首先进入安装主目录,命令是:
cd /opt/hadoop/hadoop/sbin
提示:目前文件位置可在Xshell顶部栏观察
然后启动,命令是:
start-all.sh
执行命令后,系统提示 ” Are you sure want to continue connecting(yes/no)”,输入yes,之后系统即可启动。
注意:可能会有些慢,千万不要以为卡掉了,然后强制关机,这是错误的。
如果要关闭Hadoop集群,可以使用命令:
stop-all.sh
下次启动Hadoop时,无须NameNode的初始化,只需要使用start-dfs.sh命令即可,然后接着使用start-yarn.sh启动Yarn。
实际上,Hadoop建议放弃(deprecated)使用start-all.sh和stop-all.sh一类的命令,而改用start-dfs.sh和start-yarn.sh命令。
验证Hadoop集群是否启动成功
读者您可以在终端执行jps命令查看Hadoop是否启动成功。
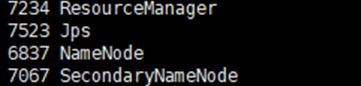
在master节点,执行:
jps
如果显示:SecondaryNameNode、 ResourceManager、 Jps 和NameNode这四个进程,则表明主节点master启动成功
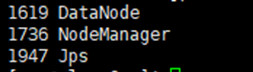
然后分别在slave0和slave1节点下执行命令:
jps
如果成功显示:NodeManager、Jps 和 DataNode,这三个进程,则表明从节点(slave0和slave1)启动成功
写在后面
如果觉得本文帮助了你,还请高抬贵手赠予 uh5 项目 一个 Star。
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数