【AI视野·今日Sound 声学论文速览 第二十一期】Mon, 9 Oct 2023-程序员宅基地
技术标签: 语音合成扩散模型 神经语音增强 语音克隆 音视频扩散模型 Papers Sound audio 音频事件检测 语音疾病检测 语音合成
AI视野·今日CS.Sound 声学论文速览
Mon, 9 Oct 2023
Totally 13 papers
上期速览更多精彩请移步主页

Interesting:
MBTFNet,用于歌声质量增强的多带宽时频神经网络 (from 西工大 Audio, Speech and Language Processing Group (ASLP@NPU),)
Daily Sound Papers
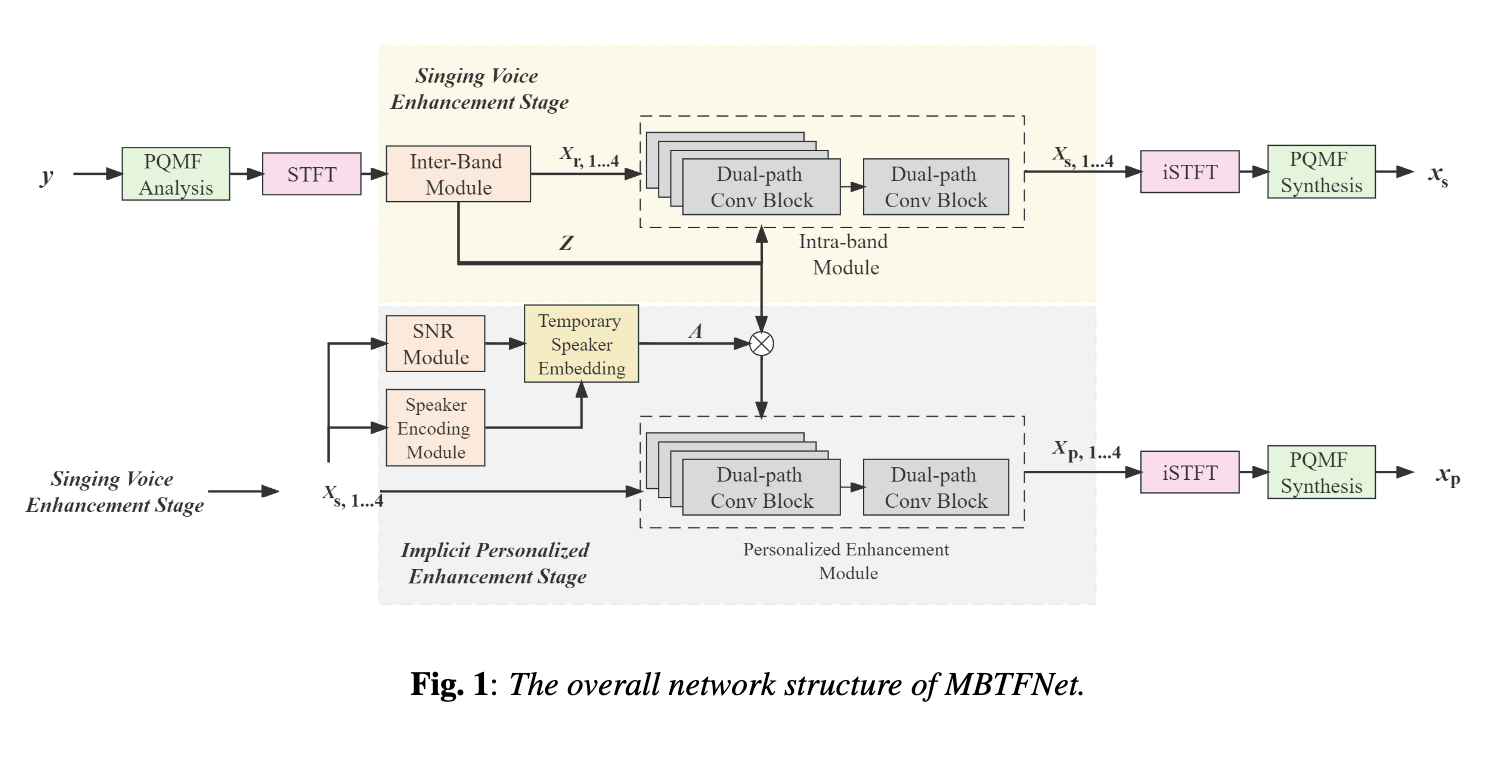
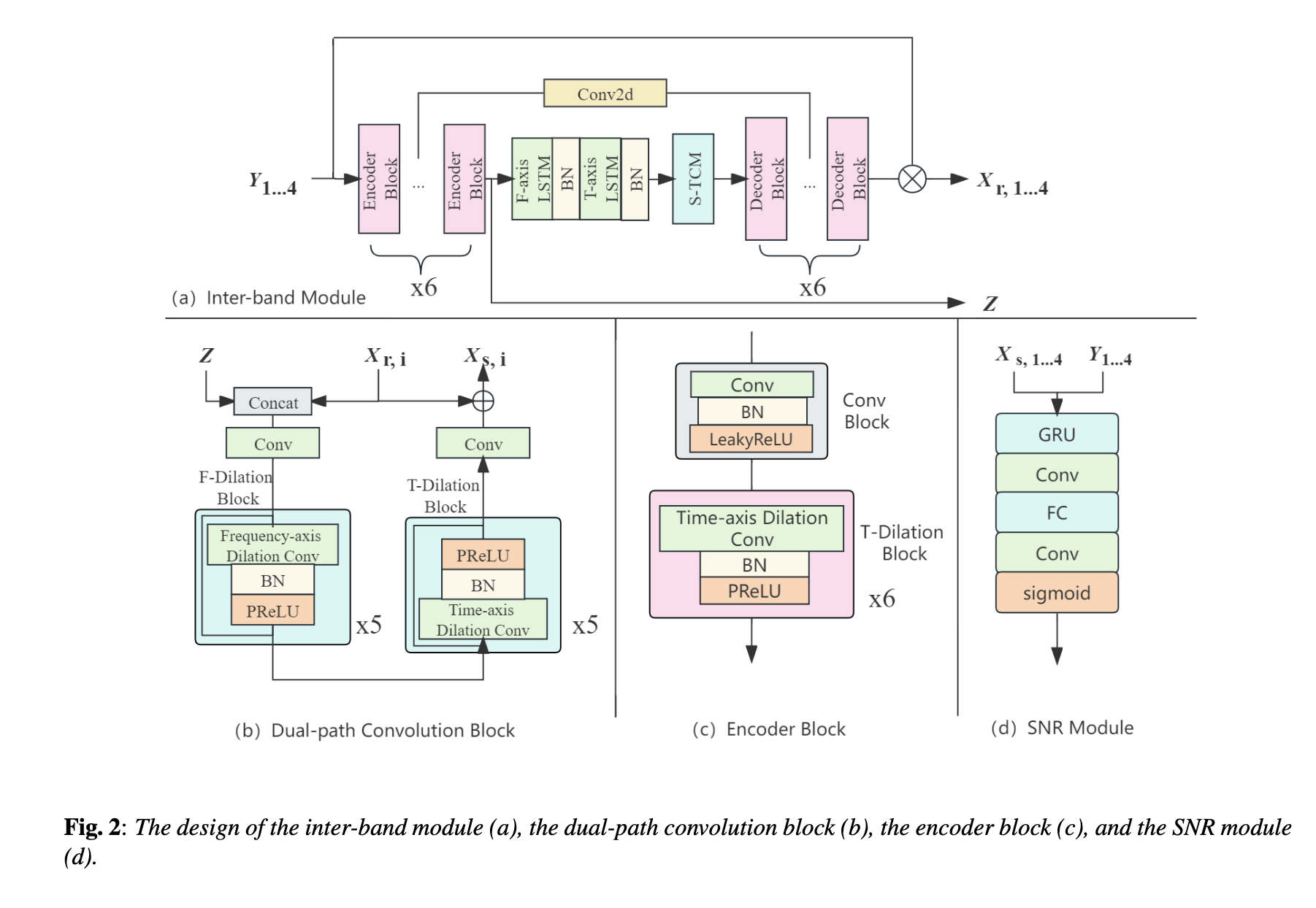
| MBTFNet: Multi-Band Temporal-Frequency Neural Network For Singing Voice Enhancement Authors Weiming Xu, Zhouxuan Chen, Zhili Tan, Shubo Lv, Runduo Han, Wenjiang Zhou, Weifeng Zhao, Lei Xie 典型的神经语音增强SE方法主要处理语音和噪声混合,这对于歌声增强场景来说并不是最佳的。音乐源分离MSS模型平等地对待人声和各种伴奏成分,与仅考虑人声增强的模型相比,这可能会降低性能。在本文中,我们提出了一种新颖的多频带时频神经网络 MBTFNet 用于歌声增强,特别是从歌声录音中去除背景音乐、噪音甚至背景人声。 MBTFNet 结合了带间和带内建模,以更好地处理全带信号。引入双路径建模来扩展模型的感受野。我们提出了基于信噪比 SNR 估计的隐式个性化增强 IPE 阶段,进一步提高了 MBTFNet 的性能。 |
| U-Style: Cascading U-nets with Multi-level Speaker and Style Modeling for Zero-Shot Voice Cloning Authors Tao Li, Zhichao Wang, Xinfa Zhu, Jian Cong, Qiao Tian, Yuping Wang, Lei Xie 零样本说话人克隆的目的是在仅给出当前说话人的单个语音参考的情况下,为 TTS 系统构建过程中未见过的任何目标说话人合成语音。尽管在实际应用中更实用,但当前的零样本方法仍然产生自然度和说话人相似度不理想的语音。此外,还没有考虑在零样本设置中赋予目标说话者任意的说话风格。这是因为零样本说话者和风格克隆的独特挑战是仅从表示任意说话者和任意风格的简短参考中学习解开的说话者和风格表示。为了应对这一挑战,我们提出了 U Style,它采用 Grad TTS 作为骨干,特别是在文本编码器和扩散解码器之间级联特定于说话者的编码器和特定于风格的编码器。因此,利用信号扰动,U Style 被明确分解为说话者和风格特定的建模部分,从而实现更好的说话者和风格分离。为了提高未见过的说话人和风格建模能力,这两个编码器通过跳过连接的 U 网进行多级说话人和风格建模,结合表示提取和信息重建过程。此外,为了提高合成语音的自然度,我们在这些编码器中采用基于均值的实例归一化和风格自适应层归一化来分别执行表示提取和条件自适应。实验表明,在自然性和说话人相似性方面,U Style 显着超越了看不见的说话人克隆中最先进的方法。 |
| Layer-Adapted Implicit Distribution Alignment Networks for Cross-Corpus Speech Emotion Recognition Authors Yan Zhao, Yuan Zong, Jincen Wang, Hailun Lian, Cheng Lu, Li Zhao, Wenming Zheng 在本文中,我们提出了一种新的无监督域自适应 DA 方法,称为层自适应隐式分布对齐网络 LIDAN,以解决跨语料库语音情感识别 SER 的挑战。 LIDAN 扩展了我们之前的 ICASSP 工作,即深度隐式分布对齐网络 DIDAN,其主要贡献在于引入了一种称为隐式分布对齐 IDA 的新颖正则化术语。该术语允许在源训练语音样本上训练的 DIDAN 仍然适用于预测目标测试语音样本的情感标签,而不管跨语料库 SER 中的语料库差异如何。为了进一步增强这种方法,我们将 IDA 扩展到分层适配的 IDA LIDA ,从而产生 LIDAN。该层适应扩展由三个修改后的 IDA 术语组成,它们考虑不同粒度级别的情感标签。这些术语战略性地排列在 LIDAN 的不同全连接层中,与层深度方面不断增强的情感辨别能力相一致。与 DIDAN 相比,这种安排使 LIDAN 能够更有效地学习跨各种语料库的 SER 的情感辨别和语料库不变特征。还值得一提的是,与大多数依赖估计统计矩来描述预先假设的显式分布的现有方法不同,IDA 和 LIDA 都采用了不同的方法。他们利用目标样本重建的思想来直接弥合特征分布差距,而不对其分布类型做出假设。因此,DIDAN 和 LIDAN 可以被视为隐式跨语料库 SER 方法。为了评估 LIDAN,我们在 EmoDB、eNTERFACE 和 CASIA 语料库上进行了广泛的跨语料库 SER 实验。 |
| HuBERTopic: Enhancing Semantic Representation of HuBERT through Self-supervision Utilizing Topic Model Authors Takashi Maekaku, Jiatong Shi, Xuankai Chang, Yuya Fujita, Shinji Watanabe 最近,自监督表示学习 SSRL 方法的有用性已在各种下游任务中得到证实。其中许多模型(例如 HuBERT 和 WavLM)使用从光谱特征或模型自身的表示特征生成的伪标签。从之前的研究可知,伪标签包含语义信息。然而,HuBERT 的学习标准屏蔽预测任务侧重于局部上下文信息,可能无法有效利用全局语义信息,如说话人、演讲主题等。在本文中,我们提出了一种丰富 HuBERT 语义表示的新方法。我们将主题模型应用于伪标签,为每个话语生成主题标签。 HuBERT 中添加了一个辅助主题分类任务,以主题标签为教师。这允许以无监督的方式合并附加的全局语义信息。实验结果表明,我们的方法在大多数任务中实现了与基线相当或更好的性能,包括自动语音识别和八个 SUPERB 任务中的五个。此外,我们发现主题标签包含有关话语的各种信息,例如性别、说话者及其主题。 |
| Zero-Shot Emotion Transfer For Cross-Lingual Speech Synthesis Authors Yuke Li, Xinfa Zhu, Yi Lei, Hai Li, Junhui Liu, Danming Xie, Lei Xie 跨语言语音合成中的零样本情感转移旨在将情感从源语言中的任意语音参考转移到目标语言中的合成语音。构建这样的系统面临着不自然的外国口音的挑战以及对不同语言的共享情感表达进行建模的困难。本文以 DelightfulTTS 神经架构为基础,通过引入专门设计的模块来分别对语言特定的韵律特征和语言共享的情感表达进行建模,从而解决了这些挑战。具体来说,通过非自回归预测编码NPC模块学习特定于语言的语音韵律,以提高合成跨语言语音的自然度。不同语言之间共享的情感表达是从具有强大泛化能力的预训练自监督模型HuBERT中提取的。我们进一步使用分层情感模型来捕获跨不同语言的更全面的情感。 |
| EFFUSE: Efficient Self-Supervised Feature Fusion for E2E ASR in Multilingual and Low Resource Scenarios Authors Tejes Srivastava, Jiatong Shi, William Chen, Shinji Watanabe 自监督学习 SSL 模型在各种语音任务中表现出了卓越的性能,特别是在资源匮乏和多语言领域。最近的研究表明,与使用一种 SSL 模型相比,融合 SSL 模型可以获得更优越的性能。然而,融合模型增加了模型参数大小,导致推理时间更长。在本文中,我们提出了一种从单个 SSL 模型预测其他 SSL 模型特征的新颖方法,从而形成具有竞争性能的轻量级框架。我们的实验表明,SSL 特征预测模型在多语言语音识别任务中优于单个 SSL 模型。领先的预测模型在 ML SUPERB 基准测试中平均 SUPERB 分数提高了 135.4。 |
| Diffusion Models as Masked Audio-Video Learners Authors Elvis Nunez, Yanzi Jin, Mohammad Rastegari, Sachin Mehta, Maxwell Horton 在过去的几年中,音频和视觉信号之间的同步已被用来学习更丰富的视听表示。借助大量未标记视频的帮助,许多无监督训练框架在各种下游音频和视频任务中表现出了令人印象深刻的结果。最近,Masked Audio Video Learners MAViL 已成为最先进的音频视频预训练框架。 MAViL 将对比学习与屏蔽自动编码相结合,通过融合两种模态的信息来联合重建音频频谱图和视频帧。在本文中,我们研究了扩散模型和 MAViL 之间的潜在协同作用,寻求从这两个框架中获得共同利益。将扩散纳入 MAViL,并结合各种训练效率方法(包括使用掩蔽比课程和自适应批量大小调整),可将预训练浮点运算 FLOPS 显着减少 32 倍,预训练挂钟时间减少 18 倍。 |
| Securing Voice Biometrics: One-Shot Learning Approach for Audio Deepfake Detection Authors Awais Khan, Khalid Mahmood Malik 自动说话人验证 ASV 系统容易遭受使用音频深度伪造的欺诈活动,也称为逻辑访问语音欺骗攻击。由于生成式人工智能和语音合成技术的最新进展,这些深度伪造品对语音生物识别技术构成了令人担忧的威胁。虽然已经开发了几种用于语音合成检测的深度学习模型,但大多数模型的通用性很差,特别是当攻击具有与所看到的统计分布不同的统计分布时。因此,本文提出了 Quick SpoofNet,这是一种使用一次性学习和度量学习技术来检测 ASV 系统中可见和不可见的合成攻击的方法。通过使用有效的频谱特征集,该方法从语音样本中提取紧凑且有代表性的时间嵌入,并利用度量学习和三元组损失来评估相似性指数并区分不同的嵌入。该系统有效地对相似的语音嵌入进行聚类,将真实的语音分类为目标类别,并将其他聚类识别为欺骗攻击。使用 ASVspoof 2019 逻辑访问 LA 数据集对所提出的系统进行评估,并针对 ASVspoof 2021 数据集中未见过的深度伪造攻击进行测试。 |
| Transferring speech-generic and depression-specific knowledge for Alzheimer's disease detection Authors Ziyun Cui, Wen Wu, Wei Qiang Zhang, Ji Wu, Chao Zhang 从自发语音中检测阿尔茨海默病 AD 引起了越来越多的关注,而训练数据的稀疏性仍然是一个重要问题。本文通过知识转移来处理这个问题,特别是从语音通用知识和抑郁症特定知识。该论文首先研究了在大量语音和文本数据上预训练的通用基础模型的顺序知识迁移。基于从不同基础模型的不同中间块中提取的表示,对 AD 诊断进行块分析。除了来自语音通用表征的知识之外,本文还提出基于抑郁症和 AD 的高共病率,同时迁移来自语音抑郁症检测任务的知识。研究了并行知识转移框架,该框架共同学习这两个任务之间共享的信息。 |
| Analysis on the Influence of Synchronization Error on Fixed-filter Active Noise Control Authors Guo Yu 主动噪声控制技术在减轻城市噪声(特别是低频分量)方面的功效已得到充分证实。在传统学术研究领域中,自适应算法(例如滤波参考最小均方方法)被广泛用于在许多应用中实现实时降噪。然而,该技术在商业产品中的应用往往因其巨大的计算复杂性和固有的不稳定性而受到阻碍。在这种特殊情况下,采用固定滤波器策略成为解决这些挑战的可行替代方案,尽管在降噪功效方面可能需要权衡。本工作旨在对数字主动噪声控制 ANC 系统的同步误差进行理论研究。 |
| Dementia Assessment Using Mandarin Speech with an Attention-based Speech Recognition Encoder Authors Zih Jyun Lin, Yi Ju Chen, Po Chih Kuo, Likai Huang, Chaur Jong Hu, Cheng Yu Chen 痴呆症的诊断需要一系列不同的测试方法,既复杂又耗时。早期发现痴呆症至关重要,因为它可以防止病情进一步恶化。本文利用语音识别模型在图片描述任务中构建了一个针对普通话使用者的痴呆症评估系统。通过在与现实世界场景非常相似的语音数据上训练基于注意力的语音识别模型,我们显着增强了模型的识别能力。随后,我们从语音识别模型中提取了编码器,并添加了用于痴呆症评估的线性层。我们收集了 99 名受试者的普通话语音数据,并从当地一家医院获得了他们的临床评估。 |
| Challenges and Insights: Exploring 3D Spatial Features and Complex Networks on the MISP Dataset Authors Yiwen Shao 多通道多说话者语音识别在语音处理领域提出了巨大的挑战,其特点是背景噪声、混响和重叠语音等问题。克服这些复杂性需要利用上下文线索将目标语音从不和谐的混合中分离出来,从而实现准确的识别。在这些线索中,3D 空间功能已成为一种前沿解决方案,特别是在配备有关目标说话者的空间信息时。它具有识别混合音频中目标说话者的卓越能力,通常会导致中间处理冗余,为直接训练多合一 ASR 模型铺平了道路。这些模型在模拟和现实数据上都表现出了值得称赞的性能。在本文中,我们将这种方法扩展到 MISP 数据集,以进一步验证其功效。 |
| Audio Event-Relational Graph Representation Learning for Acoustic Scene Classification Authors Yuanbo Hou, Siyang Song, Chuang Yu, Wenwu Wang, Dick Botteldooren 大多数基于深度学习的声学场景分类 ASC 方法根据从音频剪辑转换而来的声学特征来识别场景,其中包含由复调音频事件 AE 纠缠的混合信息。然而,这些方法很难解释它们使用什么线索来识别场景。本文进行了首次研究,揭示了现实生活中的声学场景与最相关的 AE 的语义嵌入之间的关系。具体来说,我们提出了一种用于 ASC 的事件关系图表示学习 ERGL 框架来对场景进行分类,并同时清楚、直接地回答分类中使用了哪些线索。在事件关系图中,每个事件的嵌入被视为节点,而从每对节点导出的关系线索由多维边缘特征描述。在现实生活中的 ASC 数据集上进行的实验表明,所提出的 ERGL 通过仅学习有限数量的 AE 的嵌入,在 ASC 上实现了有竞争力的性能。结果表明基于音频事件关系图识别不同声学场景的可行性。 |
| Chinese Abs From Machine Translation |
智能推荐
Spring Boot 获取 bean 的 3 种方式!还有谁不会?,Java面试官_springboot2.7获取bean-程序员宅基地
文章浏览阅读1.2k次,点赞35次,收藏18次。AutowiredPostConstruct 注释用于在依赖关系注入完成之后需要执行的方法上,以执行任何初始化。此方法必须在将类放入服务之前调用。支持依赖关系注入的所有类都必须支持此注释。即使类没有请求注入任何资源,用 PostConstruct 注释的方法也必须被调用。只有一个方法可以用此注释进行注释。_springboot2.7获取bean
Logistic Regression Java程序_logisticregression java-程序员宅基地
文章浏览阅读2.1k次。理论介绍 节点定义package logistic;public class Instance { public int label; public double[] x; public Instance(){} public Instance(int label,double[] x){ this.label = label; th_logisticregression java
linux文件误删除该如何恢复?,2024年最新Linux运维开发知识点-程序员宅基地
文章浏览阅读981次,点赞21次,收藏18次。本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。下面我们来进行文件的恢复,执行下文中的lsof命令,在其返回结果中我们可以看到test-recovery.txt (deleted)被删除了,但是其存在一个进程tail使用它,tail进程的进程编号是1535。我们看到文件名为3的文件,就是我们刚刚“误删除”的文件,所以我们使用下面的cp命令把它恢复回去。命令进入该进程的文件目录下,1535是tail进程的进程id,这个文件目录里包含了若干该进程正在打开使用的文件。
流媒体协议之RTMP详解-程序员宅基地
文章浏览阅读10w+次,点赞12次,收藏72次。RTMP(Real Time Messaging Protocol)实时消息传输协议是Adobe公司提出得一种媒体流传输协议,其提供了一个双向得通道消息服务,意图在通信端之间传递带有时间信息得视频、音频和数据消息流,其通过对不同类型得消息分配不同得优先级,进而在网传能力限制下确定各种消息得传输次序。_rtmp
微型计算机2017年12月下,2017年12月计算机一级MSOffice考试习题(二)-程序员宅基地
文章浏览阅读64次。2017年12月的计算机等级考试将要来临!出国留学网为考生们整理了2017年12月计算机一级MSOffice考试习题,希望能帮到大家,想了解更多计算机等级考试消息,请关注我们,我们会第一时间更新。2017年12月计算机一级MSOffice考试习题(二)一、单选题1). 计算机最主要的工作特点是( )。A.存储程序与自动控制B.高速度与高精度C.可靠性与可用性D.有记忆能力正确答案:A答案解析:计算...
20210415web渗透学习之Mysqludf提权(二)(胃肠炎住院期间转)_the provided input file '/usr/share/metasploit-fra-程序员宅基地
文章浏览阅读356次。在学MYSQL的时候刚刚好看到了这个提权,很久之前用过别人现成的,但是一直时间没去细想, 这次就自己复现学习下。 0x00 UDF 什么是UDF? UDF (user defined function),即用户自定义函数。是通过添加新函数,对MySQL的功能进行扩充,就像使..._the provided input file '/usr/share/metasploit-framework/data/exploits/mysql
随便推点
webService详细-程序员宅基地
文章浏览阅读3.1w次,点赞71次,收藏485次。webService一 WebService概述1.1 WebService是什么WebService是一种跨编程语言和跨操作系统平台的远程调用技术。Web service是一个平台独立的,低耦合的,自包含的、基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言下的一个子集)标准...
Retrofit(2.0)入门小错误 -- Could not locate ResponseBody xxx Tried: * retrofit.BuiltInConverters_已添加addconverterfactory 但是 could not locate respons-程序员宅基地
文章浏览阅读1w次。前言照例给出官网:Retrofit官网其实大家学习的时候,完全可以按照官网Introduction,自己写一个例子来运行。但是百密一疏,官网可能忘记添加了一句非常重要的话,导致你可能出现如下错误:Could not locate ResponseBody converter错误信息:Caused by: java.lang.IllegalArgumentException: Could not l_已添加addconverterfactory 但是 could not locate responsebody converter
一套键鼠控制Windows+Linux——Synergy在Windows10和Ubuntu18.04共控的实践_linux 18.04 synergy-程序员宅基地
文章浏览阅读1k次。一套键鼠控制Windows+Linux——Synergy在Windows10和Ubuntu18.04共控的实践Synergy简介准备工作(重要)Windows服务端配置Ubuntu客户端配置配置开机启动Synergy简介Synergy能够通过IP地址实现一套键鼠对多系统、多终端进行控制,免去了对不同终端操作时频繁切换键鼠的麻烦,可跨平台使用,拥有Linux、MacOS、Windows多个版本。Synergy应用分服务端和客户端,服务端即主控端,Synergy会共享连接服务端的键鼠给客户端终端使用。本文_linux 18.04 synergy
nacos集成seata1.4.0注意事项_seata1.4.0 +nacos 集成-程序员宅基地
文章浏览阅读374次。写demo的时候遇到了很多问题,记录一下。安装nacos1.4.0配置mysql数据库,新建nacos_config数据库,并根据初始化脚本新建表,使配置从数据库读取,可单机模式启动也可以集群模式启动,启动时 ./start.sh -m standaloneapplication.properties 主要是db部分配置## Copyright 1999-2018 Alibaba Group Holding Ltd.## Licensed under the Apache License,_seata1.4.0 +nacos 集成
iperf3常用_iperf客户端指定ip地址-程序员宅基地
文章浏览阅读833次。iperf使用方法详解 iperf3是一款带宽测试工具,它支持调节各种参数,比如通信协议,数据包个数,发送持续时间,测试完会报告网络带宽,丢包率和其他参数。 安装 sudo apt-get install iperf3 iPerf3常用的参数: -c :指定客户端模式。例如:iperf3 -c 192.168.1.100。这将使用客户端模式连接到IP地址为192.16..._iperf客户端指定ip地址
浮点性(float)转化为字符串类型 自定义实现和深入探讨C++内部实现方法_c++浮点数 转 字符串 精度损失最小-程序员宅基地
文章浏览阅读7.4k次。 写这个函数目的不是为了和C/C++库中的函数在性能和安全性上一比高低,只是为了给那些喜欢探讨函数内部实现的网友,提供一种从浮点性到字符串转换的一种途径。 浮点数是有精度限制的,所以即使我们在使用C/C++中的sprintf或者cout 限制,当然这个精度限制是可以修改的。比方在C++中,我们可以cout.precision(10),不过这样设置的整个输出字符长度为10,而不是特定的小数点后1_c++浮点数 转 字符串 精度损失最小