分布式协调服务--zookeeper_zookeeper分布式协调服务-程序员宅基地
目录
一、概述
1、zookeeper有两种运行状态
1、有leader模型

2、无leader模型
即:不可用状态
官方压测:从无主模型恢复到有主模型时间在200毫秒内
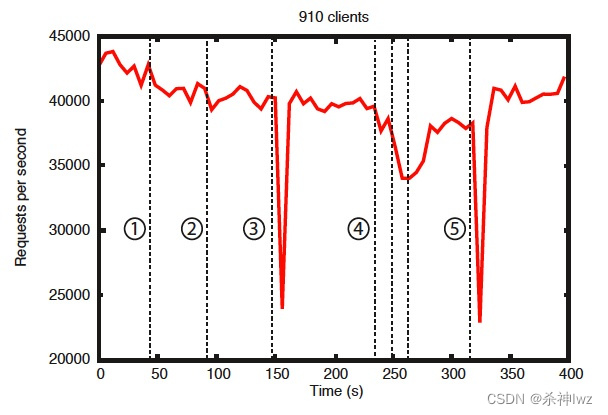
从这张图中可以看出一些重要的观察结果。首先,如果追随者失败并迅速恢复,那么ZooKeeper能够在失败的情况下保持高吞吐量。但也许更重要的是,领导人选举算法允许系统足够快地恢复,以防止吞吐量大幅下降。根据我们的观察,ZooKeeper只需要不到200毫秒的时间就可以选出新的领导者。第三,随着追随者的恢复,ZooKeeper能够在他们开始处理请求后再次提高吞吐量。
zookeeper是一个目录树结构!
node可以存数据1MB。
docker中搭建zookeeper集群 预留
zookeeper架构的角色:
- Leader
- Follower:只有Follower才能选举
- Observer:放大查询能力
zookeeper可靠性:快速恢复Leader、数据可靠可用一致性、攘外必先安内。
2、Paxos算法:消息传递的一致性算法
原文链接:https://www.douban.com/note/208430424/
Paxos:它是一个基于消息传递的一致性算法,Leslie Lamport在1990年提出,近几年被广泛应用于分布式计算中,Google的Chubby,Apache的Zookeeper都是基于它的理论来实现的,Paxos还被认为是到目前为止唯一的分布式一致性算法,其它的算法都是Paxos的改进或简化。有个问题要提一下,Paxos有一个前提:没有拜占庭将军问题。就是说Paxos只有在一个可信的计算环境中才能成立,这个环境是不会被入侵所破坏的。
Paxos描述了这样一个场景,有一个叫做Paxos的小岛(Island)上面住了一批居民,岛上面所有的事情由一些特殊的人决定,他们叫做议员(Senator)。议员的总数(Senator Count)是确定的,不能更改。岛上每次环境事务的变更都需要通过一个提议(Proposal),每个提议都有一个编号(PID),这个编号是一直增长的,不能倒退。每个提议都需要超过半数((Senator Count)/2 +1)的议员同意才能生效。每个议员只会同意大于当前编号的提议,包括已生效的和未生效的。如果议员收到小于等于当前编号的提议,他会拒绝,并告知对方:你的提议已经有人提过了。这里的当前编号是每个议员在自己记事本上面记录的编号,他不断更新这个编号。整个议会不能保证所有议员记事本上的编号总是相同的。现在议会有一个目标:保证所有的议员对于提议都能达成一致的看法。
好,现在议会开始运作,所有议员一开始记事本上面记录的编号都是0。有一个议员发了一个提议:将电费设定为1元/度。他首先看了一下记事本,嗯,当前提议编号是0,那么我的这个提议的编号就是1,于是他给所有议员发消息:1号提议,设定电费1元/度。其他议员收到消息以后查了一下记事本,哦,当前提议编号是0,这个提议可接受,于是他记录下这个提议并回复:我接受你的1号提议,同时他在记事本上记录:当前提议编号为1。发起提议的议员收到了超过半数的回复,立即给所有人发通知:1号提议生效!收到的议员会修改他的记事本,将1好提议由记录改成正式的法令,当有人问他电费为多少时,他会查看法令并告诉对方:1元/度。
现在看冲突的解决:假设总共有三个议员S1-S3,S1和S2同时发起了一个提议:1号提议,设定电费。S1想设为1元/度, S2想设为2元/度。结果S3先收到了S1的提议,于是他做了和前面同样的操作。紧接着他又收到了S2的提议,结果他一查记事本,咦,这个提议的编号小于等于我的当前编号1,于是他拒绝了这个提议:对不起,这个提议先前提过了。于是S2的提议被拒绝,S1正式发布了提议: 1号提议生效。S2向S1或者S3打听并更新了1号法令的内容,然后他可以选择继续发起2号提议。
好,我觉得Paxos的精华就这么多内容。现在让我们来对号入座,看看在ZK Server里面Paxos是如何得以贯彻实施的。
小岛(Island)——ZK Server Cluster
议员(Senator)——ZK Server
提议(Proposal)——ZNode Change(Create/Delete/SetData…)
提议编号(PID)——Zxid(ZooKeeper Transaction Id)
正式法令——所有ZNode及其数据
貌似关键的概念都能一一对应上,但是等一下,Paxos岛上的议员应该是人人平等的吧,而ZK Server好像有一个Leader的概念。没错,其实Leader的概念也应该属于Paxos范畴的。如果议员人人平等,在某种情况下会由于提议的冲突而产生一个“活锁”(所谓活锁我的理解是大家都没有死,都在动,但是一直解决不了冲突问题)。Paxos的作者Lamport在他的文章”The Part-Time Parliament“中阐述了这个问题并给出了解决方案——在所有议员中设立一个总统,只有总统有权发出提议,如果议员有自己的提议,必须发给总统并由总统来提出。好,我们又多了一个角色:总统。
总统——ZK Server Leader
又一个问题产生了,总统怎么选出来的?
现在我们假设总统已经选好了,下面看看ZK Server是怎么实施的。
情况一:
居民甲(Client)到某个议员(ZK Server)那里询问(Get)某条法令的情况(ZNode的数据),议员毫不犹豫的拿出他的记事本(local storage),查阅法令并告诉他结果,同时声明:我的数据不一定是最新的。你想要最新的数据?没问题,等着,等我找总统Sync一下再告诉你。
情况二:
居民乙(Client)到某个议员(ZK Server)那里要求政府归还欠他的一万元钱,议员让他在办公室等着,自己将问题反映给了总统,总统询问所有议员的意见,多数议员表示欠屁民的钱一定要还,于是总统发表声明,从国库中拿出一万元还债,国库总资产由100万变成99万。居民乙拿到钱回去了(Client函数返回)。
情况三:
总统突然挂了,议员接二连三的发现联系不上总统,于是各自发表声明,推选新的总统,总统大选期间政府停业,拒绝居民的请求。
呵呵,到此为止吧,当然还有很多其他的情况,但这些情况总是能在Paxos的算法中找到原型并加以解决。这也正是我们认为Paxos是Zookeeper的灵魂的原因。当然ZK Server还有很多属于自己特性的东西:Session, Watcher,Version等等等等,需要我们花更多的时间去研究和学习。
3、ZAB协议
原文链接:https://baijiahao.baidu.com/s?id=1718646106068529193&wfr=spider&for=pc
ZAB协议的全称是Zookeeper Atomic Broadcast(Zookeeper原子广播)。
Zookeeper 是通过 Zab 协议来保证分布式事务的最终一致性。
Zab协议是为分布式协调服务Zookeeper专门设计的一种支持崩溃恢复的原子广播协议,是Zookeeper保证数据一致性的核心算法。Zab借鉴了Paxos算法,但又不像Paxos那样,是一种通用的分布式一致性算法。它是特别为Zookeeper设计的支持崩溃恢复的原子广播协议。
在Zookeeper中主要依赖Zab协议来实现数据一致性,基于该协议,zk实现了一种主备模型(即Leader和Follower模型)的系统架构来保证集群中各个副本之间数据的一致性。
这里的主备系统架构模型,就是指只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader客户端将数据同步到其他Follower节点。
Zookeeper 客户端会随机的链接到 zookeeper 集群中的一个节点,如果是读请求,就直接从当前节点中读取数据;如果是写请求,那么节点就会向 Leader 提交事务,Leader 接收到事务提交,会广播该事务,只要超过半数节点写入成功,该事务就会被提交。
Zab 协议的特性:
1)Zab 协议需要确保那些已经在 Leader 服务器上提交(Commit)的事务最终被所有的服务器提交。
2)Zab 协议需要确保丢弃那些只在 Leader 上被提出而没有被提交的事务。
模型图
Zab 协议实现的作用
1)使用一个单一的主进程(Leader)来接收并处理客户端的事务请求(也就是写请求),并采用了Zab的原子广播协议,将服务器数据的状态变更以事务proposal(事务提议)的形式广播到所有的副本(Follower)进程上去。
2)保证一个全局的变更序列被顺序引用。
Zookeeper是一个树形结构,很多操作都要先检查才能确定是否可以执行,比如P1的事务t1可能是创建节点"/a",t2可能是创建节点"/a/bb",只有先创建了父节点"/a",才能创建子节点"/a/b"。
为了保证这一点,Zab要保证同一个Leader发起的事务要按顺序被apply,同时还要保证只有先前Leader的事务被apply之后,新选举出来的Leader才能再次发起事务。
3)当主进程出现异常的时候,整个zk集群依旧能正常工作。
Zab协议原理
Zab协议要求每个 Leader 都要经历三个阶段:发现,同步,广播。
发现:要求zookeeper集群必须选举出一个 Leader 进程,同时 Leader 会维护一个 Follower 可用客户端列表。将来客户端可以和这些 Follower节点进行通信。
同步:Leader 要负责将本身的数据与 Follower 完成同步,做到多副本存储。这样也是体现了CAP中的高可用和分区容错。Follower将队列中未处理完的请求消费完成后,写入本地事务日志中。
广播:Leader 可以接受客户端新的事务Proposal请求,将新的Proposal请求广播给所有的 Follower。
Zab协议核心
Zab协议的核心:定义了事务请求的处理方式
1)所有的事务请求必须由一个全局唯一的服务器来协调处理,这样的服务器被叫做Leader服务器。其他剩余的服务器则是Follower服务器。
2)Leader服务器 负责将一个客户端事务请求,转换成一个事务Proposal,并将该 Proposal 分发给集群中所有的 Follower 服务器,也就是向所有 Follower 节点发送数据广播请求(或数据复制)
3)分发之后Leader服务器需要等待所有Follower服务器的反馈(Ack请求),在Zab协议中,只要超过半数的Follower服务器进行了正确的反馈后(也就是收到半数以上的Follower的Ack请求),那么 Leader 就会再次向所有的 Follower服务器发送 Commit 消息,要求其将上一个 事务proposal 进行提交。
Zab协议内容
Zab 协议包括两种基本的模式:崩溃恢复和消息广播
协议过程
当整个集群启动过程中,或者当 Leader 服务器出现网络中弄断、崩溃退出或重启等异常时,Zab协议就会进入崩溃恢复模式,选举产生新的Leader。
当选举产生了新的 Leader,同时集群中有过半的机器与该 Leader 服务器完成了状态同步(即数据同步)之后,Zab协议就会退出崩溃恢复模式,进入消息广播模式。
这时,如果有一台遵守Zab协议的服务器加入集群,因为此时集群中已经存在一个Leader服务器在广播消息,那么该新加入的服务器自动进入恢复模式:找到Leader服务器,并且完成数据同步。同步完成后,作为新的Follower一起参与到消息广播流程中。
协议状态切换
当Leader出现崩溃退出或者机器重启,亦或是集群中不存在超过半数的服务器与Leader保存正常通信,Zab就会再一次进入崩溃恢复,发起新一轮Leader选举并实现数据同步。同步完成后又会进入消息广播模式,接收事务请求。
保证消息有序
在整个消息广播中,Leader会将每一个事务请求转换成对应的 proposal 来进行广播,并且在广播 事务Proposal 之前,Leader服务器会首先为这个事务Proposal分配一个全局单递增的唯一ID,称之为事务ID(即zxid),由于Zab协议需要保证每一个消息的严格的顺序关系,因此必须将每一个proposal按照其zxid的先后顺序进行排序和处理。
消息广播
1)在zookeeper集群中,数据副本的传递策略就是采用消息广播模式。zookeeper中数据副本的同步方式与二段提交相似,但是却又不同。二段提交要求协调者必须等到所有的参与者全部反馈ACK确认消息后,再发送commit消息。要求所有的参与者要么全部成功,要么全部失败。二段提交会产生严重的阻塞问题。
2)Zab协议中 Leader 等待 Follower 的ACK反馈消息是指“只要半数以上的Follower成功反馈即可,不需要收到全部Follower反馈”
消息广播具体步骤
1)客户端发起一个写操作请求。
2)Leader 服务器将客户端的请求转化为事务 Proposal 提案,同时为每个 Proposal 分配一个全局的ID,即zxid。
3)Leader 服务器为每个 Follower 服务器分配一个单独的队列,然后将需要广播的 Proposal 依次放到队列中取,并且根据 FIFO 策略进行消息发送。
4)Follower 接收到 Proposal 后,会首先将其以事务日志的方式写入本地磁盘中,写入成功后向 Leader 反馈一个 Ack 响应消息。
5)Leader 接收到超过半数以上 Follower 的 Ack 响应消息后,即认为消息发送成功,可以发送 commit 消息。
6)Leader 向所有 Follower 广播 commit 消息,同时自身也会完成事务提交。Follower 接收到 commit 消息后,会将上一条事务提交。
zookeeper 采用 Zab 协议的核心,就是只要有一台服务器提交了 Proposal,就要确保所有的服务器最终都能正确提交 Proposal。这也是 CAP/BASE 实现最终一致性的一个体现。
Leader 服务器与每一个 Follower 服务器之间都维护了一个单独的 FIFO 消息队列进行收发消息,使用队列消息可以做到异步解耦。 Leader 和 Follower 之间只需要往队列中发消息即可。如果使用同步的方式会引起阻塞,性能要下降很多。
崩溃恢复
一旦 Leader 服务器出现崩溃或者由于网络原因导致 Leader 服务器失去了与过半 Follower 的联系,那么就会进入崩溃恢复模式。
在 Zab 协议中,为了保证程序的正确运行,整个恢复过程结束后需要选举出一个新的 Leader 服务器。因此 Zab 协议需要一个高效且可靠的 Leader 选举算法,从而确保能够快速选举出新的 Leader 。
Leader 选举算法不仅仅需要让 Leader 自己知道自己已经被选举为 Leader ,同时还需要让集群中的所有其他机器也能够快速感知到选举产生的新 Leader 服务器。
崩溃恢复主要包括两部分:Leader选举和数据恢复
Zab 协议如何保证数据一致性
假设两种异常情况:
1、一个事务在 Leader 上提交了,并且过半的 Folower 都响应 Ack 了,但是 Leader 在 Commit 消息发出之前挂了。
2、假设一个事务在 Leader 提出之后,Leader 挂了。
要确保如果发生上述两种情况,数据还能保持一致性,那么 Zab 协议选举算法必须满足以下要求:
Zab 协议崩溃恢复要求满足以下两个要求:
1)确保已经被 Leader 提交的 Proposal 必须最终被所有的 Follower 服务器提交。
2)确保丢弃已经被 Leader 提出的但是没有被提交的 Proposal。
根据上述要求
Zab协议需要保证选举出来的Leader需要满足以下条件:
1)新选举出来的 Leader 不能包含未提交的 Proposal。
即新选举的 Leader 必须都是已经提交了 Proposal 的 Follower 服务器节点。
2)新选举的 Leader 节点中含有最大的 zxid。
这样做的好处是可以避免 Leader 服务器检查 Proposal 的提交和丢弃工作。
Zab 如何数据同步
1)完成 Leader 选举后(新的 Leader 具有最高的zxid),在正式开始工作之前(接收事务请求,然后提出新的 Proposal),Leader 服务器会首先确认事务日志中的所有的 Proposal 是否已经被集群中过半的服务器 Commit。
2)Leader 服务器需要确保所有的 Follower 服务器能够接收到每一条事务的 Proposal ,并且能将所有已经提交的事务 Proposal 应用到内存数据中。等到 Follower 将所有尚未同步的事务 Proposal 都从 Leader 服务器上同步过啦并且应用到内存数据中以后,Leader 才会把该 Follower 加入到真正可用的 Follower 列表中。
Zab 数据同步过程中,如何处理需要丢弃的 Proposal
在 Zab 的事务编号 zxid 设计中,zxid是一个64位的数字。
其中低32位可以看成一个简单的单增计数器,针对客户端每一个事务请求,Leader 在产生新的 Proposal 事务时,都会对该计数器加1。而高32位则代表了 Leader 周期的 epoch 编号。
epoch 编号可以理解为当前集群所处的年代,或者周期。每次Leader变更之后都会在 epoch 的基础上加1,这样旧的 Leader 崩溃恢复之后,其他Follower 也不会听它的了,因为 Follower 只服从epoch最高的 Leader 命令。
每当选举产生一个新的 Leader ,就会从这个 Leader 服务器上取出本地事务日志充最大编号 Proposal 的 zxid,并从 zxid 中解析得到对应的 epoch 编号,然后再对其加1,之后该编号就作为新的 epoch 值,并将低32位数字归零,由0开始重新生成zxid。
Zab 协议通过 epoch 编号来区分 Leader 变化周期,能够有效避免不同的 Leader 错误的使用了相同的 zxid 编号提出了不一样的 Proposal 的异常情况。
基于以上策略
当一个包含了上一个 Leader 周期中尚未提交过的事务 Proposal 的服务器启动时,当这台机器加入集群中,以 Follower 角色连上 Leader 服务器后,Leader 服务器会根据自己服务器上最后提交的 Proposal 来和 Follower 服务器的 Proposal 进行比对,比对的结果肯定是 Leader 要求 Follower 进行一个回退操作,回退到一个确实已经被集群中过半机器 Commit 的最新 Proposal。
实现原理
Zab 节点有三种状态:
Following:当前节点是跟随者,服从 Leader 节点的命令。
Leading:当前节点是 Leader,负责协调事务。
Election/Looking:节点处于选举状态,正在寻找 Leader。
代码实现中,多了一种状态:Observing 状态
这是 Zookeeper 引入 Observer 之后加入的,Observer 不参与选举,是只读节点,跟 Zab 协议没有关系。
节点的持久状态:
history:当前节点接收到事务 Proposal 的Log
acceptedEpoch:Follower 已经接受的 Leader 更改 epoch 的 newEpoch 提议。
currentEpoch:当前所处的 Leader 年代
lastZxid:history 中最近接收到的Proposal 的 zxid(最大zxid)
Zab 的四个阶段
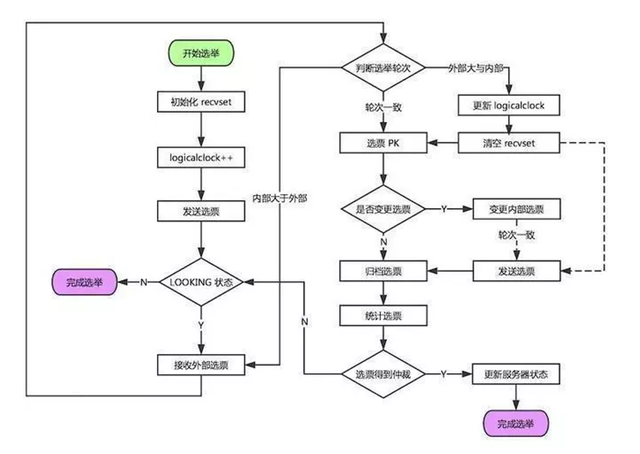
1、选举阶段(Leader Election)
节点在一开始都处于选举节点,只要有一个节点得到超过半数节点的票数,它就可以当选准 Leader,只有到达第三个阶段(也就是同步阶段),这个准 Leader 才会成为真正的 Leader。
Zookeeper 规定所有有效的投票都必须在同一个 轮次 中,每个服务器在开始新一轮投票时,都会对自己维护的 logicalClock 进行自增操作。
每个服务器在广播自己的选票前,会将自己的投票箱(recvset)清空。该投票箱记录了所受到的选票。
例如:Server_2 投票给 Server_3,Server_3 投票给 Server_1,则Server_1的投票箱为(2,3)、(3,1)、(1,1)。(每个服务器都会默认给自己投票)
前一个数字表示投票者,后一个数字表示被选举者。票箱中只会记录每一个投票者的最后一次投票记录,如果投票者更新自己的选票,则其他服务器收到该新选票后会在自己的票箱中更新该服务器的选票。
这一阶段的目的就是为了选出一个准 Leader ,然后进入下一个阶段。
协议并没有规定详细的选举算法,后面会提到实现中使用的 Fast Leader Election。
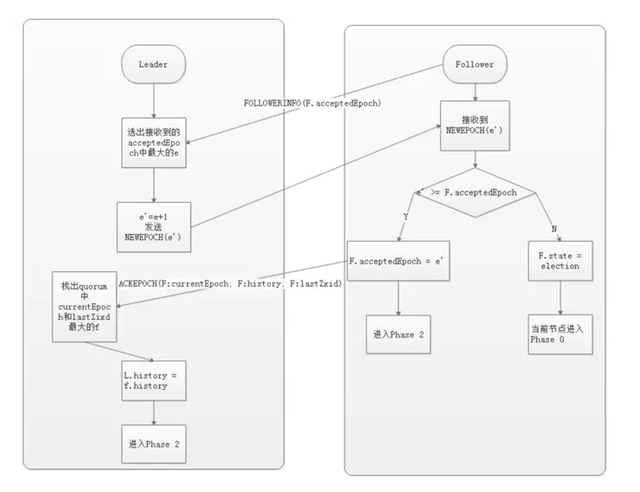
2、发现阶段(Descovery
在这个阶段,Followers 和上一轮选举出的准 Leader 进行通信,同步 Followers 最近接收的事务 Proposal 。
一个 Follower 只会连接一个 Leader,如果一个 Follower 节点认为另一个 Follower 节点,则会在尝试连接时被拒绝。被拒绝之后,该节点就会进入 Leader Election阶段。
这个阶段的主要目的是发现当前大多数节点接收的最新 Proposal,并且准 Leader 生成新的 epoch ,让 Followers 接收,更新它们的 acceptedEpoch。
3、同步阶段(Synchronization)
同步阶段主要是利用 Leader 前一阶段获得的最新 Proposal 历史,同步集群中所有的副本。
只有当 quorum(超过半数的节点) 都同步完成,准 Leader 才会成为真正的 Leader。Follower 只会接收 zxid 比自己 lastZxid 大的 Proposal。
4、广播阶段(Broadcast)
到了这个阶段,Zookeeper 集群才能正式对外提供事务服务,并且 Leader 可以进行消息广播。同时,如果有新的节点加入,还需要对新节点进行同步。
需要注意的是,Zab 提交事务并不像 2PC 一样需要全部 Follower 都 Ack,只需要得到 quorum(超过半数的节点)的Ack 就可以。
协议实现
协议的 Java 版本实现跟上面的定义略有不同,选举阶段使用的是 Fast Leader Election(FLE),它包含了步骤1的发现指责。因为FLE会选举拥有最新提议的历史节点作为 Leader,这样就省去了发现最新提议的步骤。
实际的实现将发现和同步阶段合并为 Recovery Phase(恢复阶段),所以,Zab 的实现实际上有三个阶段。
Zab协议三个阶段:
1)选举(Fast Leader Election)
2)恢复(Recovery Phase)
3)广播(Broadcast Phase)
Fast Leader Election(快速选举)
前面提到的 FLE 会选举拥有最新Proposal history (lastZxid最大)的节点作为 Leader,这样就省去了发现最新提议的步骤。这是基于拥有最新提议的节点也拥有最新的提交记录
成为 Leader 的条件:
1)选 epoch 最大的
2)若 epoch 相等,选 zxid 最大的
3)若 epoch 和 zxid 相等,选择 server_id 最大的(zoo.cfg中的myid)
节点在选举开始时,都默认投票给自己,当接收其他节点的选票时,会根据上面的Leader条件判断并且更改自己的选票,然后重新发送选票给其他节点。当有一个节点的得票超过半数,该节点会设置自己的状态为 Leading ,其他节点会设置自己的状态为 Following。
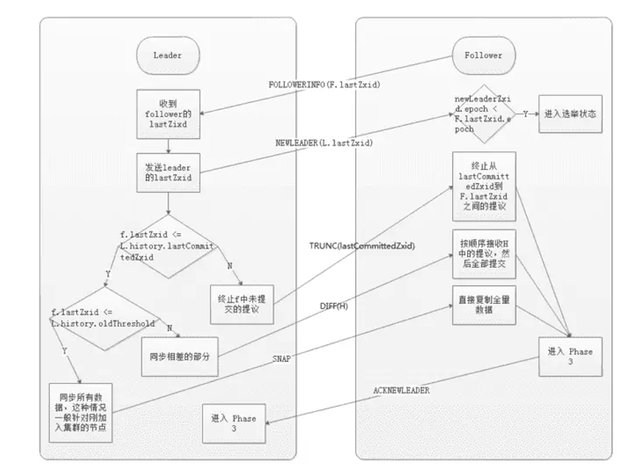
Recovery Phase(恢复阶段)
这一阶段 Follower 发送他们的 lastZxid 给 Leader,Leader 根据 lastZxid 决定如何同步数据。这里的实现跟前面的 Phase 2 有所不同:Follower 收到 TRUNC 指令会终止 L.lastCommitedZxid 之后的 Proposal ,收到 DIFF 指令会接收新的 Proposal。
history.lastCommitedZxid:最近被提交的 Proposal zxid
history.oldThreshold:被认为已经太旧的已经提交的 Proposal zxid






4、watch监控
zk作为一款成熟的分布式协调框架,订阅-发布功能是很重要的一个。所谓订阅发布功能,其实说白了就是观察者模式。观察者会订阅一些感兴趣的主题,然后这些主题一旦变化了,就会自动通知到这些观察者。
zk的订阅发布也就是watch机制,是一个轻量级的设计。因为它采用了一种推拉结合的模式。一旦服务端感知主题变了,那么只会发送一个事件类型和节点信息给关注的客户端,而不会包括具体的变更内容,所以事件本身是轻量级的,这就是所谓的“推”部分。然后,收到变更通知的客户端需要自己去拉变更的数据,这就是“拉”部分。
ZooKeeper是用来协调(同步)分布式进程的服务,提供了一个简单高性能的协调内核,用户可以在此之上构建更多复杂的分布式协调功能。
多个分布式进程通过ZooKeeper提供的 API 来操作共享的ZooKeeper内存数据对象ZNode来达成某种一致的行为或结果,这种模式本质上是基于状态共享的并发模型,与Java的多线程并发模型一致,他们的线程或进程都是“共享式内存通信”。Java没有直接提供某种响应式通知接口来监控某个对象状态的变化,只能要么浪费CPU时间毫无响应式的轮询重试,或基于Java提供的某种主动通知(Notif)机制(内置队列)来响应状态变化,但这种机制是需要循环阻塞调用。而ZooKeeper实现这些分布式进程的状态(ZNode的Data、Children)共享时,基于性能的考虑采用了类似的异步非阻塞的主动通知模式即Watch机制,使得分布式进程之间的“共享状态通信”更加实时高效,其实这也是ZooKeeper的主要任务决定的—协调。
所有的Zookeeper读操作,包括getData()、getChildren()和exists(),都有一个开关,可以在操作的同时再设置一个watch。在ZooKeeper中,Watch是一个一次性触发器,会在被设置watch的数据发生变化的时候,发送给设置watch的客户端。
watch的定义中有三个关键点:
一次性触发器
一个watch事件将会在数据发生变更时发送给客户端。例如,如果客户端执行操作getData(“/znode1″, true),而后/znode1 发生变更或是删除了,客户端都会得到一个/znode1 的watch事件。如果/znode1 再次发生变更,则在客户端没有设置新的watch的情况下,是不会再给这个客户端发送watch事件的。
发送给客户端
这就是说,一个事件会发送给客户端,但可能在操作成功的返回值到达发起变动的客户端之前,这个事件还没有送达watch的客户端。Watch是异步发送的。但ZooKeeper保证了一个顺序:一个客户端在收到watch事件之前,一定不会看到它设置过watch的值的变动。网络时延和其他因素可能会导致不同的客户端看到watch和更新返回值的时间不同。但关键点是,每个客户端所看到的每件事都是有顺序的。
被设置了watch的数据
这是指节点发生变动的不同方式。你可以认为ZooKeeper维护了两个watch列表:data watch和child watch。getData()和exists()设置data watch,而getChildren()设置child watch。或者,可以认为watch是根据返回值设置的。getData()和exists()返回节点本身的信息,而getChildren()返回子节点的列表。因此,setData()会触发znode上设置的data watch(如果set成功的话)。一个成功的?create() 操作会触发被创建的znode上的数据watch,以及其父节点上的child watch。而一个成功的?delete()操作将会同时触发一个znode的data watch和child watch(因为这样就没有子节点了),同时也会触发其父节点的child watch。
Watch由client连接上的ZooKeeper服务器在本地维护。这样可以减小设置、维护和分发watch的开销。当一个客户端连接到一个新的服务器上时,watch将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到watch的。而当client重新连接时,如果需要的话,所有先前注册过的watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch可能会丢失:对于一个未创建的znode的exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个watch事件可能会被丢失。
ZooKeeper对Watch提供了什么保障
对于watch,ZooKeeper提供了这些保障:
Watch与其他事件、其他watch以及异步回复都是有序的。ZooKeeper客户端库保证所有事件都会按顺序分发;客户端会保障它在看到相应的znode的新数据之前接收到watch事件;从ZooKeeper接收到的watch事件顺序一定和ZooKeeper服务所看到的事件顺序是一致的。
关于Watch的一些值得注意的事情
Watch是一次性触发器,如果你得到了一个watch事件,而你希望在以后发生变更时继续得到通知,你应该再设置一个watch。
因为watch是一次性触发器,而获得事件再发送一个新的设置watch的请求这一过程会有延时,所以你无法确保你看到了所有发生在ZooKeeper上的一个节点上的事件。所以请处理好在这个时间窗口中可能会发生多次znode变更的这种情况。(你可以不处理,但至少请认识到这一点)。
一个watch对象或一个函数/上下文对,为一个事件只会被通知一次。比如,如果同一个watch对象在同一个文件上分别通过exists和getData注册了两次,而这个文件之后被删除了,这时这个watch对象将只会收到一次该文件的deletion通知。
当你从一个服务器上断开时(比如服务器出故障了),在再次连接上之前,你将无法获得任何watch。请使用这些会话事件来进入安全模式:在disconnected状态下你将不会收到事件,所以你的程序在此期间应该谨慎行事。
5、分布式锁
原文链接:https://www.cnblogs.com/darling2047/p/16870751.html
一、分布式锁的通用实现思路
分布式锁的实现思路;
- 首先,需要保证唯一性,即某一时点只能有一个线程访问某一资源;比方说待办短信通知功能,每天早上九点短信提醒所有工单的处理人处理工单,假设服务部署了20个容器,那么早上九点的时候会有20个线程启动准备发送短信,此时我们只能让一个线程执行短信发送,否则用户会收到20条相同的短信;
- 其次,需要考虑下何时应该释放锁?这又分三种情况,一是拿到锁的线程正常结束,另一种是获取锁的线程异常退出,还有种是获取锁的线程一直阻塞;第一种情况直接释放即可,第二种情况可以通过定义下锁的过期时间然后通过定时任务去释放锁;zk的话直接通过临时节点即可;最后一种阻塞的情况也可以通过定时任务来释放,但是需要根据业务来综合判断,如果业务本身就是长时间耗时的操作那么锁的过期时间就得设置的久一点
- 最后,当拿到锁的线程释放锁的时候,如何通知其他线程可以抢锁了呢
这里简单介绍两种解决方案,一种是所有需要锁的线程主动轮询,固定时间去访问下看锁是否释放,但是这种方案无端增加服务器压力并且时效性无法保证;另一种就是zk的watch,监听锁所在的目录,一有变化立马得到通知二、ZK实现分布式锁的思路
- zk通过每个线程在同一父目录下创建临时有序节点,然后通过比较节点的id大小来实现分布式锁功能;再通过zk的watch机制实时获取节点的状态,如果被删除立即重新争抢锁;具体流程见线图:
提示:需要关注下图里判断自身不是最小节点时的监听情况,为什么不监听父节点?原因图里已有描述,这里就不再赘述
三、ZK实现分布式锁的编码实现
1、核心工具类实现
通过不断的调试,我封装了一个
ZkLockHelper类,里面封装了上锁和释放锁的方法,为了方便我将zk的一些监听和回调机智也融合到一起了,并没有抽出来,下面贴上该类的全部代码package com.darling.service.zookeeper.lock; import lombok.Data; import lombok.extern.slf4j.Slf4j; import org.apache.zookeeper.*; import org.apache.zookeeper.data.Stat; import org.junit.platform.commons.util.StringUtils; import java.util.Collections; import java.util.List; import java.util.Objects; import java.util.concurrent.CountDownLatch; /** * @description: * @author: dll * @date: Created in 2022/11/4 8:41 * @version: * @modified By: */ @Data @Slf4j public class ZkLockHelper implements AsyncCallback.StringCallback, AsyncCallback.StatCallback,Watcher, AsyncCallback.ChildrenCallback { private final String lockPath = "/lockItem"; ZooKeeper zkClient; String threadName; CountDownLatch cd = new CountDownLatch(1); private String pathName; /** * 上锁 */ public void tryLock() { try { log.info("线程:{}正在创建节点",threadName); zkClient.create(lockPath,(threadName).getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL,this,"AAA"); log.info("线程:{}正在阻塞......",threadName); // 由于上面是异步创建所以这里需要阻塞住当前线程 cd.await(); } catch (InterruptedException e) { e.printStackTrace(); } } /** * 释放锁 */ public void unLock() { try { zkClient.delete(pathName,-1); System.out.println(threadName + " 工作结束...."); } catch (Exception e) { e.printStackTrace(); } } /** * create方法的回调,创建成功后在此处获取/DCSLock的子目录,比较节点ID是否最小,是则拿到锁。。。 * @param rc 状态码 * @param path create方法的path入参 * @param ctx create方法的上下文入参 * @param name 创建成功的临时有序节点的名称,即在path的后面加上了zk维护的自增ID; * 注意如果创建的不是有序节点,那么此处的name和path的内容一致 */ @Override public void processResult(int rc, String path, Object ctx, String name) { log.info(">>>>>>>>>>>>>>>>>processResult,rx:{},path:{},ctx:{},name:{}",rc,path,ctx.toString(),name); if (StringUtils.isNotBlank(name)) { try { pathName = name ; // 此处path需注意要写/ zkClient.getChildren("/", false,this,"123"); // List<String> children = zkClient.getChildren("/", false); // log.info(">>>>>threadName:{},children:{}",threadName,children); // // 给children排序 // Collections.sort(children); // int i = children.indexOf(pathName.substring(1)); // // 判断自身是否第一个 // if (Objects.equals(i,0)) { // // 是第一个则表示抢到了锁 // log.info("线程{}抢到了锁",threadName); // cd.countDown(); // }else { // // 表示没抢到锁 // log.info("线程{}抢锁失败,重新注册监听器",threadName); // zkClient.exists("/"+children.get(i-1),this,this,"AAA"); // } } catch (Exception e) { e.printStackTrace(); } } } /** * exists方法的回调,此处暂不做处理 * @param rc * @param path * @param ctx * @param stat */ @Override public void processResult(int rc, String path, Object ctx, Stat stat) { } /** * exists的watch监听 * @param event */ @Override public void process(WatchedEvent event) { //如果第一个线程锁释放了,等价于第一个线程删除了节点,此时只有第二个线程会监控的到 switch (event.getType()) { case None: break; case NodeCreated: break; case NodeDeleted: zkClient.getChildren("/", false,this,"123"); // // 此处path需注意要写"/" // List<String> children = null; // try { // children = zkClient.getChildren("/", false); // } catch (KeeperException e) { // e.printStackTrace(); // } catch (InterruptedException e) { // e.printStackTrace(); // } // log.info(">>>>>threadName:{},children:{}",threadName,children); // // 给children排序 // Collections.sort(children); // int i = children.indexOf(pathName.substring(1)); // // 判断自身是否第一个 // if (Objects.equals(i,0)) { // // 是第一个则表示抢到了锁 // log.info("线程{}抢到了锁",threadName); // cd.countDown(); // }else { // /** // * 表示没抢到锁;需要判断前置节点存不存在,其实这里并不是特别关心前置节点存不存在,所以其回调可以不处理; // * 但是这里关注的前置节点的监听,当前置节点监听到被删除时就是其他线程抢锁之时 // */ // zkClient.exists("/"+children.get(i-1),this,this,"AAA"); // } break; case NodeDataChanged: break; case NodeChildrenChanged: break; } } /** * getChildren方法的回调 * @param rc * @param path * @param ctx * @param children */ @Override public void processResult(int rc, String path, Object ctx, List<String> children) { try { log.info(">>>>>threadName:{},children:{}", threadName, children); if (Objects.isNull(children)) { return; } // 给children排序 Collections.sort(children); int i = children.indexOf(pathName.substring(1)); // 判断自身是否第一个 if (Objects.equals(i, 0)) { // 是第一个则表示抢到了锁 log.info("线程{}抢到了锁", threadName); cd.countDown(); } else { // 表示没抢到锁 log.info("线程{}抢锁失败,重新注册监听器", threadName); /** * 表示没抢到锁;需要判断前置节点存不存在,其实这里并不是特别关心前置节点存不存在,所以其回调可以不处理; * 但是这里关注的前置节点的监听,当前置节点监听到被删除时就是其他线程抢锁之时 */ zkClient.exists("/" + children.get(i - 1), this, this, "AAA"); } } catch (Exception e) { e.printStackTrace(); } } }提示:代码中注释的代码块可以关注下,原本是直接阻塞式编程,将获取所有子节点并释放锁的操作直接写在getChildren方法的回调里,后来发现当节点被删除时我们还要重新抢锁,那么代码就冗余了,于是结合响应式编程的思想,将这段核心代码放到
getChildren方法的回调里,这样代码简洁了并且可以让业务更只关注于getChildren这件事了2、测试代码编写
线程安全问题复现
package com.darling.service.zookeeper.lock; import lombok.SneakyThrows; import lombok.extern.slf4j.Slf4j; import org.junit.Test; /** * @description: 开启是个线程给i做递减操作,未加锁的情况下会有线程安全问题 * @author: dll * @date: Created in 2022/11/8 8:32 * @version: * @modified By: */ @Slf4j public class ZkLockTest02 { private int i = 10; @Test public void test() throws InterruptedException { for (int n = 0; n < 10; n++) { new Thread(new Runnable() { @SneakyThrows @Override public void run() { Thread.sleep(100); incre(); } }).start(); } Thread.sleep(5000); log.info("i = {}",i); } /** * i递减 线程不安全 */ public void incre(){ // i.incrementAndGet(); log.info("当前线程:{},i = {}",Thread.currentThread().getName(),i--); } }
- 上面代码运行结果如下:
使用上面封装的
ZkLockHelper实现的分布式锁package com.darling.service.zookeeper.lock; import lombok.SneakyThrows; import lombok.extern.slf4j.Slf4j; import org.apache.zookeeper.ZooKeeper; import org.junit.After; import org.junit.Before; import org.junit.Test; /** * @description: 使用zk实现的分布式锁解决线程安全问题 * @author: dll * @date: Created in 2022/11/8 8:32 * @version: * @modified By: */ @Slf4j public class ZkLockTest03 { ZooKeeper zkClient; @Before public void conn (){ zkClient = ZkUtil.getZkClient(); } @After public void close (){ try { zkClient.close(); } catch (InterruptedException e) { e.printStackTrace(); } } private int i = 10; @Test public void test() throws InterruptedException { for (int n = 0; n < 10; n++) { new Thread(new Runnable() { @SneakyThrows @Override public void run() { Thread.sleep(100); ZkLockHelper zkHelper = new ZkLockHelper(); // 这里给zkHelper设置threadName是为了后续调试的时候日志打印,便于观察存在的问题 String threadName = Thread.currentThread().getName(); zkHelper.setThreadName(threadName); zkHelper.setZkClient(zkClient); // tryLock上锁 zkHelper.tryLock(); incre(); log.info("线程{}正在执行业务代码...",threadName); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } // 释放锁 zkHelper.unLock(); } }).start(); } while (true) { } } /** * i递减 线程不安全 */ public void incre(){ // i.incrementAndGet(); log.info("☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆当前线程:{},i = {}",Thread.currentThread().getName(),i--); } }
- 运行结果如下:
由于日志中掺杂着zk的日志所有此处并未截全,但是也能看到i是在按规律递减的,不会出现通过线程拿到相同值的情况
四、zk实现分布式锁的优缺点
优点
- 集群部署不存在单点故障问题
- 统一视图
zk集群每个节点对外提供的数据是一致的,数据一致性有所报障- 临时有序节点
zk提供临时有序节点,这样当客户端失去连接时会自动释放锁,不用像其他方案一样当拿到锁的实例服务不可用时,需要定时任务去删除锁;临时节点的特性就是当客户端失去连接会自动删除- watch能力加持
当获取不到锁时,无需客户端定期轮询争抢,只需watch前一节点即可,当有变化时会及时通知,比普通方案即及时又高效;注意这里最好只watch前一节点,如果watch整个父目录的话,当客户端并发较大时会不断有请求进出zk,给zk性能带来压力缺点
- 与单机版redis比较的话性能肯定较差,但是当客户端集群足够庞大且业务量足够多时肯定还是集群更加稳定
- 极端情况下还是会出现多个线程抢到同一把锁的问题;假设某个线程拿到锁后还没执行业务代码就进入长时间的垃圾收集STW了,此时与zk的连接也会消失;然后此时别的线程的watch会被触发从而抢到锁去执行了,但是当stw的线程恢复过来时继续执行自身的业务代码,此时就会出现不一致的问题了;当然,个人认为这种设想太过极端了,毕竟如果stw时间过长肯定会影响整个集群的性能的,所以我感觉可以不必考虑,真的要解决那么再加上mysql乐观锁吧;



干我们这行,啥时候懈怠,就意味着长进的停止,长进的停止就意味着被淘汰,只能往前冲,直到凤凰涅槃的一天!
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数