Hadoop案例(十)WordCount_hadoop的wordcount案例-程序员宅基地
WordCount案例
需求1:统计一堆文件中单词出现的个数(WordCount案例)
0)需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
1)数据准备:Hello.txt
hello world
dog fish
hadoop
spark
hello world
dog fish
hadoop
spark
hello world
dog fish
hadoop
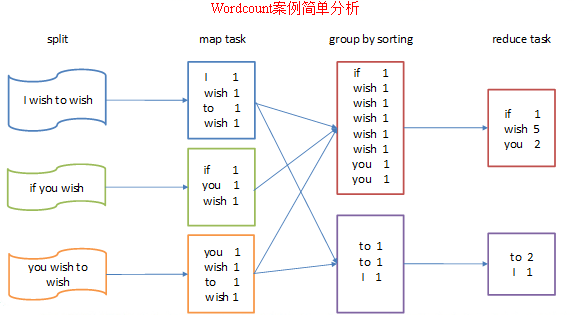
spark2)分析
按照mapreduce编程规范,分别编写Mapper,Reducer,Driver。

3)编写程序
(1)定义一个mapper类
package com.xyg.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* KEYIN:默认情况下,是mr框架所读到的一行文本的起始偏移量,Long;
* 在hadoop中有自己的更精简的序列化接口,所以不直接用Long,而是用LongWritable
* VALUEIN:默认情况下,是mr框架所读到的一行文本内容,String;此处用Text
* KEYOUT:是用户自定义逻辑处理完成之后输出数据中的key,在此处是单词,String;此处用Text
* VALUEOUT,是用户自定义逻辑处理完成之后输出数据中的value,在此处是单词次数,Integer,此处用IntWritable
* @author Administrator
*/
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
/**
* map阶段的业务逻辑就写在自定义的map()方法中
* maptask会对每一行输入数据调用一次我们自定义的map()方法
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 将maptask传给我们的文本内容先转换成String
String line = value.toString();
// 2 根据空格将这一行切分成单词
String[] words = line.split(" ");
// 3 将单词输出为<单词,1>
for(String word:words){
// 将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reducetask中
context.write(new Text(word), new IntWritable(1));
}
}
}(2)定义一个reducer类
package com.xyg.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* KEYIN , VALUEIN 对应mapper输出的KEYOUT, VALUEOUT类型
* KEYOUT,VALUEOUT 对应自定义reduce逻辑处理结果的输出数据类型 KEYOUT是单词 VALUEOUT是总次数
*/
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* key,是一组相同单词kv对的key
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
// 1 汇总各个key的个数
for(IntWritable value:values){
count +=value.get();
}
// 2输出该key的总次数
context.write(key, new IntWritable(count));
}
}(3)定义一个主类,用来描述job并提交job
package com.xyg.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 相当于一个yarn集群的客户端,
* 需要在此封装我们的mr程序相关运行参数,指定jar包
* 最后提交给yarn
* @author Administrator
*/
public class WordcountDriver {
public static void main(String[] args) throws Exception {
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
// 8 配置提交到yarn上运行,windows和Linux变量不一致
// configuration.set("mapreduce.framework.name", "yarn");
// configuration.set("yarn.resourcemanager.hostname", "node22");
Job job = Job.getInstance(configuration);
// 6 指定本程序的jar包所在的本地路径
// job.setJar("/home/admin/wc.jar");
job.setJarByClass(WordcountDriver.class);
// 2 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 3 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 4 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 5 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
// job.submit();
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}4)集群上测试
(1)将程序打成jar包,然后拷贝到hadoop集群中。
(2)启动hadoop集群
(3)执行wordcount程序
[admin@node21 module]$ hadoop jar wc.jar com.xyg.wordcount.WordcountDriver /user/admin/input /user/admin/output
5)本地测试
(1)在windows环境上配置HADOOP_HOME环境变量。
(2)在eclipse上运行程序
(3)注意:如果eclipse打印不出日志,在控制台上只显示
1.log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
2.log4j:WARN Please initialize the log4j system properly.
3.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.需要在项目的src目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n 需求2:把单词按照ASCII码奇偶分区(Partitioner)
0)分析

1)自定义分区
package com.xyg.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class WordCountPartitioner extends Partitioner<Text, IntWritable>{
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
// 1 获取单词key
String firWord = key.toString().substring(0, 1);
char[] charArray = firWord.toCharArray();
int result = charArray[0];
// int result = key.toString().charAt(0);
// 2 根据奇数偶数分区
if (result % 2 == 0) {
return 0;
}else {
return 1;
}
}
}2)在驱动中配置加载分区,设置reducetask个数
job.setPartitionerClass(WordCountPartitioner.class);
job.setNumReduceTasks(2);需求3:对每一个maptask的输出局部汇总(Combiner)
0)需求:统计过程中对每一个maptask的输出进行局部汇总,以减小网络传输量即采用Combiner功能。

1)数据准备:hello,txt
方案一
1)增加一个WordcountCombiner类继承Reducer
package com.xyg.mr.combiner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable v :values){
count += v.get();
}
context.write(key, new IntWritable(count));
}
}2)在WordcountDriver驱动类中指定combiner
//9 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordcountCombiner.class);方案二
1)将WordcountReducer作为combiner在WordcountDriver驱动类中指定
//9 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordcountReducer.class);运行程序

需求4:大量小文件的切片优化(CombineTextInputFormat)
0)需求:将输入的大量小文件合并成一个切片统一处理。
1)输入数据:准备5个小文件
2)实现过程
(1)不做任何处理,运行需求1中的wordcount程序,观察切片个数为5

(2)在WordcountDriver中增加如下代码,运行程序,并观察运行的切片个数为1
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);// 2m
智能推荐
Linux(Ubuntu)中对音频批量转换格式MP3转WAV/PCM转WAV_ubuntu批量mp3转wav命令-程序员宅基地
文章浏览阅读2.2k次。1、批量将MP3格式音频转换成WAV格式利用ffmpeg工具,统一处理成16bit ,小端编码,单通道,16KHZ采样率的wav音频格式。首先新建Mp3ToWav.sh 文件以路径/home/XXX下音频处理为例,编辑如下代码段:#!/bin/bashfolder=/home/XXXfor file in $(find "$folder" -type f -iname "*.mp3..._ubuntu批量mp3转wav命令
用python+graphviz/networkx画目录结构树状图_networkx画树状图-程序员宅基地
文章浏览阅读1.3w次,点赞2次,收藏22次。想着用python绘制某目录的树状图,一开始想到了用grapgviz,因为去年离职的时候整理文档,用graphviz画过代码调用结构图。graphviz有一门自己的语言DOT,dot很简单,加点加边设置属性就这点东西,而且有python接口。我在ubuntu下,先要安装graphviz软件,官网有deb包,然后python安装pygraphviz模块。目标功能是输入一个路径,输出该路径下的_networkx画树状图
【绿色求索T1设备资产通1.5单机版】适用于资产密集型企业管理_求索t1设备资产通系统(单机版)注册码-程序员宅基地
文章浏览阅读899次。绿色求索T1设备资产通 1.5 单机版 [企业管理高价值设备资产的使用情况]下载软件大小:5.56MB软件语言:简体中文软件类别:软件授权:免费软件更新时间:2013-08-03 07:44:00应用平台:Win2K,WinXP,Win2003,Vista,Win7绿色软件下么官方地址:系统之家官网求索T1设备资产通 1.5 单机版 _求索t1设备资产通系统(单机版)注册码
王桂林C语言从放弃到入门课程-程序员宅基地
文章浏览阅读195次。课程目标16天,每天6节课,每节40分钟课堂实录,带你征服C语言,让所有学过和没有学过C语言的人,或是正准备学习C语言的人,找到学习C语言的不二法门。适用人群所有学过和没有学过C语言的人,或是正准备学习C语言的人!
xml实体注入问题_xml注入 内容注入-程序员宅基地
文章浏览阅读618次。xml实体注入问题 https://www.owasp.org/index.php/XML_External_Entity_(XXE)_Prevention_Cheat_Sheet#SAXBuilder_xml注入 内容注入
CRM是否有效?可通过这些办法判断!_crm如何判断会员唯一性-程序员宅基地
文章浏览阅读204次。CRM就是关于客户与公司销售团队之间的客户关系管理,它是一个销售人员管理工具。作为一个工具型产品,CRM能减少更多的人为错误,提高工作效率,从而达到更好的营收。如果在使用CRM期间出现以下现象:不能从不同潜在客户来源中获取潜在客户,不能将潜在客户转化为销售订单,不能提供合适的销售渠道,不能提高销售人员的工作效率。说明你使用的CRM存在问题。如何判断CRM是否有效?为了检查CRM的有效性,销售人员可以对捕获到的潜在客户和具体需求进行跟踪。销售人员能够判断这个潜在客户是否值得做进一步的跟进,或者是否应该放_crm如何判断会员唯一性
随便推点
Algorithm Gossip (20) 阿姆斯壮数_actan算法 c++-程序员宅基地
文章浏览阅读543次。Algorithm Gossip: 阿姆斯壮数_actan算法 c++
php中大量数据如何优化,如何对PHP导出的海量数据进行优化-程序员宅基地
文章浏览阅读429次。本篇文章的主要主要讲述的是对PHP导出的海量数据进行优化,具有一定的参考价值,有需要的朋友可以看看。导出数据量很大的情况下,生成excel的内存需求非常庞大,服务器吃不消,这个时候考虑生成csv来解决问题,cvs读写性能比excel高。测试表student 数据(大家可以脚本插入300多万测数据。这里只给个简单的示例了)SET NAMES utf8mb4;SET FOREIGN_KEY_CHECK..._php大数据优化
有道云笔记怎么保存html,有道云笔记如何保存网页 有道笔记保存页面教程-程序员宅基地
文章浏览阅读905次。有道云笔记如何保存网页 有道笔记保存页面教程网页剪报功能支持哪些浏览器?IE,360安全,Firefox,Chrome,搜狗,遨游等主流浏览器。不能收藏网页,原因是没有安装浏览器剪报插件:②点击如下图部门网页剪报”立即体验“。③在弹出”有道云笔记网页剪报“网页对话框,点击如下图”添加到浏览器“。④然后在弹出”确认新增扩展程序“网页对话框中,点击”添加“即可。⑤现在,在浏览器右上角多了一个标记,只需..._有道云笔记装扩展
EasyUI 取得选中行数据-程序员宅基地
文章浏览阅读63次。转自:http://www.jeasyui.net/tutorial/23.html本实例演示如何取得选中行数据。数据网格(datagrid)组件包含两种方法来检索选中行数据:getSelected:取得第一个选中行数据,如果没有选中行,则返回 null,否则返回记录。getSelections:取得所有选中行数据,返回元素记录的数组数据。创建数据网格(DataGrid)<..._easyui 获取table选中的一行的值
云上武功秘籍(三)华为云上部署金蝶EAS Cloud_云上部署含带宽-程序员宅基地
文章浏览阅读1k次。每天琐事缠身,查错、维护、开接口?——不,你可以更加富有创造力!假期千里迢迢飞回公司机房处理一个小故障?——不,你可以更加自由高效!如果这就是你的写照,那为什么不选择上云呢?如果要上云,那为什么不选择华为云呢?云上秘籍第三弹——超详细、超全面的金蝶EAS Cloud部署教程来啦!负载均衡?WEB安全?一篇文章全部搞定!最后,请大家相信我们华为云生态 ISV团队的诚意和实力,谢谢!_云上部署含带宽
京东OLAP实践之路-程序员宅基地
文章浏览阅读640次。导读:本文主要介绍京东在构建OLAP从无到有各环节考虑的重点,由需求场景出发,剖析当前存在的问题,并提供解决方案,最后介绍OLAP的发展过程。▌需求场景1. 京东数据入口① 业务数据:订单..._京东 风控flink实践之路