卷积中的attention map理解及可视化-程序员宅基地
技术标签: 网络架构
引用
Woo S , Park J , Lee J Y , et al. CBAM: Convolutional Block Attention Module[J]. 2018.
下载
https://arxiv.org/pdf/1807.06521.pdf
转载于:
https://www.jianshu.com/p/4fac94eaca91
https://blog.csdn.net/weixin_36541072/article/details/79126225摘要
论文提出了Convolutional Block Attention Module(CBAM),这是一种为卷积神将网络设计的,简单有效的注意力模块(Attention Module)。对于卷积神经网络生成的feature map,CBAM从通道和空间两个维度计算feature map的attention map,然后将attention map与输入的feature map相乘来进行特征的自适应学习。CBAM是一个轻量的通用模块,可以将其融入到各种卷积神经网络中进行端到端的训练。
主要思想
对于一个中间层的feature map:,CBAM将会顺序推理出1维的channel attention map
以及2维的spatial attention map
,整个过程如下所示:
其中为element-wise multiplication,首先将channel attention map与输入的feature map相乘得到
,之后计算
的spatial attention map,并将两者相乘得到最终的输出
。下图为CBAM的示意图:

CBAM的结构图
Channel attention module
feature map 的每个channel都被视为一个feature detector,channel attention主要关注于输入图片中什么(what)是有意义的。为了高效地计算channel attention,论文使用最大池化和平均池化对feature map在空间维度上进行压缩,得到两个不同的空间背景描述:和
。使用由MLP组成的共享网络对这两个不同的空间背景描述进行计算得到channel attention map:
。计算过程如下:
其中,
,
后使用了Relu作为激活函数。
Spatial attention module.
与channel attention不同,spatial attention主要关注于位置信息(where)。为了计算spatial attention,论文首先在channel的维度上使用最大池化和平均池化得到两个不同的特征描述和
,然后使用concatenation将两个特征描述合并,并使用卷积操作生成spatial attention map
。计算过程如下:
其中,表示7*7的卷积层
下图为channel attention和spatial attention的示意图:

(上)channel attention module;(下)spatial attention module
简单了说:通过深度学习的方法,自动判defect类型。并画出attention map。找到其中的defect位置,就可以不用Rcnn等方法去标记bbox。
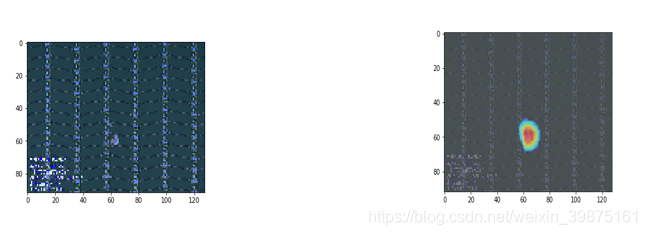
代码实现tensorflow 1.9
"""
@Time : 2018/10/19
@Author : Li YongHong
@Email : [email protected]
@File : test.py
"""
import tensorflow as tf
import numpy as np
slim = tf.contrib.slim
def combined_static_and_dynamic_shape(tensor):
"""Returns a list containing static and dynamic values for the dimensions.
Returns a list of static and dynamic values for shape dimensions. This is
useful to preserve static shapes when available in reshape operation.
Args:
tensor: A tensor of any type.
Returns:
A list of size tensor.shape.ndims containing integers or a scalar tensor.
"""
static_tensor_shape = tensor.shape.as_list()
dynamic_tensor_shape = tf.shape(tensor)
combined_shape = []
for index, dim in enumerate(static_tensor_shape):
if dim is not None:
combined_shape.append(dim)
else:
combined_shape.append(dynamic_tensor_shape[index])
return combined_shape
def convolutional_block_attention_module(feature_map, index, inner_units_ratio=0.5):
"""
CBAM: convolution block attention module, which is described in "CBAM: Convolutional Block Attention Module"
Architecture : "https://arxiv.org/pdf/1807.06521.pdf"
If you want to use this module, just plug this module into your network
:param feature_map : input feature map
:param index : the index of convolution block attention module
:param inner_units_ratio: output units number of fully connected layer: inner_units_ratio*feature_map_channel
:return:feature map with channel and spatial attention
"""
with tf.variable_scope("cbam_%s" % (index)):
feature_map_shape = combined_static_and_dynamic_shape(feature_map)
# channel attention
channel_avg_weights = tf.nn.avg_pool(
value=feature_map,
ksize=[1, feature_map_shape[1], feature_map_shape[2], 1],
strides=[1, 1, 1, 1],
padding='VALID'
)
channel_max_weights = tf.nn.max_pool(
value=feature_map,
ksize=[1, feature_map_shape[1], feature_map_shape[2], 1],
strides=[1, 1, 1, 1],
padding='VALID'
)
channel_avg_reshape = tf.reshape(channel_avg_weights,
[feature_map_shape[0], 1, feature_map_shape[3]])
channel_max_reshape = tf.reshape(channel_max_weights,
[feature_map_shape[0], 1, feature_map_shape[3]])
channel_w_reshape = tf.concat([channel_avg_reshape, channel_max_reshape], axis=1)
fc_1 = tf.layers.dense(
inputs=channel_w_reshape,
units=feature_map_shape[3] * inner_units_ratio,
name="fc_1",
activation=tf.nn.relu
)
fc_2 = tf.layers.dense(
inputs=fc_1,
units=feature_map_shape[3],
name="fc_2",
activation=None
)
channel_attention = tf.reduce_sum(fc_2, axis=1, name="channel_attention_sum")
channel_attention = tf.nn.sigmoid(channel_attention, name="channel_attention_sum_sigmoid")
channel_attention = tf.reshape(channel_attention, shape=[feature_map_shape[0], 1, 1, feature_map_shape[3]])
feature_map_with_channel_attention = tf.multiply(feature_map, channel_attention)
# spatial attention
channel_wise_avg_pooling = tf.reduce_mean(feature_map_with_channel_attention, axis=3)
channel_wise_max_pooling = tf.reduce_max(feature_map_with_channel_attention, axis=3)
channel_wise_avg_pooling = tf.reshape(channel_wise_avg_pooling,
shape=[feature_map_shape[0], feature_map_shape[1], feature_map_shape[2],
1])
channel_wise_max_pooling = tf.reshape(channel_wise_max_pooling,
shape=[feature_map_shape[0], feature_map_shape[1], feature_map_shape[2],
1])
channel_wise_pooling = tf.concat([channel_wise_avg_pooling, channel_wise_max_pooling], axis=3)
spatial_attention = slim.conv2d(
channel_wise_pooling,
1,
[7, 7],
padding='SAME',
activation_fn=tf.nn.sigmoid,
scope="spatial_attention_conv"
)
feature_map_with_attention = tf.multiply(feature_map_with_channel_attention, spatial_attention)
return feature_map_with_attention
#example
feature_map = tf.constant(np.random.rand(2,8,8,32), dtype=tf.float16)
feature_map_with_attention = convolutional_block_attention_module(feature_map, 1)
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
result = sess.run(feature_map_with_attention)
print(result.shape)kears的map
https://github.com/datalogue/keras-attention/blob/master/visualize.py
attention map可视化
下面开始抄另一个人的
1. 卷积知识补充
为了后面方便讲解代码,这里先对卷积的部分知识进行一下简介。关于卷积核如何在图像的一个通道上进行滑动计算,网上有诸多资料,相信对卷积神经网络有一定了解的读者都应该比较清楚,本文就不再赘述。这里主要介绍一组卷积核如何在一幅图像上计算得到一组feature map。
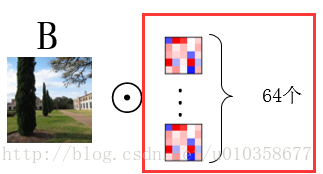
以从原始图像经过第一个卷积层得到第一组feature map为例(从得到的feature map到再之后的feature map也是同理),假设第一组feature map共有64个,那么可以把这组feature map也看作一幅图像,只不过它的通道数是64, 而一般意义上的图像是RGB3个通道。为了得到这第一组feature map,我们需要64个卷积核,每个卷积核是一个k x k x 3的矩阵,其中k是卷积核的大小(假设是正方形卷积核),3就对应着输入图像的通道数。下面我以一个简单粗糙的图示来展示一下图像经过一个卷积核的卷积得到一个feature map的过程。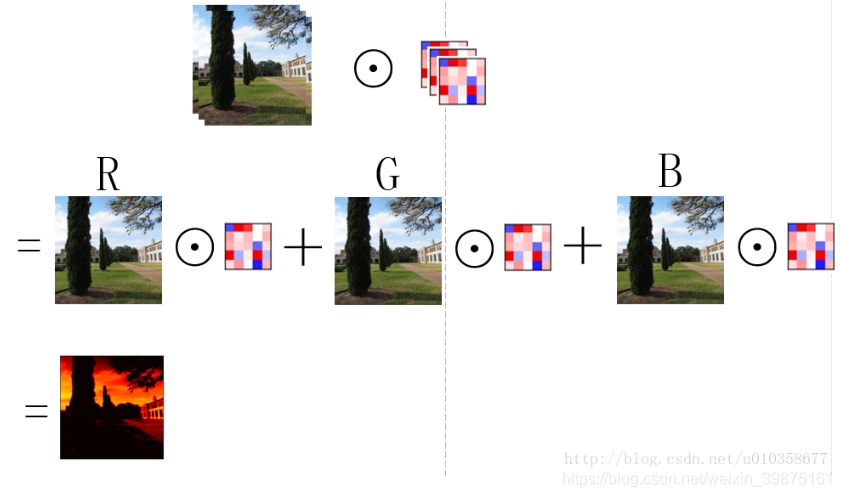
如图所示,其实可以看做卷积核的每一通道(不太准确,将就一下)和图像的每一通道对应进行卷积操作,然后再逐位置相加,便得到了一个feature map。
那么用一组(64个)卷积核去卷积一幅图像,得到64个feature map就如下图所示,也就是每个卷积核得到一个feature map,64个卷积核就得到64个feature map。
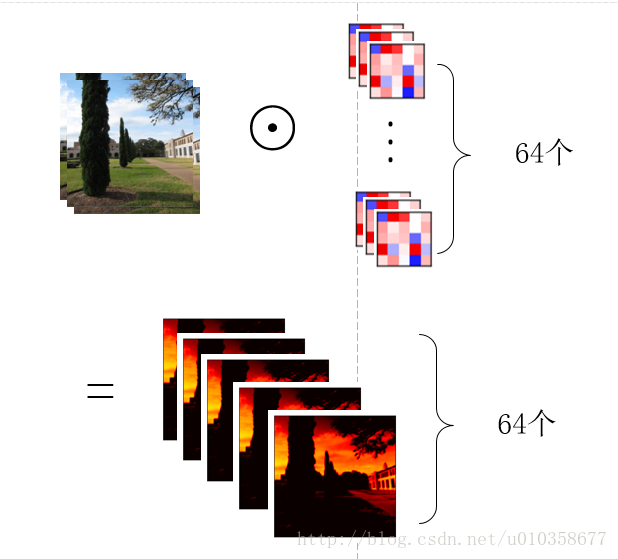
另外,也可以稍微换一个角度看待这个问题,那就是先让图片的某一通道分别与64个卷积核的对应通道做卷积,得到64个feature map的中间结果,之后3个通道对应的中间结果再相加,得到最终的feature map,如下图所示:
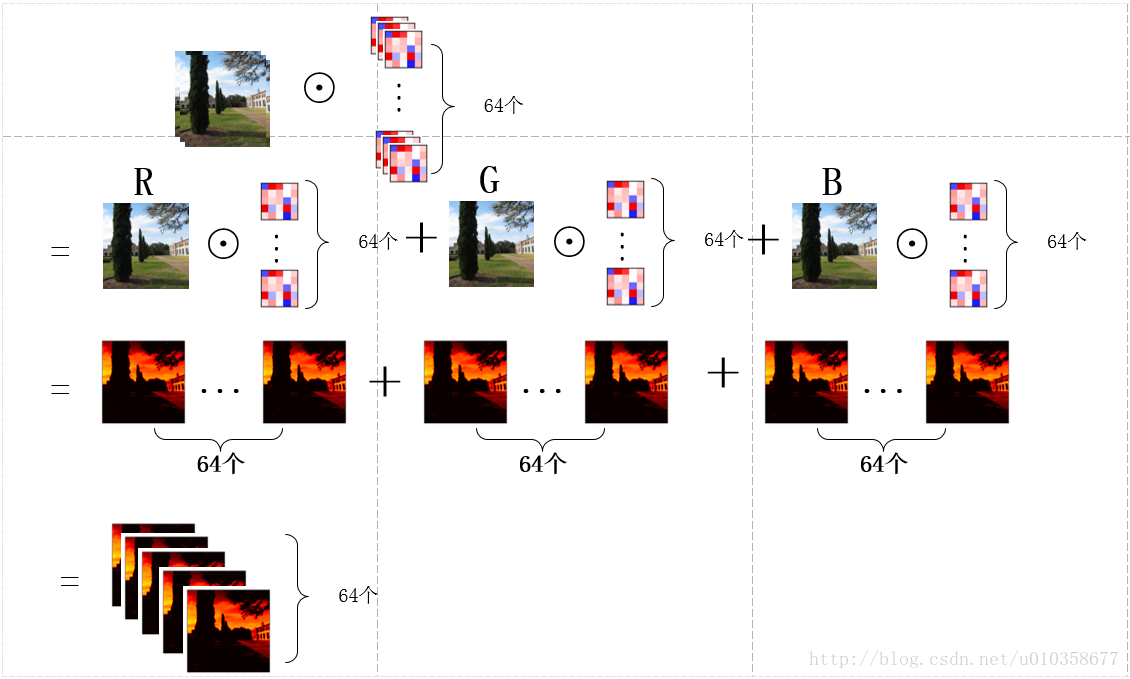
可以看到这其实就是第一幅图扩展到多卷积核的情形,图画得较为粗糙,有些中间结果和最终结果直接用了一样的子图,理解时请稍微注意一下。下面代码中对卷积核进行展示的时候使用的就是这种方式,即对应着输入图像逐通道的去显示卷积核的对应通道,而不是每次显示一个卷积核的所有通道,可能解释的有点绕,需要注意一下。通过下面这个小图也许更好理解。
智能推荐
UE4 C++ 在屏幕上绘制线和文字的方法_ue4 c++画线-程序员宅基地
文章浏览阅读4.2k次,点赞2次,收藏9次。1. 通过C++代码,在屏幕上绘制点、线、圆等图形来进行调试或显示效果。void DrawDebugLine(const FVector& StartPost, const FVector& EndPos, const FLinearColor& LineColor){ ULineBatchComponent* const LineBatcher = GetWorld()->PersistentLineBatcher;//GetDebugLineBatcher(Get_ue4 c++画线
linux常见错误码_linux错误码-程序员宅基地
文章浏览阅读586次。#define EPERM 1 /* Operation not permitted */#define ENOENT 2 /* No such file or directory */#define ESRCH 3 /* No such process */#define EINTR 4 /* Interrupted system call */#define EIO 5 /* I/O error */#define ENXIO 6 /* No such device or address */_linux错误码
什么是JSTL标签?常用的标签库有哪些?_jstl中常用的标签有哪些-程序员宅基地
文章浏览阅读2.3k次。从JSP1.1规范开始,JSP就支持使用自定义标签,使用自定义标签大大降低了JSP页面的复杂度,同时增强了代码的重用性。为此,许多Web应用厂商都定制了自身应用的标签库,然而同一功能的标签由不同的Web应用厂商制定可能是不同的,这就导致市面上出现了很多功能相同的标签,令网页制作者无从选择,为了解决这个问题,Sun公司制定了一套标准标签库(JavaServer Pages Standard Tag Library),简称JSTL。JSTL虽然被称为标准标签库,而实际上这个标签库是由5个不同功能的标签库共同组_jstl中常用的标签有哪些
parseInt() 函数的奇怪行为_parseint3-程序员宅基地
文章浏览阅读725次。parseInt() 是一个内置的 JavaScript 函数,用于从数字字符串中解析整数。 例如,让我们从数字字符串 '100' 中解析整数:const number = parseInt('100'); number; // 100正如预期的那样,'100' 被解析为整数 100。 parseInt(numericalString, radix) 还接受第二个参数:数字字符串参数所在的基数。 radix 参数允许我们解析不同数字基数的整数,最常见的是 2、8、10 和 16。 让我们使用 pa_parseint3
关于win7 内部版本7601,此windows副本不是正版解决!_windows 6.1.7601是什么版本-程序员宅基地
文章浏览阅读4.2k次。 已经激活正版的Win7不知为何今天却说不是正版,桌面右下角显示“windows7内部版本7600此windows副本不是正版”的字样,多少难看,决定激活!因为多种原因,桌面右下角会显示测试模式Windows 7 内部版本7600的水印信息。很多时候检查发现自己的Windows是正常激活状态,以为装了一个未经授权的Windows 7,其实不一定,这种情况只是Windows 7进入了测试模式而已。而..._windows 6.1.7601是什么版本
微信摇一摇插件ios_iOS实现微信朋友圈与摇一摇功能-程序员宅基地
文章浏览阅读163次。本Demo为练手小项目,主要是熟悉目前主流APP的架构模式.此项目中采用MVC设计模式,纯代码和少许XIB方式实现.主要实现了朋友圈功能和摇一摇功能.预览效果:主要重点1.整体架构利用UITabBarController和UINavigationController配合实现.其中要注意定义基类,方便整体上的管理,例如对UINavigationController头部的颜色,字体和渲染颜色等设置.以..._ios摇一摇脚本
随便推点
自动控制原理专业词汇中英文对照(一)_与自动控制有关的英语-程序员宅基地
文章浏览阅读1.2w次,点赞41次,收藏181次。自动控制原理专业词汇中英文对照_与自动控制有关的英语
Redis&Mysql同步_redis与msyql同步-程序员宅基地
文章浏览阅读2.0k次,点赞2次,收藏10次。canal实现redis和mysql同步_redis与msyql同步
安卓开发艺术探索!2021Android高级面试题总结,全套教学资料_安卓侧重思维能力的问题-程序员宅基地
文章浏览阅读523次。背景惯例,先简单陈述一下自己的,91年生人,164年三本毕业后在深圳工作,末流小公司,工资13k,无房,无车,无户口。那时候感觉生活也还行,父母有退休金,我基本上不用太操心,女朋友在一起很久了,很体贴,没有怎么要求我。本来生活就这样一帆风顺下去我就满足了,但是去年初,女朋友家里出了一些事情,一点积蓄全给她了,后面疫情来了,家里开始催婚了,我感觉到了压力。目前的工资无法满足生活,虽然这些年来有一点点的提升,但是,房价物价涨的更快,于是我决定跳槽。从去年年底开始瞎投简历,回顾了一下,一共投了33份简历_安卓侧重思维能力的问题
OpenMV(五)--STM32实现人脸识别_stm32人脸识别-程序员宅基地
文章浏览阅读3.7w次,点赞65次,收藏663次。STM32实现人脸识别引前言引OpenMV(一)–基础介绍与硬件架构OpenMV(二)–IDE安装与固件下载OpenMV(三)–实时获取摄像头图片OpenMV(四)–STM32实现特征检测前言本专栏基于以STM32H743为MCU的OpenMV-H7基板,结合OV7725卷帘快门摄像头进行相关机器视觉应用的开发。..._stm32人脸识别
华为平板可不可以更新鸿蒙,恭喜了,这37款华为支持升级鸿蒙,你的可以吗?...-程序员宅基地
文章浏览阅读1.5w次。智能手机强大的性能是硬件配置跟操作系统软件互相配合协调的结果,现在智能手机的操作是苹果iPhone手机iOS系统以及谷歌安卓系统的天下,iOS系统只有苹果iPhone手机才可以使用,而其他安卓智能手机厂商的系统都是基于安卓系统底层,比如小米的MIUI系统,华为的EMUI系统。华为在上个月举行的开发者大会上正式发布了EMUI11系统以及华为鸿蒙2.0系统,而且有一个好消息就是华为鸿蒙2.0系统终于会..._华为m3平板升级鸿蒙
zendstudio安装_zendstudio 10.1 key-程序员宅基地
文章浏览阅读393次。Zend Studio 10正式版破解及汉化2013年03月12日 ⁄ PHP ⁄ 共 975字 ⁄ 字号 小 中 大 ⁄ 暂无评论 ⁄ 阅读 6,828 次今天下载了Zend Studio 10正式版来学习下PHP,200多兆的软件下了我一个下午居然还要收费,真是惨绝人寰啊!寻思着在我大天朝居然还有这种事,百度之。首先你得下载Zend Studio_zendstudio 10.1 key