利用VGG16网络模块进行迁移学习,实操(附源码)_vgg16迁移学习-程序员宅基地
什么是迁移学习
当数据集没有大到足以训练整个CNN网络时,通常可以对预训练好的imageNet网络(如VGG16,Inception-v3等)进行调整以适应新任务。
通常来说,迁移学习有两种类型:
- 特征提取
- 微调(fine-tuning)
第一种迁移学习是将预训练的网络视为一个任意特征提取器。图片经过输入层,然后前向传播,最后在指定层停止,通过提取该指定层的输出结果作为输入图片的特征。
第二种迁移学习需要更改预训练模型的结构,具体方法为移除全连接层,添加一组自定义的全连接层来进行新的分类(不唯一)。
本文通过对第二种类型的迁移学习进行项目实操,加深读者理解。
预备知识
1. keras内置的VGG-16网络模块
先简单了解下VGG16网络结构(图1),具体包括5个卷积组和3个全连接层。5个卷积组分别有2,2,3,3,3个卷积层,因此,共有2+2+3+3+3+3=16层。

本文将通过移除顶层的3个全连接层,添加自定义全连接层来进行Food-5K数据集的分类训练。
通过如下代码预览去除全连接层后的网络结构。当模型初始化的时候权重会自动下载,这里采用的是在imageNet数据集上预训练好的权重。
from keras.applications import VGG16
model=VGG16(weights='imagenet',include_top=False)
model.summary()输出结果如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, None, None, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, None, None, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, None, None, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, None, None, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, None, None, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, None, None, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, None, None, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, None, None, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, None, None, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, None, None, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, None, None, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, None, None, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, None, None, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, None, None, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
2. Food-5K数据集

Food-5K数据集包括training,validation,evaluation三个子包,分别有3000,1000,1000张图片,食物和非食物均占一半(图2)。
项目实践
1. 项目结构
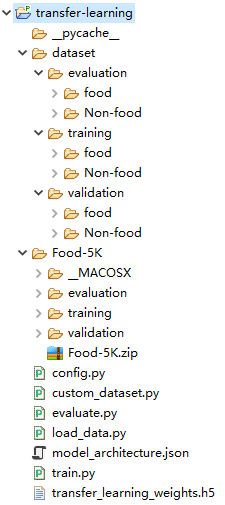
- dataset是我们自定义的数据集,初始文件夹为空,
- Food-5K为原始数据集,
- config.py完成一些基本的配置,
- custom_dataset.py文件可以获得自定义的dataset数据集,
- load_data.py返回我们所需的数据格式(images,labels)
- train.py完成迁移学习的训练,
- evaluate.py得到模型在测试集上的准确率,
- model.architecture.json为保存的模型结构(不含权重),
- transfer_learning_weights.h5为VGG16微调并重新训练后的模型权重。
2. config 文件
ORIG_DATA_PATH='Food-5K' #原始文件夹
BASE_PATH='dataset' #自定义文件夹
TRAIN='training' #训练集
VALID='validation' #验证集
TEST='evaluation' #测试集
CLASSES=['Non-food','food'] #标签类别3. 自定义数据集
import os
import config
import shutil
for split in (config.TRAIN,config.VALID,config.TEST):
print('[INFO] processing {} split:'.format(split))
imagePaths=os.listdir(os.path.join(config.ORIG_DATA_PATH,split))
for ele in imagePaths:
if not ele.endswith('.jpg'):
imagePaths.remove(ele)
for imagePath in imagePaths:
label=config.CLASSES[int(imagePath.split('_')[0])]
dst=os.path.join(config.BASE_PATH,split,label)
if not os.path.exists(dst):
os.makedirs(dst)
#复制图片
shutil.copy2(os.path.join(config.ORIG_DATA_PATH,config.TRAIN,imagePath), os.path.join(dst,imagePath))
print('[INFO] All is done' )分别完成Food-5K文件夹中三个子包的食物和非食物分类。
4. 获得训练、验证、测试所用的数据结构
from config import BASE_PATH
from imutils import paths
import numpy as np
import random
import cv2
import os
#定义图像载入函数
def load_images(x):
image=cv2.imread(x)
image=cv2.resize(image,(224,224))
return image
#获得模型用数据结构
def load_data_split(datapath):
imagePaths=list(paths.list_images(os.path.join(BASE_PATH,datapath)))
random.shuffle(imagePaths)
labels=[int(i.split('\\')[-1][0]) for i in imagePaths]
images=np.array([load_images(i) for i in imagePaths])
return (images,labels)5. VGG16网络的微调及训练
from keras.layers import Flatten,Dense,Dropout,Input
from keras.applications import VGG16
from load_data import load_data_split
from keras.optimizers import SGD
from keras.models import Model
from keras.utils import np_utils
import config
print('[INFO] loading dataset......')
(x_train,y_train)=load_data_split(config.TRAIN)
(x_valid,y_valid)=load_data_split(config.VALID)
y_train=np_utils.to_categorical(y_train,2)
y_valid=np_utils.to_categorical(y_valid,2)
print('[INFO] initializing model......')
base_model=VGG16(weights='imagenet',include_top=False,input_tensor=Input(shape=(224,224,3)))
#微调
head_model=base_model.output
head_model=Flatten(name="flatten")(head_model)
head_model = Dense(512, activation="relu")(head_model)
head_model = Dropout(0.5)(head_model)
head_model=Dense(64,activation='relu')(head_model)
head_model = Dense(len(config.CLASSES), activation="softmax")(head_model)
model=Model(base_model.input,head_model)
#冻结前面的5个卷积组,只训练自定义的全连接层
for layer in base_model.layers:
layer.trainable=False
print('[INFO] compiling model')
sgd=SGD(lr=0.0001,momentum=0.9)
model.compile(loss='categorical_crossentropy',metrics=['accuracy'],optimizer=sgd)
print('[INFO] training model')
model.fit(x_train, y_train, batch_size=32, epochs=2, validation_data=(x_valid,y_valid))
print('[INFO] saving model and weights')
#保存模型(不含权重)
model_json=model.to_json()
open('model_architecture.json','w').write(model_json)
#保存权重
model.save_weights('transfer_learning_weights.h5', overwrite=True)冻结去除了顶层的VGG16网络的权重参数,只训练自定义的全连接层。最后将新的模型和权重分别保存。
经过两轮的训练,训练集上准确率就已经达到了96.13%,验证集上99.2%。结果如下:
- loss: 0.4639 - acc: 0.9613 - val_loss: 0.1036 - val_acc: 0.9920
6.测试集上的准确率
from keras.models import model_from_json
from keras.utils import np_utils
from load_data import load_data_split
from keras.optimizers import SGD
import config
#载入模型和权重
loaded_model_json = open('model_architecture.json', 'r').read()
model=model_from_json(loaded_model_json)
model.load_weights('transfer_learning_weights.h5')
print('[INFO] loading dataset...')
(x_test,y_test)=load_data_split(config.TEST)
y_test=np_utils.to_categorical(y_test,2)
sgd=SGD(lr=0.0001,momentum=0.9)
model.compile(loss='categorical_crossentropy',metrics=['accuracy'],optimizer=sgd)
print('[INFO] evaluating...')
score=model.evaluate(x_test,y_test,batch_size=32)
print('test score: {}'.format(score[0]))
print('test accuracy:{}'.format(score[1]))输出结果如下:
test score: 0.08451384264268018
test accuracy:0.992
可以发现通过迁移学习,经过两轮的训练后在测试集上同样达到99.2%的准确率。
PS:扫码关注公众号,回复“food-5k”可以获取数据集,回复“vgg16”即可获得完整项目

智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf